По прогнозам IDC, в 2024 году размер мирового рынка граничных вычислений (edge computing) достигнет $250,6 млрд, так что эта технология определенно заслуживает пристального внимания. И сегодня мы поговорим о таком ее важном аспекте, как сегментация: что это, зачем она нужна, и как реализуется.
Суть концепции edge computing физически перенести вычисления как можно ближе к конечному потребителю, чтобы предоставлять их максимально быстро и эффективно. Однако в отличие от распределенной архитектуры ЦОД, где информационный обмен между сервисами сводится к взаимодействию кластеров машин, сконцентрированных в одной локации, граничные вычисления подразумевают использование физических устройств, которые рассредоточены на обширной территории (например, банкоматы) и даже могут активно перемещаться в пространстве (складские погрузчики или беспилотные автомобили). Такое резкое увеличение парка и разнообразия устройств, образующих цифровой домен, принципиально меняет архитектурные подходы к распределенным вычислениям, см. Рис. 1.
 Рис. 1: Граничные вычисления повышают
уровень сегментации распределенных вычислений.
Рис. 1: Граничные вычисления повышают
уровень сегментации распределенных вычислений.
Критическим фактором при проектировании архитектуры граничных вычислений является сегментация: физическая, логическая и на уровне данных. В edge computing очень важно, где и как именно существуют вычислительные ресурсы, образующие домен приложения. Кроме того, если в облачных вычислениях главным предметом обеспокоенности является защита данных, то в граничных вычислениях не менее важно защищать от вредоносного вторжения и сами устройства, между которыми циркулируют данные, а количество таких устройств может исчисляться не только десятками и сотнями, но и тысячами. В самом деле, вам вряд ли понравится, если хакер подключится к умной колонке в вашей гостиной и начнет прослушивать домашние разговоры? Или, не дай бог, перехватит управление электронным ассистентом в вашем автомобиле и устроит Армагеддон прямо посреди города.
Перечисленные риски относятся к разряду вполне реальных проблем, характерных для систем граничных вычислений, и должны устраняться в обязательном порядке. К счастью, это уже сделано и главным образом за счет тщательной проработки архитектуры таких систем в аспекте сегментации.
В этой статье мы рассмотрим сегментацию граничных вычислительных сред, обсудим сопутствующие таким средам проблемы, и разберем различные подходы к сегментации: физические, логические и на уровне данных.
Проблемы на пороге
Вместе с граничными вычислениями в распределенных системах появляется ряд факторов, которые усложняют архитектурное проектирование сегментации. Если классическая среда облачных вычислений относительно однородна и состоит из дата-центров, заполненных стойками серверов x86 или мейнфреймов, которые связаны оптоволоконным Ethernet-ом и общаются по TCP/IP, то граничные вычисления выводят на арену широкий спектр устройств и коммуникационных протоколов на базе различных аппаратных архитектур и чипсетов. Одни из этих устройств, такие как банкоматы, используют стандартные процессоры x86. Другие, например, различные системы на базе микрокомпьютеров Raspberry PI, построены на архитектуре ARM. И наконец, третьи, вроде роботизированных систем или автомобилей, используют узко специализированные чипсеты.
Помимо железа взрыв разнообразия происходит и на уровне коммуникационных протоколов. Одни устройства могут напрямую подключаться Ethernet-кабелем, другие по беспроводному 802.11x, третьи через Bluetooth. И все эти устройства требуется поддерживать.
Другой важный момент обновление этих новых граничных систем. Для стандартных вычислительных устройств, таких как ноутбуки, планшеты или мобильные телефоны, обновление выполняется довольно просто, поскольку они, как правило, почти всегда доступны по сети. Но как обновить ПО на беспилотном автомобиле, который использует очень специфическое железо и протоколы, а к сети подключен отнюдь не постоянно? Это создает серьезные вызовы при проектировании ИТ-архитектуры предприятия, которые надо всесторонне учитывать. И именно поэтому в граничных вычислениях так важно тщательно прорабатывать сегментацию на физическом и логическом уровнях, а также на уровне данных.
Физическая сегментация
Физическая сегментация это про то, как разнести части распределенной архитектуры по различным физическим машинам. Как уже говорилось, в дата-центре физическая сегментация обычно сводится к размещению оборудования в серверных стойках внутри одного здания. В ситуациях, когда требуется обеспечить молниеносную связь между какими-то конкретными машинами, их надо размещать как можно ближе друг к другу. Это просто законы физики: чем меньше расстояние, тем быстрее обмен данными. Для приложений, менее требовательных в плане задержек, физическое расстояние между машинами внутри дата-центра не критично, им просто достаточно быть в одном здании.
Однако в случае граничных вычислений всё сложнее. То, где именно размещаются машины, приобретает гораздо большее значение, особенно когда домен приложения охватывает обширную географию. Большие расстояния между устройствами могут приводить к большим задержкам в коммуникационной цепочке. В таких случаях физическую вычислительную сеть надо разбивать на более мелкие сегменты.
Одна из таких моделей разбиения получила название туманных вычислений (fog computing) и подразумевает наличие промежуточных дата-центров и точек сбора данных, расположенных между устройствами IoT и главным центром обработки данных, см. Рис. 2.
 это способ сегментации физических вычислительных ресурсов между устройствами IoT и главным дата-центром.") Рис. 2: Туманные вычисления (fog
computing) это способ сегментации физических вычислительных
ресурсов между устройствами IoT и главным дата-центром.
Рис. 2: Туманные вычисления (fog
computing) это способ сегментации физических вычислительных
ресурсов между устройствами IoT и главным дата-центром.
В рамках fog-модели дата-центры зачастую выступают в роли квази-граничных устройств: они работают в частных сетях, обслуживают какую-то конкретную локацию и решают какую-то специфическую задачу.
Хорошим примером fog-архитектуры является городская система дорожных камер, которые группами подключаются к районным ЦОД в городской сети, а эти ЦОД уже подключены к главному дата-центру города. Передача данных при этом становится эффективнее, так как каждая камера подключена к fog-облаку. Однако простое перемещение данных туда и обратно имеет смысл только с точки зрения логики использования этих данных. Здесь можно добиться хорошей эффективности, если разместить критически важный программный интеллект в правильно выбранном относительно других вычислительных активов месте. И именно здесь в игру вступает сегментирование программной логики.
Сегментирование логики
Интеллект веб-приложений часто распределяется таким образом, чтобы реализовать логику пользовательского интерфейса, правила проверки и некоторых вычислительных задачи непосредственно на веб-странице или на клиентском устройстве. Вычислительная логика более сложных многоуровневых приложений, вроде покупок на сайте Amazon, реализуется в дата-центре. Во многих отношениях архитектура веб-приложений близка к традиционной архитектуре клиент-сервер.
Однако, в случае edge-вычислений веб-серверная модель сегментации логики между граничным устройством и главным дата-центром не всегда имеет смысл, особенно если граничное устройство представляет собой специализированную машину, вроде умного складского погрузчика или дорожной камеры наблюдения. Здесь сам сетевой трафик, вернее его отсутствие, может стопорить работу, например, когда погрузчик заезжает в мертвую зону и не может связаться с главным дата-центром. Поэтому выбор ответа на вопрос, где и как сегментируется логика это важное архитектурное решение.
Эмпирическое правило гласит, что на каждом физическом уровне должно присутствовать столько логики, сколько требуется для выполнения работы на этом участке. Допустим, IoT-устройство это умный складской погрузчик с геолокацией в реальном времени, который может сам находить нужный отсек на складе и забирать оттуда паллету с запрошенным товаром. В этом случае логика безопасного передвижения по складу должна быть реализована на самом погрузчике. Погрузчик не должен постоянно спрашивать сервер, как ему двигаться по складу. Кроме того, непосредственно на погрузчике должна иметься и логика его обновления. Это может быть SSH-сервер, чтобы оператор или bash-скрипт могли делать обновление. Либо это может быть подписчик системы обмена сообщениями, привязанный к расположенному в fog-облаке брокеру и получающий от него сигнал о необходимости обновить свой код и затем связывающийся с fog-сервером с помощью клиента HTTP.
Навигация по складу, выбор паллеты с нужным товаром и активное участие в обновлении своего ПО это основные функции погрузчика. А вот работа с данными клиентского заказа, к которому относится товар, к основным функциям погрузчика не относится. Поэтому соответствующая логика должна реализовываться уже в другом месте, например, на серверной миниферме на том же складе, где работает погрузчик, либо выше, где-то в частном fog-облаке, накрывающем территорию склада.
Также логично будет разграничить обработку заказов, чтобы каждый склад обрабатывал только свои заказы. Есть и следующий, более высокий уровень логики, где клиентский заказ уже отслеживаются в рамках общей картины управления цепочками поставок, и который реализуется на уровне корпоративной системы ERP, охватывающей все регионы присутствия компании, см. Рис. 3.
 Рис. 3: В архитектуре граничных
вычислений логика должна разделяться согласно ключевым функциям
уровня сегментации.
Рис. 3: В архитектуре граничных
вычислений логика должна разделяться согласно ключевым функциям
уровня сегментации.
Общий принцип логической сегментации граничных архитектур состоит в том, чтобы располагать логику как можно ближе к тем местам, где в реальной жизни происходят описываемые ею процессы. Детали реализации этого принципа на практике будут варьироваться в зависимости от домена приложения и массива задействуемых устройств. Например, смартфоны устройства многофункциональные и будут нести широкий спектр ПО, а вот специализированные устройства, вроде домашнего термостата гораздо меньше.
Умение сегментировать это одновременно и наука, и искусство. Важно понимать, что сегментация логики является важным аспектом проектирования архитектуры граничных вычислений и требует самого тщательного обдумывания и планирования, а также четкого понимания задач каждого элемента в архитектуре граничных вычислений.
Сегментирование на уровне данных
Помимо разделения логики, при организации граничных вычислений необходимо продумать и сегментацию данных. Здесь тоже нет универсальных решений и всё сильно зависит от задач, в ходе которых возникает обмен данными, а также от особенностей физической организации сети.
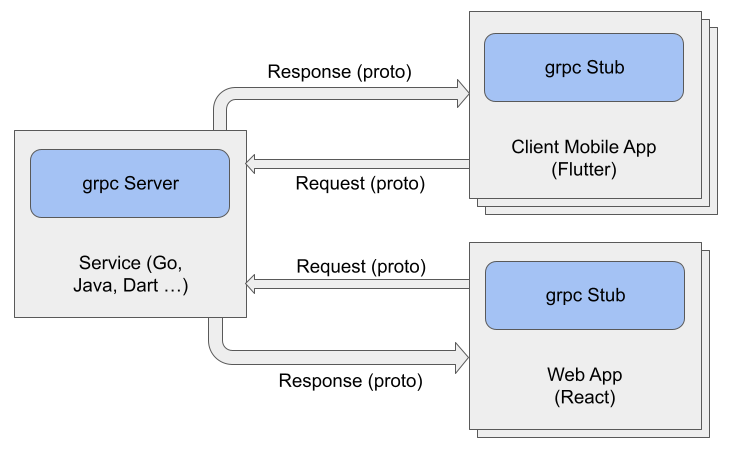
Впрочем, всегда полезно помнить, что маленькие пакеты проще передаются по сети и быстрее обрабатываются, чем большие. Преобразование данных в двоичный формат, такой как Protocol Buffers, и потоковая передача данных, такая как gRPC, обеспечивают очень быстрый обмен данными. Обратная сторона перехода на двоичные структуры данных и потоковую передачу усложнение архитектуры за счет упаковки и обработки данных. Как бы то ни было, основное правило здесь следующее: маленькие пакеты это хорошо, а потоковые данные еще лучше! Запомним это правило и вернемся к сценарию со складом и умным погрузчиком.
В этом сценарии есть три точки обмена данными: умный погрузчик, локальное частное fog-облако склада и координирующая цепочку поставок ERP-система, которая расположена в защищенном глобальном облаке.
Задача погрузчика забрать паллету с нужным товаром из складского отсека. Для этого локальное fog-облако склада отправляет погрузчику соответствующую информацию о заказе.
Причем, fog-облако отслеживает передвижения погрузчика, а также отправляет в ERP-систему данные по выполнению заказа после того, как погрузчик заберет на складе паллету с товаром и загрузит ее в грузовик для доставки клиенту.
В свою очередь, расположенная в глобальном облаке ERP отправляет складскому fog-облаку информацию по заказам, которые надо отправить клиентам. Полностью этот сценарий показан на Рис.3.
Теперь займемся сегментацией данных с учетом конечных точек.
Как происходит обмен данными в средах IoT
Начнем с погрузчика. Он, во-первых, должен отправлять в частное fog-облако свое местоположении, чтобы fog мог строить оптимальный маршрут к нужному складскому отсеку. Во-вторых, погрузчик сообщает в fog свой операционный статус, чтобы склад своевременно знал, если погрузчик вышел из строя.
Данные о местоположении и статусе очень чувствительны ко времени. Если какой-то проезд по складу оказывается заблокирован, то погрузчик должен срочно изменить свой маршрут. Или если погрузчик вдруг сломался, то заказ, который он обрабатывал, необходимо передать другому погрузчику. Погрузчик может инкапсулировать данные о местоположении, маршрутизации и состоянии в небольшие структурированные сообщения, которые непрерывным потоком передаются в складское fog-облако. Как уже говорилось, потоковые данные передаются быстро и эффективно, особенно если текст предварительно трансформируется в двоичный формат. Таким образом, сегментация данных в двоичные сообщения с потоковой пересылкой gRPC, решает поставленную задачу.
Что касается клиентского заказа, то погрузчику достаточно знать лишь ID заказа, идентификатор товара (SKU) и складской отсек, где хранится паллета с этим товаром. Эти три значения можно упаковать в очень маленькое сообщение, которое погрузчик будет получать от fog-облака. Доставку таких сообщений легко организовать с помощью типового запроса-ответа HTTP на RESTful API, а чтобы ускорить передачу информации о заказе, погрузчик и fog-облако могут общаться через двусторонний поток gRPC.
На самом деле неважно, какой транспортный метод используется в системе. Важно лишь чтобы данные, которыми обмениваются устройство IoT (в нашем случае погрузчик) и частное fog-облако, координирующее работу этого устройства на складе, сегментировались на небольшие сообщения, которые можно было отправлять и принимать очень быстро. Короче говоря, здесь прежде всего важна скорость. И именно под эту задачу и сегментируются данные.
Сегментирование данных при обмене между fog-облаком и корпоративным облаком
Сегментация данных при информационном обмене между складским fog-облаком и корпоративной системой ERP, расположенной в глобальном облаке, существенно отличается от только что рассмотренной выше, и прежде всего тем, что здесь совсем не так критичен фактор времени.
Обмен данными между устройством IoT и fog-облаком должен быть практически мгновенным, то есть измеряться миллисекундами. Обмен данными между fog-облаком и глобальной системой ERP вполне переживет задержку в секунду-две. Кроме того, системе ERP и складскому fog-облаку нужна только информация о выполнении заказа. Иначе говоря, здесь вполне возможен пакетный обмен, когда одно сообщение содержит данные сразу по нескольким заказам. В результате сообщения становятся больше, но это не страшно, поскольку на обмен информацией есть гораздо больше времени, см. рис. 4.
 Рис. 4: Сегментация данных это важный
аспект корпоративной архитектуры в средах edge computing.
Рис. 4: Сегментация данных это важный
аспект корпоративной архитектуры в средах edge computing.
Обмен данными можно упростить за счет использования стандартного HTTP через RESTful API или же передавать их потоковым методом, тут уже дело личных предпочтений. Кому-то работать через REST на уровне ERP покажется намного проще, чем создавать и поддерживать механизмы кодирования-декодирования двоичных потоков данных по открытому и постоянному сетевому соединению. Интересно отметить, что наряду с сегментацией данных с учетом специфики физической среды и решаемых задач, для успешной работы организации требуется и сегментация ИТ-специалистов по профессиональным навыкам, чтобы нужные люди были на нужных местах.
Для программирования устройств IoT требуется совсем другие навыки, чем для кодирования систем ERP, особенно при работе со специализированными IoT-устройствами с проприетарными языками программирования. И организации склонны сегментировать ИТ-разработчиков соответствующим образом. Поэтому выбор используемых API-фреймворков и форматов данных в некоторой степени определяется и наличием людей с определенными квалификациями, а не только спецификой задач, которые решаются в ходе обмена данными, и особенностями физической среды, где происходит такой обмен.
Подводим итоги
Граничные вычисления это следующий большой шаг в распределенных вычислениях. Неуклонный рост интернета вещей и все более широкое распространение коммерческих веб-приложений выводит граничные вычисления в разряд главных задач проектирования и построения ИТ-архитектур.
С граничными вычислениями современное цифровое предприятие становится гораздо сильнее. Но где сила, там и ответственность. Поэтому для развития корпоративной архитектуры важно иметь хотя бы общее представление о том, какие факторы стоят за той или иной моделью сегментации граничных вычислений. В этом посте мы лишь слегка затронули эту тему, но надеемся она послужит вам хорошей отправной точкой.