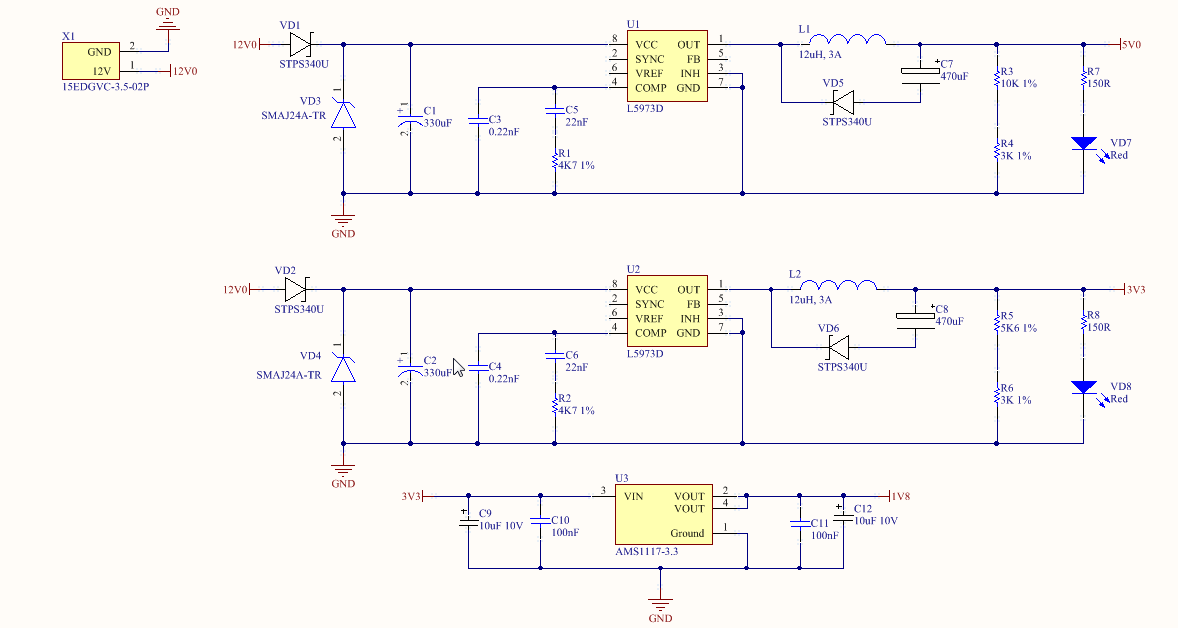
"То что ясно всем, ещё кто-то должен сказать"
Типа эпиграфа, Google/Яндекс автора не сыскали
При построении модели какого-либо объекта её можно свести к представлению чёрного ящика с несколькими параметрами P(i), влияющими на выход T. Для сложного многомерного объекта это могут быть модели его "сечения" в различных плоскостях/смыслах.
В идеальном случае для получения информации, необходимой для построения модели, необходимо получить значения T для всех сочетаний его параметров, заданных с достаточно малым (равномерным) шагом в интервале значений, допустимом для каждого из параметров. Чем больше имеется точек по каждому параметру (и, соответственно, значений Т), тем точнее можно построить модель. Однако, в реальной жизни, зачастую оказывается что и параметры влияют по-разному и шаг по каждому из них разумнее делать не равномерным. Например, в начале допустимого интервала параметр слабо влияет на Т, а в середине или в конце его влияние меняется (и даже многократно) и, следовательно, шаг по такому параметру стоит делать иным.
Но в начале построения модели, когда информации о взаимосвязях мало, допустимый интервал значений каждого параметра разбивается с равномерным шагом. При повторном решении задачи построения модели объекта близкого или слабо изменившегося к ранее уже исследованному, особенность влияния его параметров можно учесть в задании неравномерного разбиения допустимого интервала. Это минимизирует количество необходимых для построения модели значений Т при сохранении полноты получаемой об объекте информации, используемой в модели.
Здесь следует обратить внимание на то, что существуют объекты, для которых стоимость/сложность/длительность получения каждого выходного значения T очень велики. Далее речь пойдёт именно о таких объектах и их моделях.
Процедура задания каждого нового значения параметра в процессе исследования такого объекта уже не может быть тривиальной (равномерный шаг), она высоко затратна, и должна учитывать, по возможности, всю уже имеющуюся информацию о поведении Т. Каждый выбираемый шаг/значение i-го параметра должен учитывать текущую его корреляцию с поведением Т. Это становится возможно, если на каждом шаге строить предварительную модель объекта заново, и это оправдано, учитывая стоимость/сложность/длительность получения каждого нового значения T.
Сформулирую вытекающий из вышесказанного подход к моделированию неизвестного в общем случае объекта (с описанной выше сложностью): сначала по априорным, физическим и/или уже имеющимся исходным данным строится грубая модель с примерно постоянным (крупным или какой есть) шагом по каждому параметру. Затем на каждом новом шаге вычисления/получения Т создаётся/уточняется модель на основе новой информации, и модель уточняется (пересчитывается) с получением каждого нового значения Т. На каждом шаге по текущей модели определяется оптимальный следующий шаг по каждому параметру. Оптимальный в том смысле, что новое значение Т будет приносить максимум новой информации об объекте на данном этапе знания о нём.
Способ определения оптимального следующего шага будет работать тем лучше, чем точнее будут аппроксимированы зависимости Т от каждого параметра в текущей (промежуточной) модели. Здесь встаёт задача (необходимость) распараллеливания вычислительных процессов. Пока идёт относительно длительное вычисление ответа Т, на основании ранее полученной информации об объекте выполняется вспомогательный процесс - построение/уточнение модели и определение следующего набора параметров для нового расчёта. Причём заранее неизвестно сколько времени будет доступно для этих расчётов - столько, сколько идёт вычисление ответа Т. Чем быстрее работает алгоритм генерации точек, на которых производится интерполяция и аппроксимация по имеющимся точкам и точкам, полученным от текущей (промежуточной) модели, тем лучшего качества/точности достигнет алгоритм выбора оптимального следующего шага. Этот алгоритм работает в цикле - сначала грубо определяется новый набор параметров для вычислений, потом, если не прервали, идёт его уточнение и т.д. до завершения определяющего процесса - вычисления ответа Т. Ему (определяющему процессу) передаётся набор/вектор новых параметров для расчёта, а полученная новая точка Т используется в уточнении модели и новой процедуре выбора следующего шага.
Конечно, доля вычислительных затрат на получение набора значений каждого параметра с заданным шагом (именно этот алгоритм является целью обсуждения настоящей статьи, назову его Z, чтобы отличать от других упоминаемых) обычно намного меньше затрат на остальные расчёты по выбору шага для оценки Т. Но предлагаемый к обсуждению алгоритм демонстрирует предельно малые вычислительные затраты и не влечёт недостатков или сложностей. Разумно его использовать во всех подходящих применениях, это почти ничего не стоит.
На примере простейшей функции одного переменного T(X) покажу алгоритм получения значений параметров (X) для последующей аппроксимации. Напоминаю, что тут речь идёт об относительно мало затратных вычислениях по промежуточной модели и оптимизировать расположение точек на интервале допустимых значений параметров нет необходимости, кроме разве краёв диапазона (см. ниже):
Сначала производится расчёт по модели T(X) на 3-х точках: Xmin, (Xmin + Xmax)/2 и Xmax, т.е. по краям и посередине допустимого интервала (Xmin, Xmax). Далее каждый отрезок делится пополам и вычисляются значения в серединах каждого отрезка и т.д. Следующий анимированный GIF демонстрирует процесс генерации первых 14 значений параметров для одномерного случая.

В среднем плотность точек, генерируемых алгоритмом Z, выше на краях диапазона, как и должно быть для лучшей аппроксимации. "В среднем" понимается с учётом того, что весь вспомогательный процесс подбора следующего шага (и работы алгоритма Z) может быть прерван в любой момент, если завершилось получение новой точки Т. Расчёт нового ответа Т начнётся по тому набору/вектору параметров (новый шаг), который к этому времени успел сделать вспомогательный процесс. Результат незаконченной итерации расчёта нового шага или отбрасывается, или таки завершается, если велико соотношение временных затрат на расчёт Т и завершение расчёта текущей итерации прогноза нового шага.
Описанный подход применялся и при поиске экстремума сложной функции многих переменных. Целью минимизации служила сумма квадратов отклонения точек, полученных по модели от экспериментально измеренных на некоем объекте.
Алгоритм Z несложно масштабируется на двумерную (и более) плоскость, демонстрируя даже снижение средних вычислительных затрат на точку для больших размерностей. Для одномерного случая при достаточно большом количестве точек, получаемых на интервале (Xmin, Xmax), вычислительные затраты стремятся к 3/2 операции сложения (или вычитания, считаем их эквивалентными) на точку. Более простыми операциями присвоения и организации циклов пренебрегаем, ибо цикл и так участвует в самой процедуре аппроксимации.
Для двумерного случая вычислительные затраты стремятся к (!) операции сложения.
Автор утверждает, что не существует более экономичного алгоритма с точки зрения вычислительных затрат на генерируемую точку.
Ожидаю обсуждения (хорошо бы с буквой "б", а не без) сообществом Хабра описанного выше подхода к решению задачи построения модели и, возможно, ответа на мой вызов (к сообществу) о предельных характеристиках описанного алгоритма Z. Во второй части статьи, если не будет предложено решения, оспаривающего первенство по вычислительным затратам моего алгоритма, изложу конкретное программное его решение для одно- и двумерного случаев исполнения.
Надеюсь, вселенная меня не остановит. :)