Бесспорно, интерфейс Gravitee представляет достаточно наглядные
и удобные средства визуализации работы шлюзов Gravitee. Но в любом
случае, возникает потребность предоставить доступ к этим
инструментам службе мониторинга, владельцам или потребителям API и
при этом они могут находится вне закрытого контура, в котором
расположен менеджер API. Да и иметь всю доступную информацию по
различным API на одном экране всегда удобнее.
Видеть происходящее на шлюзах, при этом не вдаваясь в особенности
пользовательского интерфейса Gravitee, а администраторам - не
тратить время на создание пользователей и разделение ролей и
привилегий внутри Gravitee.
На Хабре уже была пара статей посвященных APIM Gravitee, тут и тут. По этому, в своей заметке,
буду подразумевать, что читатель уже знаком с процессом
установки/настройки APIM Gravitee и Grafana, рассмотрю только
процесс настройки их интеграции.
Почему нельзя пойти простым путём?
По умолчанию, хранилищем для аналитики Gravitee является ElasticSearch. Информация накапливается в четырёх различных индексах, с посуточной разбивкой:
-
gravitee-request-YYYY.MM.DD - здесь хранится информация по каждому запросу (аналог access.log в nginx). Это наша основная цель;
-
gravitee-log-YYYY.MM.DD - здесь уже хранится более подробная информация о запросе (при условии, что включена отладка, см. рисунок ниже). А именно полные заголовки запросов и ответов, а также полезная нагрузка. В зависимости от настроек, логироваться может как обмен между потребителем и шлюзом, так и/или шлюзом и поставщиком API;
 Экран включения/отключения расширенного
логирования
Экран включения/отключения расширенного
логирования
-
gravitee-monitor-YYYY.MM.DD - этот нас не интересует;
-
gravitee-health-YYYY.MM.DD - этот нас не интересует.
И казалось бы, что может быть проще: подключай ElasticSearch в
качестве источника данных в Grafana и визуализируй, но не всё так
просто.
Во первых, в индексе хранятся только идентификаторы объектов, т.е.
человеко-читаемых имён поставщиков и потребителей, вы там не
увидите. Во вторых, получить полную информацию соединив данные из
двух источников непосредственно в интерфейсе Grafana, крайне
проблематично. Gravitee хранит информацию о настройках и статистику
своей работы в разных местах. Настройки, в MongoDB или PostgreSQL,
по сути статическая информация. Таким образом в одном месте у нас
(в терминах Grafana) - таблица, в другом - временной ряд.
B как же быть?
Большим преимуществом СУБД PostgreSQL является богатый набор
расширений для работы с внешними источниками данных, в том числе и
с ElasticSearch (тут). Благодаря этому
интеграция сводится к тому, что Grafana общается с единственным
источником данных - СУБД PostgreSQL, которая в свою очередь
получает данные из ElasticSearch и обогащает их информацией и
делает читаемой для администратора или любого другого
бенефициара.
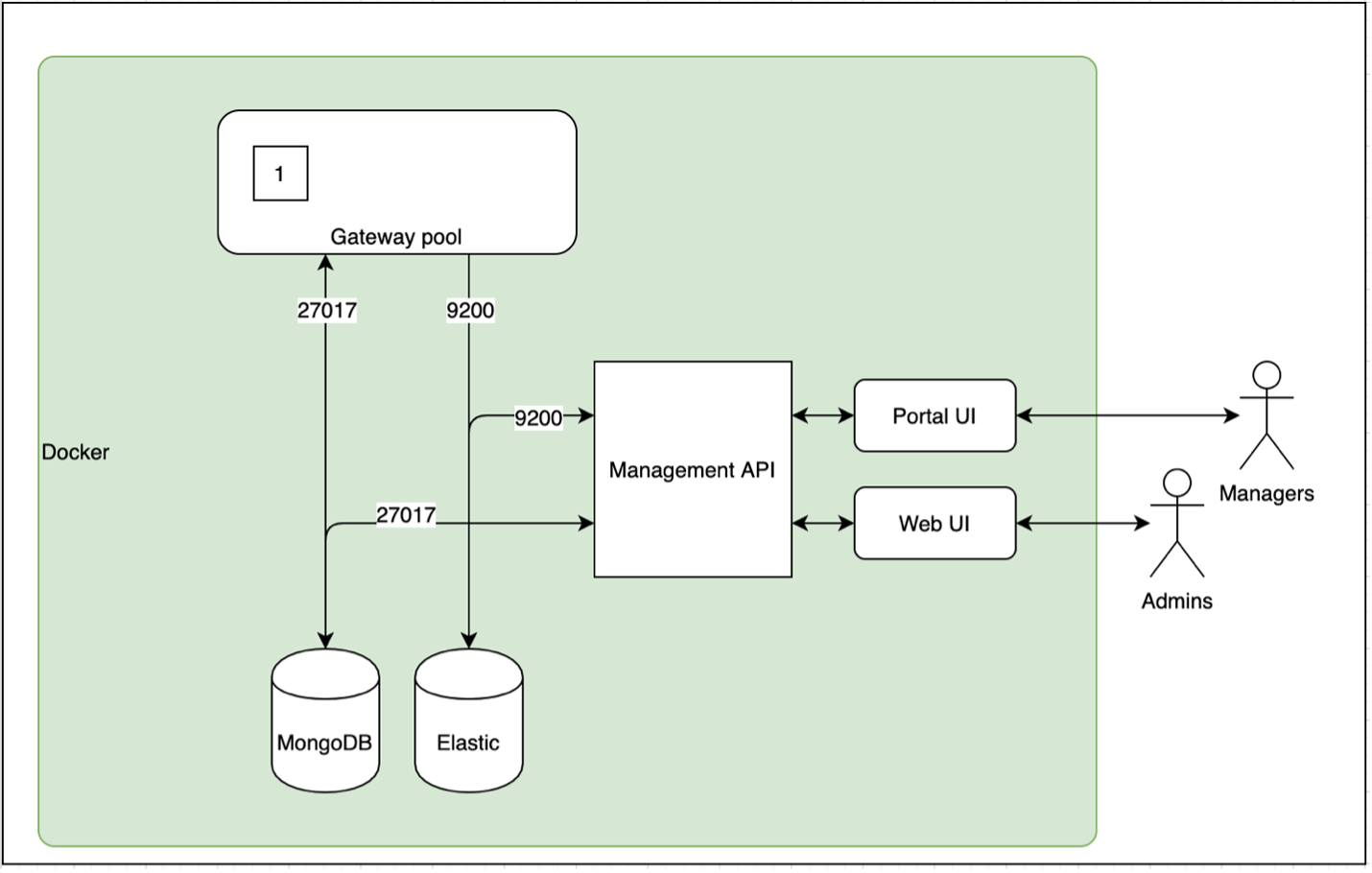
Схематически это будет выглядеть следующим образом (рисунок
ниже).
 Схема взаимодействия модулей Gravitee
Схема взаимодействия модулей Gravitee
Ну что же, за дело!
Все ниже описанные действия актуальны для следующей конфигурации: CentOS 7, APIM Gravitee 3.6, СУБД PostgreSQL 11, ElasticSearch 7.+
Начнём с интеграции PostgreSQL и ElasticSearch. Сам процесс интеграции достаточно прост и делится на следующие шаги:
-
Устанавливаем расширение multicorn11 и если не установлен pip, то ставим и его:
yum install multicorn11 python3-pip -
Далее из pip-репозитория, устанавливаем библиотеку python3 для работы с ElasticSearch:
pip3 install pg_es_fdw -
Далее, переходим к настройке PostgreSQL. Подключаемся целевой БД и добавляем расширение multicorn и подключаем необходимую библиотеку:
GRANT USAGE on FOREIGN DATA WRAPPER multicorn TO gatewaytest;GRANT USAGE ON FOREIGN SERVER multicorn_es TO gatewaytest;CREATE EXTENSION multicorn; CREATE SERVER multicorn_es FOREIGN DATA WRAPPER multicorn OPTIONS (wrapper 'pg_es_fdw.ElasticsearchFDW'); -
Выдаём права, непривилегированному пользователю. В нашем случае это logreader:
GRANT USAGE on FOREIGN DATA WRAPPER multicorn TO logreader;GRANT USAGE ON FOREIGN SERVER multicorn_es TO logreader; -
Для удобства, создадим отдельную схему logging, владельцем которой будет наш пользователь logreader:
CREATE SCHEMA logging AUTHORIZATION logreader; -
Создадим родительскую таблицу, к которой мы будем подключать новые индексы и удалять не актуальные:
CREATE TABLE logging.requests ( id varchar(36), "@timestamp" timestamp with time zone, api varchar(36), "api-response-time" int, application varchar(36), custom json, endpoint text, gateway varchar(36), "local-address" varchar(16), method int, path text, plan varchar(36), "proxy-latency" int, "remote-address" varchar(16), "request-content-length" int, "response-content-length" int, "response-time" int, sort text, status int, subscription varchar(36), uri text, query TEXT, score NUMERIC) PARTITION BY RANGE("@timestamp");Конечно же, индексы содержат больше полей, но для решения текущей задачи, приведенных выше - достаточно.
-
Для подключения и отключения индексов, создадим небольшой shell-скрипт и будем запускать его раз в сутки через cron:
#!/bin/shNEWPART=${1:-$(date +'%Y.%m.%d')}OLDPART=$(date --date='14 days ago' +'%Y.%m.%d')curl http://gateway.corp/testpsql gateway -U logreader -c "CREATE FOREIGN TABLE logging.\"requests_${NEWPART}\"PARTITION OF logging.requests FOR VALUES FROM ('${NEWPART} 00:00:00') TO ('${NEWPART} 23:59:59')SERVER multicorn_esOPTIONS (host 'els-host', port '9200', index 'gravitee-request-${NEWPART}', rowid_column 'id', query_column 'query', query_dsl 'false', score_column 'score', sort_column 'sort', refresh 'false', complete_returning 'false', timeout '20', username 'elastic-ro', password 'Sup3rS3cr3tP@ssw0rd');" psql gateway -U gatewaydev -c "drop foreign table logging.\"requests_${OLDPART}\""Немного пояснений:
-
NEWPART - текущая дата, для формирования имени партиции , при подключении нового индекса из ElasticSearch;
-
OLDPART - дата истекшего, неактуально индекса, здесь это 14 дней (определяется исходя из настроек ES Curator). Удалять партиции, ссылающиеся на несуществующие - обязательно. В противном случае запросы, к родительской таблице, будут прерываться с ошибками;
-
Вызов 'curl http://gateway.corp/test', необходим для того, что бы создавался индекс текущего дня, так как он создаётся в момент первого обращения к любому поставщику API. Если его не создать, то это будет приводить к ошибке, описанной выше. Такая проблема больше актуальна для тестовых стендов и стендов разработки;
-
Затем, создаём партицию на индекс текущего дня;
-
И на последнем шаге - удаляем неактуальный индекс.
-
Проверяем что всё работает
TABLE logging.requests LIMIT 1;Если всё правильно, то должны получить похожий результат
-[ RECORD 1 ]-----------+-------------------------------------id | 55efea8a-9c91-4a61-afea-8a9c917a6133@timestamp | 2021-05-16 00:00:02.025+03api | 9db39338-1019-453c-b393-381019f53c72api-response-time | 0application | 1custom | {}endpoint | gateway | 7804bc6c-2b72-497f-84bc-6c2b72897fa9local-address | 10.15.79.29method | 3path | plan | proxy-latency | 2remote-address | 10.15.79.27request-content-length | 0response-content-length | 49response-time | 2sort | status | 401subscription | uri | /testquery | score | 1.0 -
Рисуем графики
И вот мы подошли к тому, ради чего всё и делалось -
визуализируем статистику Gravitee. Благодаря тому, что для доступа
к аналитике используется единая точка входа, а именно СУБД
PostgreSQL, это даёт дополнительные возможности. Например, выводить
статическую информацию: количество поставщиков, количество
потребителей и их статусы; количество и состояние подписок;
параметры конфигурации для поставщика и многое другое, наряду с
динамическими данными.
В том числе хотелось бы отметить, что у поставщиков и потребителей
имеется раздел Metadata, которые можно заполнять кастомными данными
и так же выводить в дашборды Grafana.
Вот тут:
 Раздел Metadata в Gravitee
Раздел Metadata в Gravitee
А вот так это можно отобразить в Grafana:
 Вариант отображения Metadata в Grafana
Вариант отображения Metadata в Grafana
SELECT name "Наименование", value "Значение"FROM metadataWHERE reference_id='${apis}'
Пример комплексного экрана
 Вариант
комплексного экрана
Вариант
комплексного экрана
APIs (статика) - общее количество поставщиков и количество активных.
SELECT COUNT(*) AS "Всего" FROM apis;SELECT COUNT(*) AS "Активных" FROM apis WHERE lifecycle_state='STARTED';
Для Applications, запросы составляются по аналогично, только из таблицы applications
API Hits - количество вызовов по каждому поставщику. Тут уже немного по сложнее
SELECT date_trunc('minute',"@timestamp") AS time, apis.name,ee с Grafana COUNT(*)FROM logging.requests alJOIN apis ON al.api = apis.idWHERE query='@timestamp:[$__from TO $__to]'GROUP BY 1,2
Average response time by API - среднее время ответа, по каждому поставщику считается аналогичным способом.
SELECT date_trunc('minute',"@timestamp") AS time, apis.name, AVG(al."api-response-time")FROM logging.requests alJOIN apis ON al.api = apis.idWHERE query='@timestamp:[$__from TO $__to]'GROUP BY 1,2
Еще один интересный показатель Hits, by gateways, это равномерность распределения запросов по шлюзам. Считается так:
SELECT date_trunc('minute',"@timestamp") as time, al."local-address", COUNT(*)FROM logging.requests alWHERE query='@timestamp:[$__from TO $__to]'GROUP BY 1,2
 График распределения запросов по шлюзам
График распределения запросов по шлюзам
Заключение
Приведённое выше решение, по моему субъективному мнению,
нисколько не уступает стандартным средствам визуализации APIM
Gravitee, а ограничено лишь фантазией и потребностями.
Учитывая то, что Grafana, обычно является центральным объектом
инфраструктуры мониторинга, то преимущества такого решения
очевидны: более широкий охват, более высокая плотность информации и
простая кастомизация визуальных представлений.
P.S.
В ближайшее время, планируется ещё статья по интеграции Gravitee с ActiveDirectory. Процесс достаточно прост, но как всегда, есть нюансы.
Конструктивная критика, пожелания и предложения
приветствуются!