DataHub: универсальный инструмент поиска и обнаружения метаданных.
Как оператор крупнейшей в мире профессиональной сети и экономического графика, отдел данных LinkedIn постоянно работает над масштабированием своей инфраструктуры в соответствии с требованиями нашей постоянно растущей экосистемы больших данных. По мере роста объема и разнообразия данных специалистам по данным и инженерам становится все сложнее обнаруживать доступные активы данных, понимать их происхождение и предпринимать соответствующие действия на основе полученных данных. Чтобы помочь нам продолжить масштабировать производительность и вносить инновации в базу данных, мы создали универсальный инструмент поиска и обнаружения метаданных, DataHub.
Примечание редактора: с момента публикации этого сообщения в блоге, команда в феврале 2020 года открыла DataHub с исходным кодом. Подробнее о том, как открыть исходный код для платформы, можно узнать здесь.
Масштабирование метаданных
Чтобы повысить продуктивность группы данных LinkedIn, мы ранее разработали и открыли исходный код WhereHows центральное хранилище метаданных и портал для наборов данных. Тип хранимых метаданных включает как технические метаданные (например, местоположение, схемы, разделы, владение), так и метаданные процесса (например, происхождение, выполнение задания). WhereHows также имеет поисковую систему, которая помогает находить интересующие вас наборы данных.
С момента нашего первого выпуска WhereHows в 2016 году, в отрасли наблюдается растущий интерес к повышению продуктивности специалистов по обработке данных с помощью метаданных. Например, инструменты, разработанные в этой области, включают Dataportal AirBnb, Databook Uber, Metacat Netflix, Amundsen Lyft и совсем недавно Data Catalog от Google. В LinkedIn мы также были заняты расширением объема сбора метаданных для новых вариантов использования при сохранении конфиденциальности. Однако мы пришли к выводу, что у WhereHows были фундаментальные ограничения, которые не позволяли удовлетворить наши растущие потребности в метаданных. Вот то, что мы смогли узнать во время работы с масштабированием WhereHows:
- Push лучше, чем pull: хотя получение метаданных непосредственно из источника кажется наиболее простым способом сбора метаданных. Более масштабируемым является использование отдельных поставщиков метаданных для передачи информации в центральный репозиторий через API или сообщения. Такой подход на основе push также обеспечивает более своевременное отображение новых и обновленных метаданных.
- Общее лучше, чем конкретное: WhereHows категорически придерживается мнения о том, как должны выглядеть метаданные для набора данных или задания. Это приводит к упрямому API, модели данных и формату хранения. Небольшое изменение модели метаданных приведет к каскаду необходимых изменений вверх и вниз по стеку. Он был бы более масштабируемым, если бы мы разработали общую архитектуру, не зависящую от модели метаданных, которую она хранит и обслуживает. Это, в свою очередь, позволило бы нам сосредоточиться на адаптации и развитии строго самоуверенных моделей метаданных, не беспокоясь о нижних уровнях стека.
- Онлайн так же важен, как и офлайн. После того, как метаданные собраны, естественно необходимо проанализировать эти метаданные, чтобы извлечь из них пользу. Одно из простых решений сбросить все метаданные в автономную систему, такую как Hadoop, где можно выполнять произвольный анализ. Однако вскоре мы обнаружили, что одной только поддержки автономного анализа недостаточно. Есть много вариантов использования, таких как управление доступом и обработка конфиденциальности данных, для которых необходимо запрашивать последние метаданные в Интернете.
- Взаимоотношения действительно важны. Метаданные часто передают важные взаимосвязи (например, происхождение, владение и зависимости), которые обеспечивают мощные возможности, такие как анализ воздействия, объединение данных, повышение релевантности поиска и т. д.
- Многоцентровая вселенная: мы поняли, что недостаточно просто моделировать метаданные, сосредоточенные вокруг одного объекта (набора данных). Существует целая экосистема данных, кода и человеческих сущностей (наборы данных, специалисты по обработке данных, команды, код, API микросервисов, показатели, функции ИИ, модели ИИ, информационные панели, записные книжки и т. Д.), Которые необходимо интегрировать и связать через единый граф метаданных.
Встречайте DataHub
Примерно год назад мы вернулись к чертежной доске и заново создали WhereHows с нуля, основываясь на этих знаниях. В то же время мы осознали растущую потребность LinkedIn в единообразном поиске и обнаружении различных объектов данных, а также в графе метаданных, которая соединяет их вместе. В результате мы решили расширить масштаб проекта, чтобы создать полностью обобщенный инструмент поиска и обнаружения метаданных, DataHub, с амбициозным видением: соединить сотрудников LinkedIn с данными, которые для них важны.
Мы разделили монолитный стек WhereHows на два отдельных стека: интерфейс модульного пользовательского интерфейса и бэкэнд общей архитектуры метаданных. Новая архитектура позволила нам быстро расширить сферу сбора метаданных, не ограничиваясь только наборами данных и заданиями. На момент написания DataHub уже хранит и индексирует десятки миллионов записей метаданных, которые охватывают 19 различных сущностей, включая наборы данных, показатели, задания, диаграммы, функции ИИ, людей и группы. Мы также планируем в ближайшем будущем внедрить метаданные для моделей и меток машинного обучения, экспериментов, информационных панелей, API микросервисов и кода.
Модульный интерфейс
Веб-приложение DataHub это то, как большинство пользователей взаимодействуют с метаданными. Приложение написано с использованием Ember Framework и работает на среднем уровне Play. Чтобы сделать разработку масштабируемой, мы используем различные современные веб-технологии, включая ES9, ES.Next, TypeScript, Yarn with Yarn Workspaces, а также инструменты качества кода, такие как Prettier и ESLint. Уровни представления, управления и данных разделены на пакеты, так что определенные представления в приложении построены на основе композиции соответствующих пакетов.
Структура обслуживания компонентов
Применяя модульную инфраструктуру пользовательского интерфейса, мы создали веб-приложение DataHub как серию связанных компонентов, согласованных по функциям, которые сгруппированы в устанавливаемые пакеты. Эта архитектура пакета использует в основе Yarn Workspaces и надстройки Ember и разбита на компоненты с использованием компонентов и сервисов Ember. Вы можете думать об этом как о пользовательском интерфейсе, который построен с использованием небольших строительных блоков (например, компонентов и сервисов) для создания более крупных строительных блоков (например, надстроек Ember и пакетов npm / Yarn), которые при объединении в конечном итоге составляют веб-приложение DataHub .
Благодаря компонентам и службам в основе приложения, эта структура позволяет нам разделять различные аспекты и объединять другие функции в приложении. Кроме того, сегментация на каждом уровне обеспечивает очень настраиваемую архитектуру, которая позволяет потребителям масштабировать или оптимизировать свои приложения, чтобы воспользоваться преимуществами только функций или встроить новые модели метаданных, относящиеся к их области.
Взаимодействие с DataHub
На самом высоком уровне интерфейс обеспечивает три типа взаимодействия: (1) поиск, (2) просмотр и (3) просмотр / редактирование метаданных. Вот несколько примеров скриншотов из реального приложения:



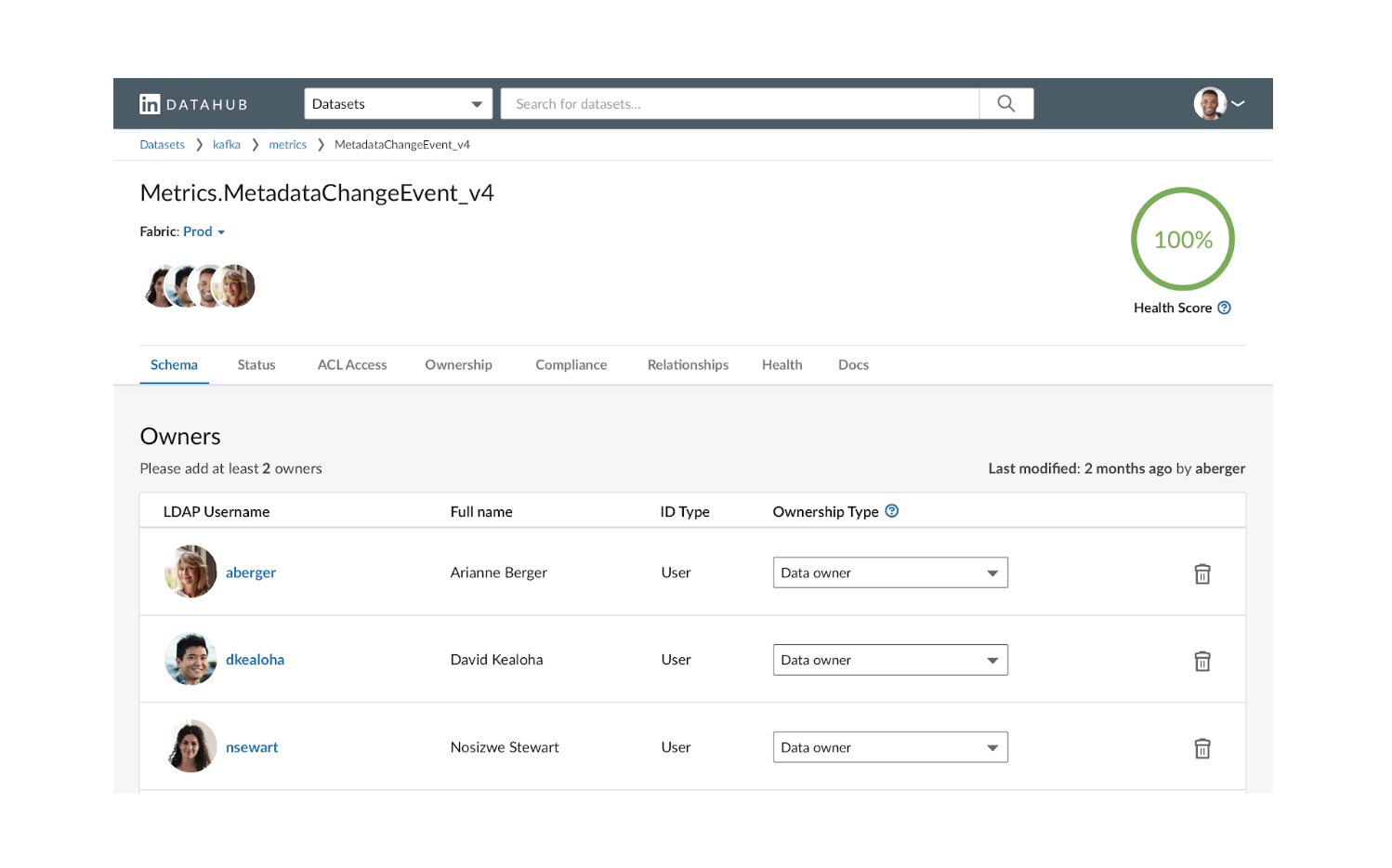


Как и в обычной поисковой системе, пользователь может искать один или несколько типов объектов, предоставляя список ключевых слов. Они могут далее нарезать и нарезать результаты, фильтруя список аспектов. Опытные пользователи также могут использовать такие операторы, как OR, NOT и регулярное выражение, для выполнения сложного поиска.
Сущности данных в DataHub могут быть организованы и просматриваться в виде дерева, где каждой сущности разрешено появляться в нескольких местах дерева. Это дает пользователям возможность просматривать один и тот же каталог разными способами, например, с помощью конфигурации физического развертывания или функциональной организации бизнеса. Может быть даже выделенная часть дерева, показывающая только сертифицированные объекты, которые курируются в рамках отдельного процесса управления.
Последнее взаимодействие просмотр / редактирование метаданных также является наиболее сложным. У каждого объекта данных есть страница профиля, на которой показаны все связанные метаданные. Например, страница профиля набора данных может содержать метаданные о его схеме, владении, соответствии, работоспособности и происхождении. Он также может показать, как объект связан с другими, например, задание, которое создало набор данных, метрики или диаграммы, которые вычисляются из этого набора данных, и т. Д. Для метаданных, которые доступны для редактирования, пользователи также могут обновлять их непосредственно через пользовательский интерфейс.
Обобщенная архитектура метаданных
Чтобы полностью реализовать видение DataHub, нам нужна была архитектура, способная масштабироваться с помощью метаданных. Проблемы масштабируемости бывают четырех разных форм:
- Моделирование: моделируйте все типы метаданных и отношений в удобной для разработчиков манере.
- Прием: прием большого количества изменений метаданных в любом масштабе как через API, так и через потоки.
- Обслуживание: обслуживайте собранные необработанные и производные метаданные, а также множество сложных запросов к метаданным в любом масштабе.
- Индексирование: индексируйте метаданные в масштабе, а также автоматически обновляйте индексы при изменении метаданных.
Моделирование метаданных
Проще говоря, метаданные это данные, которые предоставляют информацию о других данных. Когда дело доходит до моделирования метаданных, это предъявляет два различных требования:
- Метаданные это также данные: для моделирования метаданных нам нужен язык, который по крайней мере так же многофункциональн, как те, которые используются для моделирования данных общего назначения.
- Метаданные распределены: нереально ожидать, что все метаданные поступают из одного источника. Например, система, которая управляет списком управления доступом (ACL) набора данных, скорее всего, будет отличаться от той, которая хранит метаданные схемы. Хорошая среда моделирования должна позволять нескольким командам независимо развивать свои модели метаданных, одновременно представляя единое представление всех метаданных, связанных с объектом данных.
Вместо того, чтобы изобретать новый способ моделирования метаданных, мы решили использовать Pegasus, хорошо зарекомендовавший себя язык схем данных с открытым исходным кодом, созданный LinkedIn. Pegasus разработан для моделирования данных общего назначения и поэтому хорошо работает с большинством метаданных. Однако, поскольку Pegasus не предоставляет явного способа моделирования отношений или ассоциаций, мы ввели некоторые специальные расширения для поддержки этих вариантов использования.
Чтобы продемонстрировать, как использовать Pegasus для моделирования метаданных, давайте рассмотрим простой пример, проиллюстрированный следующей измененной диаграммой сущностей-отношений (ERD).
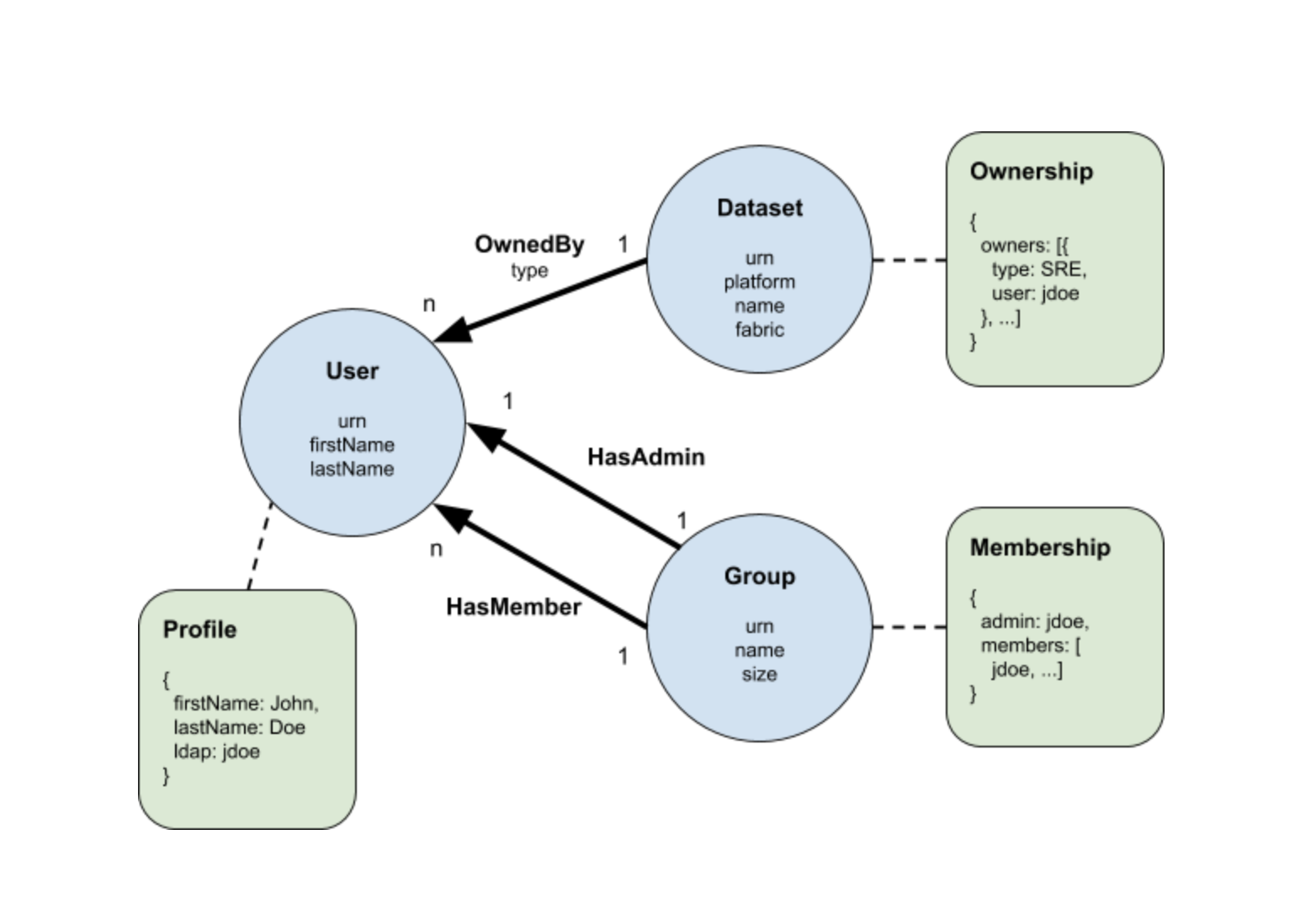
Пример содержит три типа сущностей Пользователь, Группа и Набор данных представленных синими кружками на диаграмме. Мы используем стрелки для обозначения трех типов отношений между этими объектами, а именно OwnedBy, HasMember и HasAdmin. Другими словами, группа состоит из одного администратора и нескольких членов пользователя, которые, в свою очередь, могут владеть одним или несколькими наборами данных.
В отличие от традиционного ERD, мы помещаем атрибуты сущности и отношения непосредственно внутри круга и под именем отношения, соответственно. Это позволяет нам присоединять к объектам новый тип компонента, известный как аспекты метаданных. Разные команды могут владеть и развивать различные аспекты метаданных для одного и того же объекта, не мешая друг другу, таким образом выполняя требование моделирования распределенных метаданных. Три типа аспектов метаданных: владение, профиль и членство включены в приведенный выше пример в виде зеленых прямоугольников. Связь аспекта метаданных с сущностью обозначается пунктирной линией. Например, профиль может быть связан с пользователем, а владение может быть связано с набором данных и т. д.
Вы, возможно, заметили, что есть совпадения между атрибутами сущности и отношения с аспектами метаданных, например, атрибут firstName пользователя должен быть таким же, как поле firstName связанного профиля. Причина такой повторяющейся информации будет объяснена в более поздней части этой публикации, но пока достаточно рассматривать атрибуты как интересную часть аспектов метаданных.
Чтобы смоделировать пример в Pegasus, мы переведем каждую из сущностей, отношений и аспектов метаданных в отдельный файл схемы Pegasus (PDSC). Для краткости мы включим сюда только по одной модели из каждой категории. Во-первых, давайте взглянем на PDSC для объекта User:
{ "type": "record", "name": "User", "fields": [ { "name": "urn", "type": "com.linkedin.common.UserUrn", }, { "name": "firstName", "type": "string", "optional": true }, { "name": "lastName", "type": "string", "optional": true }, { "name": "ldap", "type": "com.linkedin.common.LDAP", "optional": true } ]}
Каждая сущность должна иметь глобально уникальный идентификатор в форме URN, который можно рассматривать как типизированный GUID. Сущность User имеет атрибуты, включая имя, фамилию и LDAP, каждое из которых соответствует необязательному полю в записи пользователя.
Далее следует модель PDSC для отношения OwnedBy:
{ "type": "record", "name": "OwnedBy", "fields": [ { "name": "source", "type": "com.linkedin.common.Urn", }, { "name": "destination", "type": "com.linkedin.common.Urn", }, { "name": "type", "type": "com.linkedin.common.OwnershipType", } ], "pairings": [ { "source": "com.linkedin.common.urn.DatasetUrn", "destination": "com.linkedin.common.urn.UserUrn" } ]}
Каждая модель отношений, естественно, содержит поля источник и место назначения, которые указывают на конкретные экземпляры сущности с использованием их URN. Модель может дополнительно содержать другие поля атрибутов, например, в данном случае тип. Здесь мы также вводим настраиваемое свойство, называемое пары, чтобы ограничить отношения конкретными парами исходных и целевых типов URN. В этом случае отношение OwnedBy может использоваться только для подключения набора данных к пользователю.
Наконец, ниже вы найдете модель аспекта метаданных владения. Здесь мы решили смоделировать владение как массив записей, содержащих поля type и ldap. Однако при моделировании аспекта метаданных практически нет ограничений, если это действительная запись PDSC. Это позволяет удовлетворить требование метаданные это также данные, сформулированное ранее.
{ "type": "record", "name": "Ownership", "fields": [ { "name": "owners", "type": { "type": "array", "items": { "name": "owner", "type": "record", "fields": [ { "name": "type", "type": "com.linkedin.common.OwnershipType" }, { "name": "ldap", "type": "string" } ] } } } ]}
После того, как все модели созданы, возникает следующий логический вопрос: как связать их вместе, чтобы сформировать предлагаемый ERD. Мы отложим это обсуждение до раздела Индексирование метаданных в более поздней части этого сообщения.
Получение метаданных
DataHub предоставляет две формы приема метаданных: либо через прямые вызовы API, либо через поток Kafka. Первый предназначен для изменений метаданных, которые требуют согласованности чтения после записи, тогда как второй больше подходит для обновлений, ориентированных на факты.
API DataHub основан на Rest.li, масштабируемой строго типизированной сервисной архитектуре RESTful, широко используемой в LinkedIn. Поскольку Rest.li использует Pegasus в качестве определения интерфейса, все модели метаданных, определенные в предыдущем разделе, могут использоваться дословно. Прошли те времена, когда требовалось преобразование нескольких уровней моделей от API до хранилища API и модели всегда будут синхронизироваться.
Ожидается, что для приема на основе Kafka производители метаданных будут генерировать стандартизированное событие изменения метаданных (MCE), которое содержит список предлагаемых изменений конкретных аспектов метаданных, введенных с помощью соответствующего URN объекта. Схема для MCE находится в Apache Avro, но автоматически создается из моделей метаданных Pegasus.
Использование одной и той же модели метаданных для схем событий API и Kafka позволяет нам легко развивать модели без кропотливого обслуживания соответствующей логики преобразования. Однако, чтобы добиться истинной непрерывной эволюции схемы, нам нужно ограничить все изменения схемы, чтобы они всегда были обратно совместимы. Это применяется во время сборки с дополнительной проверкой совместимости.
В LinkedIn мы склонны больше полагаться на поток Kafka из-за слабой связи, которую он обеспечивает между производителями и потребителями. Ежедневно мы получаем миллионы MCE от различных производителей, и ожидается, что их объем будет расти экспоненциально только по мере того, как мы расширяем объем нашей коллекции метаданных. Чтобы построить конвейер приема потоковых метаданных, мы использовали Apache Samza в качестве нашей платформы обработки потоковой информации. Задание Samza приема специально разработано, чтобы быть быстрым и простым для достижения высокой пропускной способности. Он просто преобразует данные Avro обратно в Pegasus и вызывает соответствующий API Rest.li для завершения приема.
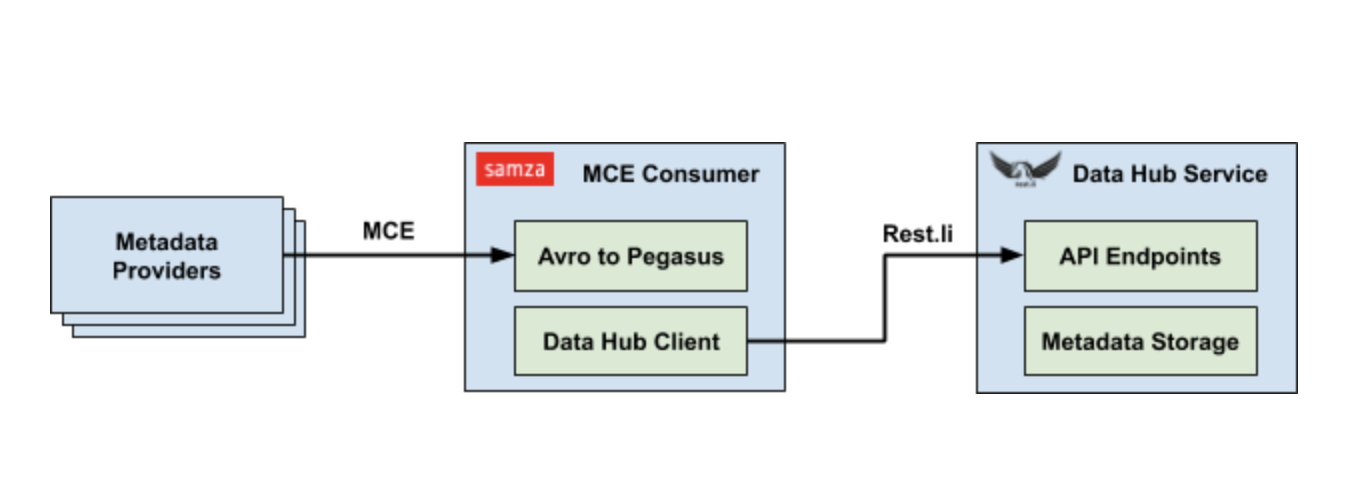
Обслуживание метаданных
После того, как метаданные были получены и сохранены, важно эффективно обслуживать необработанные и производные метаданные. DataHub поддерживает четыре типа часто встречающихся запросов к большому количеству метаданных:
- Документно-ориентированные запросы
- Графические запросы
- Сложные запросы, включающие соединения
- Полнотекстовый поиск
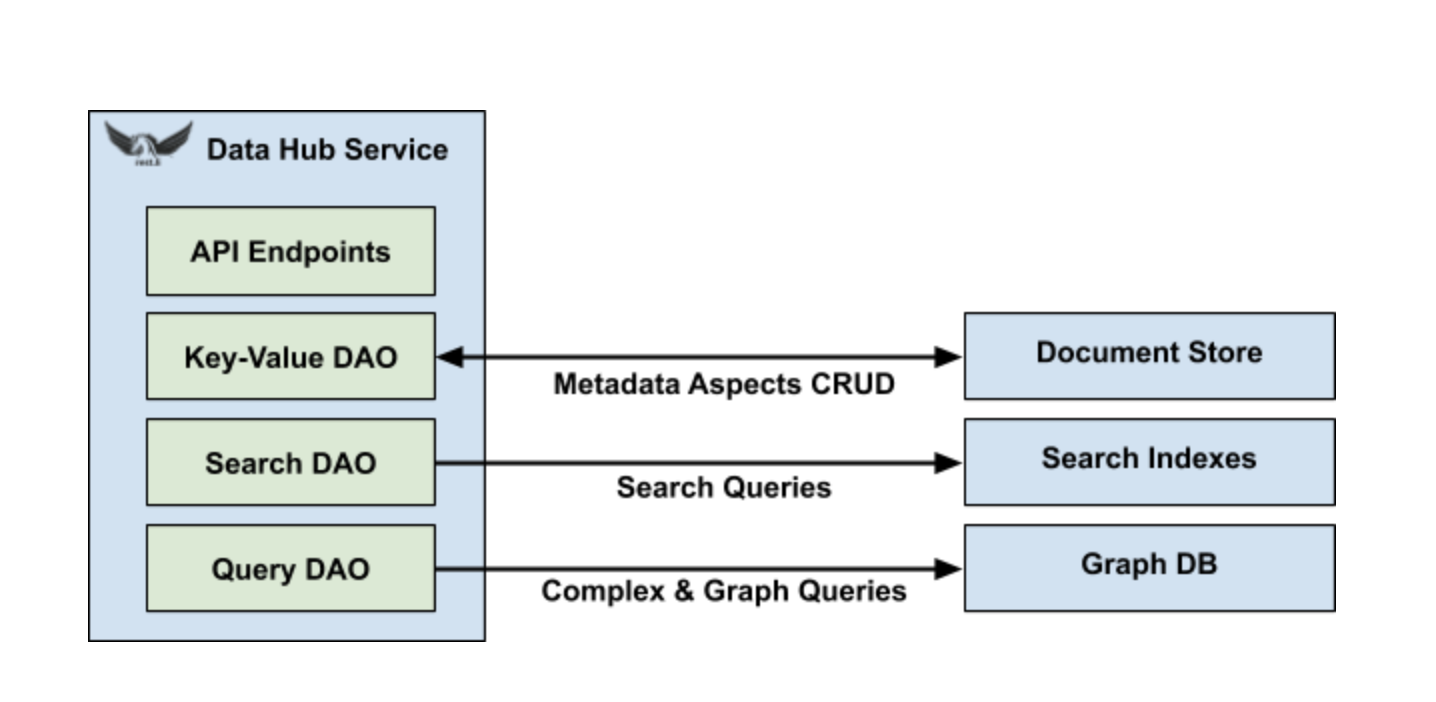
Для этого DataHub необходимо использовать несколько типов систем данных, каждая из которых специализируется на масштабировании и обслуживании ограниченных типов запросов. Например, Espresso это база данных NoSQL LinkedIn, которая особенно хорошо подходит для масштабируемого документально-ориентированного CRUD. Точно так же Galene может легко индексировать и обслуживать полнотекстовый поиск в Интернете. Когда дело доходит до нетривиальных запросов к графам, неудивительно, что специализированная графовая БД может выполнять на порядки лучше, чем реализации на основе СУБД. Однако оказывается, что структура графа также является естественным способом представления отношений внешнего ключа, позволяя эффективно отвечать на сложные запросы соединения.
DataHub дополнительно абстрагирует базовые системы данных с помощью набора общих объектов доступа к данным (DAO), таких как DAO ключ-значение, запрос DAO и поиск DAO. После этого реализация DAO для конкретной системы данных может быть легко заменена, без изменения какой-либо бизнес-логики в DataHub. В конечном итоге это позволит нам открыть DataHub с открытым исходным кодом с эталонными реализациями для популярных систем с открытым исходным кодом, в то же время используя все преимущества проприетарных технологий хранения LinkedIn.
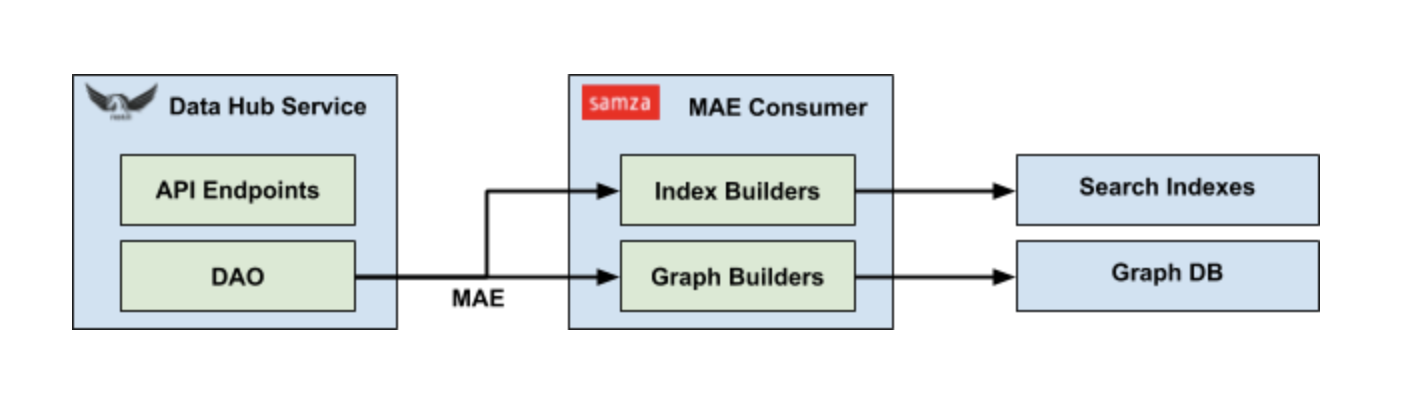
Еще одно ключевое преимущество абстракции DAO стандартизированный сбор данных об изменениях (CDC). Независимо от типа базовой системы хранения данных, любая операция обновления через DAO ключ-значение автоматически генерирует событие аудита метаданных (MAE). Каждый MAE содержит URN соответствующего объекта, а также изображения до и после определенного аспекта метаданных. Это позволяет использовать лямбда-архитектуру, в которой MAE могут обрабатываться как пакетами, так и потоками. Подобно MCE, схема MAE также автоматически генерируется из моделей метаданных.
Индексирование метаданных
Последний недостающий элемент головоломки конвейер индексации метаданных. Это система, которая объединяет модели метаданных и создает соответствующие индексы в графической БД и поисковой системе для облегчения эффективных запросов. Эти бизнес-логики фиксируются в форме построителя индексов и построителей графиков и выполняются как часть задания Samza, обрабатывающего MAE. Каждый разработчик зарегистрировал свой интерес к конкретным аспектам метаданных в задании и будет вызван с соответствующим MAE. Затем построитель возвращает список идемпотентных обновлений, которые будут применяться к БД индекса поиска или графа.
Конвейер индексации метаданных также хорошо масштабируется, поскольку его можно легко разделить на основе URN объекта каждого MAE для поддержки упорядоченной обработки для каждого объекта.
Заключение и с нетерпением жду
В этом посте мы представили DataHub, нашу последнюю эволюцию в путешествии по метаданным в LinkedIn. Проект включает в себя интерфейс модульного пользовательского интерфейса и серверную часть архитектуры обобщенных метаданных.
DataHub работает в LinkedIn в течение последних шести месяцев. Каждую неделю его посещают более 1500 сотрудников, которые поддерживают поиск, обнаружение и различные рабочие процессы для конкретных действий. График метаданных LinkedIn содержит более миллиона наборов данных, 23 системы хранения данных, 25 тысяч показателей, более 500 функций искусственного интеллекта и, что наиболее важно, всех сотрудников LinkedIn, которые являются создателями, потребителями и операторами этого графика.
Мы продолжаем улучшать DataHub, добавляя в продукт больше интересных пользовательских историй и алгоритмов релевантности. Мы также планируем добавить встроенную поддержку GraphQL и использовать язык Pegasus Domain Specific Language (PDL) для автоматизации генерации кода в ближайшем будущем. В то же время мы активно работаем над тем, чтобы поделиться этой эволюцией WhereHows с сообществом разработчиков ПО с открытым исходным кодом, а после публичного выпуска DataHub мы сделаем объявление.