Привет! Меня зовут Игорь Николаев, я пью за любовь
работаю в отделе автоматизации процессов разработки Мир Plat.Form в
НСПК. В этой статье я поделюсь тем, как наш отдел решал задачу по
автоматизации предоставления различных ресурсов для команд
разработки. Эта задача свойственна организациям с большим
количеством проектов, инфраструктура которых состоит из
распределенных и, возможно, слабо связанных сетевых сегментов.
В статье описан PoC (Proof of concept) решения задачи выделения ресурсов в рамках сервисов CI/CD (Continuous Integration & Continuous Delivery) и предоставления привилегий для пользователей этих сервисов.

Описание
Часто в организациях используются сложные и дорогостоящие IDM - класс систем Identity Management (как в рамках лицензирования, так и внедрения и обслуживания) для управления доступами. Нам хотелось совместить процессы запроса и предоставления ресурсов на сервисах CI/CD и предоставления доступов к этим ресурсам. Хотелось получить максимально прозрачное и простое в поддержке и реализации решение, которое обеспечивает следующий функционал:
- Создание и управление сущностями сервисов CI/CD
- Использование удобных для нас инструментов
- Легкая интеграция с уже развернутыми у нас системами
- Простота эксплуатации
- Возможность тиражирования
Про тиражирование стоит сказать подробнее, у нас есть несколько сетевых сегментов с разными сервисами CI/CD, и иногда они имеют минимум сетевой связанности. Система должна с минимальными затратами обслуживать несколько окружений, которые могут отличаться друг от друга.
Что мы выбрали для PoC:
Как подход был выбран
IaC (Infrastructure-as-Code) с описанием желаемых состояний в
виде yaml
файлов.
Python
язык для написания автоматизации (подходящий вариант для
прототипа);
Bitbucket
веб-сервис для хостинга проектов и их совместной разработки;
Jenkins
сервис непрерывной интеграции (необходим нам для визуализации
выполнения задач).
Как пилотные системы для автоматизации были выбраны:
Active Directory всем известные службы каталогов (нам
понадобятся группы и пользователи);
Bitbucket
часто запрашивают создание проектов, предоставление привилегий;
Nexus 3 OSS (не реклама, нет страницы в Wiki) корпоративная
система хранения артефактов, при появлении проектов создаются
персональные репозитории проекта и выдаются привилегии.
Немного про Bitbucket и
GitOps
(Перевод замечательной статьи про GitOps от коллег из
Флант)
Разговор об автоматизации следует начать с описания общей концепции.
В Bitbucket есть две важные сущности: проект(project) и репозиторий (repository), который входит в состав проекта. Для описания доступов в рамках концепта мы решили ограничиться доступами к проекту (более сегментированное предоставление привилегий (на репозиторий) в рамках концепта не потребуется).
У project в Bitbucket есть параметр project key, который понадобится для дальнейших манипуляций, мы взяли его за связующую основу. Именно он и будет являться названием директории в git-репозитории meta. В директории проекта будут размещаться meta-файлы (карты) проекта описанные в формате yaml.
Проектов в Мир Plat.Form много, и у каждого есть своя специфика. Возникает мысль держать в одном месте информацию о группах, инструментах, требуемых проекту, стендах (наборах серверов) и прочего, что имеет отношение к проекту. Для этого отлично подходит git репозиторий.
Какие задачи это решает?
- В первую очередь, мы получаем стандартный интерфейс описания, который создает однотипные сущности сервисов CI/CD.
- В любой момент времени мы можем увидеть реальное описание пользователей и их привилегий в рамках проекта.
- Выполняя автоматизацию по расписанию можно гарантированно получать именно то, что описано в проектных метаданных (защита от очумелых ручек).
- Расширяя описание проекта в виде определенной структуры meta-данных, можно автоматизировать другие сущности.
Структура meta репозитория git:
DEV наименование сетевого сегмента
project1 ключ проекта в Bitbucket
project1_meta.yaml карта проекта
examples директория примера описания
Такая структура позволит описать несколько различных сетевых сегментов, при этом сохраняя гибкую возможность изменений и различий между ними.
Скрипты автоматизации в рамках концепта будут находиться в проекте в отдельных репозиториях (названия не принципиальны):
О назначении первых трех репозиториев легко догадаться. Последний репозиторий jjb-core репозиторий в котором мы будем хранить описание Jenkins Job в виде рецептов для Jenkins Job builder (о нем будет рассказано ниже).
Автоматизация Microsoft AD
Active Directory используется во многих организациях. Большое количество рабочих процессов организаций начинаются именно с него. У нас в Мир Plat.Form все сотрудники имеют учетные записи в AD и включены в различные группы.
За AD отвечает подразделение инфраструктуры. Для наших нужд была выделена техническая учетная запись (ТУЗ), которой делегировано управление одним из Organization unit (OU). Именно в нем с помощью простой автоматизации мы будем создавать группы и наполнять их пользователями.
Часть содержимого project1_meta.yaml, которая отвечает за AD:
---READY: True # Защита от "дурака", если не True, то автоматизация проигнорирует весь файлTEAM: # Описание состава команды (роли) USER_LOCATION: ldap # local or ldap ROLES: owner: - owner1 developer: - developer1 - developer2 qa: - qa1 - qa2GLOBAL_PRIVILEGES: &global_privileges # Базовый набор привилегий для каждой роли в команде owner: [read, write, delete] developer: [read, write] qa: [read]
READY булево значение и позволяет, в случае
необходимости, выключить автоматизацию обработки данного мета
файла
TEAM секция, описывающая сущность проекта
ROLES произвольные названия ролей на проекте,
отображающие суть
GLOBAL_PRIVELEGES секция описывает, какая роль
будет обладать какими привилегиями
Пример мета репозитория
В рамках предоставления прав для окружения разработки, чтобы не усложнять пример, остановимся на 3х основных ролях: owner, developer, qa (в целом, количество и наименование ролей является произвольным). Для дальнейшей автоматизации эти роли позволят покрыть большую часть повседневных потребностей (у нас сразу появились роль tech, для ТУЗ, но для примера обойдемся без нее).
В рамках OU проекта будем автоматически, на основании meta-файлов проекта, создавать необходимые SG (Security group) и наполнять их пользователями.
На схеме структура выглядит так:
В AD используем плоскую иерархическую структуру, это позволит ее легко обслуживать, и выглядит она весьма наглядно.
Скрипт автоматизации получился очень простой. Он позволяет отслеживать изменения в составе групп (добавление/удаление пользователей) и создавать OU/SG.
Для запуска потребуется установить зависимости из requirements.txt (ldap3, PyYAML).
Автоматизация Sonatype Nexus3 OSS
Что такое Nexus? Nexus это менеджер репозиториев, позволяющий обслуживать разные типы и форматы репозиториев через единый интерфейс (Maven, Docker, NPM и другие).
На момент написания статьи версия была OSS 3.25.1-04
Почему именно Nexus?
Есть community версия, которая обладает богатым функционалом, достаточным для выполнения большинства задач, связанных с хранением артефактов и проксирования внешних репозиториев.
Процесс хранения артефактов является важным при проектировании конвейера тестирования и развертывания.
Что потребуется автоматизировать?
Blobstore
Все двоичные файлы, загружаемые через proxy репозитории (мы не
предоставляем прямого доступа к интернет репозиториям, используем
исключительно прокисрование через nexus), опубликованные в hosted
(локальные репозитории) репозитории хранятся в хранилищах
Blob-объектов, связанном с репозиторием. В базовом развертывании
Nexus, с одним узлом, обычно связаны с локальным каталогом на
файловой системе, как правило, а каталоге sonatype-work.
Nexus версии >= 3.19 поддерживает два типа хранилищ File и
S3.
UI Blob stores:
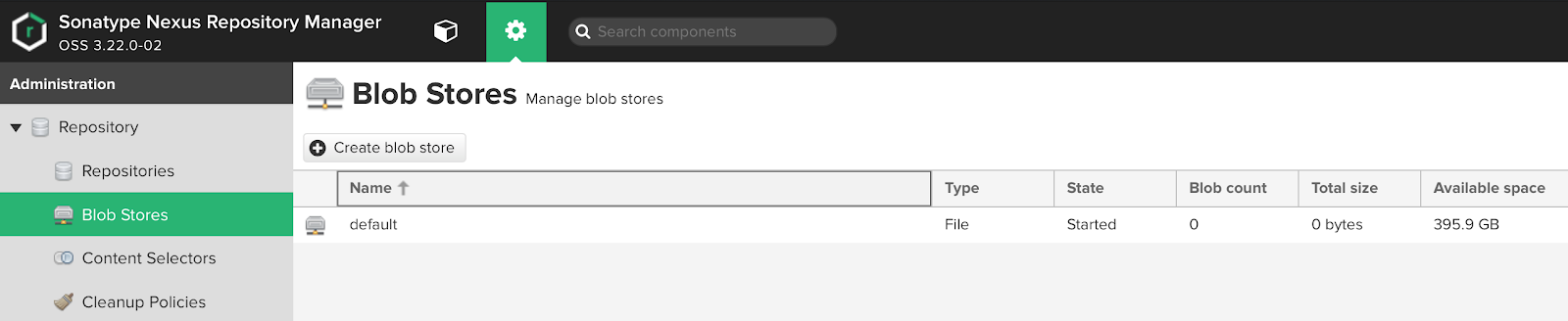
Как мы видим, по умолчанию нам уже доступно хранилище default. Из информации выше мы можем понять, что данный blob находится на диске и ему доступен весь объем дискового раздела, на котором находится директория sonatype-work.
Проблематика
В целом, все логично, но есть минимум две проблемы, о которых следует задуматься:
- В случае, если все репозитории будут привязаны к одному blob, у нас могут появиться проблемы с тем, что хранилище может побиться.
- Если мы предполагаем, что наш Nexus будет использоваться несколькими командами разработки, то стоит сразу задуматься о том, что в некоторых ситуациях чрезмерная генерация артефактов может забить весь раздел и проблема будет не только у команды, которая генерирует большой объем артефактов, но и у других команд.
Простое решение
Первое, что приходит в голову это создание отдельных blob
stores. Очевидно, это не решает проблему расположения на одном
дисковом разделе. Подходящим решением является "нарезать" разделы
для каждого проекта. Забегая вперед, это решит еще и вопрос
мониторинга и отправки уведомлений ответственным за проект. Удобное
решение второго пункта описанных проблем.
По первому пункту наиболее правильным решением является создание
отдельных blob store для каждого репозитория.
UI создания Blob stores:

Nexus позволяет настроить Soft quota, штука сомнительная. Она уведомляет о том, что с местом что-то не так, но не производит каких-либо действий. При правильном применении шагов, описанных выше, удается добиться большего функционала (Появляется простой способ отслеживания объема и обращений к диску, а переполнение не создает неприятности "соседям").
В поле path мы можем указать раздел, который примонтирован,
например, как nfs.
Что позволяет держать раздел непосредственно на сетевом хранилище.
Это может снизить скорость, но дает ряд преимуществ с точки зрения
простоты.
Nexus у нас запускается в Docker, для этого используется compose файл. Для подключения новых точек монтирования, простым решением будет добавить в compose файле монтирование родительского каталога точек монтирования.
Пример docker-compose:
version: "3"services: nexus3: container_name: nexus3 image: sonatype/nexus3:3.27.0 ports: - 8443:8443 - 50011:50011 # project1-docker-releases - 20012:50012 # project2-docker-releases volumes: - /nexus/sonatyep-work:/nexus-data - /mnt-blobs:/mnt-blobs - /etc/timezione:/etc/timezone - /etc/localtime:/etc/localtime logging: driver: "json-file" options: max-size: "10m" max-file: "10"
Repositories
Nexus позволяет создавать репозитории почти всех распространенных
форматов. Если идти в сторону идеального хранения, то целесообразно
для каждого проекта создавать минимум release и snapshot
репозиторий, хотя идеальный вариант может содержать еще и
release-candidat репозиторий. Это позволит настроить удобный
механизм чистки репозиториев.
Определенно, release репозиторий должен во многих случаях иметь максимальную глубину хранения, как требование, в релизах не должно оказаться "мусора". Напротив, с репозиториями snapshot мы должны иметь возможность очищать без опасений в любое удобное время и без рисков.
Ко всем форматам репозиториев доступ осуществляется по 80 и/или 443 портам, за исключением docker. Репозиторий Docker, для доступа к нему, должен иметь персональный порт. Это приводит к некоторым сложностям. Каждый раз публикуя новый порт, мы должны добавлять его публикацию в compose файле.
LDAP
Nexus имеет возможность реализации подключения к LDAP и
использования его в качестве аутентификации пользователей. В нашем
случае мы используем группы пользователей для предоставления
прав.
Roles
Для удобства роли создаются под проект, лучше идти от минимума, и
для себя мы выбрали три роли для каждого проекта:
qa обладают правами достаточными для read
developers read, write
owners read, write, delete
Группы из AD матчатся в локальные группы Nexus.
API
Начиная с версии Nexus OSS 3.19 появилось весьма удобное API для
управления Nexus, это значимое нововведение, которое многие
пользователи ждали позволит нам управлять Nexus и приводить его в
нужное состояние.
Swagger UI API:

На момент написания статьи API, по большей части, в статусе beta, но не смотря на это, работает без больших проблем и позволяет автоматизировать почти все необходимое.
Часть содержимого project1_meta.yaml, которая отвечает за nexus:
RESURCES: # Ресурсы, обслуживаемые автоматизацией nexus: repository: # Сущности # Maven - name: test-maven-releases locationType: hosted repoType: maven - name: test-maven-proxy locationType: proxy blobStoreName: test remoteUrl: http://test.ru repoType: maven # Docker - name: test-docker-releases locationType: hosted repoType: docker - name: test-docker-proxy locationType: proxy blobStoreName: test-blob remoteUrl: http://test.ru repoType: docker - name: test-docker-group blobStoreName: test-blob locationType: group httpPort: 10555 repoType: docker memberNames: - test-docker-releases - test-docker-proxy # Npm - name: test-npm-proxy locationType: proxy remoteUrl: http://test.ru repoType: npm blob: - name: test-blob path: test-blob privileges: <<: *global_privileges
На основании такого файла система автоматизации создает все обслуживаемые сущности. В наших командах принято, что teamlead отвечает за наполнение файла проекта, однако, создать его может любой желающий. После создания pull request следует согласование вовлеченными в процесс участниками, после мерджа с master веткой, отрабатывает автоматизация.
Стоит отметить, мы стремимся сделать процесс максимально простым для пользователя, что влечет к использованию шаблонов конфигураций, которые описаны в виде примитивных моделей. Система позволяет переопределить умолчания в случае возникновения необходимости в описании карты проекта.
Пример кода модели для maven hosted repository:
def maven_model_hosted(params): model = { 'name': params.get('name'), 'online': params.get('online', True), 'storage': { 'blobStoreName': params.get('blobStoreName', params['name']), 'strictContentTypeValidation': params.get('strictContentTypeValidation', True), 'writePolicy': params.get('writePolicy', 'ALLOW') }, 'cleanup': { 'policyNames': params.get('policyNames', []) }, 'maven': { 'versionPolicy': params.get('versionPolicy', 'MIXED'), 'layoutPolicy': params.get('layoutPolicy', 'PERMISSIVE') } } return model
Данный подход позволяет сократить описание создаваемой сущности
до минимума.
Идеологически, все что может использовать значения по умолчанию
должно их использовать, но при необходимости может быть заменено в
файле карты проекта.
Автоматизация Atlassian Bitbucket
Для концепта достаточно будет автоматизировать создание проекта и предоставление привилегий к нему.
Часть содержимого project1_meta.yaml, которая отвечает за Bitbucket:
... bitbucket: name: project1-bitbucket-project # Это не project key! # project_key получается из имени файла description: "Описание проекта в свободной форме" privileges: <<: *global_privileges
Это все, что потребуется при заведении нового проекта. Project key будет взят из названия yaml файла (в данном примере project1).
Как это выглядит в UI:

Jenkins Job Builder
JJB является python утилитой для описания сущностей jenkins в виде yaml манифестов, которые преобразуются в понятные jenkins API запросы. Это позволяет великолепно решать задачу управления большим количеством однотипных задач.
Jenkins в данном контексте является интерфейсом для отображения успешности выполняемых задач автоматизации и контроля над ними. Сами задачи на первом этапе планируем выполнять по расписанию, например, каждый час. Это позволит избавиться большой части неконтролируемых ручных изменений и будет каждый час приводить систему к описанному состоянию.
Структура репозитория jjb-core:

Каждая директория содержит описание Jenkins job состоящее из двух файлов.
Yaml файл описывает шаблон jenkins job имеет следующее наполнение:
---- job: # Создаем директорию CORE name: CORE project-type: folder- job: # Создаем поддиректорию ad-core-automation в CORE name: CORE/ad-core-automation project-type: folder# Описание темплэйта- job-template: name: 'CORE/ad-core-automation/{name}-{project_key}' project-type: pipeline job_description: Упралвение OU и SG для {project_key} # Defaults GIT_BRANCH: master GIT_CRED_ID: jenkins-bitbucket-integration triggers: - timed: 'H * * * *' parameters: - string: name: GIT_BRANCH default: '{GIT_BRANCH}' description: Git ref (branch/tag/SHA) - string: name: GIT_CRED_ID default: '{GIT_CRED_ID}' description: Jenkins credentials ID for BitBucket - string: name: META_LOCATION default: 'DEV/{project_key}/{project_key}_meta.yaml' description: Meta file location if CORE/meta repository dsl: !include-raw-escape: ./ad-core-automation.groovy- project: name: ad-ou project_key: - project1 - project2 - project3 jobs: - 'CORE/ad-core-automation/{name}-{project_key}'
Файл groovy это простой jenkinsfile:
def meta_location = params.META_LOCATIONdef git_cred_id = params.GIT_CRED_IDdef git_branch = params.GIT_BRANCHpipeline { agent { label 'centos' } stages { stage('Clone git repos') { steps { echo 'Clone meta' dir('meta') { git credentialsId: "${git_cred_id}", url: 'ssh://git@bitbucket.mir/core/meta.git' } echo 'Clone ad-core-automation' dir('auto') { git credentialsId: "${git_cred_id}", branch: git_branch, url: 'ssh://git@bitbucket/core/ad-core-automation.git' } } } stage('Install and run') { steps { echo 'Install requirements' withDockerContainer('python:3.8.2-slim') { withEnv(["HOME=${env.WORKSPACE}"]) { sh 'pip install --user --upgrade -r auto/requirements.txt &> /dev/null' echo 'Run automation' withCredentials([usernamePassword(credentialsId: 'ssp_ad_tech', passwordVariable: 'ad_pass', usernameVariable: 'ad_user')]) { dir('auto') { sh "./run.py -u $ad_user -p $ad_pass -f ../meta/${meta_location}" } } } } } } }}
Все это описывает создание следующей структуры Jenkins:

Общий алгоритм работы автоматизации:

- Инициатор создает в репозитории meta новую директорию с картой проекта и создает pull-request в мастер ветку(1).
- Pull-request попадает на проверку согласующих (2)
- В случае, если проект новый, пока в ручном режиме инженер прописывает Bitbucket project key для JJB (данное действие нужно произвести единожды)
- Автоматизация после внесения изменений в шаблоны JJB генерирует описанные job для проекта(4, 5).
- Jenkins запускает автоматизацию AD(6), которая создает необходимые сущности в виде OU и SG в AD. В случае, если все сущности уже созданы, приводит состав пользователей к описанному (удаляет/добавляет)
- Jenkins запускает автоматизацию Bitbucket(4), если проекта нет в Bitbucket, то создает его и предоставляет доступ для групп команды проекта. Если проект уже существует, то добавляет к нему группы AD с необходимыми привилегиями.
- Jenkins запускает автоматизацию для Nexus(7). Создаются описанные сущности Nexus и к ним предоставляется доступ на основе групп AD
Результат и развитие
Результатом данного концепта стало появление базовой автоматизации описанных процессов. Интерфейс взаимодействия в виде yaml карт проектов оказался весьма удобен, появились запросы на улучшения. Главными показателями успешности стали простота и скорость предоставления необходимых проектам ресурсов. Показатель скорости улучшился в разы по сравнению с ручным подходом. Все стало однотипным, понятным и повторяемым. Избавились от ручных ошибок.
На текущий момент описанный PoC перешел в стадию промышленной
эксплуатации и претерпел значительные доработки. Мы переписали core
систему автоматизации, к которой в виде плагинов подключаются
модули для автоматизации новых сервисов. Появились тесты.
Всего автоматизацией обслуживается около 50 проектов и подключаются
новые. Планируем тиражирование в другие сетевые сегменты.