И сегодня мы поговорим о том, что же такое честность модели машинного обучения.

Картинка взята отсюда
И разберем на простом примере выдачи кредитов: какие проблемы могут возникнуть, какие подходы к ним бывают и что из этого обычно получается.
Задача: по данным пользователя выдать решения и вероятности того, что не произойдет дефолта кредита. Причем таким образом, чтобы наши модели машинного обучения не попали под раздачу со всеми законами о дискриминации.

Самый важный вывод из всей статьи (бесплатно и без смс):
Честность модели всегда контекстуальна, определяется задачей и людьми вовлеченными в процесс.
Следствие: если спросить мнение пяти экспертов по этому вопросу, то вполне можно получить пять разных мнений.
Вывод: всё очень сложно.
Разбираем на примере
Здесь и далее мы следуем работе гугла по честности регрессионной модели, оценивающей вероятность дефолта кредита (у них там все интерактивно).
Два сценария: идеальный и реалистичный
Потенциально, у нас две ситуации: когда группа дефолта (которая не выплатила кредит) и группа успешно успешно выплатившая не пересекаются то есть классификатор успешно отделяют обе группы. Т.е. если человек в группе дефолта, то вероятность выплаты кредита меньше 0.5, и наоборот для второй группы.
Очевидно, что такой идеальный сценарий в жизни никогда не реализуется и идеальных классификаторов в жизни не существует, а значит куда более реалистичен второй сценарий (на картинке справа):
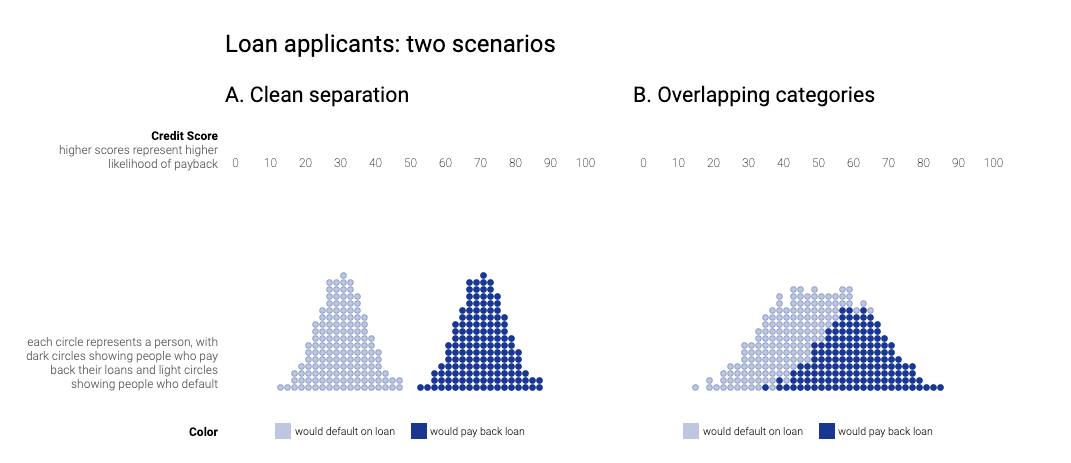
Граница решения и профит модели
Соответственно и что же мы делаем в такой ситуации? Для каждого клиента (из прошлого, по которому мы знаем правильный ответ) модель дает вероятность успешной выплаты кредита так же мы знаем, кто выплатил, а кто нет. Создателям модели известны риски ложноположительных и ложноотрицательных предсказаний (domain knowledge).
Далее, двигая границу мы будем получать разные результаты по профиту всего процесса и можем обнаружить положение дающее максимальный профит.

Смещение границ решения под нужное определение честности
Далее представим, что у нас есть группа, с которой мы подозреваем происходит что-то неладное определений честно много разных и мы обсудим их ниже. Сейчас важно, что они определяются через true positive, true negative, etc. То есть через предсказания модели и их отношением с настоящими метками класса.
Как правило, все определения это форма равенства определенных показателей в духе, равенства true positive rate. И движением границ, мы с одной стороны двигаем профит (как правило вниз), с другой приближаемся к нужным границам определения честность (как правило там задают некоторый отрезок допустимых значений).

Типы метрик
Тут мы расскажем кратко о типах метрик, подробнее можно прочитать в работе гугла.
- Независящий от групп (Group unaware): Никаких границ, система считает, что нужно давать кредит значит достойны, а если система не считает, что нужно значит так честно, ибо ваши данные хуже вписываются в то, что мы верим, кредитоспособный клиент.
- Групповые границы (Group thresholds): Второй эксперт вообще не согласен с первым. Так как есть исторические перекосы в данных, то например, женщины могут выглядеть менее кредитоспособными, чем мужчины. Например, у них может быть куда больше перерывов в работе из-за декрета, но машине все равно почему у вас был перерыв она может посчитать вам это в минус. Поэтому мы поправим границы, чтобы это поправить.
- Демографический паритет (Demographic parity): Не-не, скажет третий, вот если у нас 30% заявок от женщин, то и 30% кредитов должно пойти им.
- Равные возможности (Equal opportunity): Четвертый скажет, что это чушь потому что у них по-прежнему разные риски и с чего бы должны быть равные пропорции? Должно быть так: равные пропорции среди тех, кто их исторически выплатил. То есть, если 90% среди выплативших мужчин получили кредиты, то и 90% среди выплативших женщин должны их получить. (Если вы запутались, то модели строятся на исторических данных, где мы знаем правильные ответы.)
- Равная точность (Equal accuracy): Эксперт номер пять скажет, что четвертый на правильном пути, но не до конца: ибо оно не учитывает тех, кому их не выдали! А значит, что метрика должна учесть точность в целом, а не только положительные примеры.
Если посадите этих экспертов в одному комнату, то даже к утру они не договорятся и будут спорить о том, какое определение правильное и находить контрпримеры к определениям друг друга, показывающих их несостоятельность.
Помимо того, что определения разные в игру вступают еще и внешние факторы, которые и без всяких что если, влияют на выбор метрики: социо-экономический контекст, расчет реальных последствий для конкретной имплементации системы в обществе итд.
Невозможно следовать всем метрикам честности
Даже двум! Рассмотрим контр пример, подробнее об этом можно прочитать здесь.
Возьмем базовый уровень заражения по двум группам (base rate):

Как бы мы не смещали показатели для обеих групп, если базовые уровни отличаются, то выравнять сразу две метрики честности становится невозможно.

Вывод: должна быть выбрана метрика честности, которая является оптимальной для данного контекста и задачи.
Еще пара нюансов
Нельзя просто удалить показатели, которые мы считаем чувствительными, например, если вы удалите нужную переменную есть шанс, что система сможет ее аппроксимировать при принятии решения и тем не менее учесть.
Например, если исторические данные о том, за кем вы замужем/женаты показывают, что как правило мужчина старше, то это очень простая линейная метрика, которая может понять пол человека при подаче на кредит исходя из данных о его семье (которые вполне могут быть валидной частью анализа данных и построения модели).
Выводы
Честность модели это вещь непростая и контекстная.
Невозможно удовлетворять все метрикам честности одновременно (даже двум математически нельзя).
В центре дизайна модели и метрик честности должны стоять люди, эксперты, которые должны принять решение о том, что и как должно мониториться в системе принятия решений.
Ссылки по теме:
- research.google.com/bigpicture/attacking-discrimination-in-ml
- research.google/teams/brain/pair
- pair-code.github.io/what-if-tool/ai-fairness.html
- pair.withgoogle.com/explorables/measuring-fairness
- Context-conscious fairness in using machine learning to make decisions
- Inherent Trade-Offs in the Fair Determination of Risk Scores