
Пару слов о нас: мы команда банка Открытие, которая отвечает за разработку всех розничных фронтов от рабочего места сотрудника в отделении до мобильных приложений физических лиц. В последние пару лет мы переживаем взрывной рост в несколько раз у нас более 400 сотрудников ИТ и мы продолжаем расти и расти. Как оказалось, многие решения, которые были приняты на старте нашей работы, оказались верными. И о некоторых из них мы вам расскажем. Готовы? Поехали!
Один из вопросов на старте цифровой трансформации банка был таким: как нам хранить исходный код используя монорепозиторий для хранения всех миросервисов или много репозиториев? Мы выбрали такой подход: для каждого приложения, библиотеки или микросервиса создаем отдельный репозиторий.
В рамках дискуссий внутри команды для нас было очевидно, что:
-
Монорепоэто решение, которое невзлетает из коробки, так как у нас банально много кода (на сегодня его около 100 GB), который просто будет долго выкачиваться к себе на локальную машину изрепозитория;
-
Когда мы попытаемся открыть такой огромный проект вIDE, она скорее всего приляжет;
-
При одновременной работе сотни разработчиков над одной кодовой базой потенциально ненулевые риски получитьpullrequest-ы на десятки тысяч строк кода, которые очень долго нужно будет вычитывать, чтобы понять,что вообще меняется.Которые имеют непредсказуемые срокиревью, тестирования и сложный вывод впрод;
-
Оставался открытым вопрос разграничения доступа внутрирепозитория(большие компании, которыепиарилиподход смонорепонесколько лет назад,решали этокастомнымсамописом, который разграничивал доступ, например, на уровне папок);
-
Очевидным плюсом было удобстворазруливаниязависимостей (в одномрепозиторииэто можноконтролировать на уровне кода). Так чтоесли отказываться отмонорепозитория, то надо было придумать как решить эту проблему.
Кирпичики, из которых складывается наше решение
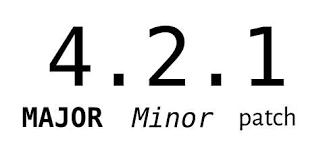
Учитывая номер версии МАЖОРНАЯ.МИНОРНАЯ.ПАТЧ, следует увеличивать:
-
МАЖОРНУЮ версию, когда сделаны обратно несовместимые изменения в работе сервиса;
-
МИНОРНУЮ версию, когда вы добавляете новую функциональность, ненарушая обратной совместимости;
-
ПАТЧ-версию, когда вы делаете какие-то внутренние исправления в работе сервиса, которые никак не меняют внешние контракты.
Дополнительные обозначения дляпредрелизныхибилд-метаданных возможны как дополнения к МАЖОРНАЯ.МИНОРНАЯ.ПАТЧ формату.
Для наших разработчиков нет греха страшнее, чем нарушить правила семантическоговерсионирования, мы строго за этим следим.
-
Публикация контрактов
В конвейер сборки сервисов внедрен процесс генерации и публикации контрактов, в которых однозначно описан интерфейс взаимодействия с ними. Доменные сервисы общаются с внешними потребителями наружу черезGraphQL(на самом деле у нас500+ сервисов, которые поделены на доменные группы, наподобие модной нынче и активно продвигаемойdomainorientedmicroservicearchitecture(DOMA). У каждой доменной группы есть только один внешнийGraphQLфасад, а внутри сервисы общаются поRabbitMQ, но для простоты понимания рассмотрим только пример с доменными сервисами). Сам контракт представляет из себя SDL схему, котораягенеритсяпри помощи стандартного функционала из коробкибиблиотекиqraphql-dotnetпри помощи утилитыgraphql-sdl-exporter. На самом деле утилиту мы написали сами, но решили ей поделиться и выложили еев паблик.

Что происходит после коммита:
Весь процесс контроля автоматизирован и встроен в конвейер сборки.
Шаги:
-
После коммита в любую ветку в случае, если увеличивается минорная версия, то есть у сервиса меняется интерфейс (как правило с добавлением новых элементов в контрактах), запускается процесс генерации контракта. В случае увеличения патч-версии перегенерация контракта не требуется, так как меняется только что-то под капотом без изменения внешнего поведения.
-
После из этого контракта (SDL схемы) при помощи утилит специфичных для каждого языка генерируются клиенты для различных потребителей на их языках, которые представляют собой пакеты, хранящиеся в репозитории пакетного менеджера. В нашем случае это NuGet, NPM, Graddle для .Net, JS и Java соответственно. В качестве инструмента для хранения и управления пакетов используется Arfifactory. Версия контракта (сервиса-поставщика) соответствует версии пакета. Например, сервис Payments версии 2.1.3 имеет контракт версии 2.1.0 (не 2.1.3, т.к. перегенерация для версий от 2.1.1 и выше не требуется, а потребуется только для 2.2.0).
В тот момент, когда в Artifactory появится новая версия пакета, у разработчика, который пишет сервис-потребитель, IDE сигнализирует о том, что вышла более новая версия пакета и предложит ему обновить пакет. Увеличение минорной версии, как правило, делается не глядя (мы даже подумываем автоматизировать этот процесс), увеличение же мажорной версии говорит нам о том, что произошли обратно несовместимые изменения и требуется более осознанный подход к обновлению.

Очень важный момент: Для feature веток и ветки master существуют различные хранилища пакетов: Release для master, Snapshot - для feature-веток. Причем из ветки master нет доступа к пакетам из Snapshot.
Рассмотрим пару примеров, которые продемонстрируют работу такого подхода.
Пусть сервис Accounts версии 4.7.2 потребляет сервис Payments версии 2.1.3 (обращается к нему, используя контракт в виде nuget пакета версии 2.1.0). Появилась необходимость добавить новую фичу в сервис Payments.

Вариант 1:
Допустим, что доработка сервиса Payments будет содержать обратно совместимые изменения. Тогда потребуется увеличить его минорную версию и после доработки она станет 2.2.0, что приведет к перегенерации контракта и клиентов для сервиса Payments, которые тоже станут версии 2.2.0.
Когда разработчиксервиса Payments Вася сделает коммит в свою feature ветку, увеличив версию сервиса, в хранилище Snapshot появятся новые клиенты для сервиса Payments. Разработчик сервиса Accounts Петя сможет обновить свой пакет для работы с сервисом Payments до версии 2.2.0 с новой функциональностью, сможет ей воспользоваться и реализовать свою логику работы с Payments в своей feature ветке своего репозитория.
Пока Вася доводит свой функционал до идеала, Петя допиливает свою функциональность, которая теперь зависит от версии Payments 2.2.0 и подливает свои изменения в ветку master, что в нашем случае приводит к инициации процесса релиза сервиса Accounts на прод. В процессе сборки сервис Accounts пытается разрешить свои зависимости и, в частности, получить новую версию пакета для работы с Payments 2.2.0 из хранилища Release (напомню, что master смотрит только туда), где его нет. Сборка падает с ошибкой. Автоматический контроль сработал. Петя идет к Васе, просит его побыстрее раскатать на прод новую версию сервиса Payments, после чего катит свою новую версию Accounts.
Вариант 2:
В сервисе Payments необходимо сделать обратно несовместимые изменения. Вообще мы такое категорически не приветствуем, но иногда такая необходимость возникает. Вася знает о своих потребителях (откуда скажем позже), он пишет письма ответственным и предупреждает всех о том, что собирается ломать обратную совместимость и увеличить версию своего сервиса до 3.0.0. В день Икс Вася опубликует версию Payments на тестовый контур и ждет результатов интеграционных тестов. У тех, кто не готов к обновлению сервиса Payments, попадают Beta тесты и тестовый контур станет неработоспособным в той части, которая потребляет сервис Payments. Новые контракты Payments при этом будут лежать в Snapshot. Вася не обновляет master-ветку, пока все потребители Payments не обновят свои версии пакетов для работы с Payments и не будут готовы синхроннос ним (сразу после него) раскататься на бой.
На описанных выше примерах мы продемонстрировали как относительно за дешево избежать проблем с контролем зависимостей. За весь период развития нашей платформы с момента внедрения этого решения мы ни разу не сталкивались с проблемами на бою, которые были обусловлены обратно не совместимыми изменениями наших сервисов.
Кстати, информация о том, кто использует клиента к сервису позволяет построить карту зависимостей системы и визуализировать ее в виде графа.

Такой подход справедлив, если код всех компонентов системы находится в области видимости сервиса картографии, основным (но не единственным) источником информации для него являются исходники. Не будем углубляться в детали, об автоматической картографии мы расскажем подробнее в одной из следующих статей следите за нашим аккаунтом и да будет всем счастье!
















