
Привет, меня зовут Маша, я работаю маркетинговым аналитиком в Ozon. Наша команда "питонит" и "эскьюэлит" во все руки и ноги во благо всего маркетинга компании. Одной из моих обязанностей является поддержка аналитики для команды медийной рекламы Ozon.
Медийная реклама Ozon представлена на разных площадках: Facebook, Google, MyTarget, TikTok и другие. Для эффективной работы любой рекламной кампании необходима оперативная аналитика. В данной статье речь пойдет о моём опыте сбора рекламных данных с площадки TikTok без посредников и лишних заморочек.
Задача на сбор статистики: вводные
У команды медийной рекламы Ozon есть бизнес-аккаунт TikTok, в котором они управляют всей рекламой на этой площадке. Они долго терпели, сами собирали данные из рекламных кабинетов, но всё-таки настало время, когда терпеть уже больше было нельзя. Так у меня появилась задача на автоматизацию сбора статистики из TikTok.
У нас в базах уже были данные о заказах по кампаниям из TikTok, для эффективной аналитики не хватало данных о расходах.
Итак, весь процесс от "нам нужны данные по расходам из TikTok" до "у нас есть данные по расходам из TikTok" разделился для нас на следующие этапы:
-
регистрация аккаунта разработчика,
-
создание приложения,
-
авторизация бизнес-аккаунта в приложении,
-
запрос, получение, обработка и загрузка данных.
Рассмотрим каждый из этапов подробнее.
Регистрация разработчика
Мы зарегестрировали аккаунт разработчика на нашего бизнес-менеджера. Перешли на портал TikTok Marketing API, нажали на "My Apps", далее кликнули на "Become a Developer", и началась череда заполнения форм.

TikTok не Facebook, у нас ничего ни разу не отклонял, но всё равно мы были очень внимательны при заполнении полей и не добавляли то, что нам не нужно прямо сейчас. Например, в поле "What services do you provide?" добавили только "Reporting".
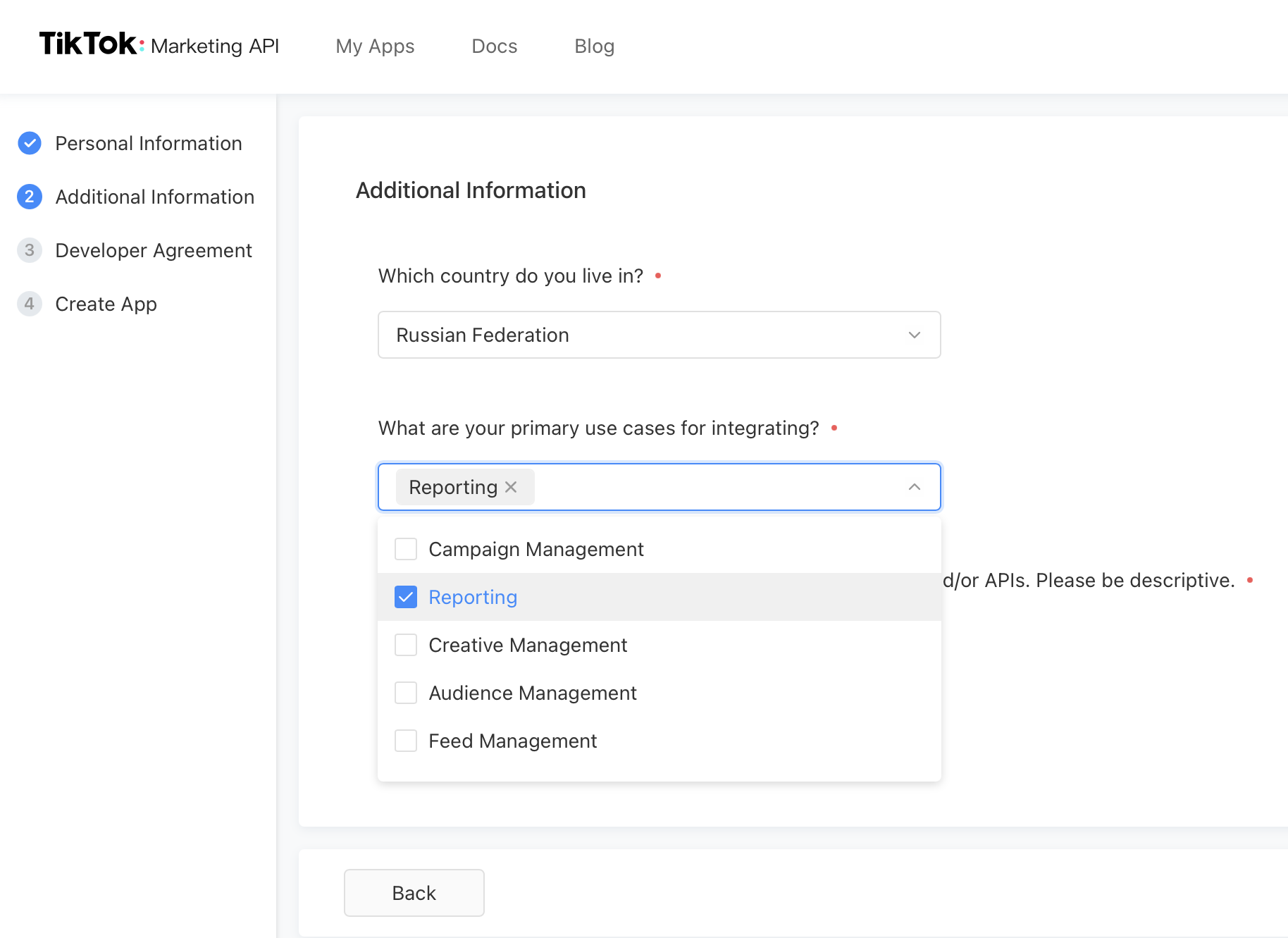
Последним пунктом был "Create App". Процесс создания аккаунта разработчика и приложения в первый раз происходит вместе.
Создание приложения
Заполняем имя и описание приложение, callback-address. Далее нужно выбрать разрешения, которые приложение будет запрашивать у авторизирующегося в нем аккаунта. Так же, как и при заполнении полей для аккаунта разработчика, выбрали только пункт "Reporting". Указали ID рекламного аккаунта. После этого отправили приложение на проверку.

Как сообщает TikTok в своей документации, проверка может занять от двух до трех рабочих дней. Мы отправили приложение на проверку в пятницу, в понедельник с утра у нас уже было одобренное приложение и можно было продолжить работу.
К сожалению, у меня нет для вас советов на тот случай, если ваше приложение не одобрили. Главное, о чём нужно помнить это правильно заполнять все обязательные поля и запрашивать разрешения только на то, что действительно необходимо: ни больше, ни меньше.
Авторизация бизнес-аккаунта в приложении
Из всей рутинной работы по заполнению форм, эта часть оказалось самой интересной. У нас не было web-приложения, которое бы отлавливало редирект с авторизационным кодом, поэтому автоматическую авторизацию бизнес-аккаунта сделать не получилось. Но мы оперативно потыкали в кнопки и получили заветный Access Token, с помощью которого собираем данные всех рекламных аккаунтов нашего бизнес-менеджера.
Итак, по порядку, что мы делали не имея сайта, который бы отлавливал callback с авторизационным кодом.
-
Зашли в приложение и указали
Callback Addresshttps://www.ozon.ru. -
Скопировали
Authorized URL, перешли по нему, авторизовались под аккаунтом бизнес-менеджера. -
Согласились на предоставление разрешений для приложения, нажали "Confirm".
-
Далее нас перекинуло на сайт Ozon, но с дополнительными аргументами в url. Получилось наподобие такого
https://www.ozon.ru/?auth_code=XXXXXXXXXXX. -
Скопировали значение
auth_code, в приложении скопировалиsecretиapp_idи отправили запрос к TikTok на получение long-term Access Token.
curl -H "Content-Type:application/json" -X POST \-d '{ "secret": "SECRET", "app_id": "APP_ID", "auth_code": "AUTH_CODE"}' \https://ads.tiktok.com/open_api/v1.2/oauth2/access_token
Получили ответ такого вида:
{ "message": "OK", "code": 0, "data": { "access_token": "XXXXXXXXXXXXXXXXXXXX", "scope": [4], "advertiser_ids": [ 1111111111111111111, 2222222222222222222] }, "request_id": "XXXXXXXXXXXXXXX"}
Важно было успеть отправить запрос на получение long-term Access
Token как можно быстрее, после редиректа на сайт Ozon. Связано это
с временем жизни auth_code 10 минут.
Из полученного ответа необходимо сохранить значения
access_token, его нужно использовать при каждом
запросе. Если access_token будет потерян или, того
хуже, скомпрометирован, нужно будет заново выполнять все пункты по
аваторизации аккаунта бизнес-менеджера.
Так же при запросах нам понадобиться список
advertiser_ids, но его не обязательно сахранять прямо
сейчас список ID аккаунтов всегда можно посмотреть в аккаунте
бизнес-менеджера.
Всё, мы готовы писать запросы!
Получение статистики
Когда мы только начинали собирать данные из TikTok, я пользовалась методом, который сейчас depricated, поэтому сразу расскажу о новом.
Итак, у нас есть всё необходимое для получения данных, а именно:
-
access_token, -
список
advertiser_ids.
В результате нужно получить расходы по кампаниям, в группировке до названия рекламного объявления.
|
media source -> campaign -> adset -> ad_name |
Значение media source всегда неизменно, так как
источник один TikTok. По остальным параметрам можно запросить
данные из API TikTok.
Теперь нужно было решить, с какой детализацией по времени будем тянуть данные. TikTok позволяет загружать детализацию по часу и дню. Если выгружать детализацию по часу, то, максимум, за один запрос можно получить данные только за один день; если запрашивать детализацию по дням максимум, на один запрос мы получим 30 дней. Конверсии в покупки анализируются за целый день, поэтому и расходы решили собирать за день.
В новом методе получения данных добавили фильтр по типу размещения рекламы: AUCTION и RESERVATION. Ozon использует только AUCTION в своей стратегии ведения кампаний.
Кроме расходов мы собирали также и другую рекламную статистику по кампаниям: просмотры, клики, количество уникальных пользователей смотревших рекламу и другое. В итоге получился такой список метрик:
METRICS = [ "campaign_name", # название кампании "adgroup_name", # название группы объявлений "ad_name", # название объявления "spend", # потраченные деньги (валюта задаётся в рекламном кабинете) "impressions", # просмотры "clicks", # клики "reach", # количество уникальных пользователей, смотревших рекламу "video_views_p25", # количество просмотров 25% видео "video_views_p50", # количество просмотров 50% видео "video_views_p75", # количество просмотров 75% видео "video_views_p100", # количество просмотров 100% видео "frequency" # среднее количество просмотра рекламы каждым пользователем]
В документации TikTok для каждого метода API описан пример на языках Java, Python, PHP и также curl-запрос. Я использовала пример на Python с небольшими изменениями.
В примерах из документации TikTok используются две дополнительные библиотеки:
pip install requestspip install six
Библиотека requests необходима для удобной отправки
get-запросов. Библиотека six используется для
генерации url-адреса запроса.
И еще две библиотеки, которые я уже добавила сама для того, чтобы записать данные в базу:
pip install pandaspip install sqlalchemy
В нашей компании для хранения данных используются SQL-подобные
хранилища, поэтому я использую pandas для
преобразования данных в DataFrame и sqlalchemy для
записи DataFrame в базу.
Я использовала функции из примера в документации TikTok для генерации url и отправки запроса.
# генерирует url на основе словаря args с аргументами запросаdef build_url(args: dict) -> str: query_string = urlencode({k: v if isinstance(v, string_types) else json.dumps(v) for k, v in args.items()}) scheme = "https" netloc = "ads.tiktok.com" path = "/open_api/v1.1/reports/integrated/get/" return urlunparse((scheme, netloc, path, "", query_string, ""))# отправляет запрос к TikTok Marketing API,# возвращает результат в виде преобразованного json в словарьdef get(args: dict, access_token: str) -> dict: url = build_url(args) headers = { "Access-Token": access_token, } rsp = requests.get(url, headers=headers) return rsp.json()
На вход функции get нужно передать список
аргументов и access token. Список аргументов под наши цели выглядит
следующим образом:
args = { "metrics": METRICS, # список метрик, описанный выше "data_level": "AUCTION_AD", # тип рекламы "start_date": 'YYYY-MM-DD', # начальный день запроса "end_date": 'YYYY-MM-DD', # конечный день запроса "page_size": 1000, # размер страницы - количество объектов, которое возвращается за один запрос "page": 1, # порядковый номер страницы (если данные не поместились в один запрос, аргумент инкрементируется) "advertiser_id": advertiser_id, # один из ID из advertiser_ids, который мы получили при генерации access token "report_type": "BASIC", # тип отчета "dimensions": ["ad_id", "stat_time_day"] # аргументы группировки, вплоть до объявления и за целый день}
Подробнее про page_size: ответ на запрос может
содержать большое количество информации и загружать всё это за один
раз не эффективно. Поэтому у TikTok есть ограничение на
максимальное количество объектов в ответе 1000. Чтобы получить
следующую порцию данных, нужно отправить запрос с теми же входными
аргументами на следующую страницу. Подробнее о постраничных
запросах ниже.
В ответ на запуск функции get получаем словарь
подобного вида.
{ # маркер успешности ответа "message": "OK", "code": 0, "data": { # информация о странице данных "page_info": { # общее количество объектов "total_number": 3000, # текущая страница "page": 1, # количество объектов на одной странице ответа "page_size": 1000, # общее количество страниц "total_page": 3 }, # массив объектов "list": [ # первый объект { # метрики "metrics": { "video_views_p25": "0", "video_views_p100": "0", "adgroup_name": "adgroup_name", "reach": "0", "spend": "0.0", "frequency": "0.0", "video_views_p75": "0", "video_views_p50": "0", "ad_name": "ad_name", "campaign_name": "campaign_name", "impressions": "0", "clicks": "0" }, # измерения (по каким параметрам группируем результаты) "dimensions": { "stat_time_day": "YYYY-MM-DD HH: mm: ss", "ad_id": 111111111111111 } },... ] }, # id ответа "request_id": "11111111111111111111111"}
Как я описывала выше, если в ответе получается более 1000
объектов, ответ будет разбит на несколько страниц. В данном случае
поле total_page говорит о том, что для получения
полного набора данных по указанным параметрам, нужны будут три
страницы. Следовательно, запускаем и коллекционируем ответы пока не
выгрузим все страницы.
page = 1 # сначала всегда получаем данные по первой страницеresult_dict = {} # словарь, в который будем записывать ответыresult = get(args, access_token) # первый запросresult_dict[advertiser_id] = result['data']['list'] # сохраняем ответ на запрос к первой странице# пока текущая полученная страница page меньше # чем общее количество страниц в последнем ответе resultwhile page < result['data']['page_info']['total_page']: # увеличиваем значение страницы на 1 page += 1 # обновляем значение текущей страницы в словаре аргументов запроса args['page'] = page # запрашиваем ответ по текущей странице page result = get(args, access_token) # накапливаем ответ result_dict[advertiser_id] += result['data']['list']
Такое необходимо повторить для каждого рекламного аккаунта из
списка advertiser_ids.
В результате всех вышеописанных манипуляций мы получили для
каждого рекламного аккаунта данные по рекламным метрикам. Осталось
только преобразовать словарь в pandas.DataFrame и
отправить их в базу.
# результирующий DataFrame, который будем записывать в базуdata_df = pd.DataFrame()# для каждого рекламного аккаунта выполнить преобразованиеfor adv_id in advertiser_ids: # получаем накопленные разультаты для аккаунта из словаря adv_input_list = result_dict[adv_id] # временный список adv_result_list = [] # для каждого объекта for adv_input_row in adv_input_list: # берём словарь метрик metrics = adv_input_row['metrics'] # насыщаем этот словарь словарём измерений metrics.update(adv_input_row['dimensions']) # добавляем полученный объект во временный список adv_result_list.append(metrics) # преобразуем временный словарь в DataFrame result_df = pd.DataFrame(adv_result_list) # добавляем колонку со значением id аккаунта result_df['account'] = adv_id # добавляем получившийся DataFrame в результирующий data_df = data_df.append( result_df, ignore_index=True )## здесь пропущены некоторые манипуляции # по преобразованию строк в числа## запись данных из результирующего DataFrame в базуdata_df.to_sql( schema=schema, name=table, con=connection, if_exists = 'append', index = False)
TikTok утверждает, что исторические данные по статистике не меняеются, а если и меняются, то это должна быть экстроординарная ситуации, наподобие аварии в ЦОД. Но на основе опыта получения данных от Facebook, я решила что всё равно буду перезаписывать семь последних дней (цифра семь появилась эмпирически).
В итоге получился вот такой скрипт, который каждый день обновляется данные по TikTok кампаниям за последние семь дней.
Полный текст скрипта.
# импорт библиотекimport jsonfrom datetime import datetimefrom datetime import timedeltaimport requestsfrom six import string_typesfrom six.moves.urllib.parse import urlencodefrom six.moves.urllib.parse import urlunparseimport pandas as pdimport sqlalchemy# генерирует url на основе словаря args с аргументами запросаdef build_url(args: dict) -> str: query_string = urlencode({k: v if isinstance(v, string_types) else json.dumps(v) for k, v in args.items()}) scheme = "https" netloc = "ads.tiktok.com" path = "/open_api/v1.1/reports/integrated/get/" return urlunparse((scheme, netloc, path, "", query_string, ""))# отправляет запрос к TikTok Marketing API,# возвращает результат в виде преобразованного json в словарьdef get(args: dict, access_token: str) -> dict: url = build_url(args) headers = { "Access-Token": access_token, } rsp = requests.get(url, headers=headers) return rsp.json()# обновляет данные в базе за последние семь дней# (или, если указаны start_date и end_date, для периода [start_date, end_date])def update_tiktik_data( # словарь с доступами к API TikTok tiktok_conn: dict, # словарь с доступами к базе данных db_conn: dict, # список id рекламных кабинетов advertiser_ids: list, # необязательное поле: начало периода start_date:datetime=None, # необязательное поле: окончание периода end_date:datetime=None): access_token = tiktok_conn['password'] start_date = datetime.now() - timedelta(7) if start_date is None else start_date end_date = datetime.now() - timedelta(1) if end_date is None else end_date START_DATE = datetime.strftime(start_date, '%Y-%m-%d') END_DATE = datetime.strftime(end_date, '%Y-%m-%d') SCHEMA = "schema" TABLE = "table" PAGE_SIZE = 1000 METRICS = [ "campaign_name", # название кампании "adgroup_name", # название группы объявлений "ad_name", # название объявления "spend", # потраченные деньги (валюта задаётся в рекламном кабинете) "impressions", # просмотры "clicks", # клики "reach", # количество уникальных пользователей, смотревших рекламу "video_views_p25", # количество просмотров 25% видео "video_views_p50", # количество просмотров 50% видео "video_views_p75", # количество просмотров 75% видео "video_views_p100", # количество просмотров 100% видео "frequency" # среднее количество просмотра рекламы каждым пользователем ] result_dict = {} # словарь, в который будем записывать ответы for advertiser_id in advertiser_ids: page = 1 # сначала всегда получаем данные по первой странице args = { "metrics": METRICS, # список метрик, описанный выше "data_level": "AUCTION_AD", # тип рекламы "start_date": START_DATE, # начальный день запроса "end_date": END_DATE, # конечный день запроса "page_size": PAGE_SIZE, # размер страницы - количество объектов, которое возвращается за один запрос "page": 1, # порядковый номер страницы (если данные не поместились в один запрос, аргумент инкрементируется) "advertiser_id": advertiser_id, # один из ID из advertiser_ids, который мы получили при генерации access token "report_type": "BASIC", # тип отчета "dimensions": ["ad_id", "stat_time_day"] # аргументы группировки, вплоть до объявления и за целый день } result = get(args, access_token) # первый запрос result_dict[advertiser_id] = result['data']['list'] # сохраняем ответ на запрос к первой странице # пока текущая полученная страница page меньше, # чем общее количество страниц в последнем ответе result while page < result['data']['page_info']['total_page']: # увеличиваем значение страницы на 1 page += 1 # обновляем значение текущей страницы в словаре аргументов запроса args['page'] = page # запрашиваем ответ по текущей странице page result = get(args, access_token) # накапливаем ответ result_dict[advertiser_id] += result['data']['list'] # результирующий DataFrame, который будем записывать в базу data_df = pd.DataFrame() # для каждого рекламного аккаунта выполнить преобразование for adv_id in advertiser_ids: # получаем накопленные разультаты для аккаунта из словаря adv_input_list = result_dict[adv_id] # временный список adv_result_list = [] # для каждого объекта for adv_input_row in adv_input_list: # берем словарь метрик metrics = adv_input_row['metrics'] # насыщаем этот словарь словарём измерений metrics.update(adv_input_row['dimensions']) # добавляем полученный объект во временный список adv_result_list.append(metrics) # преобразуем временный словарь в DataFrame result_df = pd.DataFrame(adv_result_list) # добавляем колонку со значением id аккаунта result_df['account'] = adv_id # добавляем получившийся DataFrame в результирующий data_df = data_df.append( result_df, ignore_index=True ) # # здесь пропущены некоторые манипуляции # по преобразованию строк в числа # # создание подключения к базе connection = sqlalchemy.create_engine( '{db_type}://{user}:{pswd}@{host}:{port}/{path}'.format( db_type=db_conn['db_type'], user=db_conn['user'], pswd=db_conn['password'], host=db_conn['host'], port=db_conn['port'], path=db_conn['path'] ) ) # удаление последних семи дней из базы with connection.connect() as conn: conn.execute(f"""delete from {SCHEMA}.{TABLE} where date >= '{START_DATE}' and date <= '{END_DATE}'""") # запись данных из результирующего DataFrame в базу data_df.to_sql( schema=SCHEMA, name=TABLE, con=connection, if_exists = 'append', index = False )
Миссия выполнена!
Подведем итоги
Итого, на всевышеописанные действия было потрачено менее одного рабочего дня (не считая времени, которое приложение было на проверке). Надеюсь, мне удалось показать, что уровень вхождения в API TikTok достаточно низкий, и для настройки автоматического сбора данных не нужно обязательно привлекать разработчика или блуждать по лабиринтам документации и запутанной логики.
К слову о лабиринтах, в Facebook тот же самый один рабочий день уходит на то, чтобы создать аккаунт разработчика, протыкать все галочки о политике конфидециальности и условий использования, создать приложение, настроить его и т.д. И в итоге к концу дня у тебя не работающий ETL по сбору данных, а очередной Permission Denied и распухшая голова, в которой крутится только одна мысль "что я делаю не так".
Конечно, сравнивать Facebook и TikTok не очень правильно: второй ещё относительно молод и ему еще только предстоит быть обвешанным хитрыми условиями, запретами и всеми возможными сложностями. Но сейчас всего этого пока нет, так что пользоваться TikTok Marketing API крайне удобно. Надеюсь, моя статья вам немного в этом поможет.
Полезные ссылки
-
TikTok Marketing API: официальная документация;
-
Пример запроса статистики с официальной документации TikTok;
-
Библиотека request: официальная документация;
-
Библиотека six: официальная документация;
-
Библиотека pandas: официальная документация;
-
Библиотека sqlalchemy: официальная документация.

































{kind=link}