Вступление
Моя основная работа связана с мобильной рекламой, и время от времени мне приходится работать с данными о мобильных приложениях. Я решил сделать некоторые данные общедоступными для тех, кто хочет попрактиковаться в построении моделей или получить представление о данных, которые можно собрать из открытых источников. Я считаю, что открытые наборы данных всегда полезны сообществу. Сбор данных часто бывает сложной и унылой работой, и не у всех есть возможность сделать это. В этой статье я представлю датасет и, используя его, построю одну модель.
Данные
Датасет опубликован на сайте Kaggle.
DOI: 10.34740/KAGGLE/DSV/2107675.
Для 293392 приложений (наиболее популярных) собраны токены описаний и сами данные приложений, включая оригинальное описание. В наборе данных нет имен приложений; их идентифицируют уникальные идентификаторы. Перед токенизацией большинство описаний были переведены на английский язык.
В датасете 4 файла:
-
bundles_desc.csvсодержит только описания;
-
bundles_desc_tokens.csvсодержит токены и жанры;
-
bundles_prop.csv, bundles_summary.csvсодержат рпзличные характеристики приложений и даты релиза/обновления.
EDA
Прежде всего, давайте посмотрим, как данные распределяются по операционным системам.

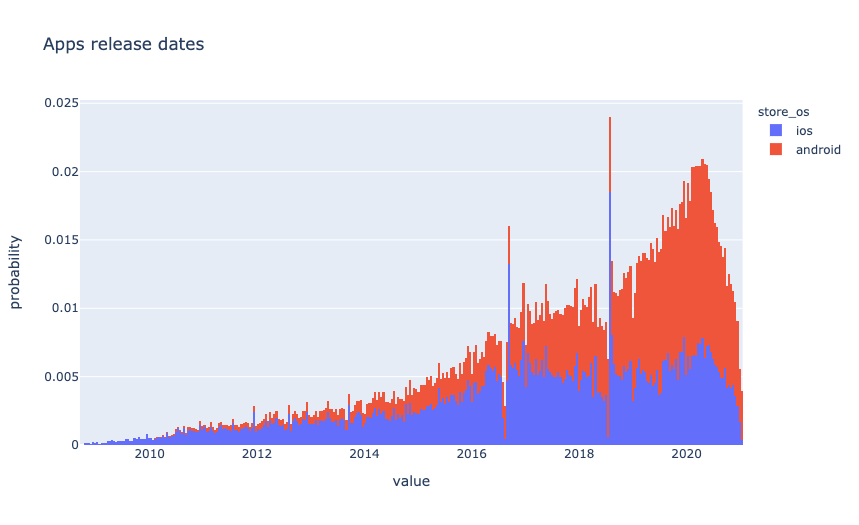
Приложения для Android доминируют в данных. Скорее всего, это связано с тем, что создается больше приложений для Android.
Учитывая, что набор данных содержит только самые популярные приложения, интересно посмотреть, как распределяется дата выпуска.
histnorm ='probability' # type of normalization
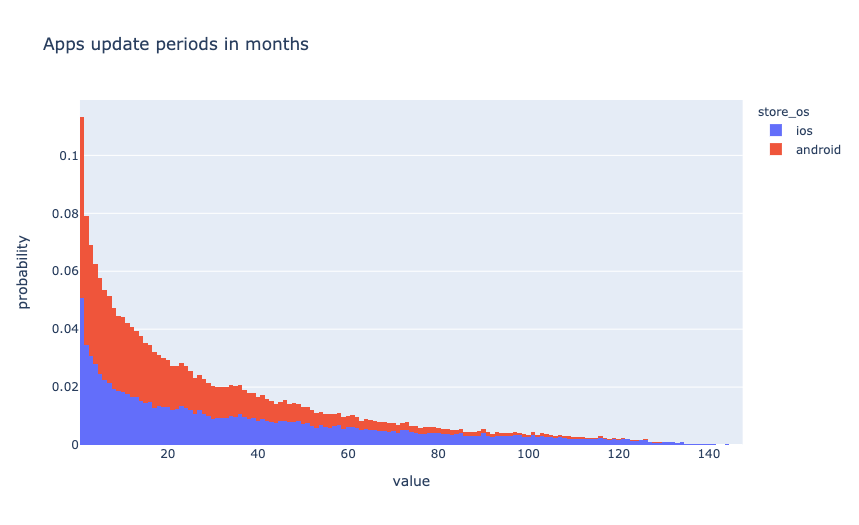
Следующий график показывает, что большинство приложений обновляются регулярно.
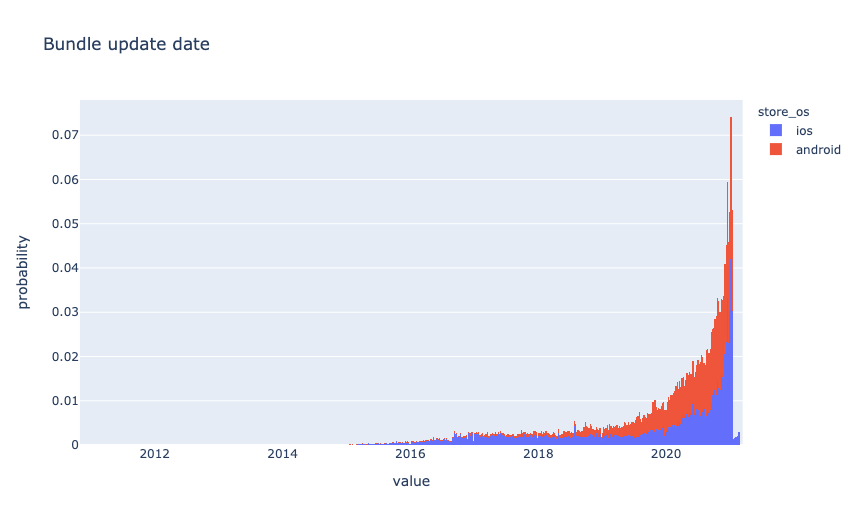
Основные данные были собраны за короткий период времени в январе 2021 года.

Добавим новую фичу - количество месяцев между датой выпуска и последним обновлением.
df['bundle_update_period'] = \ (pd.to_datetime( df['bundle_updated_at'], utc=True).dt.tz_convert(None).dt.to_period('M').astype('int') - df['bundle_released_at'].dt.to_period('M').astype('int'))у
Интересно посмотреть, как распределены жанры приложений. Принимая во внимание дисбаланс ОС, я нормализую данные для гистограммы.

Мы видим, что жанры полностью не пересекаются. Особенно это заметно в играх. Для анализа такая ситуация крайне неприятна. Что мы можем с этим поделать? Самое очевидное - уменьшить количество жанров для Android и привести их к тому же виду, что и для iOS путем сведения всех игровых жанров к одному Games. Но я полагаю, что это не лучший вариант, так как будет потеря информации. Попробуем решить обратную задачу. Для этого нужно построить модель, которая будет предсказывать жанры приложений по их описанию.
Модель
Я создал несколько дополнительных фичей, используя длину описания и количество токенов.
def get_lengths(df, columns=['tokens', 'description']): lengths_df = pd.DataFrame() for i, c in enumerate(columns): lengths_df[f"{c}_len"] = df[c].apply(len) if i > 0: lengths_df[f"{c}_div"] = \ lengths_df.iloc[:, i-1] / lengths_df.iloc[:, i] lengths_df[f"{c}_diff"] = \ lengths_df.iloc[:, i-1] - lengths_df.iloc[:, i] return lengths_dfdf = pd.concat([df, get_lengths(df)], axis=1, sort=False, copy=False)

В качестве еще одной фичи я взял количество месяцев, прошедших с даты выпуска приложения. Идея состоит в том, что на рынке в разные периоды могло быть какое-то предпочтение игровым жанрам.

Для обучения используются данные Android-приложений.
android_df = df[df['store_os']=='android']ios_df = df[df['store_os']=='ios']
Окончательный список фичей модели выглядит следующим образом:
columns = [ 'genre', 'tokens', 'bundle_update_period', 'tokens_len', 'description_len', 'description_div', 'description_diff', 'description', 'rating', 'reviews', 'score', 'released_at_month']
Я разделил данные на две части - train и validation. Обратите внимание, что разделение должно быть стратифицировано.
train_df, test_df = train_test_split( android_df[columns], train_size=0.7, random_state=0, stratify=android_df['genre'])y_train, X_train = train_df['genre'], train_df.drop(['genre'], axis=1)y_test, X_test = test_df['genre'], test_df.drop(['genre'], axis=1)
В качестве библиотеки для модели я выбрал CatBoost. CatBoost - это высокопроизводительная библиотека для градиентного бустинга на деревьях решений с открытым исходным кодом. Основным преимуществом является то, что CatBoost может использовать категориальные и текстовые фичи без дополнительной предварительной обработки. Текстовые фичи для классификации поддерживаются начиная с версии 0.19.1
В Нетрадиционный анализ тональности текста: BERT vsCatBoost я привожу пример того, как CatBoost работает с текстом и сравниваю его с BERT.
!pip install -U catboost
При работе с CatBoost рекомендую использовать Pool. Это удобная оболочка, объединяющая метки и другие метаданные, такие как категориальные и текстовые фичи. Бонусом идет снижение затрат памяти, так как не происходит дополнительная конвертация внутри библиотеки.
train_pool = Pool( data=X_train, label=y_train, text_features=['tokens', 'description'])test_pool = Pool( data=X_test, label=y_test, text_features=['tokens', 'description'])
Напишем функцию для инициализации и обучения модели. Я не подбирал оптимальные параметры; пусть это будет еще одним домашним заданием.
def fit_model(train_pool, test_pool, **kwargs): model = CatBoostClassifier( random_seed=0, task_type='GPU', iterations=10000, learning_rate=0.1, eval_metric='Accuracy', od_type='Iter', od_wait=500, **kwargs )return model.fit( train_pool, eval_set=test_pool, verbose=1000, plot=True, use_best_model=True )
Текстовые фичи используются для создания новых числовых фичей. Но для этого необходимо объяснить CatBoost, что именно мы хотим от него получить.
CatBoostClassifier имеет несколько параметров:
-
tokenizersиспользуемые для предварительной обработки фичей текстового типа перед созданием словаря;
-
dictionariesиспользуется для предварительной обработки фичей текстового типа;
-
feature_calcersиспользуется для расчета новых фичей;
-
text_processingобщий JSON-конфиг для токенизаторов, словарей и вычислителей, который определяет, как текстовые фичи преобразуются в фичи с плавающей точкой.
Четвертый параметр заменяет первые три и, на мой взгляд, самый удобный, так как в одном указывается, как работать с текстом.
tpo = { 'tokenizers': [ { 'tokenizer_id': 'Sense', 'separator_type': 'BySense', } ], 'dictionaries': [ { 'dictionary_id': 'Word', 'token_level_type': 'Word', 'occurrence_lower_bound': '10' }, { 'dictionary_id': 'Bigram', 'token_level_type': 'Word', 'gram_order': '2', 'occurrence_lower_bound': '10' }, { 'dictionary_id': 'Trigram', 'token_level_type': 'Word', 'gram_order': '3', 'occurrence_lower_bound': '10' }, ], 'feature_processing': { '0': [ { 'tokenizers_names': ['Sense'], 'dictionaries_names': ['Word'], 'feature_calcers': ['BoW'] }, { 'tokenizers_names': ['Sense'], 'dictionaries_names': ['Bigram', 'Trigram'], 'feature_calcers': ['BoW'] }, ], '1': [ { 'tokenizers_names': ['Sense'], 'dictionaries_names': ['Word'], 'feature_calcers': ['BoW', 'BM25'] }, { 'tokenizers_names': ['Sense'], 'dictionaries_names': ['Bigram', 'Trigram'], 'feature_calcers': ['BoW'] }, ] }}
Запустим обучение:
model_catboost = fit_model( train_pool, test_pool, text_processing = tpo)
 Accuracy
Accuracy Loss
Loss
bestTest = 0.6454657601

Только две фичи имеют большое влияние на модель. Скорее всего, качество можно повысить за счет использования summary, но, поскольку этих данных нет в приложениях iOS, быстро применить не удастся. Можно использовать модель, которая может получить короткий абзац текста из описания. Я оставлю это задание в качестве домашнего задания читателям.
Судя по цифрам, качество не очень высокое. Основная причина заключается в том, что приложения часто сложно отнести к одному конкретному жанру, и при указании жанра присутствует предвзятость разработчика. Требуется более объективная характеристика, отражающая несколько наиболее подходящих жанров для каждого приложения. Таким признаком может быть вектор вероятностей, где каждый элемент вектора соответствует вероятности отнесения к тому или иному жанру.
Чтобы получить такой вектор, нам нужно усложнить процесс, используя предсказания OOF (Out-of-Fold). Не будем использовать сторонние библиотеки; попробуем написать простую функцию.
def get_oof(n_folds, x_train, y, x_test, text_features, seeds): ntrain = x_train.shape[0] ntest = x_test.shape[0] oof_train = np.zeros((len(seeds), ntrain, 48)) oof_test = np.zeros((ntest, 48)) oof_test_skf = np.empty((len(seeds), n_folds, ntest, 48)) test_pool = Pool(data=x_test, text_features=text_features) models = {} for iseed, seed in enumerate(seeds): kf = StratifiedKFold( n_splits=n_folds, shuffle=True, random_state=seed) for i, (tr_i, t_i) in enumerate(kf.split(x_train, y)): print(f'\nSeed {seed}, Fold {i}') x_tr = x_train.iloc[tr_i, :] y_tr = y[tr_i] x_te = x_train.iloc[t_i, :] y_te = y[t_i] train_pool = Pool( data=x_tr, label=y_tr, text_features=text_features) valid_pool = Pool( data=x_te, label=y_te, text_features=text_features) model = fit_model( train_pool, valid_pool, random_seed=seed, text_processing = tpo ) x_te_pool = Pool( data=x_te, text_features=text_features) oof_train[iseed, t_i, :] = \ model.predict_proba(x_te_pool) oof_test_skf[iseed, i, :, :] = \ model.predict_proba(test_pool) models[(seed, i)] = model oof_test[:, :] = oof_test_skf.mean(axis=1).mean(axis=0) oof_train = oof_train.mean(axis=0) return oof_train, oof_test, models
Обучение трудозатратно, но в результате получили:
-
oof_trainOOF-предсказания для Android приложений
-
oof_testOOF-предсказания для iOS приложений
-
modelsall OOF-модели для каждого фолда и сида
from sklearn.metrics import accuracy_scoreaccuracy_score( android_df['genre'].values, np.take(models[(0,0)].classes_, oof_train.argmax(axis=1)))
За счет фолдов и усреднения по нескольким случайным разбиениям качество немного улучшилось.
OOF accuracy: 0.6560790777135628
Я созданную фичу android_genre_vec, копируем значения из oof_train для приложений Android и oof_test для приложений iOS.
idx = df[df['store_os']=='ios'].indexdf.loc[df['store_os']=='ios', 'android_genre_vec'] = \ pd.Series(list(oof_test), index=idx)idx = df[df['store_os']=='android'].indexdf.loc[df['store_os']=='android', 'android_genre_vec'] = \ pd.Series(list(oof_train), index=idx)
Дополнительно был добавлен android_genre, в котором находится жанр с максимальной вероятностью.
df.loc[df['store_os']=='ios', 'android_genre'] = \ np.take(models[(0,0)].classes_, oof_test.argmax(axis=1))df.loc[df['store_os']=='android', 'android_genre'] = \ np.take(models[(0,0)].classes_, oof_train.argmax(axis=1))
После всех манипуляций, можно наконец-то посмотреть и сравнить распределение приложений по жанрам.

Итоги
В статье:
-
представлен новый бесплатный датасет;
-
сделан небольшой EDA;
-
созданы несколько новых фичей;
-
создана модель для предсказания жанров приложений по описаниям.
Я надеюсь, что этот набор данных будет полезен сообществу и будет использоваться как в моделях, так и для дальнейшего изучения. По мере возможностей, я буду стараться его обновлять.
Код из статьи можно посмотреть здесь.