На текущей работе пишем на Reactor. Технология классная, но как всегда есть много НО. Некоторые вещи раздражают, код сложнее писать и читать, с ThreadLocal совсем беда. Решил посмотреть какие проблемы уйдут, если перейти на Kotlin Coroutines, а какие проблемы, наоборот, добавятся.
Карточка пациента
Для статьи написал маленький проект, воспроизведя проблемы, с которыми столкнулся на работе. Основной код здесь. Алгоритм специально не стал разбивать на отдельные методы, так лучше видно проблемы.
В двух словах об алгоритме:
Переводим деньги с одного счёта на другой, записывая транзакции о факте перевода.
Перевод идемпотентен, так что если транзакция уже есть в БД, то отвечаем клиенту, что всё хорошо. При вставке транзакции может вылететь DataIntegrityViolationException, это тоже значит, что транзакция уже есть.
Чтобы не уйти в минус есть проверка в коде + Optimistic lock, который не позволяет конкурентно обновлять счета. Чтобы он работал нужен retry и дополнительная обработка ошибок.
Для тех кому не нравится сам алгоритмАлгоритм для проекта выбирал такой, чтобы воспроизвести проблемы, а не чтобы он был эффективным и архитектурно правильным. Вместо одной транзакции надо вставлять полупроводки, optimistic lock вообще не нужен (вместо него проверка положительности счета в sql), select + insert надо заменить на upsert.
Жалобы пациента
-
Stacktrace не показывает каким образом мы попали в проблемное место.
-
Код явно сложнее, чем был бы на блокирующих технологиях.
-
Многоступенчатая вложенность кода из-за flatMap.
-
Неудобная обработка ошибок и их выброс.
-
Сложная обработка поведения для Mono.empty().
-
Сложности с логированием, если надо в лог добавить что-то глобальное, например traceId. (в статье не описываю, но те же проблемы с другими ThreadLocal переменными, например SpringSecurity)
-
Неудобно дебажить.
-
Неявное api для параллелизации.
Ход лечения
Написал отдельный PR перехода с Java на Kotlin.
Интеграция почти везде гладкая.
Понадобилось добавить com.fasterxml.jackson.module:jackson-module-kotlin чтобы заработала сериализация data классов и org.jetbrains.kotlin.plugin.spring чтобы не прописывать везде open модификаторы.
В контроллере достаточно было написать suspend fun
transfer(@RequestBody request: TransferRequest) вместо
public Mono<Void> transfer(@RequestBody TransferRequest
request)
В репозитории написал suspend fun save(account: Account):
Account вместо Mono<Account> save(Account
account); Единственное, репозитории не определяются, если в
них только suspend функции, надо, чтобы хоть один метод работал с
Reactor типами.
Тесты обернул в runBlocking { }, чтобы можно было
вызывать suspend функции.
Для реализации Retry использовал библиотеку kotlin-retry. Единственное, в ней не было функции фильтрации по классу ошибки, но это было легко добавить (завёл PR).
Ну и, естественно, переписал алгоритм. Все детали опишу ниже по-отдельности.
Было:
public Mono<Void> transfer(String transactionKey, long fromAccountId, long toAccountId, BigDecimal amount) { return transactionRepository.findByUniqueKey(transactionKey) .map(Optional::of) .defaultIfEmpty(Optional.empty()) .flatMap(withMDC(foundTransaction -> { if (foundTransaction.isPresent()) { log.warn("retry of transaction " + transactionKey); return Mono.empty(); } return accountRepository.findById(fromAccountId) .switchIfEmpty(Mono.error(new AccountNotFound())) .flatMap(fromAccount -> accountRepository.findById(toAccountId) .switchIfEmpty(Mono.error(new AccountNotFound())) .flatMap(toAccount -> { var transactionToInsert = Transaction.builder() .amount(amount) .fromAccountId(fromAccountId) .toAccountId(toAccountId) .uniqueKey(transactionKey) .build(); var amountAfter = fromAccount.getAmount().subtract(amount); if (amountAfter.compareTo(BigDecimal.ZERO) < 0) { return Mono.error(new NotEnoghtMoney()); } return transactionalOperator.transactional( transactionRepository.save(transactionToInsert) .onErrorResume(error -> { //transaction was inserted on parallel transaction, //we may return success response if (error instanceof DataIntegrityViolationException && error.getMessage().contains("TRANSACTION_UNIQUE_KEY")) { return Mono.empty(); } else { return Mono.error(error); } }) .then(accountRepository.transferAmount( fromAccount.getId(), fromAccount.getVersion(), amount.negate() )) .then(accountRepository.transferAmount( toAccount.getId(), toAccount.getVersion(), amount )) ); })); })) .retryWhen(Retry.backoff(3, Duration.ofMillis(1)) .filter(OptimisticLockException.class::isInstance) .onRetryExhaustedThrow((__, retrySignal) -> retrySignal.failure()) ) .onErrorMap( OptimisticLockException.class, e -> new ResponseStatusException( BANDWIDTH_LIMIT_EXCEEDED, "limit of OptimisticLockException exceeded", e ) ) .onErrorResume(withMDC(e -> { log.error("error on transfer", e); return Mono.error(e); }));}
Стало:
suspend fun transfer(transactionKey: String, fromAccountId: Long, toAccountId: Long, amount: BigDecimal) { try { try { retry(limitAttempts(3) + filter { it is OptimisticLockException }) { val foundTransaction = transactionRepository .findByUniqueKey(transactionKey) if (foundTransaction != null) { logger.warn("retry of transaction $transactionKey") return@retry } val fromAccount = accountRepository.findById(fromAccountId) ?: throw AccountNotFound() val toAccount = accountRepository.findById(toAccountId) ?: throw AccountNotFound() if (fromAccount.amount - amount < BigDecimal.ZERO) { throw NotEnoghtMoney() } val transactionToInsert = Transaction( amount = amount, fromAccountId = fromAccountId, toAccountId = toAccountId, uniqueKey = transactionKey ) transactionalOperator.executeAndAwait { try { transactionRepository.save(transactionToInsert) } catch (e: DataIntegrityViolationException) { if (e.message?.contains("TRANSACTION_UNIQUE_KEY") != true) { throw e; } } accountRepository.transferAmount( fromAccount.id!!, fromAccount.version, amount.negate() ) accountRepository.transferAmount( toAccount.id!!, toAccount.version, amount ) } } } catch (e: OptimisticLockException) { throw ResponseStatusException( BANDWIDTH_LIMIT_EXCEEDED, "limit of OptimisticLockException exceeded", e ) } } catch (e: Exception) { logger.error(e) { "error on transfer" } throw e; }}
Stacktraces
Пожалуй, это самое главное.
Было:
o.s.w.s.ResponseStatusException: 509 BANDWIDTH_LIMIT_EXCEEDED "limit of OptimisticLockException exceeded"; nested exception is c.g.c.v.r.OptimisticLockExceptionat c.g.c.v.r.services.Ledger.lambda$transfer$5(Ledger.java:75)...Caused by: c.g.c.v.r.OptimisticLockException: nullat c.g.c.v.r.repos.AccountRepositoryImpl.lambda$transferAmount$0(AccountRepositoryImpl.java:27)at r.c.p.MonoFlatMap$FlatMapMain.onNext(MonoFlatMap.java:125) ...
Стало:
error on transfer o.s.w.s.ResponseStatusException: 509 BANDWIDTH_LIMIT_EXCEEDED "limit of OptimisticLockException exceeded"; nested exception is c.g.c.v.r.OptimisticLockExceptionat c.g.c.v.r.services.Ledger.transfer$suspendImpl(Ledger.kt:70)at c.g.c.v.r.services.Ledger$transfer$1.invokeSuspend(Ledger.kt)...Caused by: c.g.c.v.r.OptimisticLockException: nullat c.g.c.v.r.repos.AccountRepositoryImpl.transferAmount(AccountRepositoryImpl.kt:24)...at c.g.c.v.r.services.Ledger$transfer$3$1.invokeSuspend(Ledger.kt:65)at c.g.c.v.r.services.Ledger$transfer$3$1.invoke(Ledger.kt)at o.s.t.r.TransactionalOperatorExtensionsKt$executeAndAwait$2$1.invokeSuspend(TransactionalOperatorExtensions.kt:30)(Coroutine boundary)at o.s.t.r.TransactionalOperatorExtensionsKt.executeAndAwait(TransactionalOperatorExtensions.kt:31)at c.g.c.v.r.services.Ledger$transfer$3.invokeSuspend(Ledger.kt:56)at com.github.michaelbull.retry.RetryKt$retry$3.invokeSuspend(Retry.kt:38)at c.g.c.v.r.services.Ledger.transfer$suspendImpl(Ledger.kt:35)at c.g.c.v.r.controllers.LedgerController$transfer$2$1.invokeSuspend(LedgerController.kt:20)at c.g.c.v.r.controllers.LedgerController$transfer$2.invokeSuspend(LedgerController.kt:19)at kotlin.reflect.full.KCallables.callSuspend(KCallables.kt:55)at o.s.c.CoroutinesUtils$invokeSuspendingFunction$mono$1.invokeSuspend(CoroutinesUtils.kt:64)(Coroutine creation stacktrace)at k.c.i.IntrinsicsKt__IntrinsicsJvmKt.createCoroutineUnintercepted(IntrinsicsJvm.kt:122)at k.c.i.CancellableKt.startCoroutineCancellable(Cancellable.kt:30)...Caused by: c.g.c.v.r.OptimisticLockException: nullat c.g.c.v.r.repos.AccountRepositoryImpl.transferAmount(AccountRepositoryImpl.kt:24)...at c.g.c.v.r.services.Ledger$transfer$3$1.invokeSuspend(Ledger.kt:65)at c.g.c.v.r.services.Ledger$transfer$3$1.invoke(Ledger.kt)at o.s.t.r.TransactionalOperatorExtensionsKt$executeAndAwait$2$1.invokeSuspend(TransactionalOperatorExtensions.kt:30)...
Скучные части стектрейсов я вырезал, пакеты сократил (забочусь о читателе, и без того длинно).
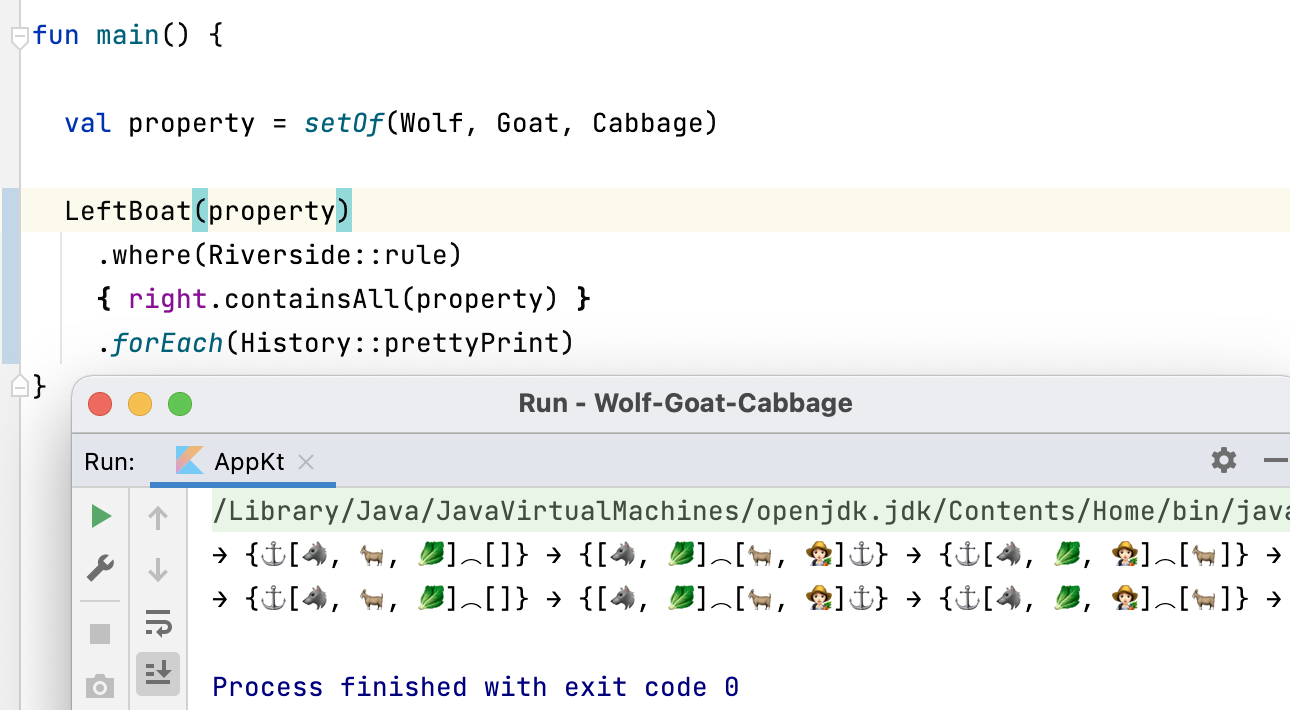
В Java очень куцая информация. Да, ошибка есть. Даже видно на какой строчке она вылетела. Только непонятно а как мы в эту строчку кода попали. В Kotlin версии виден весь трейс от контроллера.
Вот представьте себе, что вы видите ошибку в логе где-то на обращении в регулярно вызываемый метод. А кто его вызывал? Придётся по логам рядом искать. Это хорошо, если логи объединены через что-нибудь вроде traceId (thread name нам не поможет) и вообще логи есть.
Сложность кода
Kotlin версия выглядит проще, точно так же, как выглядел бы код на блокирующих технологиях. По крайне мере пока мы не вводим параллельные операции (тут ещё вопрос какой вариант сложнее писать: на блокирующих технологиях или с корутинами).
Многоступенчатая вложенность кода
Никаких flatMap. Добавились вложения из-за явных try catch, но схожая логика вся объявлена на одном уровне.
Было:
return accountRepository.findById(fromAccountId) .switchIfEmpty(Mono.error(new AccountNotFound())) .flatMap(fromAccount -> accountRepository.findById(toAccountId) .switchIfEmpty(Mono.error(new AccountNotFound())) .flatMap(toAccount -> { ... })
Стало:
val fromAccount = accountRepository.findById(fromAccountId) ?: throw AccountNotFound()val toAccount = accountRepository.findById(toAccountId) ?: throw AccountNotFound()...
Обработка ошибок и их выброс
Обработка ошибок теперь через обычный try catch, легко понять какой кусок кода мы обернули.
Было:
return transactionRepository.findByUniqueKey(transactionKey) ... .onErrorMap( OptimisticLockException.class, e -> new ResponseStatusException( BANDWIDTH_LIMIT_EXCEEDED, "limit of OptimisticLockException exceeded", e ) )
Стало:
try { val foundTransaction = transactionRepository .findByUniqueKey(transactionKey) ...} catch (e: OptimisticLockException) { throw ResponseStatusException( BANDWIDTH_LIMIT_EXCEEDED, "limit of OptimisticLockException exceeded", e )}
Ошибки выбрасывать можно просто через throw, а не возвращая объект ошибки. В Reactor меня особенно раздражают конструкции вида:
.flatMap(foo -> { if (foo.isEmpty()) { return Mono.error(new IllegalStateException()); } else { return Mono.just(foo); }})
Мне могут возразить, что это функциональный стиль, так и должно быть. Но именно из-за функционального стиля появляется дополнительная сложность кода.
Mono.empty()
Это заслуживает отдельного обсуждения. В реактор нельзя передавать null в качестве результата. При этом нельзя написать C5C.
Ide никак тебе не подсказывает, может ли этот конкретный mono быть пустым и обработал ли ты это. В рабочем проекте для меня именно это было источником тупых ошибок. То забудешь обработать, то после рефакторинга как-то не так работает.
В Kotlin будет not null тип, если ты точно знаешь, что результат будет. Или это будет nullable тип и компилятор обяжет тебя что-то с этим сделать.
Конкретно на нашем примере:
Было:
return transactionRepository.findByUniqueKey(transactionKey) .map(Optional::of) .defaultIfEmpty(Optional.empty()) .flatMap(foundTransaction -> { if (foundTransaction.isPresent()) { log.warn("retry of transaction " + transactionKey); return Mono.empty(); }...
Стало:
val foundTransaction = transactionRepository .findByUniqueKey(transactionKey)if (foundTransaction != null) { logger.warn("retry of transaction $transactionKey") return@retry}...
Может, как-то можно эту логику написать адекватнее на Reactor, но то что я нагуглил выглядит ещё хуже.
Логирование и контекст
Допустим, мы хотим всегда логировать traceId во время обработки запроса. ThreadLocal больше не работает, в том числе и MDC (контекст для логирования). Что делать?
Есть контекст. И в Reactor и в Coroutines контекст immutable, так что новое значение в MDC подбрасывать будет не так просто (нужно пересоздавать контекст).
Чтобы работало в Java надо написать фильтр, который сохранит traceId в контекст:
@Componentpublic class TraceIdFilter implements WebFilter { @Override public Mono<Void> filter( ServerWebExchange exchange, WebFilterChain chain ) { var traceId = Optional.ofNullable( exchange.getRequest().getHeaders().get("X-B3-TRACEID") ) .orElse(Collections.emptyList()) .stream().findAny().orElse(UUID.randomUUID().toString()); return chain.filter(exchange) .contextWrite(context -> LoggerHelper.addEntryToMDCContext(context, "traceId", traceId) ); }}
И каждый раз, когда мы хотим что-то залогировать, надо переносить traceId из контекста в MDC:
public static <T, R> Function<T, Mono<R>> withMDC( Function<T, Mono<R>> block) { return value -> Mono.deferContextual(context -> { Optional<Map<String, String>> mdcContext = context .getOrEmpty(MDC_ID_KEY); if (mdcContext.isPresent()) { try { MDC.setContextMap(mdcContext.get()); return block.apply(value); } finally { MDC.clear(); } } else { return block.apply(value); } });}
Да, это опять Mono. Т.е. мы можем логировать только тогда, когда код позволяет вернуть Mono. Например вот так:
.onErrorResume(withMDC(e -> { log.error("error on transfer", e); return Mono.error(e);}))
В Kotlin проще. Нужно написать фильтр, чтобы сохранить traceId сразу в MDC:
@Componentclass TraceIdFilter : WebFilter { override fun filter( exchange: ServerWebExchange, chain: WebFilterChain ): Mono<Void> { val traceId = exchange.request.headers["X-B3-TRACEID"]?.first() MDC.put("traceId", traceId ?: UUID.randomUUID().toString()) return chain.filter(exchange) }}
И при создании корутины вызывать withContext(MDCContext())
{ }
Каждый раз на время работы корутины, будет восстанавливаться MDC и в логах будет traceId. Во время записи в лог ни о чем задумываться не нужно.
Тут есть одно НО, об этом позже.
Дебаг
В Java Reactor проблемы с дебагом примерно те же, что и со стектрейсом: нужно думать о том, кто в каком порядке кого вызвал, ставить breakpoints в лямбдах и т.д..
С корутинами не замечаешь разницы с обычным кодом: работает stepOver, переменные подсвечиваются, видно стектрейс и по нему можно перемещаться (в нашем примере вплоть до контроллера).
Всё идеально, кроме возможности запускать suspend функции во время дебага. На это уже есть issue. Правда, надо сказать, что и в Java Reactor особо не получается в evaluate сделать то, что хочется.
Параллелизация
Предположим, я хочу ускорить алгоритм и запросить из базы аккаунты и транзакции параллельно, а не последовательно как сейчас.
Было:
return Mono.zip( transactionRepository.findByUniqueKey(transactionKey) .map(Optional::of) .defaultIfEmpty(Optional.empty()), accountRepository.findById(fromAccountId) .switchIfEmpty(Mono.error(new AccountNotFound())), accountRepository.findById(toAccountId) .switchIfEmpty(Mono.error(new AccountNotFound())),).flatMap(withMDC(fetched -> { var foundTransaction = fetched.getT1(); var fromAccount = fetched.getT2(); var toAccount = fetched.getT3(); if (foundTransaction.isPresent()) { log.warn("retry of transaction " + transactionKey); return Mono.empty(); } ...}
Стало:
val foundTransactionAsync = GlobalScope.async(coroutineContext) { logger.info("async fetch of transaction $transactionKey") transactionRepository.findByUniqueKey(transactionKey)}val fromAccountAsync = GlobalScope.async(coroutineContext) { accountRepository.findById(fromAccountId) }val toAccountAsync = GlobalScope.async(coroutineContext) { accountRepository.findById(toAccountId) }if (foundTransactionAsync.await() != null) { logger.warn("retry of transaction $transactionKey") return@retry}val fromAccount = fromAccountAsync.await() ?: throw AccountNotFound()val toAccount = toAccountAsync.await() ?: throw AccountNotFound()
В Kotlin версии есть явное указание вот это выполни асинхронно, вместо выполни всё это в параллель в Reactor.
Что самое важное, код ведёт себя по-разному. В случае с Reactor мы создаем три параллельных запроса и продолжаем работу только после того, как все три завершатся. С корутинами мы запускаем все три запроса и ждать чего-то начинаем только при вызове foundTransactionAsync.await(). Таким образом, если transactionRepository.findByUniqueKey() выполнится быстрее, то мы завершим обработку, без ожидания accountRepository.findById() (эти операции отменятся).
В более сложных алгоритмах разница будет ощутимей. Не уверен, что вообще в Reactor получится написать такую версию алгоритма:
val foundTransactionAsync = GlobalScope.async(coroutineContext) { logger.info("async fetch of transaction $transactionKey") transactionRepository.findByUniqueKey(transactionKey)}val fromAccountAsync = GlobalScope.async(coroutineContext) { accountRepository.findById(fromAccountId)}val toAccountAsync = GlobalScope.async(coroutineContext) { accountRepository.findById(toAccountId)}if (foundTransactionAsync.await() != null) { logger.warn("retry of transaction $transactionKey") return@retry}val transactionToInsert = Transaction( amount = amount, fromAccountId = fromAccountId, toAccountId = toAccountId, uniqueKey = transactionKey)transactionalOperator.executeAndAwait { try { transactionRepository.save(transactionToInsert) } catch (e: DataIntegrityViolationException) { if (e.message?.contains("TRANSACTION_UNIQUE_KEY") != true) { throw e; } } val fromAccount = fromAccountAsync.await() ?: throw AccountNotFound() val toAccount = toAccountAsync.await() ?: throw AccountNotFound() if (fromAccount.amount - amount < BigDecimal.ZERO) { throw NotEnoghtMoney() } accountRepository.transferAmount( fromAccount.id!!, fromAccount.version, amount.negate() ) accountRepository.transferAmount( toAccount.id!!, toAccount.version, amount )}
Здесь я ожидаю асинхронный запрос уже внутри открытой БД транзакции. Т.е. мы при работе с одним коннектом, ждём результата выполнения на другом коннекте. Так делать не стоит, скорее для примера, хоть оно и работает (пока коннектов хватает).
Побочные эффекты
Конечно, есть проблемы, куда без них.
Надо явно указывать context и scope
Чтобы программа работала как ожидается, надо:
-
Каждому запросу назначить scope. Таким образом все порождаемые при обработке запроса корутины будут отменены все вместе, например, в случае ошибки.
-
В каждом запросе проставить context. Зачем нам нужен контекст я рассказывал в разделе про логирование.
Spring не берет на себя заботу об этом вопросе, приходится в контроллере указывать явно:
@PutMapping("/transfer")suspend fun transfer(@RequestBody request: TransferRequest) { coroutineScope { withContext(MDCContext()) { ledger.transfer(request.transactionKey, request.fromAccountId, request.toAccountId, request.amount) } }}
Естественно, можно объединить в одну функцию и потом через regexp проверить, что во всех методах есть нужный вызов. Но лучше была бы какая-то автоматизация для этого.
Передача context
В случае, если мы порождаем дополнительные корутины, необходимо явным образом передать текущий контекст. Вот пример:
val foundTransactionAsync = GlobalScope.async(coroutineContext) { logger.info("async fetch of transaction $transactionKey") transactionRepository.findByUniqueKey(transactionKey)}
По-умолчанию в async() указывать контекст не требуется (он будет пуст). Видимо, чтобы было меньше неявных вещей. Но как итог, в нашем случае, если забыть передать контекст, в логе не окажется traceId. Помните я писал, что не надо задумываться во время логирования? Вместо этого надо задумываться при создании корутины (что, конечно, лучше).
AOP и suspend
Автоматизацию, которую я упоминал в первом пункте, написать самому сложно. Потому что пока нельзя нормально написать aspect для suspend функции.
Я в итоге сумел написать такой аспект. Но для объяснения того, как это работает понадобится отдельная статья.
Надеюсь, появится более адекватный способ писать аспекты (попробую этому посодействовать).
Оценка лечения
Все проблемы исчезли. Добавилась пара новых, но оно терпимо.
Надо сказать, что корутины быстро развиваются и я ожидаю только улучшения работы с ними.
Видно, что команда JetBrains внимательно отнеслась к проблемам разработчиков. Насколько я знаю, где-то год назад всё ещё были проблемы с дебагом и стактрейсом, к примеру.
Самое главное, с корутинами не надо в голове держать все особенности работы Reactor и его могучий API. Ты просто пишешь код.