
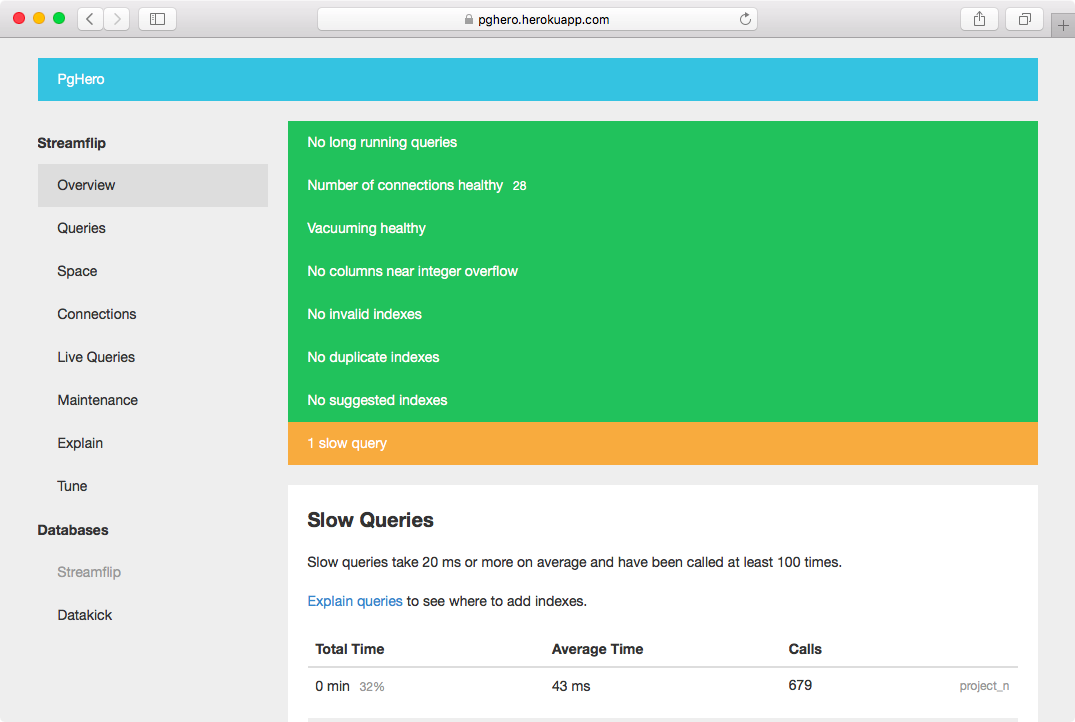
Всем привет. Сегодня я бы хотел поделиться рецептом установки утилиты PGHero с подключением нескольких баз данных. PGHero это простенькая утилита, написанная на Ruby, с минималистичным дашбордом для мониторинга производительности БД PostgreSQL.
Что может показать нам PGHero:
-
статистику по запросам: количество вызовов, среднее и суммарное время выполнения (с возможностью хранения истории);
-
активные в данный момент запросы;
-
информацию о таблицах: занимаемое на диске место, даты последних запусков VACUUM и ANALYSE;
-
информацию об индексах: занимаемое на диске место, наличие дублируемых/неиспользуемых индексов. Также может порекомендовать добавить индекс при наличии сложных запросов с Seq Scan;
-
статистику по открытым подключениям к БД;
-
вывод основных настроек БД, влияющих на производительность (shared_buffers, work_mem, maintenance_work_mem и т.д.)
Одна из очень удобных возможностей утилиты просмотр динамики среднего времени выполнения запросов (на основе статистики стандартного расширения PostgreSQL pg_stat_statements).
Выглядит это в интерфейсе PGHero вот так:

Настройка баз данных
Следующие шаги нужно проделать для каждой БД, которую мы собираемся подключать к PGHero.
Запросы нужно выполнять под суперпользователем.
-
Устанавливаем расширение pg_stat_statements (если еще не установлено):
Откройте файл postgresql.conf в текстовом редакторе и измените строку shared_preload_libraries:
shared_preload_libraries = 'pg_stat_statements'pg_stat_statements.track_utility = false
Перезапускаем сервер PostgreSQL:
sudo service postgresql restart
Создаем расширение и сбрасываем статистику:
create extension pg_stat_statements;select pg_stat_statements_reset();
-
Создаем в БД отдельного пользователя для PGHero (чтобы не давать утилите полные права над базой).
В следующем запросе заменяем эти значения в угловых скобках на свои:
<pghero_password> пароль для пользователя pghero;
<db_name> имя вашей БД;
<migrations_user> имя основной роли с доступом к текущей БД.
CREATE SCHEMA pghero;-- view queriesCREATE OR REPLACE FUNCTION pghero.pg_stat_activity() RETURNS SETOF pg_stat_activity AS$$ SELECT * FROM pg_catalog.pg_stat_activity;$$ LANGUAGE sql VOLATILE SECURITY DEFINER;CREATE VIEW pghero.pg_stat_activity AS SELECT * FROM pghero.pg_stat_activity();-- kill queriesCREATE OR REPLACE FUNCTION pghero.pg_terminate_backend(pid int) RETURNS boolean AS$$ SELECT * FROM pg_catalog.pg_terminate_backend(pid);$$ LANGUAGE sql VOLATILE SECURITY DEFINER;-- query statsCREATE OR REPLACE FUNCTION pghero.pg_stat_statements() RETURNS SETOF pg_stat_statements AS$$ SELECT * FROM public.pg_stat_statements;$$ LANGUAGE sql VOLATILE SECURITY DEFINER;CREATE VIEW pghero.pg_stat_statements AS SELECT * FROM pghero.pg_stat_statements();-- query stats resetCREATE OR REPLACE FUNCTION pghero.pg_stat_statements_reset() RETURNS void AS$$ SELECT public.pg_stat_statements_reset();$$ LANGUAGE sql VOLATILE SECURITY DEFINER;-- improved query stats reset for Postgres 12+ - delete for earlier versionsCREATE OR REPLACE FUNCTION pghero.pg_stat_statements_reset(userid oid, dbid oid, queryid bigint) RETURNS void AS$$ SELECT public.pg_stat_statements_reset(userid, dbid, queryid);$$ LANGUAGE sql VOLATILE SECURITY DEFINER;-- suggested indexesCREATE OR REPLACE FUNCTION pghero.pg_stats() RETURNSTABLE(schemaname name, tablename name, attname name, null_frac real, avg_width integer, n_distinct real) AS$$ SELECT schemaname, tablename, attname, null_frac, avg_width, n_distinct FROM pg_catalog.pg_stats;$$ LANGUAGE sql VOLATILE SECURITY DEFINER;CREATE VIEW pghero.pg_stats AS SELECT * FROM pghero.pg_stats();-- create userCREATE ROLE pghero WITH LOGIN ENCRYPTED PASSWORD '<pghero_password>';GRANT CONNECT ON DATABASE <db_name> TO pghero;ALTER ROLE pghero SET search_path = pghero, pg_catalog, public;GRANT USAGE ON SCHEMA pghero TO pghero;GRANT SELECT ON ALL TABLES IN SCHEMA pghero TO pghero;-- grant permissions for current sequencesGRANT SELECT ON ALL SEQUENCES IN SCHEMA public TO pghero;-- grant permissions for future sequencesALTER DEFAULT PRIVILEGES FOR ROLE <migrations_user> IN SCHEMA public GRANT SELECT ON SEQUENCES TO pghero;
Установка и запуск PGHero
Допустим, у нас есть три таблицы: db_one, db_two и db_three. Мы хотим по всем трем отображать статистику в PGHero (вместе с историей запросов и размеров таблиц). Важный момент: для хранения истории запросов и размеров таблиц нужно завести в одной из баз данных отдельные таблицы, где будет храниться эта статистика.
CREATE TABLE "pghero_query_stats" ( "id" bigserial primary key, "database" text, "user" text, "query" text, "query_hash" bigint, "total_time" float, "calls" bigint, "captured_at" timestamp);CREATE INDEX ON "pghero_query_stats" ("database", "captured_at");CREATE TABLE "pghero_space_stats" ( "id" bigserial primary key, "database" text, "schema" text, "relation" text, "size" bigint, "captured_at" timestamp);CREATE INDEX ON "pghero_space_stats" ("database", "captured_at");
Мы будем хранить эти таблицы в БД db_one (хотя можно завести отдельную базу для этой статистики). Далее создаем на сервере файл конфигурации pghero.yml со следующим содержимым (подставляем актуальные настройки):
# Конфигурационные урлы для наших БДdatabases: db_one: url: postgres://pghero:secret_pass@mydomain.ru:53001/db_one db_two: url: postgres://pghero:secret_pass@mydomain.ru:53001/db_two capture_query_stats: db_one db_three: url: postgres://pghero:secret_pass@mydomain.ru:53001/db_three capture_query_stats: db_one# Минимальная длительность запросов (в секундах), которые будут считаться долгимиlong_running_query_sec: 60# Минимальная длительность запросов (в миллисекундах), которые будут считаться медленнымиslow_query_ms: 250# Минимальное кол-во вызовов запросов, которые будут считаться медленнымиslow_query_calls: 100# Минимальное количество соединений для показа предупрежденияtotal_connections_threshold: 100# Таймаут для explain-запросовexplain_timeout_sec: 10# Нормализация запросов (замена значений запроса нумерованными параметрами)filter_data: true# Basic авторизацияusername: pgheropassword: secret_pass# Таймзонаtime_zone: "Europe/Moscow"
Переходим к установке. Документация предлагает нам несколько способов:
Мы будем использовать первый способ запуск в виде Docker-контейнера. Для этого в папке с файлом конфигурации pghero.yml нужно добавить Docker-файл с таким содержимым:
docker build -t mypghero .docker run -ti -p 12345:8080 mypghero
Теперь собираем образ на основе Docker-файла и запускаем контейнер на нужном порту:
docker build -t mypghero .docker run -ti -p 12345:8080 mypghero
Теперь дашборд должен быть доступен по адресу http://123.45.67.89/12345. Не забывайте про basic-авторизацию, логин и пароль мы указывали в pghero.yml.
Запуск cron-jobs для сохранения истории
Последний этап: нужно настроить автозапуск по крону скриптов для сохранения в БД истории по запросам (capture_query_stats) и размерам таблиц (capture_space_stats).
Документация рекомендует запускать capture_query_stats раз в 5 минут, а capture_space_stats раз в сутки (но тут нужно решать по ситуации). Запускаем в командной строке crontab -e и добавляем строки для запуска скриптов:
*/5 * * * * /usr/bin/docker run --rm my-pghero bin/rake pghero:capture_query_stats15 2 * * * /usr/bin/docker run --rm my-pghero bin/rake pghero:capture_space_stats
Вот и всё. Спасибо за внимание.
Демо-версию утилиты можно посмотреть здесь. Исходный код и документация.


















