Эта статья является конспектом материала Effective Aggregate DesignPart III: Gaining Insight Through Discovery.
Во второй части обсуждали, как агрегаты ссылаются друг на друга и как использовать конечную согласованность для достижения определенных бизнес целей. В третьей части увидим, как соблюдение правил агрегатов влияет на проектирование модели Scrum (тестовый проект из первой части).
Переосмысление конструкции модели
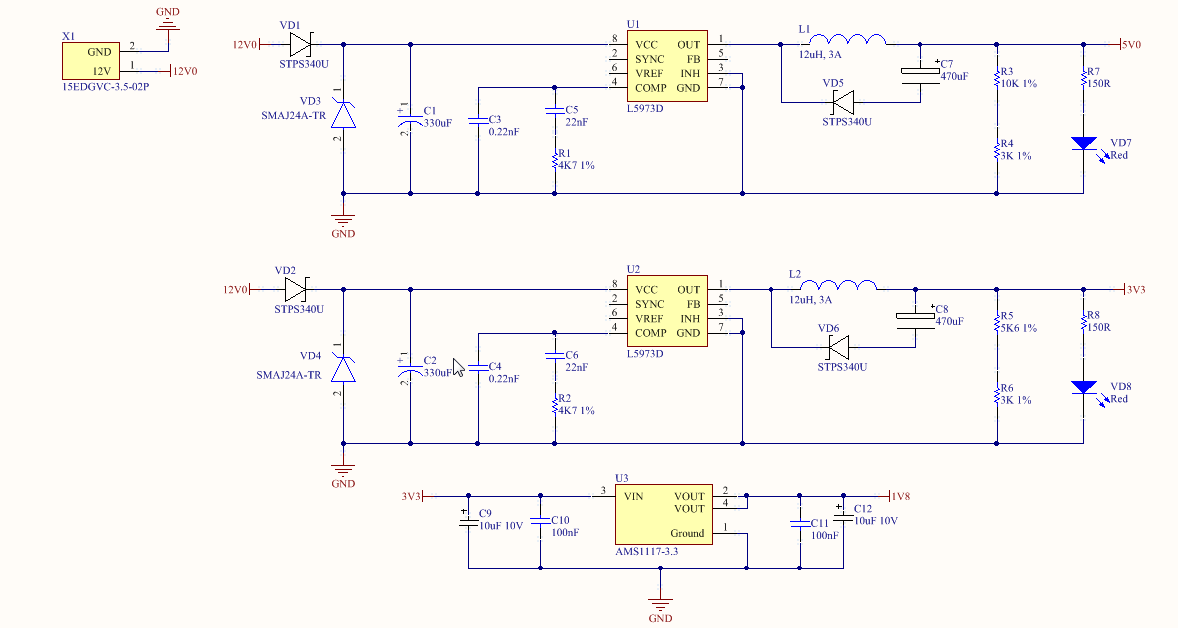
После итерации рефакторинга, благодаря которой избавились от большого агрегата Product, BacklogItem стал отдельным агрегатом. Новую версию модели можно увидеть на рисунке 1. Агрегат BacklogItem содержит коллекцию экземпляров Task. Каждый BacklogItem имеет глобальный уникальный идентификатор BacklogItemId. Ассоциация с другими агрегатами происходит через идентификаторы. Агрегат BacklogItem кажется довольно небольшим.
 Рис.1. Схема модели агрегата BacklogItem
Рис.1. Схема модели агрегата BacklogItem
Несмотря на положительный результат после первой итерации, некоторые опасения все же существуют. Например, атрибут story позволяет вмещать в себя большой объем текста. Из-за этого могут возникнуть возможные накладные расходы.
Учитывая эти потенциальные накладные расходы и ошибки, которые были допущены при проектировании большого кластерного агрегата, поставим перед собой цель уменьшить размер каждого агрегата в ограниченном контексте. Возникают некоторые вопросы. Существует ли истинный инвариант между BacklogItem и Task? Или эту связь можно разбить на две? Какова цена сохранения такой модели?
Ответ лежит в едином языке. Имеются следующие инварианты:
-
После достижения прогресса в задаче элемента бэклога, член команды должен оценить оставшееся время выполнения задачи.
-
Когда член команды оценивает время в 0 часов, элемент бэклога проверяет все задачи на наличие оставшихся часов. Если их нет, то статус элемента бэклога автоматически меняется на done.
-
Если член команды оценивает время на выполнение конкретной задачи в один и больше часов, а статус элемента бэклога уже done, то он автоматически откатывается.
Вроде как это похоже на истинные инварианты. Статус элемента бэклога автоматически корректируется и полностью зависит от общего количества часов, оставшихся на выполнения всех задач. Если общее количество часов на задачи и статус элемента бэклога должны быть согласованными, то на рисунке 1 граница согласованности установлена правильная. Однако все же нужно определить, какую цену имеет текущий кластер с точки зрения производительности и масштабируемости. Сравнивать необходимо с тем, что можно было сэкономить, если бы статус и общее количество часов на задачи имели конечную согласованность, а не транзакционную.
Давайте проанализируем подход транзакционной согласованности, а затем выясним, что можно достичь с помощью конечной согласованности. После чего каждый сам сможет сделать собственный вывод о том, какой подход предпочтительнее.
Оценка стоимости агрегата
Как показано на рисунке 1, каждый Task содержит коллекцию экземпляров EstimationLogEntry. Этот журнал фиксирует конкретные случаи, когда член команды выполняет новую оценку оставшихся часов. На практике, сколько элементов Task может содержать BacklogItem, и сколько элементов EstimationLogEntry будет содержать Task? Точно сказать сложно. Во многом это показатель того, насколько сложна задача и сколько будет длиться спринт. Но некоторые расчеты все же могут помочь.
Часы работы обычно пересчитываются каждый день после того, как член команды закончил работать над определенной задачей. Предположим, что большинство спринтов длится две или три недели. Давайте выберем количество дней от 10 до 15, например, пусть будет 12 дней.
Теперь рассмотрим количество часов, выделенных на каждую задачу. Обычно используют количество часов от 4 до 16. Часто, если задача превышает 12 часов, то эксперты Scrum предлагают разбить ее на более мелкие. В качестве теста предположим, что задачи оцениваются в 12 часов (1 час на каждый день спринта). Итак, получается 12 пересчетов для каждой задачи, предполагая, что каждая задача начинается с 12 часов, выделенные на нее.
Остается вопрос: сколько задач потребуется всего для одного элемента бэклога? Пусть будет, например, тоже 12 (я не стал расписывать, как автор пришел к такому числу; можно самому глянуть в оригинале). В итоге получается 12 задач, каждая из которых содержит 12 оценок в журнале, или 144 (12*12) на элемент бэклога. Хотя это может быть больше чем обычно, но это дает нам конкретную оценку для анализа.
Есть еще одно, что следует учесть. Если следовать рекомендациям экспертов Scrum по определению более мелких задач, это бы несколько изменило ситуацию. Удвоение числа задач (24) и уменьшение вдвое числа записей журнала (6) все равно дают 144. Однако это приведет к загрузке большего количества задач (24 вместо 12) во время запроса на оценку часов, потребляя при этом больше памяти. Но для начала давайте использовать 12 задач по 12 часов каждая.
Общие сценарии использования
Теперь важно рассмотреть общие сценарии использования. Как часто в одном пользовательском запросе нужно будет загружать в память все 144 объекта одновременно? Произойдет ли вообще это когда-то? Если нет, то каково максимальное количество объектов? Кроме того, будет ли многопользовательские запросы, которые могут привести к транзакционной конкуренции? Давайте посмотрим.
Каждая сущность имеет атрибут версии для оптимистической блокировки. Это имеет смысл поскольку инвариант изменения статуса управляется корневой сущностью BacklogItem. Когда статус автоматически изменяется, версия BacklogItem тоже изменяется. Таким образом, изменения в задачах могут происходить независимо друг от друга и не затрагивать корень при каждом изменении, если это не приводит к изменению статуса.
Однако следует учитывать, что если используется документноориентированное хранилище, а не РСУБД, то корень будет изменяться каждый раз, когда изменяется задача, так как она является частью документа.
Когда элемент бэклога впервые был создан, в нем нет задач. Обычно задачи определяются после планирования спринта. Во время совещания между членами команды определяются какие задачи необходимо добавить. В процессе обсуждения каждый член команды добавляет задачу в соответствующий элемент бэклога. Вроде как нет никакой необходимости параллельной работы нескольких членов команды с агрегатом BacklogItem. Это вызывало бы транзакционную гонку, и один из двух запросов потерпел бы неудачу.
Если бы команда узнала, что несколько пользователей регулярно хотят добавлять задачи вместе, это значительно изменило бы анализ. И чаша весов склонилась бы в пользу разделения BacklogItem и Task на два отдельных агрегата. Однако можно было бы отключить оптимистическую блокировку. В этом случае имеет смысл разрешить одновременное добавление задач, если они не создают проблем с производительностью и масштабируемостью.
Если задачи сначала оцениваются в 0 часов, а затем оценка уточняется и обновляется, транзакционной конкуренции все равно не будет. Одновременное использование в данном случае не меняет статус элемента бэклога, поскольку статус может смениться на done, если оценка меняется с ненулевого значения на ноль, или откатывается, если статус уже done, и часы меняются с нулевого значения на положительное.
Будут ли ежедневные оценки приводить к проблемам? В первый день спринта обычно нет журналов оценки по заданной задаче элемента бэклога. В конце первого дня каждый член команды, работающий над задачей, сокращает расчетное количество часов на один. Это добавляет новую запись в журнал оценки к каждой задаче, но статус элемента бэклога не изменяется. При этом только один член команды корректирует часы определенной задачи. Только на 12-й день происходит изменение статуса. После того, как будет добавлена последняя 144 запись в журнал для 12 задаче, происходит автоматический переход статуса в done.
Этот анализ привел к важному выводу. Даже если изменить сценарии использования, ускорив выполнение задач вдвое (6 дней), это ничего не меняет. Версия корня меняется только при окончательной оценке, которая меняет статус. Это кажется безопасным, хотя накладные расходы на память все еще под вопросом.
Потребление памяти
Теперь проанализируем проблему с памятью. Важно то, что оценка добавляется в журнал по дате как объект значения. Если член команды повторно оценивает любое количество раз в течение одного дня, то сохраняется только самая последняя оценка. Последнее значение с той же датой заменяет предыдущее значение в коллекции. Поэтому можно предположить, что задача никогда не будет иметь больше записей в журнале оценки, чем количество дней, в течение которого выполняется спринт. Однако это предположение неверно, если задачи были сформированы за один или более дней до планирования спринта, а часы были пересчитаны в любой из этих дней. Выходит, за каждый прошедший день добавляется одна дополнительная запись в журнал.
Что насчет общего количества задач и оценок в памяти во время каждого повторного оценивания? При использовании ленивой загрузки для задач и журналов оценки у нас будет до 12 + 12 объектов в памяти во время одного запроса, поскольку все 12 задач будут загружены во время обращения к этой коллекции. Чтобы добавить последнюю запись в журнал оценки к одной из задач, нужно загрузить коллекцию записей журнала и это дает еще до 12 объектов. В конечном итоге агрегат содержит один элемент бэклога, до 12 задач и до 12 записей в журнале, что в сумме дает максимум 25 объектов. Это не очень много. Другой факт заключается в том, что максимальное количество объектов не достигается до последнего дня спринта. В течение большей части спринта агрегат будет еще меньше.
Вызовет ли это проблему с производительностью? Необходимо провести тесты, чтобы узнать возможные накладные расходы многократной выборки.
Есть еще один факт. Команда может оценивать, используя story points, а не часы работы. Когда формируется определенная задача, можно назначить только один час для каждой задачи. Во время спринта каждая задача будет переоцениваться только один раз, меняя один час на ноль, когда задача будет завершена. Что касаемо агрегата, то использование story points сокращает общее количество записей журнала оценки для каждой задачи до одного и почти исключает накладные расходы памяти.
Альтернативная конструкция
Давайте теперь попробуем сделать Task независимым агрегатом. Это уменьшило бы накладные расходы на ленивую загрузку. Фактически, такая конструкция дает возможность сразу загружать записи журнала оценки, не используя ленивую загрузку.
 Рис. 2. BacklogItem и Task как отдельные агрегаты
Рис. 2. BacklogItem и Task как отдельные агрегаты
Однако в этом случае, если придерживаться правил, то нельзя изменять в одной транзакции Tak и BacklogItem. Следовательно, при необходимости автоматической смены статуса согласованность между задачей и элементом бэклога будет конечной, а не транзакционной.
Реализация конечной согласованности
Когда Task выполняет команду estimateHoursRemaining(), она публикует соответствующие доменное событие для достижения конечной согласованности. Событие имеет следующие свойства:
public class TaskHoursRemainingEstimated implements DomainEvent { private Date occurredOn; private TenantId tenantId; private BacklogItemId backlogItemId; private TaskId taskId; private int hoursRemaining; ...}
Теперь определенный подписчик будет прослушивать это событие и делегировать доменной службе выполнение согласованности. Служба:
-
Использует BacklogItemRepository для получения BacklogItem по идентификатору.
-
Использует TaskRepository для получения всех экземпляров Task, связанных с конкретным BacklogItem
-
Выполняет BacklogItem команду estimateTaskHoursRemaining(), передавав ей значение hoursRemaining и определенный экземпляр Task. BacklogItem может менять свой статус в зависимости от параметров.
Необходимо найти способ оптимизировать эту трехэтапную обработку, поскольку при каждой переоценки загружаются все экземпляры задач. Это можно сделать довольно просто. Вместо того, чтобы использовать репозиторий для получения всех экземпляров Task, лучше просто запросить у него сумму всех часов, которая будет рассчитываться базой данных, выделенных на задачи.
public class TaskRepositoryImpl implements TaskRepository { ... public int totalBacklogItemTaskHoursRemaining( TenantId aTenantId, BacklogItemId aBacklogItemId) { Query query = session.createQuery( "select sum(task.hoursRemaining) from Task task " + "where task.tenantId = ? and " + "task.backlogItemId = ?"); ... }}
Конечная согласованность немного усложняет пользовательский интерфейс. Если согласование состояния не произойдет в течение нескольких сотен миллисекунд, как пользовательский интерфейс отобразит новое состояние? Необходимо ли размещать бизнес-логику в представлении для определения текущего статуса? Это был бы антипаттерн умный UI. В противном случае представление отобразит устаревший статус. Это легко может быть воспринято как ошибка.
Представление может использовать фоновый запрос с помощью Ajax, но это может быть неэффективно. Поскольку компонент представления не может определить, когда потребуется проверка обновления статуса, большинство запросов Ajax не нужны. 143 из 144 переоценок не вызовут обновление статуса, что приведет к большему количеству избыточных запросов. Вместо этого можно использовать Ajax Push.
С другой стороны, возможно лучшее речение самое простое. Можно разместить визуальный сигнал на экране, который информирует пользователя о том, что текущее состояние неопределенно и сообщить приблизительные временные рамки, которые требуются для осуществления согласованности.
Время принимать решение
Исходя из всего этого анализа, возможно будет лучше отказаться от разделения Task и BacklogItem. Сейчас оно не стоит дополнительных усилий, риска нарушения истинного инварианта или возможности столкнутся с устаревшим статусом в представлении. Текущий агрегат довольно мал. Даже если в худшем случае будет загружено 50 объектов, а не 25, это все равно кластер небольшого размера.
Однако возможное разделение Task и BacklogItem в будущем никто не отменяет. После дальнейших экспериментов с текущей структурой, выполнения тестов производительности и нагрузки станет более ясно, какой подход является лучшим.
Вывод
Используя модель предметной области на реальном примере, мы рассмотрели насколько важно следовать эмпирическим правилам при проектировании агрегатов:
-
Моделируйте истинные инварианты в границах согласованности.
-
Проектируйте небольшие агрегаты.
-
Ссылайтесь на другие агрегаты по идентификатору.
-
Если необходимо, используйте конечную согласованность за пределами границ.
Если мы будем придерживаться правил, у нас будет согласованность там, где это необходимо, и мы будем поддерживать оптимальную производительность и хорошую масштабируемость системы, при этом сохраняя единый язык нашего бизнес-домена в созданной модели.