Итератор (от англ.iterator перечислитель) интерфейс, предоставляющий доступ к элементам коллекции (массива или контейнера) и навигацию по ним. В различных системах итераторы могут иметь разные общепринятые названия. В терминах систем управления базами данных итераторы называются курсорами.
В продолжение темы разработки языка программирования с необычной концепцией, публикую описание итератора для доступа к данным в декларативном стиле с очень лаконичным синтаксисом.
Ну и судя по моим наблюдениям Хабр ума палата, буду рад любым комментариям и предложениям, которые помогут протестировать или улучшить предлагаемое решение.
Стандартный итератор
В обычных языках программирования итератор реализуется довольно просто. Выбирается одно или несколько ключевых слов для операции перебора элементов итератора и описывается необходимый для его реализации интерфейс.
Например в С++ это делается с помощью конструкций вида:
for (std::list<int>::iterator it = C.begin(),end = C.end(); it != end; ++it)
Или так:
std::for_each( C.begin(), C.end(), ProcessItem );
В Python так же любой пользовательский класс тоже может поддерживать итерацию. Для этого нужно определить метод __iter__(), который и создает итератор и метод next(), который должен возвращать следующий элемент.
for value in sequence: print(value)it = iter(sequence)while True: try: value = it.next() except StopIteration: break print(value)
В Java использование итераторов выглядит примерно также.
Iterator iter = list.iterator();//Iterator<MyType> iter = list.iterator(); в J2SE 5.0while (iter.hasNext()) System.out.println(iter.next());
или даже так
for (MyType obj : list) System.out.print(obj);
Общепринятая логика у итератора следующая:
- После создания итератора, указатель сразу содержит актуальные данные
- Операции получения данных и перемещения указателя могут быть раздельными
- Большинство языков программирования поддерживают несколько управляющих конструкций с помощью которых может быть реализован перебор элементов коллекции с использованием итератора
- После завершения обхода всех элементов, итератор встает на позицию за последним элементом, тем самым делая невалидной операцию чтения данных
Концепция итератора для нового языка
Как и любому языку программирования, в новом языке так же требуется обеспечить способ навигации по коллекциям объектов (элементам списков/массивов). Поэтому при проектировании синтаксиса мне тоже пришлось задуматься над реализацией данного функционала. Причем, основная сложность возникла не с реализацией, а с записью самой операции при работе с итератором в исходном коде из-за специфических требований к синтаксису языка, а именно из-за отсутствия в языке зарезервированных ключевых слов.
Более того, при разработке языка программирования, мне хотелось унифицировать доступ не только к локальным свойствам объектов или элементам коллекций, но и использовать этот же механизм для доступа к внешним данным, включая записи в реляционных БД.
В большей степени из-за необходимости работать с объектами из базы данных, так же как с локальными объектами, итоговая концепция итератора немного (или наоборот много) отличается от общепринятой классической, вынесенной в заголовок статьи.
- При создании итератор не содержит актуальных данных, только необходимые параметры доступа к ним. Фактически, это можно интерпретировать как положение указателя на позиции перед первым элементом. А реальная инициализация итератора происходит только при сбросе, который выполняется неявно при выполнении первого чтения данных.
- Перемещение указателя на следующий элемент выполняется всегда после получения новой порции данных автоматически. Если необходимо оставлять курсор на текущей позиции (т.е. считывать одни и те же данные постоянно), то после каждого чтения необходимо возвращать позицию курсора назад, на количество реально считанных данных.
- После завершения обхода коллекции, указатель итератора остается на последней позиции данных, а не переходит за последний элемент как в случае с классическими итераторами. Это сделано для того, чтобы операция чтения данных у завершившегося итератора всегда была валидной. Конечно, кроме того случая, когда данные отсутствуют изначально.
Для чего выбрана такая логика работы с итератором?
Создание итератора
В случае реализации доступа к локальным данным внутри приложения, нет никаких причин разделять создание итератора и получение указателя на его первый элемент. Особенно в компилируемых языках (например С++), в которых итератор может быть реализован обычной ссылкой на элемент данных. В таких случаях, как правило, проблем при создании итератора не предвидится.
Однако, в случае создания итератора на основе, например файла, уже могу возникнуть ошибки. Причем как во время создания итератора (файл отсутствует или недостаточно прав доступа), так и во время получения следующего элемента данных (например, при ошибке чтения файла). Естественно, данные ситуации приходится обрабатывать на уровне исходного кода программы, либо внутри объекта, либо уже при использовании итератора, например ловя возникающие исключения.
Но в случае с базами данных ситуация становится еще интереснее. Кроме обработки возможных ошибок, требуется еще предусмотреть возможность указания различных параметров при создании итератора. Например, с учетом фильтрации данных, их сортировки или для оптимизации скорости выполнения запроса. Конечно и при файловых операциях это тоже может потребоваться, но при создании итератора тут мало что можно сделать. А вот в случае работы с курсором базы данных, можно предусмотреть создание итератора с учетом имеющихся индексов или внешних связей у таблиц.
Именно из-за этих особенностей было решено отделить создание итератора (в случае работы с базой данных, это будет описание способа доступа к данным из таблиц), от фактического доступа к данным, т.е. к первому элементу из всего набора. Поэтому, во время создания итератора, доступ к первому элементу данных не выполняется. Он происходит только при сбросе итератора, который может выполняться автоматически при первом чтении данных.
Автоматическое перемещение итератора
Как было указано выше, перемещение внутреннего указателя на следующий элемент данных выполняется всегда и автоматически, а если необходимо оставлять курсор на текущей позиции (т.е. считывать одни и те же данные постоянно), то после каждого чтения необходимо возвращать позицию курсора назад, на количество реально считанных данных. Фактически это повторяет логику работы итератора в Python (т.е. выполнение метода next).
Такое поведение было выбрано из-за желания сделать работу с итератором как можно более лаконичной. Ведь тогда в подавляющем большинстве случаев для его использования можно будет обойтись всего одной операцией получением данных, и при её успешном выполнении, внутренний указатель будет перемещаться на следующую порцию данных без необходимости выполнять данную операцию явно.
Завершение работы итератора
Вы наверно уже обратили внимание на кажущееся нелогичным поведение итератора при завершении обхода коллекции. Ведь если указатель итератора всегда будет оставаться на последней позиции данных и не будет переходить за последний элемент как в случае с классическими итераторами, то определить конец завершения данных с помощью операции чтения становится невозможно!
Эта особенность работы итератора вытекает из желания унифицировать его интерфейс для доступа к любым данным, а не только к элементам данных из перечисляемых коллекций.
Другими словами, если использовать такое поведение итератора, то при получении текущего значения становится неважно, к каким данным происходит обращение и использовать интерфейс итератора можно даже при обращении к обычным переменным (не коллекциям)!
Просто в этом случае всегда будет возвращаться её актуальное значение. Конечно, последующее перемещение курсора на очередной элемент данных не произойдет, но сами данные с точки зрения логики работы итератора будут корректны.
Синтаксис лаконичного итератора
Если в обычных языках программирования работа с итератором происходит за счет использования зарезервированных ключевых слов или стандартных управляющих конструкций, то в моем случае этот способ не подходит.
Так как концепция языка предполагает полный отказ от предопределенных ключевых слов, а способ использования итератора должен быть описан в синтаксисе языка, то с реализацией итератора для декларативного синтаксиса, возникают некоторые сложности. В итоге после нескольких тестов и экспериментов я остановился на следующем.
Довольно часто в различных языках программирования встречается управляющая конструкция вида name? или ?name. При этом интуитивно понятно, что требуется вывести значение переменой в консоль или отладочный лог. Причем, данная конструкция выглядит очень естественно и согласуется с привычным использованием данного знака препинания (знак вопроса).
И приняв это за отправную точку, операция чтения данных из итератора в декларативном стиле получается следующая:
? итератор возвращает весь набор элементов из коллекции в виде массива. Коллекция возвращается полностью, независимо от текущего положения курсора. Фактически, это означает, что перед каждым выполнением данного оператора, у итератора выполняется операция сброса в начальное состояние. Так же, с помощью конструкции вида ?(...) можно считывать произвольное количество возвращаемых элементов, например для пагинации.
! итератор возвращает один текущий объект из коллекции и переводит указатель на следующий элемент (сброс/инициализация итератора выполняется неявно и автоматически при обращении к первого элементу). В данном случае, операция чтения итератора возвращает именно сам элемент, а не массив с одним элементом. Если необходимо считать элемент данных как элемент массива, то необходимо использовать конструкцию ?(1).
При использовании только этих двух операторов нельзя вручную проверить завершение элементов в коллекции, но это делать и не требуется, так как в декларативном синтаксисе языка отсутствуют операторы для проверки условий, а перебор элементов и проверка итератора на завершение данных выполняется автоматически.
Хотя при необходимости, количество операторов для работы с итераторами может быть расширено. Например можно добавить оператор "!-" или "!!", который будет считывать один элемент данных и возвращать указатель на одну позицию назад, а оператор "??" считывать только остаток коллекции без принудительного сброса указателя в начало перед чтением данных.
Примеры использования
Мне кажется, что синтаксис получения данных с помощью итератора получился понятным, несмотря на его лаконичность, за счет использования близких по смыслу или по написанию знаков препинания.
Таким образом, конструкция name? будет означать создание итератора и вывод всех элементов коллекции, причем слева от итератора указываются параметры его создания. В общем случае, это будет класс терминов для чтения или имя функции/переменной. Дополнительно, в качестве аргументов можно задать и другие параметры, например для фильтрации терминов по заданным критериям: human(sex=man)?, но это уже зависит от реализации конкретного итератора.
Вообще все термины можно вывести с помощью конструкции "@term?", т.к. любой термин является производным от базового класса term, поэтому строки human(sex=man)? и "@term(class=human, sex=man)?" будут эквивалентны.
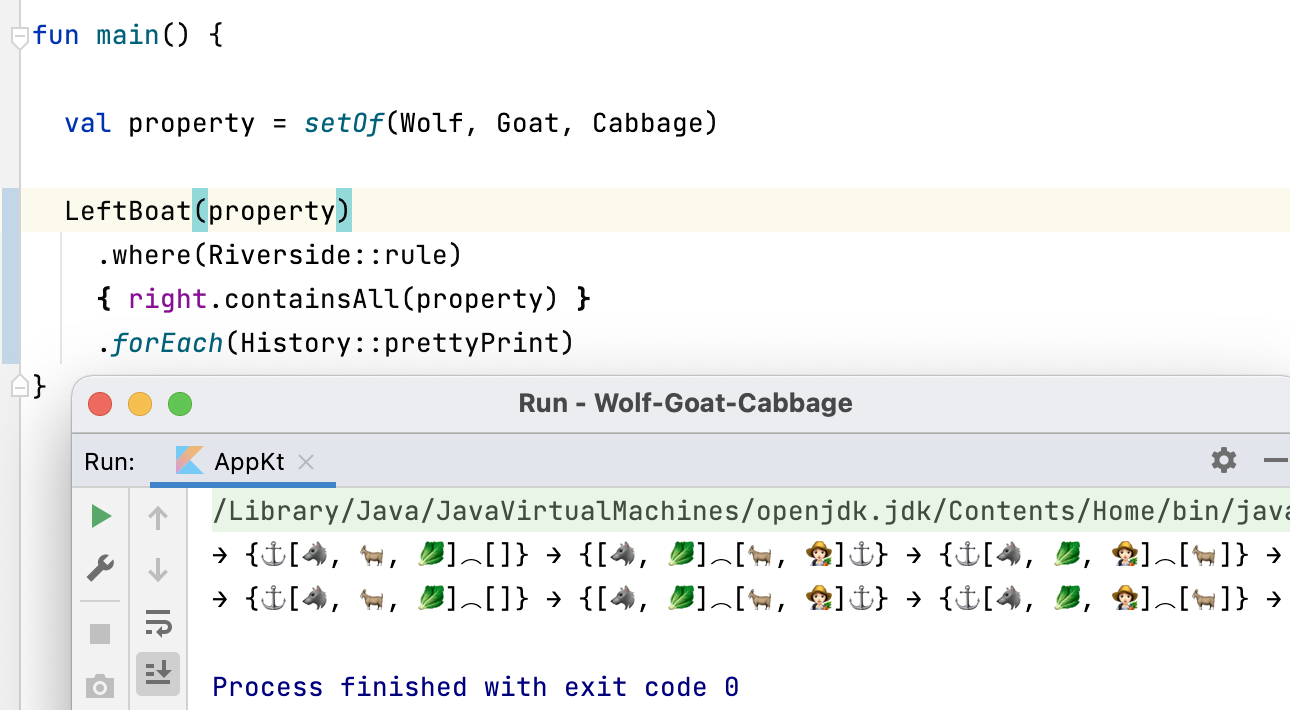
Надеюсь, сейчас стало более понятно, что делают итераторы в примере из предыдущей статьи:
Необычная концепция синтаксиса языка программирования
human::brother(test=human!) &&= $0!=$test, $0.sex==male, @intersec($0.parent, $test.parent);human.brother?