Серия из 5 постов для начинающих представляет собой ремикс первой главы книги 2015 года под названием Clojure для науки о данных (Clojure for Data Science). Автор книги, Генри Гарнер, любезно дал согласие на использование материалов книги для данного ремикса с использованием языка Python.
Книга была написана как приглашение в так называемую науку о данных, которая в последние годы получила сильный импульс к развитию в связи с потребностью в быстрой и своевременной обработке больших наборов данных локально и в распределенной среде.
Материал книги излагается живым языком и подается в задачно-ориентированном стиле, главным образом с упором на анализе данных с использованием соответствующих алгоритмов и вычислительных платформ с предоставлением коротких и прямых объяснений по ходу изложения.
Несправедливо, когда превосходный учебный материал пылится невостребованным просто из-за того, что имплементирован на достаточно академичном, если не сказать элитарном языке, каким является язык функционального программирования Clojure. Поэтому возникло желание внести свои пять копеек, чтобы сделать материал книги доступным для более широкой публики.
Три главы книги были адаптированы под язык Python в течение следующего года после издания книги, т.е. в 2016 году. Публикация ремикса книги в РФ не получилась по разным причинам, но главная из них станет понятной в конце этой серии постов. В конце заключительного поста можно будет проголосовать за или против размещения следующей серии постов. А пока же
Пост 1 посвящен подготовке среды и данных.
Статистика
Важно не кто голосует, а кто подсчитывает голоса
Иосиф Сталин
Как только перед нами возникает задача проанализировать данные, которые состоят из двух и более чисел, становится содержательным вопрос о том, каким образом эти числа распределены. Вы, наверное, уже слыхали такие выражения, как длинный хвост и правило 80/20. Они касаются разброса чисел по диапазону. В этой главе мы продемонстрируем смысл распределений и познакомим с наиболее полезным из них: нормальным распределением.
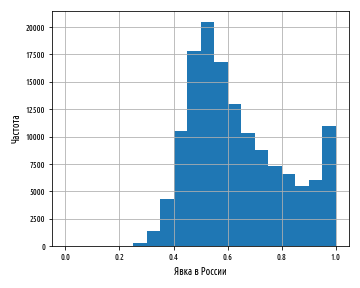
При изучении распределений чрезвычайную важность играет наглядная и удобная визуализация данных, и для этого мы воспользуемся Python-овской библиотекой pandas. Мы покажем, как пользоваться ею для загрузки, преобразования и разведывательного анализа реальных данных, а также начнем работать с фундаментальной библиотекой numpy для научных вычислений. Мы проведем сопоставительный анализ результатов двух общенациональных выборов всеобщих выборов в Великобритании 2010 г. и российских выборов депутатов Государственной Думы Федерального Собрания РФ шестого созыва 2011 г. и увидим, каким образом даже элементарный анализ может предъявить подтверждающие данные о потенциальных фальсификациях.
Примеры исходного кода для этого поста находится в моем репо на Github.
В этом посте мы будем пользоваться тремя главными библиотеками экосистемы SciPy: одноименной библиотекой SciPy для выполнения сложных математико-статистических расчетов, библиотекой pandas для загрузки данных из разнообразных источников, управления ими и их визуализации, а также библиотекой NumPy в основном для работы с массивами и матрицами.
Кроме того, мы будем пользоваться встроенными в Python модулями. Так, например, модуль random позволяет генерировать случайные числа и извлекать выборки, и модуль collections содержит дополнительные структуры данных, из которых мы воспользуемся специальным словарем Counter.
В основе библиотеки pandas лежит понятие кадра данных,
DataFrame, т.е. структуры, состоящей из строк и
столбцов, или записей и полей. Если у вас есть опыт работы с
реляционными базами данных, то таблицы pandas можно представить,
как таблицы базы данных. Каждый столбец в кадре данных поименован,
а каждая строка имеет одинаковое число столбцов, как и любая
другая. Загрузить данные в кадр данных pandas можно несколькими
способами, и тот, которым мы воспользуемся, будет зависеть от того,
в каком виде наши данные хранятся:
-
Если данные представлены текстовым файлом с разделением полей данных запятыми (.csv) или символами табуляции (.tsv), то мы будем использовать функцию чтения данных
read_csv -
Если данные представлены файлом Excel (например, файл .xls или .xlsx), то мы воспользуемся функцией чтения данных
read_excel -
Для любого другого источника данных (внешняя база данных, веб-сайт, буфер обмена данными, JSON-файлы, HTML-файлы и т. д.) предусмотрен ряд других функций
Помимо кадров данных мы будем пользоваться еще одной популярной структурой Series, т.е. рядом данных. Это одномерный массив данных, необязательно числовых, которую мы тоже будем использовать.
В этой серии постов в качестве источника данных используется
файл Excel, поэтому для чтения данных мы воспользуемся функцией
read_excel. Эта функция принимает один обязательный
аргумент файл для загрузки и ряд необязательных аргументов, в т. ч.
номер либо название листа в виде именованного аргумента. Все наши
примеры имеют всего один лист, и поэтому мы будем предоставлять
лишь один файловый аргумент в виде следующей ниже строки исходного
кода:
pd.read_excel('data/ch01/UK2010.xls')
Мы будем загружать данные из нескольких источников, поэтому мы
создадим несколько вариантов загрузки данных. В приведенном ниже
фрагменте кода мы определяем функцию загрузки данных
load_uk:
def load_uk(): '''Загрузить данные по Великобритании''' return pd.read_excel('data/ch01/UK2010.xls')
Эта функция вернет кадр данных DataFrame библиотеки
pandas, содержащий данные по Великобритании. Далее в этой главе, мы
определим дополнительные имплементации загрузки этого же и еще
одного набора данных.
Первая строка электронной таблицы UK2010.xls содержит имена
столбцов. Функция библиотеки pandas read_excel
резервирует их в качестве имен столбцов возвращаемого кадра данных.
Начнем обследование данных с их проверки атрибут кадра данных
columns возвращает имена столбцов в виде списка, при этом адресация
атрибутов осуществляется при помощи оператора точки
(.):
def ex_1_1(): '''Получить имена полей кадра данных''' return load_uk().columns
Результатом выполнения приведенной выше функции должен быть следующий ниже список полей кадра данных pandas:
Index(['Press Association Reference', 'Constituency Name', 'Region', 'Election Year', 'Electorate', 'Votes', 'AC', 'AD', 'AGS', 'APNI', ... 'UKIP', 'UPS', 'UV', 'VCCA', 'Vote', 'Wessex Reg', 'WRP', 'You', 'Youth', 'YRDPL'], dtype='object', length=144)
Это очень широкий набор данных, состоящий из 144 полей. Первые шесть столбцов в файле данных описываются следующим образом; последующие столбцы лишь распределяют число голосов по партиям:
-
Информация для Ассоциации прессы: число, идентифицирующее избирательный округ (представленный одним депутатом)
-
Название избирательного округа: стандартное название, данное избирательному округу
-
Регион: географический район Великобритании, где округ расположен
-
Год выборов: год, в котором выборы состоялись
-
Электорат: общее число граждан, имеющих право голоса в избирательном округе
-
Голосование: общее число проголосовавших
Всякий раз, когда мы сталкиваемся с новыми данными, важно потратить некоторое время на то, чтобы в них разобраться. В отсутствии подробного описания данных лучше всего начать с подтверждения наших предположений по поводу данных. Например, мы ожидаем, что этот набор данных содержит информацию о выборах 2010 г., поэтому проверим содержимое столбца года выборов Election Year.
В pandas предусмотрена обширная функциональность для горизонтального (построчного) и вертикального (постолбцового) отбора и фильтрации данных. В элементарном случае нужный столбец можно выбрать, указав его номер или имя. В этой главе мы часто будем таким способом отбирать столбцы данных из различных представлений данных:
def ex_1_2(): '''Получить значения поля "Год выборов"''' return load_uk()['Election Year']
В результате будет выведен следующий список:
0 2010.01 2010.02 2010.0...646 2010.0647 2010.0648 2010.0649 2010.0650 NaNName: Election Year, dtype: float64
Столбец года выборов возвращается в виде последовательности значений. Полученный результат бывает трудно интерпретировать, поскольку кадр данных содержит слишком много строк. Учитывая, что мы хотели бы узнать, какие уникальные значения есть в этом столбце, можно воспользоваться методом unique кадра данных. Одно из преимуществ использования библиотеки pandas состоит в том, что ее утилитные функции управления данными дополняют те, которые уже встроены в Python. Следующий ниже пример это показывает:
def ex_1_3(): '''Получить значения в поле "Год выборов" без дубликатов''' return load_uk()['Election Year'].unique()
[ 2010. nan]
Значение 2010 еще больше подкрепляет наши ожидания в отношении того, что эти данные относятся к 2010 году. Впрочем, наличие специального значения nan, от англ. not a number, т.е. не число, которое сигнализирует о пропущенных данных, является неожиданным и может свидетельствовать о проблеме с данными.
Мы еще не знаем, в скольких элементах набора данных пропущены
значения, и установив их число, мы смогли бы решить, что делать
дальше. Простой способ подсчитать такие пустые элементы состоит в
использовании подкласса словарей Counter языка Python
из модуля collections. Этот словарь трансформирует
последовательность значений в коллекцию, где ключам поставлены в
соответствие количества появлений элементов данных, т.е. их
частоты:
def ex_1_4(): '''Рассчитать частоты в поле "Год выборов" (количества появлений разных значений)''' return Counter( load_uk()['Election Year'] )
Counter({nan: 1, 2010.0: 650})
Нам не потребуется много времени, чтобы получить подтверждение, что в 2010 г. в Великобритании было 650 избирательных округов. Знание предметной области, как в этом случае, имеет неоценимое значение при проверке достоверности новых данных. Таким образом, весьма вероятно, что значение nan является посторонним, и его можно удалить. Мы увидим, как это сделать, в следующем разделе.
Исправление данных
Согласно неоднократно подтвержденной статистике, как минимум 80% рабочего времени исследователь данных тратит на исправление данных. Эта процедура заключается в выявлении потенциально поврежденных или некорректных данных и их корректировке либо фильтрации.
Специальное значение nan в конце столбца года выборов может сигнализировать о грязных данных, которые требуется удалить. Мы уже убедились, что нужные столбцы данных в pandas можно отобрать, указав их номера или имена. Для фильтрации записей данных можно воспользоваться одним из предикативных методов библиотеки pandas.
Мы сообщаем библиотеке pandas, какие записи мы хотим отфильтровать, передавая в кадр данных как аргумент логическое выражение с использованием предикативных функций. В результате будут сохранены только те записи, для которых все предикаты возвращают истину. Например, чтобы отобрать только пустые значения из нашего набора данных, нужно следующее:
def ex_1_5(): '''Вернуть отфильтрованную по полю "Год выборов" запись в кадре данных (в виде словаря)''' df = load_uk() return df[ df['Election Year'].isnull() ]
|
Press Association Reference |
Constituency Name |
Region |
Election Year |
Electorate |
Votes |
AC |
AD |
AGS |
... |
|
|
650 |
NaN |
NaN |
NaN |
NaN |
NaN |
29687604 |
NaN |
NaN |
NaN |
... |
Выражение dt['Election Year'].isnull() вернет
булеву последовательность, в которой все элементы, кроме
последнего, равны False, в результате чего будет
возвращена последняя запись кадра данных. Если Вы знаете язык
запросов SQL, то отметите, что этот метод очень похож на условный
оператор WHERE.
Присмотревшись к результатам примера ex_1_5, можно заметить, что
в полученной записи все поля (кроме одного) имеют значение
NaN. Дальнейший анализ данных подтверждает, что строка
с непустым полем на самом деле является строкой итоговой суммы в
листе файла Excel. Эту строку следует из набора данных удалить. Мы
можем удалять проблемные строки путем обновления коллекции
предикативной функцией notnull(), которая в данном
случае вернет только те строки, в которых год выборов не равен
NaN:
df = load_uk() return df[ df[ 'Election Year' ].notnull() ]
Приведенные выше строки нам почти всегда придется вызывать
непосредственно перед использованием данных. Лучше всего это
сделать, добавив еще одну имплементацию функции загрузки данных по
Великобритании load_uk_scrubbed с этим этапом
фильтрации:
def load_uk_scrubbed(): '''Загрузить и отфильтровать данные по Великобритании''' df = load_uk() return df[ df[ 'Election Year' ].notnull() ]
Теперь при написании любого фрагмента кода с описанием доступа к
набору данных в файле, можно выбирать вариант загрузки: обычный при
помощи функции load_uk либо его аналог с очисткой
данных load_uk_scrubbed. Приведенный выше пример
должен вернуть список из 650 чисел, обозначающих количество
избирателей в каждом избирательном округе Великобритании.
Внося исправления поверх загружаемых данных, мы сохраняем возможность проследить характер выполненных преобразований. В результате нам самим и будущим читателям нашего исходного кода становится понятнее, какие были внесены изменения в источник данных. Это также означает, что, как только потребуется снова запустить наш анализ, но уже с данными из нового источника, мы можем попросту загрузить новый файл, указав его вместо существующего.
Следующая часть, часть 2, серии постов Python, наука о данных и выборы посвящена описательным статистикам, группированию данных и нормальному распределению. Все эти сведения заложат основу для дальнейшего анализа электоральных данных.