Привет, я фронт, и за десять лет разработки в энтерпрайзах, стартапах и некрупных компаниях я впервые деплою свой код сам и отвечаю за его эксплуатацию, а не только за проектирование и разработку сервиса. О том, как я до этого дошел и почему не собираюсь останавливаться, в этой статье.

В нашей компании самостоятельный деплой это часть workflow многих разработчиков. Такая практика типична, скорее, для стартапов и редка в средних и крупных компаниях. Почему? Мне кажется, решение о полной передаче деплоя выделенным специалистам, играющим роль релиз-инженеров, происходит по вполне понятным причинам:
-
Разделение ответственности в ряде случаев ответственность за деплой оказывается высокой.
-
Необходимость в дополнительных навыках обычно нужно неплохо знать платформу, через которую происходит деплой, или хотя бы разбираться в скриптах вроде Capistrano.
-
Сложность инфраструктуры при деплое приходится учитывать массу поддерживающих сервисов, таких как меш-сети, очереди, воркеры, базы данных и т. д.
Как это происходит у нас
В Учи.ру был создан собственный инструмент для выкатки сервисов и настройки стейджей под названием Шаман по сути кастомный интерфейс к HashiCorp Nomad. Несколько лет назад он помог уйти от исполнения скриптов на локальных машинах, автоматизировать процесс деплоя и позволил разработчикам создавать тестовые конфигурации максимально быстро. Об этом мои коллеги из команды инфраструктуры написали отдельную статью.
Немного истории
С самого начала вся разработка у нас велась внутри одного-единственного монолитного репозитория, поэтому Шаман умел собирать его и выкатывать, при этом отлично справляясь со своей задачей. Но компания росла, а вместе с ней осваивались рынки, запускались новые проекты, добавляя перекрестные логические связи и в без того сложный код.
Но аве прогрессу подходы к разработке эволюционируют вместе с нами. Поэтому в какой-то момент, наевшись боли от того, что в монолит коммитят 200 человек, мы потихоньку начали откусывать от него небольшие семантически связанные куски и выносить их в сервисы. Со временем сервисов отпочковывалось все больше, а им, естественно, нужно как-то коммуницировать друг с другом сложность настройки приложений экспоненциально увеличивалась.
Да придет спаситель
И здесь Шаман действительно выручил, потому что настраивать такие связки вручную правильно и предсказуемо довольно непростая задача. Он абстрагировал сложность управления новыми машинами с массой параметров, раскладку на них сервисов через докер-контейнеры, настройку и регистрацию эндпоинтов этих сервисов в оркестраторе в общем, кучу вещей, которые объять каждому разработчику мозгом будет проблематично, да и, положа руку на сердце, не нужно. Вместо этого я вижу суровый, минималистичный, но тем не менее довольно понятный интерфейс, освобождающий меня от необходимости заглядывать в глаза бездне низкоуровневого администрирования.
А что делать, если тебе нужно поднять копию среды для тестирования второго релиза? Не создавать же всю связку целиком заново? А если ее незначительно видоизменить? Для подобного в Шамане есть возможность создать шаблон конфигурации, в котором с помощью YAML описана вся россыпь машин, сервисов и эндпоинтов. В результате, если ваша команда поддерживает свой шаблон, поднятие нового инстанса развесистой связки сервисов становится тривиальной задачей.
И, кажется, коллеги со мной согласны:
Лично для меня в деплое нет ничего сложного. И учитывая, что иногда мне приходится делать больше десяти тестовых выкаток в день, а также развертывания совершенно новых приложений, я очень рад, что не нужно каждый раз подключать кого-то из отдела инфраструктуры. Приложений у нас много, и возможность самостоятельной выкатки сильно упрощает жизнь и ускоряет работу, Роман Литвинов, ROR разработчик.
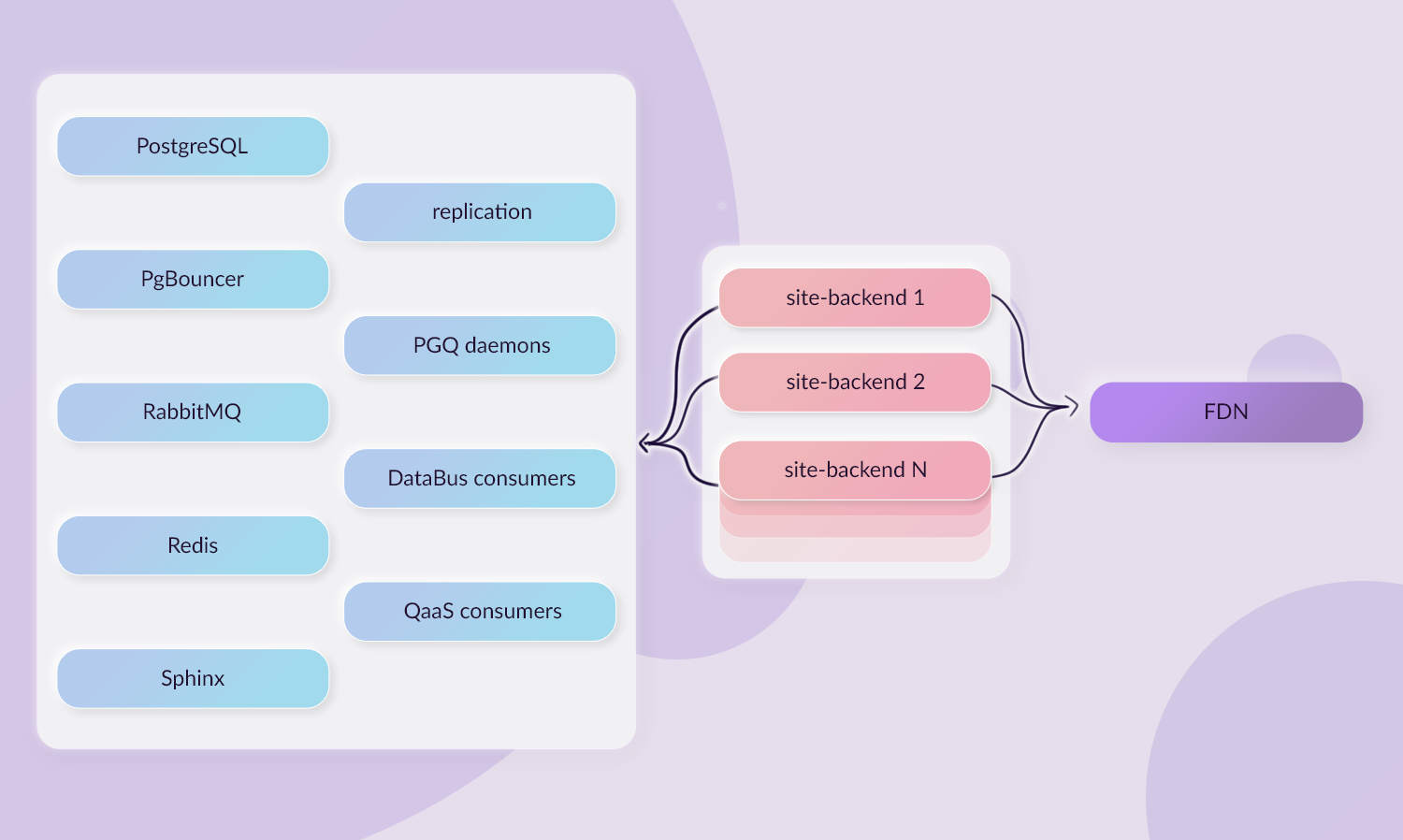
Схема связи Шамана с кодом
На данный момент почти все наши GitHub-репозитории собираются при помощи GitHub Actions, в результате чего докер-образ пушится в общую приватную докер-репу. Этот workflow можно триггерить как автоматически (пуш в релизную ветку), так и руками, если хочется потестить какой-то сиюминутный фикс. Дальше Шаман подцепляет свежий образ и по кнопке раскатывает его на стейдж. Ну не красота, а?
И так как этот процесс находится в ведении разработчиков чуть более чем полностью, у нас есть возможность его упрощать. Меня, например, все-таки расстраивает необходимость сначала идти в GitHub, чтобы посмотреть статус билда, а потом в Шаман чтобы нажать на заветную зеленую кнопку для выкатки образа. После незначительной встряски коллег из инфраструктуры выяснилось, что последний предоставляет API, ручку которого можно дернуть из Github Actions с адресом для деплоя и идентификатором образа для деплоя. А это значит, что деплоить код можно полностью автоматически!
Когда что то идёт не так
Понятное дело, что после выкатки кода на прод надо убедится, что он ведёт себя так, как задумано. И тут у нас чуть хуже с автоматизацией, но тем не менее всё под контролем. Для мониторинга мы используем сервис Sentry, который нотифицирует как о новых индивидуальных ошибках, так и об изменениях общего фона. Ну и продуктовые дашборды с метриками никто не отменял. А Шаман, в свою очередь, быстро и непринужденно позволяет откатить бажную версию фронтового приложения в случае серьезных проблем.
Так нужно ли деплоить разработчику?
Мой ответ да, если есть подобная система, упрощающая жизнь. Потому что твой сервис твоя крепость. И за него нужно нести ответственность на всех этапах, в том числе и в контексте выкаток. Да, это требует больше знаний, но наш отдел эксплуатации сделал крутую абстракцию, скрывающую большинство низкоуровневых процессов.
Такая схема позволяет не аккумулировать сделанные задачи в большие релизы, которые долго тестируются, а выкатывать их по мере готовности. Больше контроля и меньше вероятность ошибки.
Ну и вопрос времени: деплоить самому куда быстрее, чем отдавать релиз выделенным инженерам. Но, естественно, с допущениями:
-
Сервисы приходят и уходят, соответственно, шаблон связки сервисов нужно держать актуальным, иначе поднятие новых тестовых стендов превратится в боль.
-
Стоит держать в голове, что мы работаем с in-house-решением со всеми вытекающими: оно может сломаться. Поэтому здесь нужно быть достаточно открытым и помогать коллегам чинить проблему, а не бранить решение.
-
Такой подход требует высокого уровня развития процедур и процессов для сохранения качества и стабильности сервиса при высоком ритме выкаток, а также определенной смелости от ключевых стейхолдеров.
Как происходит деплой в вашей компании? Считаете ли вы наш подход с одной кнопкой оптимальным или вам нравятся другие варианты выкатки новых сервисов и обновлений? Поделитесь мнением в комментариях.