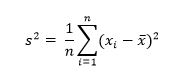Сегодня вашему вниманию представлена аналитика (исследование) алкогольной продукции сети магазинов Лента (далее - Лента), находящаяся в каталоге на официальном сайте компании.
Планирование, подготовка, выборка
Почему выбор пал на алкогольную продукцию и на эту компанию? Да
очень всё просто - первое, что пришло в голову (да, такое бывает) и
большой ассортимент данного сегмента. Думаю в дальнейшем будет
аналитика продукции других компаний. Но вернёмся к нашим
бутылкам элементам исследования. Предварительно изучив
структуру самого сайта компании приходим к выводу, что каталог
продукции динамичен в зависимости от места расположения объекта
продаж и изменением ассортимента. Выборку было решено взять по г.
Москва, в гипермаркетах. Конечно же не обладая точными данными
ассортимента алкогольной продукции компании нельзя сказать, что она
репрезентативная, но всё же полагаем, что всё ок. Изучив количество
единиц продукции в каталогах на сайте по точкам продаж получаем,
что в среднем одинаково, вотЪ.
Инструменты для аналитики
Как любой себя уважающий senior data analyst джун в нашем
исследовании мы будем применять стандартные инструменты для этого -
язык программирования python 3+, библиотеки pandas для анализа и
обработки данных, библиотеки BeautifulSoup, request, csv, lxml для
парсинга, библиотеки seaborn, matplotlib, plotly для визуализации
результата, всё это находится в нашей любимой Anaconda, в которой
JupyterLab и Jupyternotebook, плюс родные и добрые таблицы google
sheets(возможно понадобятся) и конечно же не забудем про свой
brain.
Получение данных для исследования
Данные мы будем получать конечно же с помощью нашего любимого автоматизированного процесса сбора данных (о как !) или более проще - парсинга (скрапинга). Парсинг будет осуществляться посредством скрипта на питОне (python). Для написания скрипта пришлось где-то почитать, где-то посмотреть, где-то прихватить (да простите меня товарищи). Код скрипта можно посмотреть тут.
Процесс парсинга
Итак, заходим на сайт подопытного объекта исследования и
включаем в браузере режим разработчика, находим нужные нам классы и
категории и прописываем (подставляем) их в коде.Кстати, у нас
получилось 101 страница в каталоге. Запускаем процесс парсинга в
Jupyter и ждём когда файл наполнится данными.


Процесс подготовки и обработки данных
Следующий шаг это открытие файла .csv в нашем сатурне
джупИтире и краткая информация о самом датафрейме, для этого
импортируем библиотеки, с запасом.

Как мы видим, у нас есть данные (числа) с пробелами. Поэтому, как завещал великий (ну почти) Карл Андерсон в своей книги Аналитическая культура нам нужны правильные данные, собранные правильным образом, в правильной форме, в правильном месте, в правильное время. Для этого применяем всю мощь библиотек в python для анализа. На самом деле основную работу сделал код скрипта парсинга, там был прописаны методы strip() и replace(), которые удалили лишние пробелы, переносы и символ рубля .

Пробел в числах в поле price был идентифицирован как символ \xa0 - неразрывный пробел, элемент компьютерной кодировки текстов (подробнее тут). Далее с помощью метода replace() удаляем его и с помощью astype(float) меняем формат столбцов в float и у нас получается нормальный формат цены товара.

Процесс анализа данных
Далее с помощью describe() узнаем краткие описательные статистики. Как мы видим среднее значение равное 986.78 руб. в цене без скидки, медиана равна 631.59 руб.

Построим гистограмму c помощью библиотеки matplotlib и увидим распределение, в параметрах прологарифмируем переменную. Как мы видим на гистограмме основная цена на алкогольную продукцию в пределах до 2400 руб, есть много выбросов.

Для углубленного анализа построим график boxplot от библиотеки plotly. Теперь мы видим, что подавляющее значение выбросов начинается от 2420 руб. А самым большим выбросом оказался коньяк Hennessy XO за 16209 руб. С помощью метода sort_value() узнаем пятерку самого дорогого алкоголя в Ленте.


Напомню, что цены и ассортимент динамичны, поэтому всё может изменяться каждый день.
Благодарю за внимание, всем всего наилучшего, ваш konstatic.