Привет, Хабр. В прошлой статье я рассказал о начальном анализе предметной области и базовом проектировании нашей новой ECM-системы. Теперь я расскажу о первой практической задаче, которую мы решили. А именно - о выборе способа организации структуры хранилища бизнес-атрибутов объектов.
Напомню, что в результате анализа мы пришли к следующей структуре объекта:
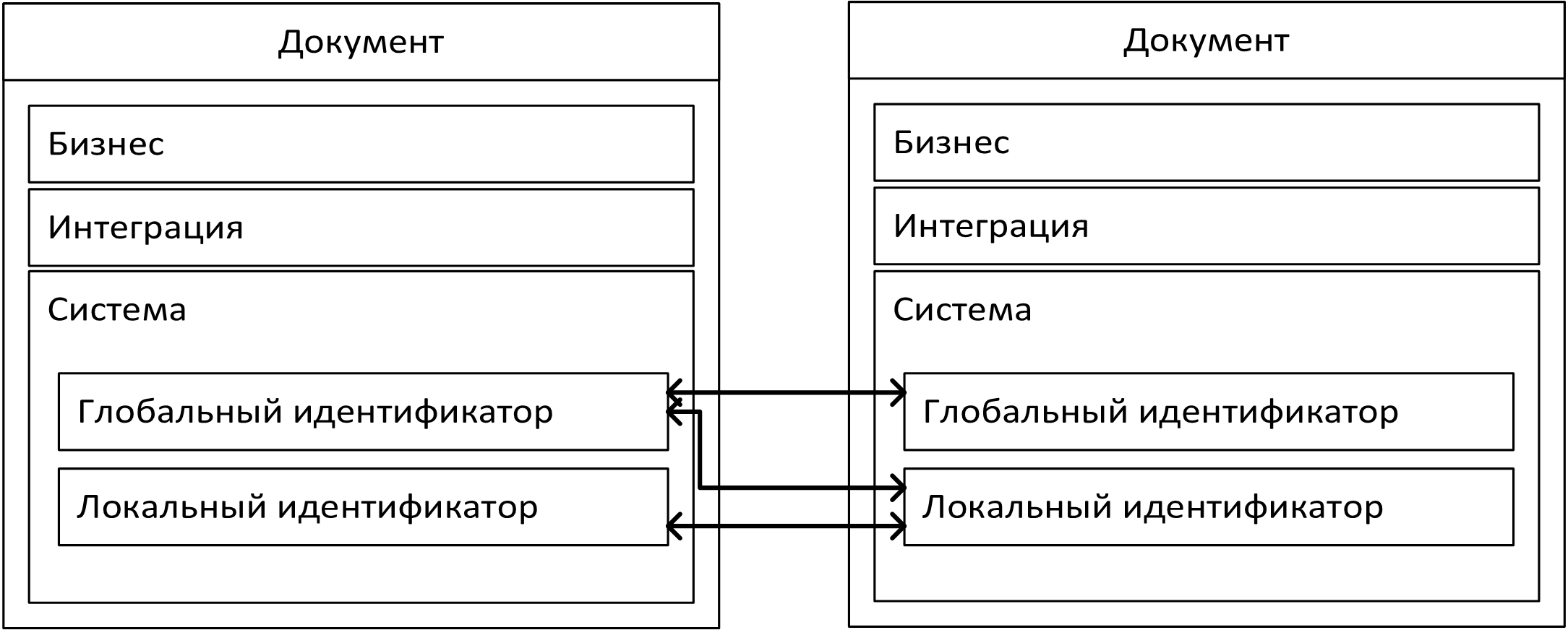
Системные и интеграционные поля содержат техническую информацию и редко подвержены модификациям. А вот бизнес-поля - искомые атрибуты объектов - могут и будут различаться для разных типов документов, которых у нас на входе предполагается около 1000. Проанализировав возможность повторного использования полей, мы пришли к выводу, что у разных типов документов может быть не более 15% общих свойств. И при этом всё равно придется скрепя сердце согласиться на неполное соответствие названия и содержания.
Таким образом, есть большое количество сущностей с разнообразным атрибутивным составом, который нужно хранить, тратя как можно меньше ресурсов, и расширять который хотелось бы также с минимальными усилиями.
Какие есть варианты?
Любые концепции хранения, которые будем рассматривать подразумевают использование промышленных баз данных, организацию хранилища в виде таблиц и связей между ними. Сразу можно выделить два наиболее часто используемых принципа организации атрибутивного хранилища.
Первый, условно классический, заключается в том, что структура представляется в виде набора таблиц, в каждой из которых данные сохраняются в колонках, имеющих четко заданный тип данных, размерность, ограничения и проверки. Общие колонки и некий глобальный идентификатор выделяются в одной корневой таблицу - базовую для всех остальных, что позволяет гибко связывать между собой объекты разных типов. На эту таблицу ссылаются расширяющие, которые содержат в себе поля, уникальные для каждой сущности.
Такая структура хранения дает возможность прогнозировать размер хранилища при расширении функционала, позволяет хорошо оптимизировать производительность, она проще для понимания на первых этапах разработки.
Но при этом со временем усложняется ее модификация - чем больше данных и полей для них, тем менее интуитивно становится добавление нового и тем больше ошибок можно допустит - каждый раз придется модифицировать всю цепочку получения данных.
А впоследствии могут начать возникать проблемы с восприятием. Если поля данных добавляются в одну общую таблицу, то растет размер впустую выделяемых ячеек. Если для каждой сущности добавляется отдельная таблица со специфичными для нее данными, то со временем структура хранилища начинает напоминать примерно такой "одуванчик".
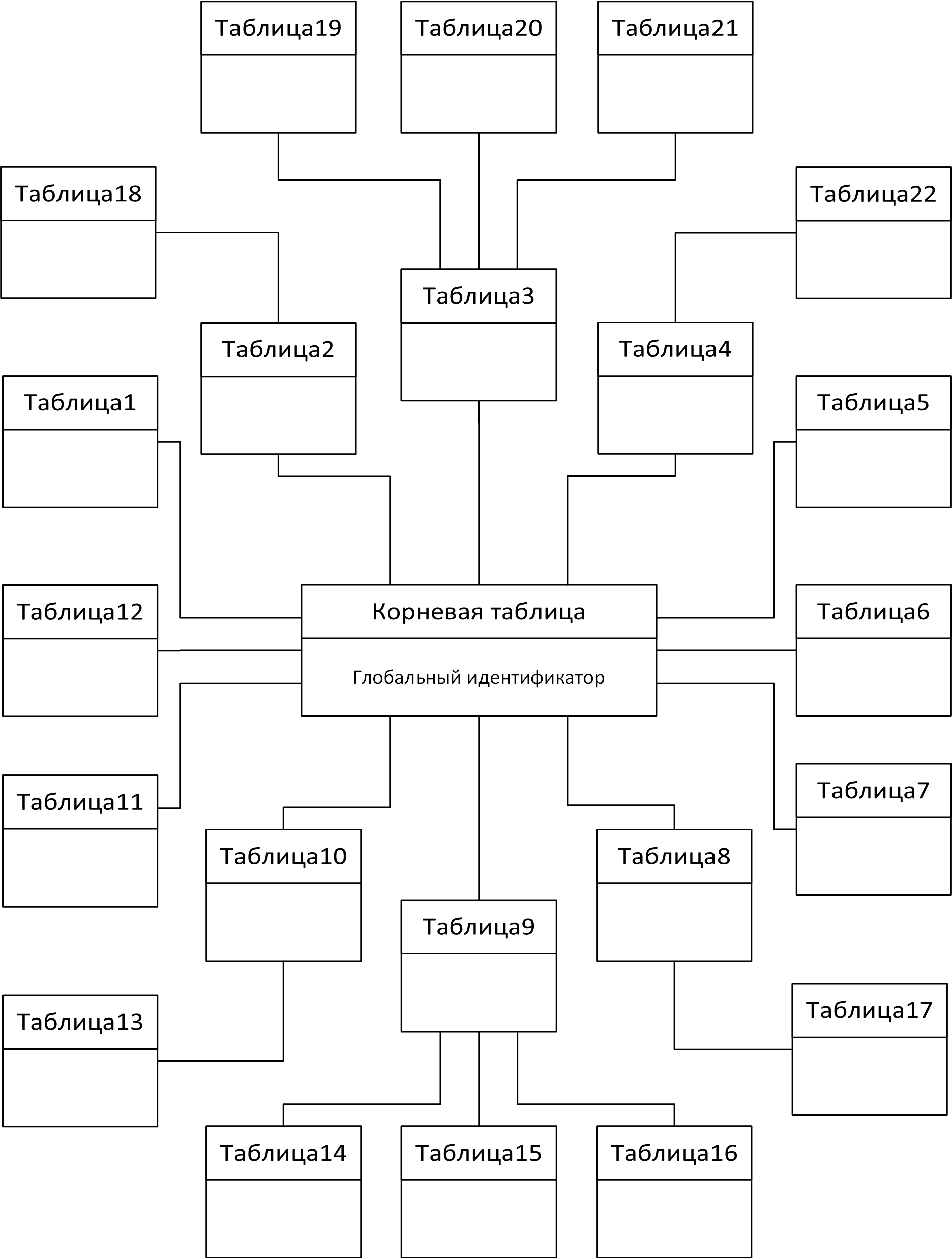
Именно с этим я столкнулся на двух прошлых (не самых старых) проектах со схожей декомпозицией объектов, разработчики которых выбрали именно такой путь организации данных.
Также стоит упомянуть про еще один способ организации данных, с которым я сталкивался. Он используется не в пример реже и больше напоминает "велосипед" - назовем его вертикальный. В хранилище создается таблица, которая содержит, условно, название поля, данные в нем, тип данных и связь с объектом. Возможно создание нескольких таких таблиц для разных типов данных или несколько колонок в одной таблице. Далее, при извлечении такие данные трансформируются из списка в плоский набор полей. Понимаете, почему я упомянул про велосипед?
А что у нас?
Второй вариант - это использование специализированных документоориентированных (или документных, как больше нравится) баз данных, реализующих NoSQL-подход к хранению и обработкенеструктурированной или слабоструктурированной информации. Наиболее часто данные хранятся в виде JSON объектов, но с предоставлением производителями СУБД инструментария для доступа к данным внутри этих структур.
У такого подхода, применительно к проектируемой системе, можно выделить несколько плюсов:
-
можем управлять структурой объектов без программирования, в том числе в реальном времени, путем администрирования. Администратор сможет зайти в некий интерфейс справочника полей и задать новые.
-
ограничиваем ситуации случайного воздействия на данные - модифицировать json объект гораздо сложнее, чем данные в колонке.
-
проще описывать объекты в коде - иногда можно вообще не описывать структуру документа в коде, а работать прямо с полями в JSON.
Но есть и минусы:
-
невозможно нативно реализовать проверки данных при размещении в хранилище.
-
валидацию данных придется проводить в коде.
-
невозможно организовать внутреннюю связность подчиненных данных, например, справочников.
Минусы, касающиеся необходимости дополнительной работы с данными в коде не так уж серьезны. Проблема со связностью решается организацией таблицы, в которой к любому объекту можно привязать любой другой. Правила связывания при этом должны также быть описаны в коде обработки данных. Плюсы же дают несравнимо больший потенциал для развития системы.
Чтобы продемонстрировать применимость такого подхода, мы решили сравнить, насколько оба варианта будут отличаться друг от друга по производительности, расширяемости и объемам хранилища.
Делаем прототип
Возьмем гипотезу, что NoSQL-подход для нашей системы применим как минимум не хуже, чем классический. Для ее проверки создадим прототип, в рамках которого реализуем оба подхода. В качестве СУБД возьмем Postgre, который уже давно умеет хорошо работать с JSON полями.
Создадим следующие таблицы:
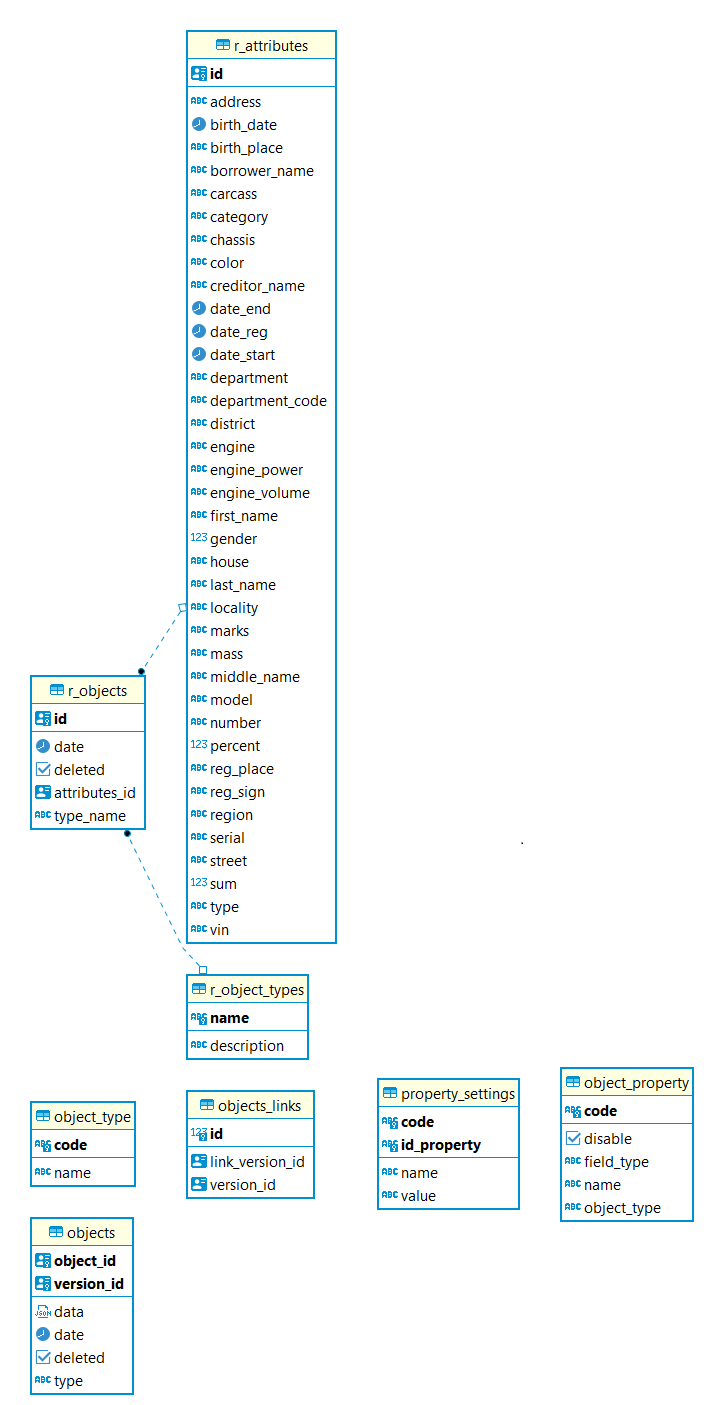
Для описания объектов в табличном виде:
-
r_objects, базовые данные по объектам: тип, дата создания и ссылка на хранилище атрибутов.
-
r_attributes. атрибуты, во всех возможные колонки для всех объектов. В идеале конечно же хранилища атрибутов для разных объектов лучше разбить по разным таблицам, но для прототипа это не критично.
Для описания объектов в виде JSON:
-
objects. Данные по объектам, где в поле data формата jsonb хранятся искомые атрибуты.
Остальные таблицы - это различные вспомогательные хранилища.
Реализуем в коде 5 разных типов объектов, для каждого из них описав программную структуру, механизм извлечения данных из хранилища и наполнения этими данными самих объектов.
Методика тестирования
Для тестирования обоих подходов хранения данных используем следующие методы:
-
добавление данных по объекту. Критерий успешности: объект с данными появился в хранилище, метод вернул в ответе его идентификатор.
-
обновление данных по объекту. Критерий успешности: данные в хранилище были изменены, метод вернул отметку об успехе. Удаление данных в системе не предусматривается, поэтому удаление объекта является операцией, аналогичной обновлению.
-
извлечение данных по объекту. Критерий успешности: объект с данными возвращен в ответе на запрос. Извлечение объекта происходит по конкретному идентификатору, по критериям поиска и постранично (пагинация).
Генерация запросов будет происходить в 20 параллельных потоков по 50 запросов в каждом потоке. Для того, чтобы тестирование было действительно показательным с точки зрения производительности, предварительно наполним базу 200 млн. объектов.
Тестирование показало следующие результаты:
 График по тестированию табличного хранилища
График по тестированию табличного хранилища График по тестированию NoSQL-хранилища
График по тестированию NoSQL-хранилища
Первая (высокая) часть графика - это получение объектов по случайной странице - пагинация. Здесь в обоих случаях пришлось применить небольшой трюк - так как Postgres не агрегирует точное число строк в таблице, то узнать, сколько всего записей на объеме данных теста простым count - это долго, и для получения количества записей пришлось брать статистику данных по таблице. Также время получения данных на страницах свыше 10000-й неприлично велико, поэтому верхняя планка для получения случайного номера страницы была установлена в 10000. Учитывая специфику нашей системы, получение пагинированных данных не будет частой операцией, и поэтому такое извлечение данных применяется исключительно в целях тестирования.
Вторая (средняя) часть графика - вставка или обновление данных.
Третья (низкая) часть графика - получение данных по случайному идентификатору.
В случае табличной структуры данных - линий на графике больше, потому что с точки зрения программной структуры, получение данных для каждого типа объекта идет по разным методам, тогда как для NoSQL - по одинаковым.
В данном тесте связность данных не учитывается, потому что она организовывается одинаково для обоих случаев.
Результаты тестов на 40000 запросов приведу в виде таблицы:
|
Табличная |
NoSQL |
|
|
Объем хранилища |
74 |
66 |
|
Среднее количество операций в секунду |
970 |
1080 |
|
Время тестирования, секунды |
42 |
37 |
|
Количество запросов |
40000 |
40000 |
Отмечу, что в течение месяца после реализации прототипа проводилось еще несколько тестирований по схожей методике, но с разными показателями нагрузки, показавших схожие результаты.
Что получилось?
В итоге, можно с уверенностью сказать, что для нашей системы NoSQL-подход к хранению данных оказался вполне подходящим. Даже с учетом потенциальных минусов, которые можно решить на этапе разработки серверной части, можно сказать, что он дает лучшие показатели по сравнению с табличным хранением. А плюсы в виде возможности настройки структуры объекта на лету, позволяют высвободить ресурсы от рутинного расширения объектов в сторону разработки новой функциональности.