Перетаскивание элементов в списке популярная фича в современных приложениях, наличие которой только порадует пользователей. Однако реализуя такой функционал нужно постараться не наступить на грабли плохой оптимизации: большое количество элементов, пересчет позиции каждый раз, а если в списке ещё и несколько секций то при перетаскивании между секциями, скорее всего, нужно реализовать дополнительную логику. Как не получить по лбу, уменьшить количество вычислений, и как нам в этом помогут лексоранги читайте под катом.
Обозначим проблему
Итак, Вы решили добавить в своё приложение возможность перетаскивать элементы. Значит, нужно как-то сортировать элементы, иначе никакого смысла в перетаскивании. И что первое приходит в голову?
Позиции
Самые обычные ничем не примечательные позиции. Те самые числа от 1 до бесконечности(не совсем). Работать с ними просто и удобно, элементы сортируются без проблем. На первый взгляд, всё хорошо. На столько хорошо, что для большинства приложений это то, что нужно.
Что же тогда не так с числовой позицией?
Проблема таится в сопутствующих операциях. Нужно внедрить элемент между вторым и третьим элементами? Смещаем всё вперёд на один начиная с третьего элемента, не забыв при этом обновить данные в БД. Выполнение такой операции единожды не выглядит сложно, однако эта операция будет выполняться довольно часто.
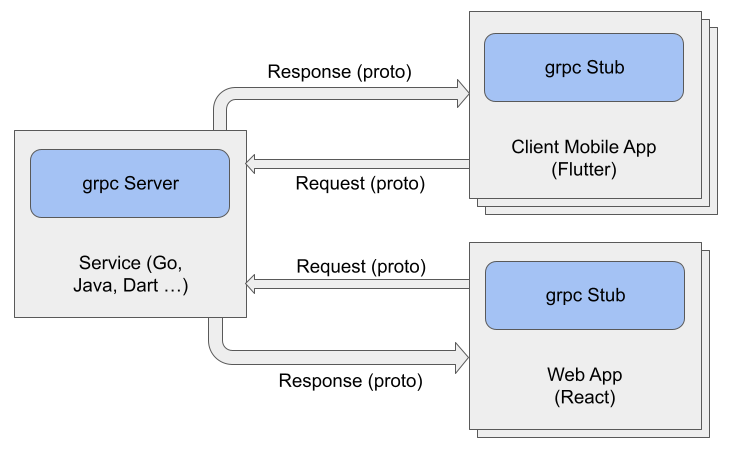
Еще одна проблемная операция обновление данных на сервере. Обновили задачу нужно послать апдейт всех затронутых задач на сервер. Сервер в свою очередь должен разослать этот апдейт всем, кто подписан на список задач. Чем чаще пользователи изменяют порядок задач в списке, тем больше данных нужно послать на сервер, и тем больше данных сервер должен разослать клиентам.
Получается, при перетягивании одной задачи мы будем не только изменять позиции у большого количества элементов, но и отсылать их на сервер, который будет после рассылать их другим пользователям.
Вывод: хочется что-то более оптимальное
Варианты решений
Когда мы в компании столкнулись с подобной проблемой, первым возможным решением стал следующий алгоритм: всем элементам мы расставим какие-нибудь стандартные позиции через равные интервалы(шаги). Так, первый элемент будет иметь позицию равной 1, а второй равной 1000. Когда пользователь захочет перетащить что-нибудь между этими двумя элементами, мы посчитаем среднюю позицию (1000 + 1) / 2 = ~500. И так далее, и так далее.
Чем плох этот вариант, думаю, вы догадались сразу. Мы ограничены в количестве шагов, которые можно сделать. Т.е. между 1 и 1000 500. Между 1 и 500 250. Потом 125 и в конечном итоге места не останется. Увеличение шага эту проблему не решает.
Может воспользуемся дробными числами?
Нет, дробные числа не исправляют проблему, а лишь оттягивают момент её появления.
Немного подумав и погуглив, мы наткнулись на доклад о том, как в Жире (Jira) используются лексоранги (Lexorank, доклад).
Основаны они на трёх вещах:
1 строки легко сортировать в алфавитном порядке
2 между двумя строками можно найти среднюю строку (не всегда, и это уже не так просто)
3 нельзя найти среднюю? Воспользуемся ведром(звучит странно, да)
С сортировкой всё понятно, идём сразу к пункту номер 2.
Есть в английском алфавите буквы в a и c, а между ними, очевидно, b. Но как найти эту b математическим путём?
Давайте просто отнимем от кода буквы c код буквы a, получим 2 (c = 143, a = 141). Осталось поделить результат пополам. Получили 1. И правда, если прибавить к коду а единицу, мы получим код буквы b.
Комбинация английских букв и называется лексорангом
Ситуации, когда между двумя строками нет места, тут так же имеют место быть, и я уже писал, что для их решения используются вёдра.
Ведро это метка перед рангом, выглядит так: 0|aaa. Здесь 0 номер ведра. Когда места не остаётся, элементы перекладываются из одного ведра в другое, а метки расставляются заново с сохранением порядка. Вот и вся магия!
Как этим воспользовались мы
Точно не сказано (скорее, просто мы не нашли) как легко и безболезненно найти среднюю строку между двумя. Поэтому мы напряглись и придумали вот что. Сразу окунаемся в пример.
Возьмём две строки: aa и cc и найдём между ними среднюю.
После посимвольного вычитания как выше мы получим число 11. Но что делать дальше? Вы можете подумать, что нужно просто добавить результат к строке aa. Тут и правда получится строка bb, находящаяся между аа и сс, однако алгоритм будет неверным, и сейчас мы с вами увидим почему.
Давайте подумаем, на что это похоже? aa, cc, 11. На какую-то систему счисления. На какую? А на 26-ричную! Почему? Потому что в английском алфавите 26 букв. Вот так вот.
Надо перевести результат, 11, из 26-ричной системы счисления в привычную нам 10-ричную.
Формула довольно простая:
X = y0 + y1 * size + y2 * size^2 yn * size^(n-1)
Здесь за size обозначен размер системы счисления (в данном случае size = 26)
yn n-ное число справа
Запомним эту формулу как, например, формула 1, она нам ещё пригодится.
Подставляем наши числа и вот что получается: 2 + 2 * 26 = 54. Теперь мы знаем, сколько символов между строкой аа и сс. Но нам нужно взять среднюю между этими двумя. Делим 54 на 2, получаем 27. Остаётся только правильно добавить к кодам аа наш результат.
Как это сделать? Вначале узнаем, сколько нужно прибавить к первому (правому) символу. Для этого получим остаток от деления 27 на 26. Получится 1. Прибавляем к а 1 получится буква b.
Теперь надо подумать, как узнать, на сколько символов надо сдвинуть второй символ.
Тут нам поможет следующая формула:
X = Y / size^(n-1) % size
По этой формуле мы можем узнать, сколько нужно добавить к определённому месту(символу, задаётся с помощью n).
Подставляем всё туда, получаем(n = 2): (27/ 26) % 26 = 1. Прибавляем. Получаем финальный результат bb.
Реализовать алгоритм на каком-либо ЯП не так сложно, когда точно знаешь, как он работает. Ниже я добавил реализацию алгоритма на языке Dart(приложение, в котором возникла данная проблема, написано на Flutter'е).
Наша реализация нахождения 'средней' строки
String getRankBetween({@required String firstRank, @required String secondRank}) { assert(firstRank.compareTo(secondRank) < 0, "First position must be lower than second. Got firstRank $firstRank and second rank $secondRank"); /// Make positions equal while (firstRank.length != secondRank.length) { if (firstRank.length > secondRank.length) secondRank += "a"; else firstRank += "a"; } var firstPositionCodes = []; firstPositionCodes.addAll(firstRank.codeUnits); var secondPositionCodes = []; secondPositionCodes.addAll(secondRank.codeUnits); var difference = 0; for (int index = firstPositionCodes.length - 1; index >= 0; index--) { /// Codes of the elements of positions var firstCode = firstPositionCodes[index]; var secondCode = secondPositionCodes[index]; /// i.e. ' a < b ' if (secondCode < firstCode) { /// ALPHABET_SIZE = 26 for now secondCode += ALPHABET_SIZE; secondPositionCodes[index - 1] -= 1; } /// formula: x = a * size^0 + b * size^1 + c * size^2 final powRes = pow(ALPHABET_SIZE, firstRank.length - index - 1); difference += (secondCode - firstCode) * powRes; } var newElement = ""; if (difference <= 1) { /// add middle char from alphabet newElement = firstRank + String.fromCharCode('a'.codeUnits.first + ALPHABET_SIZE ~/ 2); } else { difference ~/= 2; var offset = 0; for (int index = 0; index < firstRank.length; index++) { /// formula: x = difference / (size^place - 1) % size; /// i.e. difference = 110, size = 10, we want place 2 (middle), /// then x = 100 / 10^(2 - 1) % 10 = 100 / 10 % 10 = 11 % 10 = 1 final diffInSymbols = difference ~/ pow(ALPHABET_SIZE, index) % (ALPHABET_SIZE); var newElementCode = firstRank.codeUnitAt( secondRank.length - index - 1) + diffInSymbols + offset; offset = 0; /// if newElement is greater then 'z' if (newElementCode > 'z'.codeUnits.first) { offset++; newElementCode -= ALPHABET_SIZE; } newElement += String.fromCharCode(newElementCode); } newElement = newElement .split('') .reversed .join(); } return newElement;}
Но это ещё не всё
Во всяком случае, для нас это было не всё. Мы добавляли данную фичу в уже выпущенное приложение, поэтому нужна была миграция. Написать миграции для SQL проблем не составляет, а вот посчитать стандартные ранги уже не так просто. Но, зная как находится средняя строка, сделать это становится не сложно. Алгоритм будет следующий:
- задаём начало и конец промежутка(у нас это ааа и zzz соответственно)
- считаем, сколько комбинаций разных символов между строками, тут нам поможет формула 1
- теперь делим то, что получилось на максимально возможное количество элементов в списке
- итак, у нас есть шаг, есть начальная позиция, остаётся только к начальной позиции прибавить шаг, получить ранг, потом к этому рангу прибавить шаг, получить новый ранг, потом снова прибавить шаг и так далее
Всё так же на Dart'е. параметр forNumOfTasks отвечает за то, сколько позиций вы получите. Если вы проставляете позиции для списка, где сейчас всего три элемента, нет смысла рассчитывать позиции на весь список(на 50, 100 или ещё сколько-то)
Наша реализация нахождения 'дефолтных' рангов
/// modify field forNumOfTasks to get certain number of positionsListString getDefaultRank({int forNumOfTasks = TASK_FOR_PROJECT_LIMIT_TOTAL}) {final startPos = START_POSITION;final endPos = END_POSITION;final startCode = startPos.codeUnits.first;final endCode = endPos.codeUnits.first;final diffInOneSymb = endCode - startCode;/// x = a + b * size + c * size^2final totalDiff = diffInOneSymb + diffInOneSymb * ALPHABET_SIZE + diffInOneSymb * ALPHABET_SIZE * ALPHABET_SIZE;/// '~/' div without remainderfinal diffForOneItem = totalDiff ~/ (TASK_FOR_PROJECT_LIMIT_TOTAL + 1);/// x = difference / size^(place - 1) % sizefinal Listint diffForSymbols = [diffForOneItem % ALPHABET_SIZE,diffForOneItem ~/ ALPHABET_SIZE % ALPHABET_SIZE,diffForOneItem ~/ (pow(ALPHABET_SIZE, 2)) % ALPHABET_SIZE];ListString positions = [];var lastAddedElement = startPos;for (int ind = 0; ind < forNumOfTasks; ind++) {var offset = 0;var newElement = "";for (int index = 0; index < 3; index++) {final diffInSymbols = diffForSymbols[index];var newElementCode = lastAddedElement.codeUnitAt(2 - index) + diffInSymbols;if (offset != 0) {newElementCode += 1;offset = 0;}/// 'z' code is 122 if 'll be neededif (newElementCode > 'z'.codeUnitAt(0)) {offset += 1;newElementCode -= ALPHABET_SIZE;}final symbol = String.fromCharCode(newElementCode);newElement += symbol;}/// reverse element cuz we are calculating from the endnewElement = newElement.split('').reversed.join();positions.add(newElement);lastAddedElement = newElement;}positions.sort();positions.forEach((p) => print(p));return positions;}
Фуууух, устали? Самое сложное уже позади, осталось совсем немного!
Нам не очень понравилась идея с вёдрами. Объективно она хороша. Но нам не нравилась сама идея наличия алгоритма восстановления: закончились позиции восстанавливайся с помощью вёдер! Так что, никаких вёдер. Однако, ранги не бесконечные, а значит что-то придумать надо.
И мы придумали
Если места между строками не осталось, то мы решили просто добавить к нижней границе среднюю букву английского алфавита (n). Т.е. если мы захотим всунуть элемент между аа и аb, то получится aa, aan и ab. Благодаря тому, что строки сортируются поэлементно слева-направо, удлинение строки не испортит сортировку. Зато у нас появилось место для новых элементов, и это без каких-либо алгоритмов восстановления.
Этот кусочек кода можно найти также и в алгоритме нахождения средней строки.
Кусочек кода с добавлением 'среднего' символа
if (difference <= 1) { /// add middle char from alphabet newElement = firstRank + String.fromCharCode('a'.codeUnits.first + ALPHABET_SIZE ~/ 2); }
Резюме
Лексоранги показались нам отличным инструментом индексации, использование которого оптимизирует работу с БД и сервером: при изменении порядка задач необходимо обновить только одну измененную задачу.
Делитесь своим мнением по поводу лексорангов и тем, какие у Вас мысли по поводу решения подобных задач.
Ну и для всех читателей Хабра предлагаем оценить результат, который у нас получился. А также забрать себе полезный список Кодекс авторов Хабра.
Спасибо за внимание!