Распределенная файловая система Apache Hadoop (HDFS) де-факто является файловой системой для больших данных. При этом легко забыть, насколько масштабируемая и надежная HDFS в реальном мире. Наши клиенты управляют кластерами с тысячами узлов; в этих кластерах хранится более 100 петабайт данных, обслуживающих тысячи одновременных клиентов.
Верная своим корням big data, HDFS работает лучше всего, когда большинство файлов имеют большой размер - от десятков до сотен мегабайт. HDFS страдает от известного ограничения небольших файлов, а производительность начинает ухудшаться при более чем 350 миллионах файлов. Существует повышенный спрос на HDFS-подобные системы хранения данных, которые могут масштабироваться до миллиардов маленьких файлов.
Ozone - это распределенное объектное хранилище, которое может управлять как малыми, так и большими файлами. В то время как HDFS предоставляет семантику, подобную POSIX, Ozone архитектурно выглядит и ведет себя как Object Store. Ozone разрабатывается и внедряется командой инженеров и архитекторов, имеющих значительный опыт управления большими кластерами Apache Hadoop. Это дало нам представление о том, что HDFS делает хорошо, и о некоторых вещах, которые можно делать по-другому. Эти уроки повлияли на дизайн и эволюцию Ozone.
При проектировании Озона мы руководствовались следующими принципами:
Strongly Consistent
Строгая консистенция упрощает проектирование приложений. Озон
разработан для обеспечения строгой серийности.
Архитектурная простота
Простая архитектура
проще в рассуждениях и проще в отладке, когда что-то идет не так.
Мы постарались сделать архитектуру Ozone простой даже ценой
потенциальной масштабируемости. Однако Ozone не сдаёт позиции,
когда речь заходит о масштабировании. Мы разработали его для
хранения более 100 миллиардов объектов в одном кластере.
Многослойная архитектура
Для достижения масштабов современных систем хранения данных Ozone
является многоуровневой файловой системой. Она отделяет управление
пространством имён от слоя управления блоками и узлами, что
позволяет пользователям независимо масштабировать по обеим
осям.
Безболезненное восстановление
Ключевым преимуществом HDFS является то, что она может эффективно
восстанавливаться после таких катастрофических событий, как
отключение электроэнергии по всему кластеру без потери данных и без
дорогостоящих шагов по восстановлению. Потери в стойке и в узле -
относительно незначительные. Озон является таким же надежным перед
лицом сбоев.
Открытые исходные коды в Apache
Мы считаем, что сообщество Apache с открытым исходным кодом имеет
решающее значение для успеха Ozone. Весь дизайн и разработка Ozone
осуществляется в сообществе Apache Hadoop.
Взаимодействие с экосистемой Hadoop
Озон должен использоваться существующей экосистемой Apache Hadoop и
связанными с ней приложениями, такими как Apache Hive, Apache Spark
и традиционные задания MapReduce. Следовательно, Озон
поддерживает:
- Hadoop Compatible FileSystem API (он же OzoneFS). Это позволяет
Hive, Spark и т.д. использовать Ozone в качестве хранилища с
нулевыми модификациями.
- Data Locality (Локальность данных) была ключом к оригинальной
архитектуре HDFS/MapReduce, позволяя планировать задачи на тех же
узлах, что и данные. Ozone также поддерживает локализацию данных
для приложений.
- Совместное развертывание рядом с HDFS. Ozone может быть
установлен в существующем кластере Hadoop и может совместно
использовать диски хранения данных с HDFS.
Озон состоит из знакомых для S3 хранилищ понятий - Volumes,
Buckets и keys.
Volumes - Volumes аналогичны аккаунтам. Они могут
быть созданы или удалены только администраторами. Администратор
обычно создает том для всей организации или команды.
Buckets - Том может содержать ноль и более корзин. Корзины Озона похожи на корзины Amazon S3.
Keys - Ключи уникальны внутри данной корзины и похожи на Объекты в S3. Имя ключа может быть любой строкой. Значения представляют собой данные, которые вы храните внутри этих ключей, в настоящее время Ozone не применяет верхний предел размера ключа.
Чтобы масштабировать Ozone до миллиардов файлов, нам нужно было
решить два узких места, которые существуют в HDFS:
Масштабируемость пространства имён
Мы больше не можем хранить все пространство имен в памяти одного
узла. Ключевым моментом является то, что пространство имен имеет
опорную точку, поэтому мы можем хранить только рабочий набор в
памяти. Пространство имен управляется сервисом под названием Ozone
Manager.
Масштабируемость карты блоков
Эту проблему решить сложнее. В отличие от пространства имён, карта
блоков не имеет опорного местоположения, так как узлы хранения
(DataNodes) периодически посылают отчеты о каждом блоке в системе.
Озон делегирует эту проблему на общий уровень хранилища под
названием Hadoop Distributed DataStore (HDDS).
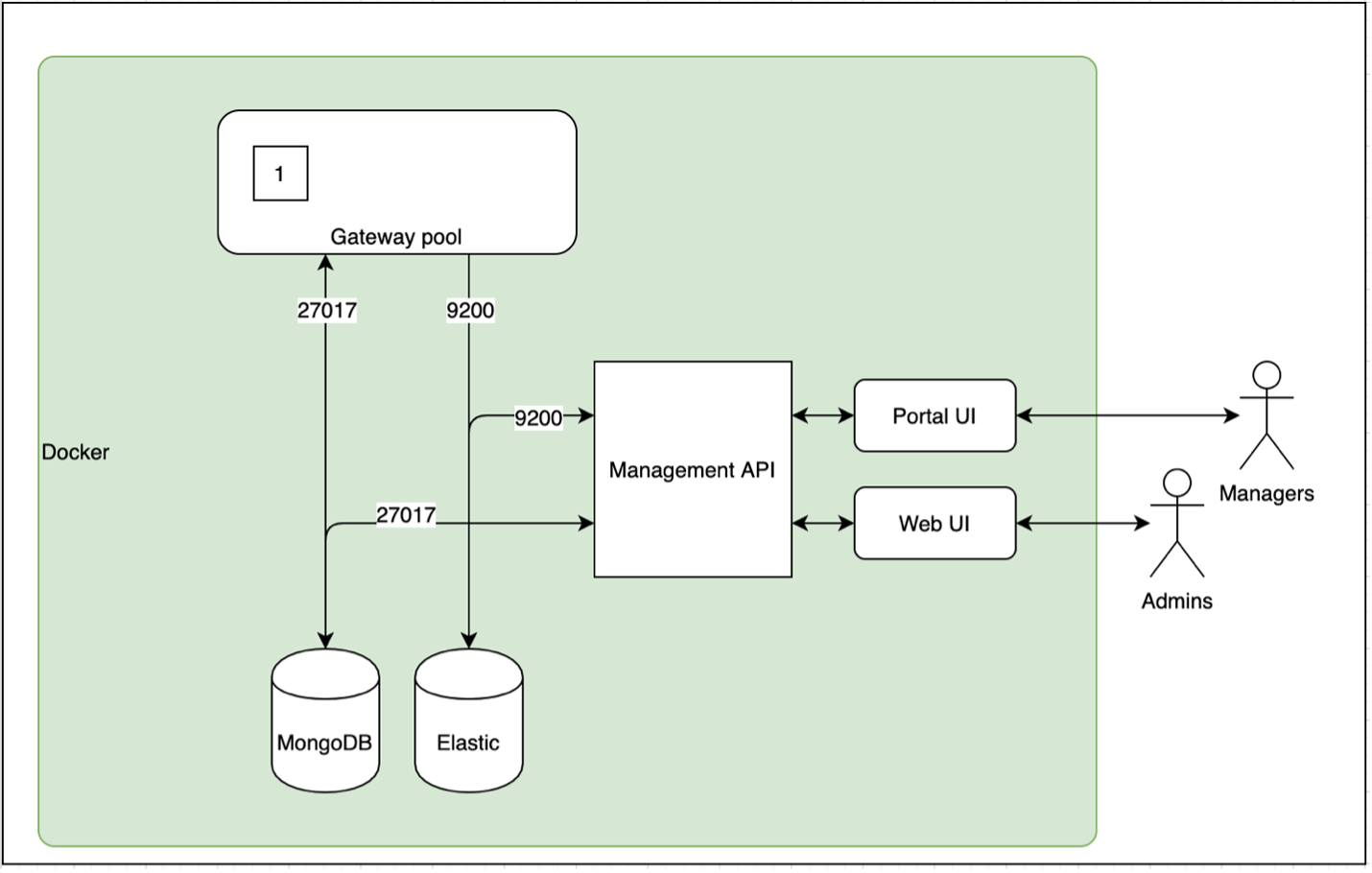
Основные блоки архитектуры:
-
Storage Containers - Контейнеры для хранения, построенные с использованием готовой key-value БД (RocksDB). Типичный размер контейнера - 5 ГБ. Единица репликации, реплики синхронизированы через консенсус-протокол RAFT. Хранится на DataNodes, управляется Storage Container Manager. Эквивалент менеджера блоков HDFS.
-
Консенсусный протокол RAFT через Apache Ratis. RAFT - это консенсус-протокол, похожий по духу на Paxos, но предназначенный для простоты понимания и реализации. Apache Ratis - это Java-реализация с открытым исходным кодом RAFT, оптимизированная для высокой пропускной способности.
-
Storage Container Manager (SCM) - сервис, который управляет жизненным циклом реплицируемых контейнеров. Масштабируется, не отслеживая отдельные блоки данных. Вместо этого он отслеживает контейнеры, которые являются аггрегатами информации о блоках. Storage Container Manager выступает в качестве кластер менеджера, центра сертификации, блок-менеджера и менеджера по репликам. SCM выделяет блоки и распределяет их по узлам. Клиенты читают и записывают эти блоки напрямую. SCM отслеживает все реплики блоков.
-
Hadoop Distributed Data Store (HDDS) - общий уровень распределенного хранения для блоков, не предоставляющих пространства имен.
-
Ozone Manager (OM) - менеджер пространства имен, реализующий архитектуру ключ-значение. Пространство имён Озона - это коллекция томов, каждый из которых состоит из корзин и ключей. OM ведет список томов, корзин и ключей. Ozone Manager будет использовать Apache Ratis для воспроизведения состояния OM. Это обеспечивает высокую доступность для Ozone.

Основные свойства Озона, которые помогают ему достичь масштабируемости:
-
Пространство имён (namespace) в Ozone сохраняется в локальную RocksDB, при таком дизайне может быть легко настроен баланс между производительностью (сохранение всего в памяти) и масштабируемостью (сохранение на диске менее используемых метаданных).
-
Управление пространством имён и блоками разделено на два разных сервиса OzoneManager(OM) и StorageContainerManager(SCM) соответственно. Каждый из них может масштабироваться независимо друг от друга.
-
В отличие от HDFS, отчеты по блокам Ozone передаются через контейнерные отчеты, которые агрегируют отчеты по нескольким блокам в контейнере.
Бенчмаркинг Ozone
Apache Ozone был разработан для преодоления ограничений масштабирования HDFS при небольших файлах и большом общем количестве объектов файловой системы. На текущем оборудовании центра обработки данных ограничение HDFS составляет около 350 миллионов файлов и 700 миллионов объектов файловой системы. Архитектура Ozone устраняет эти ограничения. Ниже сравнивается производительность Ozone при работе с HDFS.
Для тестирования мы выбрали широко используемый эталонный тест TPC-DS и обычный стек Hadoop, состоящий из Hive, Tez, YARN и HDFS наряду с Ozone. В соответствии с текущей потребностью отрасли в разделении вычислений и хранилищ данных, когда используются высокоплотные узлы хранения и эластичные вычисления, мы выполняем эти тесты, используя отдельные DataNodes и NodeManagers. Фундаментальная цель данного исследования и последующих усилий по оптимизации продукта - сделать его сопоставимым по стабильности и производительности с HDFS. И мы хотели бы отметить невероятный объем работы, проделанной сообществом за последние несколько месяцев для достижения этой цели.
Hive на Ozone работает быстрее
Следующие измерения были получены путем создания двух независимых наборов данных по 100 ГБ и 1 ТБ в кластере с 12 выделенными узлами для хранения и 12 выделенными вычислительными узлами. В последнем разделе этой статьи будет представлена более подробная информация о конфигурации.
Следующие иллюстрации показывают, что, учитывая общее время выполнения наших 99 тестовых запросов, на обоих наборах данных Ozone превзошел HDFS в среднем на 3,5%.


Чтобы лучше понять подробные результаты, мы разделили наши запросы на три группы:
1. Более быстрые запросы (запросы, в которых Ozone превосходит HDFS).
2. Незначительно более медленные запросы (запросы, в которых Ozone уступает HDFS на 25% или меньше).
3. Выбросы - запросы, в которых Ozone уступает HDFS более чем на 25%).


Когда данные находятся в Ozone, более чем в 70% случаев запросы выполняются быстрее по сравнению с HDFS. Усилия сообщества, направленные на стабилизацию и улучшение производительности, похоже, окупаются. Но есть еще куда расти.
На следующем графике разброса показана средняя разница во времени выполнения между Ozone и HDFS для каждого отдельного запроса TPC-DS и каждого набора данных. Каждый запрос на графике, который колеблется в районе 0%, показывает незначительную разницу в производительности между Ozone и HDFS. Чтобы нормализовать дисперсию из-за шума, числа были усреднены для каждого запроса за 10 последовательных прогонов.


Значения по оси Y представляют собой разницу во времени выполнения по сравнению со временем выполнения запроса в HDFS. Так, например, 50% означает, что разница составляет половину времени выполнения в HDFS. Это фактически означает, что в Ozone запрос выполнялся в 2 раза быстрее, а -50% (отрицательное значение) означает, что для выполнения запроса в Ozone потребовалось в 1,5 раза большее время, чем в HDFS.
Заключение
Тестовые прогоны показывают, что Ozone с небольшим отрывом лидирует - немногим более чем на 70% запросов TPC-DS. Однако есть несколько выбросов, которые мы активно изучаем, чтобы найти узкие места и сгладить их с наивысшим приоритетом.
В настоящее время Ozone выпущен в GA-версии, готов к работе в
продуктиве и включен в дистрибутив
Cloudera Data Platform (CDP), мы постоянно находимся в процессе
сбора отзывов и продолжения развития распределенной системы
хранения больших данных следующего поколения. В рамках платформы
Озон интегрирован с Ranger и поддерживает шифрование данных как в
пути, так и в покое.
Сообщество пользователей активно растёт, так например Tencent
использует Озон в продуктиве на около 1000 узлах, также в списке
активных пользователей Bloomberg и Target. Доступны или готовятся к
выходу референсные архитектуры от
Cisco, Dell и HP, а также материалы от Клаудеры. Из основных
планов на ближайшее будущее: реализация HA Storage Container
Manager, поддержка Erasure Coding, интеграция с Atlas,
NiFi/Kafka/Flink коннекторы и тул для миграции HDFS->Ozone.
Подробная информация о среде
Кластер состоит из 28 однородных физических узлов, оснащенных 20-ядерными процессорами Intel Xeon, 128 ГБ оперативной памяти, 4 дисками по 2 ТБ и сетью 10 ГБ/с. Узлы, работающие под управлением CentOS 7.4 и Cloudera Runtime 7.0.3, которые содержат Hive 3, Hadoop 3, Tez 0.9 и Ozone, созданы из основной ветки Apache с начала января 2020 г.
4 главных узла, один - для Cloudera Manager, Prometheus и Zookeeper, другой - для YARN, третий - для Hive и четвертый - для HDFS и Ozone, поскольку мы используем их в разное время.
12 узлов хранения, с 2 выделенными дисками для хранения данных и 12 вычислительных узлов с 3 дисками, выделенными для YARN и журналов (логов).
Шифрование SSL/TLS было отключено, и использовалась простая аутентификация.
Ozone был настроен на использование одного тома с одним бакетом для имитации семантики HDFS.
Высокая доступность не была включена ни для одной из служб.
Внутренняя сеть кластера используется совместно с другими хостами, и мы знаем, что трафик может быть нестабильным - от довольно низкого до пикового. Отчасти это причина того, что мы усреднили результаты десяти полных тестовых прогонов как для HDFS, так и для Ozone, прежде чем прийти к окончательному результату.
Кэширование результатов в Hive было отключено для всех запросов, чтобы все данные считывались из файловой системы.
Инструменты, которые мы использовали для тестирования, также доступны и имеют открытый исходный код - если хотите, попробуйте его в своей среде. Все инструменты можно найти в этом репозитории.
Дополнительная литература