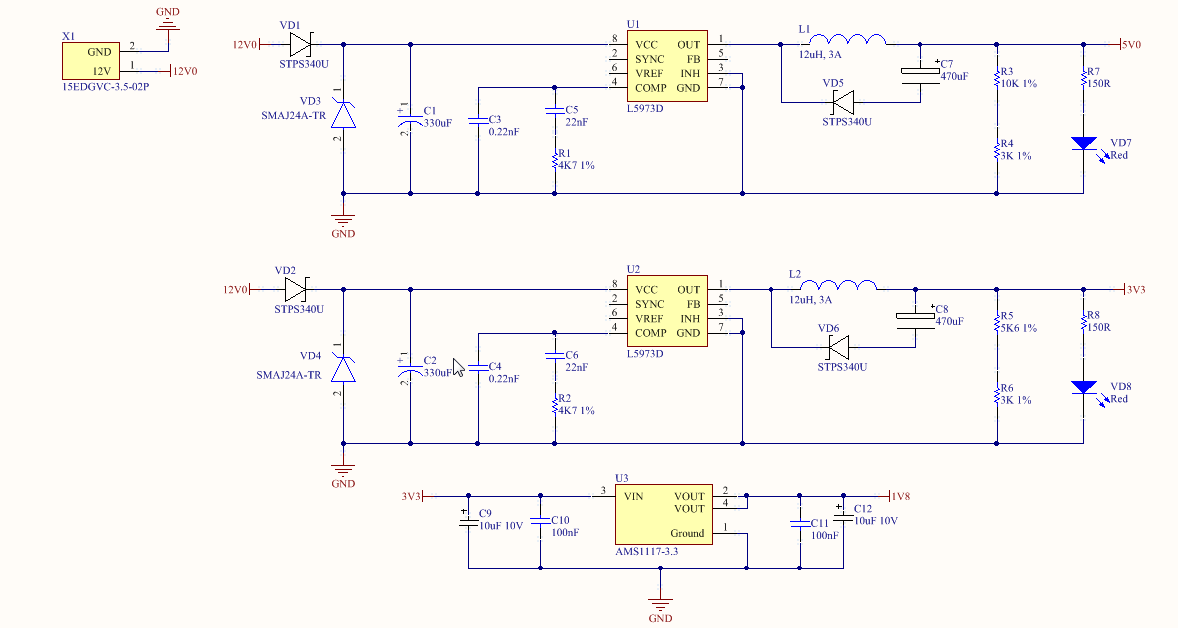
1. Адаптированная методология Anchor modeling
Архитектура ядра хранилища данных должна соответствовать описанной ниже адаптированной (не оригинальной) методологии Anchor modeling (но не Data Vault).
|
Тип таблицы |
Примеры имени таблицы (в скобках описание) |
С таблицами каких типов может быть связана |
Обязательный тип поля |
Примеры имени поля |
|
Сущности (Anchor, Entity type). Обозначается квадратом |
TR_Transaction (полупроводка по дебету или по кредиту), AC_Account (синтетический счет) |
Связи, Атрибут сущностей |
Суррогатный ключ сущности |
TR_ID, AC_ID |
|
Атрибут сущностей (Attribute). Обозначается кругом |
TR_TDT_TransactionDate (дата заключения сделки) |
Сущности |
Суррогатный ключ сущности (является первичным ключом в течение срока действия записи) |
TR_ID |
|
Дата и время начала срока действия записи |
TR_TDT_FROM |
|||
|
Дата и время окончания срока действия записи (не включительно) |
TR_TDT_BEFORE |
|||
|
Атрибут сущностей |
TR_TDT |
|||
|
Связи (Tie, Relationship). Обозначается ромбом |
TR_AC_DC_Transaction_Account_DrCr (счет главной книги в полупроводке) |
Сущности |
Суррогатные ключи каждой связанной сущности (вместе с некоторыми атрибутами связей, обозначающими тип связи, образуют составной ключ в течение срока действия записи) |
TR_ID, AC_ID |
|
Дата и время начала срока действия записи |
TR_AC_DC_FROM |
|||
|
Дата и время окончания срока действия записи (не включительно) |
TR_AC_DC_BEFORE |
|||
|
Опциональный атрибут или несколько атрибутов связей |
DC (дебет/кредит) |
 Схема данных примера
Схема данных примера
Таблицы связей связывают сущности отношениями многие-ко-многим или один-ко-многим. Таблицы связей должны соединять минимально возможное количество сущностей и атрибутов связей за счет увеличения количества таблиц связей. Например, вместо связывания в одной таблице связей полупроводки с синтетическим счетом, с контрагентом, с продуктом или финансовым инструментом и т.д. необходимо связывать полупроводку с каждым из этих типов сущностей отдельной таблицей связей. Если не следовать этому принципу, то разбухшая таблица связей превратится в таблицу фактов в денормализованной схеме звезды со всеми ее недостатками.
В оригинальной методологии Anchor modeling атрибуты связей запрещены, но они иногда могут быть полезными для упрощения структуры данных и ее лучшего соответствия реальному миру. Также в оригинальной методологии Anchor modeling используются более длинные и неудобные имена таблиц и полей.
В ядре хранилища данных не должны использоваться значения NULL, за исключением тех атрибутов связей, которые не входят в составной ключ (обычно это наименования, обозначения, коды, ссылки, выбранные значения, флаги). Если неизвестны начало и/или окончание срока действия записи, то должны указываться принятые условные даты (например, '0001-01-01', '-infinity', '9999-12-31', 'infinity').
Для облегчения создания полиморфных связей двухсимвольный код в именах должен совпадать с двумя последними символами в соответствующих суррогатных ключах, которыми обозначается тип сущностей или атрибут связей (см. ниже). Поэтому в нем необходимо использовать символы алфавита Crockford's base32.
Таблицы типа узел (knot) исключены из адаптированной методологии Anchor modeling. Однако типовое обозначение узла на схеме в виде квадрата с закругленными углами удобно использовать для обозначения атрибутов связей.
Набросок БД может быть сделан (в том числе, офлайн) с помощью наглядных и удобных веб-инструментов Online Modeler или Online Modeler (test version), но сгенерированный ими SQL-код непригоден для использования. Для генерации SQL-кода (включая SQL-запросы) по методологии Anchor modeling все известные компании используют самостоятельно разработанные ими инструменты на основе языка программирования Python и Microsoft Excel.
2. Суррогатные ключи в адаптированном формате ULID
Для связи таблиц должны использоваться исключительно суррогатные ключи в адаптированном формате ULID. Для связи таблиц не должны использоваться автоинкремент, составные ключи и хеши бизнес-ключей.
В качестве суррогатного ключа должна использоваться адаптированная (не оригинальная) версия ULID (но не UUID), имеющая любой из двух форматов:
-
ttttttttttrrrrrrrrrrrrrrxx (пример: 01F5B023PBG3C48TSBDQQ3V9TR)
-
ttttttttttsssrrrrrrrrrrrxx (пример: 01F5B023PB00448TSBDQQ3V5TR)
где
t дата и время генерации с точностью до миллисекунды (Timestamp) (10 символов или 48 бит), UNIX-time в миллисекундах (UTC)
s счетчик от 0 до 32768, сбрасываемый каждую миллисекунду, (Sequence) (3 символа или 15 бит)
r случайное число (Randomness) (14/11 символов или 65/55 бит)
x тип сущностей (Entity type) (2 символа или 10 бит)
Должна использоваться кодировка и алфавит Crockford's base32.
Генератор ULIDов должен удовлетворять следующим требованиям:
-
Соблюдение требуемого формата ULIDов
-
Однократное использование каждого генерируемого ULIDа в качестве суррогатного ключа сущности
-
Использование (достаточно производительного) криптографически стойкого генератора псевдослучайных чисел или генератора истинно случайных чисел
-
Монотонное возрастание ULIDов в интервале менее миллисекунды (за счет инкремента случайного числа для формата без счетчика, или за счет счетчика для формата со счетчиком)
-
Генерация ULIDов в формате (текстовый, бинарный, UUID или целочисленный), наиболее производительном для операций поиска в применяемых СУБД и носителе данных (HDD или SSD)
-
Пиковая (в течение 5 мс) производительность генерации ULIDов должна быть выше максимальной производительности записи в применяемых СУБД и носителе данных (HDD или SSD) (например, за счет буферизации заранее вычисленных частей ULIDа)
Данные из информационных систем-источников должны загружаться в хранилище данных уже с необходимыми именами полей и с суррогатными ключами, имеющими описанный выше формат. В хранилище данных эти ключи не должны изменяться, подменяться другими ключами или переименовываться.
3. Указание начала и окончания срока действия записи
Для сохранения историчности данных должен применяться второй тип медленно меняющегося измерения SCD2 с добавлением двух унифицированных полей (столбцов): Дата и время начала срока действия записи (имя столбца с суффиксом _FROM) и Дата и время окончания срока действия записи (не включительно) (имя столбца с суффиксом _BEFORE).
Единственным условием связи записей в таблицах, помимо суррогатного ключа, должно быть одновременное действие (valid time) связанных записей, определяемое унифицированными полями начала и окончания срока действия записи, но не датой загрузки в систему или датой создания записи (transaction time). Данные не должны храниться в форме срезов на отчетные или на текущую дату или за календарный период (например, месяц).
4. Указание даты и времени создания записи
Если нужно знать не только изменение состояния реального мира во времени, но и изменение состояния самой учетной системы (когда в учетной системе изменяются сведения об одном и том же моменте в реальном мире), то во все таблицы необходимо добавить поле с датой и временем создания записи (transaction time), являющееся частью составного ключа. Чтобы точно воспроизвести отчет, сформированный в определенный момент в прошлом, достаточно игнорировать записи, чьи дата и время создания позднее этого момента в прошлом.
Примеры имени поля: TR_TIMESTAMP, TR_TDT_TIMESTAMP, TR_AC_DC_TIMESTAMP.
5. Только внешние источники пунктов классификаторов
В учетной системе необходимо использовать пункты классификаторов (статьи доходов и расходов, синтетические счета, категории клиентов, типы продуктов и т.п.), полученные непосредственно из реального мира без каких либо изменений вместо разработки собственных или соединения в гибридных классификаторах. Пункты классификаторов могут быть получены из законодательства, из требований топ-менеджмента к отчетам и т.п.
Если при загрузке свежей версии классификатора изменился (исчез, появился) пункт классификатора, то должны автоматически рассчитываться и указываться окончание срока действия прежней запаси, а также начало и окончание действия новой записи.
6. Фасетная классификация
Необходимо по возможности использовать фасетную классификацию вместо иерархической классификации.
Если всё же приходится использовать иерархический справочник из внешнего источника, то для него нужно создать соответствующие справочники фасетной классификации. При этом каждый пункт из иерархического справочника становится сущностью, а каждый пункт из справочника фасетной классификации атрибутом этой сущности.
Например, пятизначные счета второго порядка в плане счетов российских кредитных организаций должны быть самостоятельными сущностями, а не атрибутами двадцатизначных лицевых счетов. К счетам второго порядка можно привязать соответствующие значения атрибутов, не образующих составной ключ:
-
признак счета активный/пассивный,
-
глава,
-
раздел,
-
счет первого порядка,
-
тип контрагента,
-
срок.
7. Теги
Если есть большое количество атрибутов с логическими значениями true и false, то эти атрибуты удобнее заменить соответствующими тегами, которые можно хранить в одном поле типа array, типа hstore или типа jsonb.
8. Полиморфные связи
В некоторых учетных системах необходима возможность связывать определенную таблицу (будем называть ее основной) с большим количеством других таблиц, причем эти связи используются редко. Например, таблица полупроводок должна иметь большое количество субконто или аналитик, каждая из которых редко используется в отчетах.
Однако использование таблиц связей в таких случаях нежелательно, так как их будет слишком много, и на их поддержание будет затрачиваться слишком много ресурсов IT-подразделения.
Решить эту проблему можно с помощью полиморфных связей. В основной таблице в поле полиморфных связей ищется суррогатный ключ записи, содержащейся в связанной таблице, а по двум последним символам в этом суррогатном ключе определятся таблица с типом Сущности. Связь автоматически устанавливается с записью в этой таблице, имеющей соответствующий суррогатный ключ.
Если полиморфные связи необходимы одновременно с несколькими таблицами, то суррогатные ключи записей в этих связанных таблицах можно хранить в основной таблице в одном поле типа array, типа hstore или типа jsonb.
9. Устранение витрин данных
Каждый отчет должен формироваться непосредственно из реплики ядра хранилища данных.
Нежелательно использовать витрины данных, так как они сводят на нет все достоинства методологии Anchor modeling. Особенно большими недостатками обладают универсальные витрины данных, предназначенные для формирования любых видов отчетности.
10. Типовые SQL-запросы и материализованные представления
Разработка SQL-запросов к базе данных, соответствующей методологии Anchor modeling, трудоемка. Поэтому для облегчения работы системных аналитиков и SQL-программистов могут быть созданы типовые SQL-запросы или материализованные представления, соединяющие сущности с их атрибутами на задаваемую дату. Но использование таких SQL-запросов и материализованных представлений может привести к усложнению БД и снижению производительности. Поэтому для рабочей системы вместо них необходимо использовать автоматическую генерацию SQL-запросов (с использованием языка программирования Python и Microsoft Excel).
В качестве источника значений для заполнения полей могут использоваться соответствующие SQL-запросы, материализованные представления или созданные на их основе таблицы допустимых значений. Допустимые значения для заполнения полей могут определяться и таблицей решений (см. ниже).
Сильная нормализация данных в Anchor modeling не позволяет производить многие автоматические проверки целостности на уровне таблиц. Поэтому для проверки целостности и качества данных нужны соответствующие SQL-запросы, автоматически запускаемые перед вставкой данных в таблицы.
11. Вынесение логики из программного кода в таблицы решений
Логику необходимо по возможности выносить из программного кода на языках программирования, SQL и различных ORM в таблицы решений. Например, в таблице решений может быть закодирован выбор дебетуемого синтетического счета в зависимости от типа операции, категории контрагента и срока погашения финансового инструмента. Таблица решений может быть реализована двумя способами:
-
таблица сущностей правил, к которой привязаны входные атрибуты и один выходной атрибут,
-
таблица связей, соединяющая входные сущности и атрибуты с выходной сущностью либо с выходным атрибутом.
Первый способ очевидно более гибкий и упорядоченный.