Originally published at deepu.tech.
In this multi-part series, I aim to demystify the concepts behind memory management and take a deeper look at memory management in some of the modern programming languages. I hope the series would give you some insights into what is happening under the hood of these languages in terms of memory management. Learning about memory management will also help us to write more performant code as the way we write code also has an impact on memory management regardless of the automatic memory management technique used by the language.
Part 1: Introduction to Memory management
Memory management is the process of controlling and coordinating the way a software application access computer memory. It is a serious topic in software engineering and its a topic that confuses some people and is a black box for some.
What is it?
When a software runs on a target Operating system on a computer it needs access to the computers RAM(Random-access memory) to:
- load its own bytecode that needs to be executed
- store the data values and data structures used by the program that is executed
- load any run-time systems that are required for the program to execute
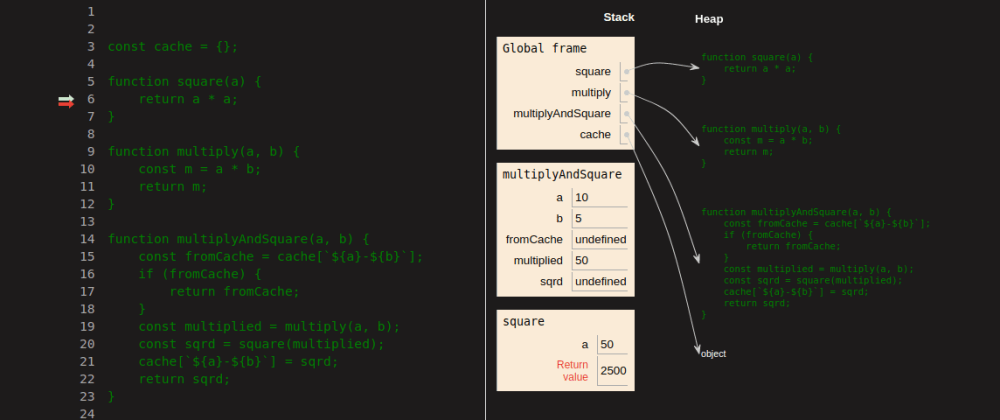
When a software program uses memory there are two regions of memory they use, apart from the space used to load the bytecode, Stack and Heap memory.
Stack
The stack is used for static memory allocation and as the name suggests it is a last in first out(LIFO) stack (Think of it as a stack of boxes).
- Due to this nature, the process of storing and retrieving data from the stack is very fast as there is no lookup required, you just store and retrieve data from the topmost block on it.
- But this means any data that is stored on the stack has to be finite and static(The size of the data is known at compile-time).
- This is where the execution data of the functions are stored as stack frames(So, this is the actual execution stack). Each frame is a block of space where the data required for that function is stored. For example, every time a function declares a new variable, it is "pushed" onto the topmost block in the stack. Then every time a function exits, the topmost block is cleared, thus all of the variables pushed onto the stack by that function, are cleared. These can be determined at compile time due to the static nature of the data stored here.
- Multi-threaded applications can have a stack per thread.
- Memory management of the stack is simple and straightforward and is done by the OS.
- Typical data that are stored on stack are local variables(value types or primitives, primitive constants), pointers and function frames.
- This is where you would encounter stack overflow errors as the size of the stack is limited compared to the Heap.
- There is a limit on the size of value that can be stored on the Stack for most languages.

Stack used in JavaScript, objects are stored in Heap and referenced when needed. Here is a video of the same.
Heap
Heap is used for dynamic memory allocation and unlike stack, the program needs to look up the data in heap using pointers (Think of it as a big multi-level library).
- It is slower than stack as the process of looking up data is more involved but it can store more data than the stack.
- This means data with dynamic size can be stored here.
- Heap is shared among threads of an application.
- Due to its dynamic nature heap is trickier to manage and this is where most of the memory management issues arise from and this is where the automatic memory management solutions from the language kick in.
- Typical data that are stored on the heap are global variables, reference types like objects, strings, maps, and other complex data structures.
- This is where you would encounter out of memory errors if your application tries to use more memory than the allocated heap(Though there are many other factors at play here like GC, compacting).
- Generally, there is no limit on the size of the value that can be stored on the heap. Of course, there is the upper limit of how much memory is allocated to the application.
Why is it important?
Unlike Hard disk drives, RAM is not infinite. If a program keeps on consuming memory without freeing it, ultimately it will run out of memory and crash itself or even worse crash the operating system. Hence software programs can't just keep using RAM as they like as it will cause other programs and processes to run out of memory. So instead of letting the software developer figure this out, most programming languages provide ways to do automatic memory management. And when we talk about memory management we are mostly talking about managing the Heap memory.
Different approaches?
Since modern programming languages don't want to burden(more like trust 👅) the end developer to manage the memory of his/her application most of them have devised a way to do automatic memory management. Some older languages still require manual memory handling but many do provide neat ways to do that. Some languages use multiple approaches to memory management and some even let the developer choose what is best for him/her(C++ is a good example). The approaches can be categorized as below
Manual memory management
The language doesn't manage memory for you by default, it's up to you to allocate and free memory for the objects you create. For example, C and C++. They provide the malloc, realloc, calloc, and free methods to manage memory and it's up to the developer to allocate and free heap memory in the program and make use of pointers efficiently to manage memory. Let's just say that it's not for everyone 😉.
Garbage collection(GC)
Automatic management of heap memory by freeing unused memory allocations. GC is one of the most common memory management in modern languages and the process often runs at certain intervals and thus might cause a minor overhead called pause times. JVM(Java/Scala/Groovy/Kotlin), JavaScript, C#, Golang, OCaml, and Ruby are some of the languages that use Garbage collection for memory management by default.
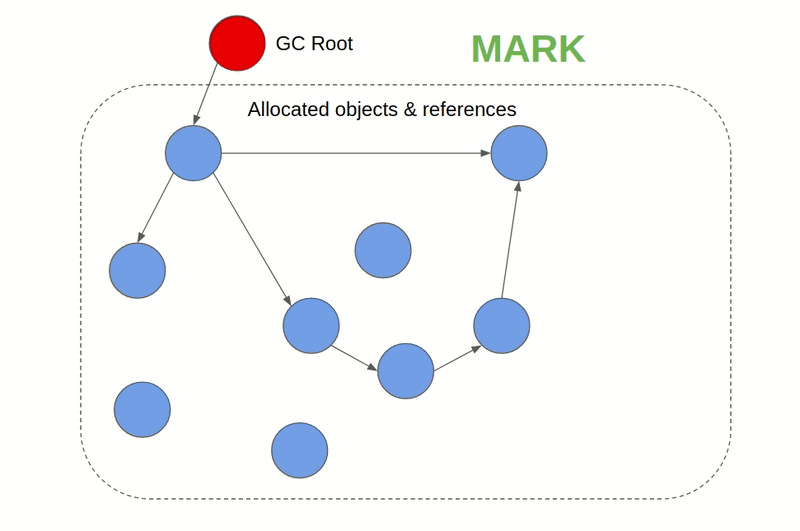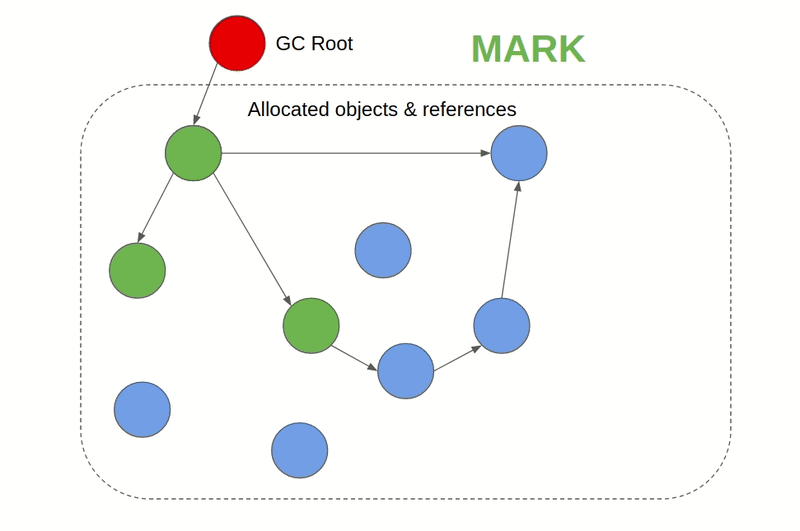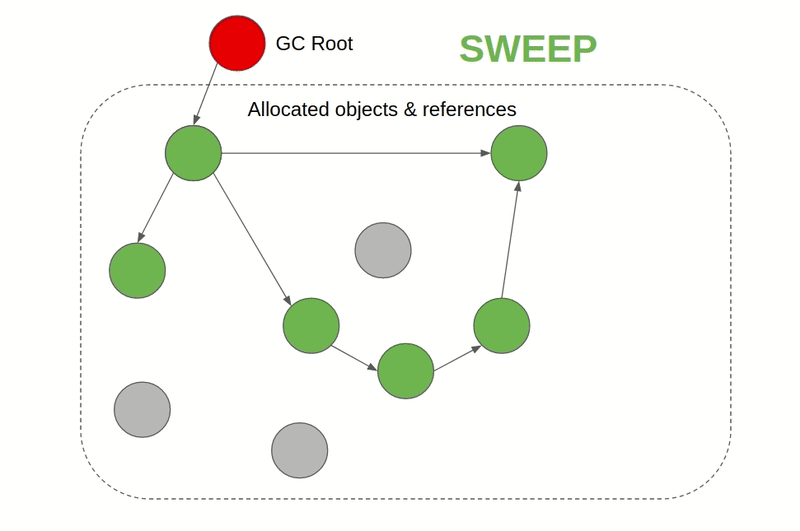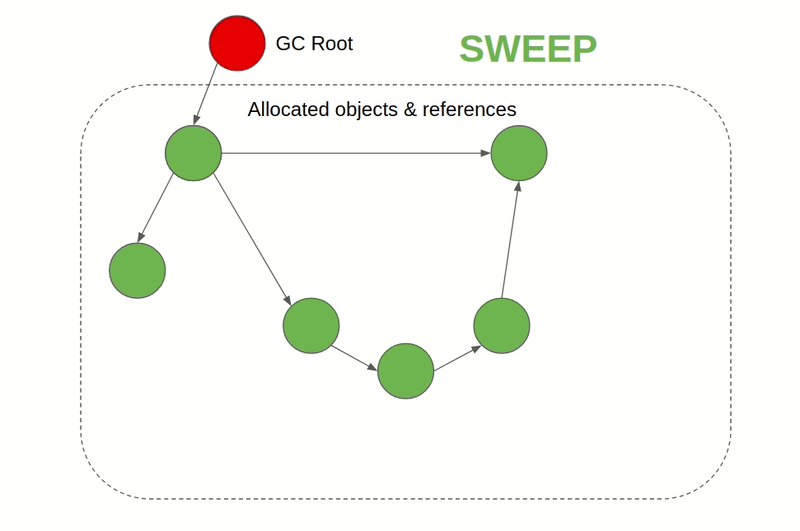
- Mark & Sweep GC: Also known as Tracing GC. Its generally a two-phase algorithm that first marks objects that are still being referenced as "alive" and in the next phase frees the memory of objects that are not alive. JVM, C#, Ruby, JavaScript, and Golang employ this approach for example. In JVM there are different GC algorithms to choose from while JavaScript engines like V8 use a Mark & Sweep GC along with Reference counting GC to complement it. This kind of GC is also available for C & C++ as an external library.
- Reference counting GC: In this approach, every object gets a reference count which is incremented or decremented as references to it change and garbage collection is done when the count becomes zero. It's not very preferred as it cannot handle cyclic references. PHP, Perl, and Python, for example, uses this type of GC with workarounds to overcome cyclic references. This type of GC can be enabled for C++ as well.
Resource Acquisition is Initialization (RAII)
In this type of memory management, an object's memory allocation is tied to its lifetime, which is from construction until destruction. It was introduced in C++ and is also used by Ada and Rust.
Automatic Reference Counting(ARC)
It's similar to Reference counting GC but instead of running a runtime process at a specific interval the retain and release instructions are inserted to the compiled code at compile-time and when an object reference becomes zero its cleared automatically as part of execution without any program pause. It also cannot handle cyclic references and relies on the developer to handle that by using certain keywords. Its a feature of the Clang compiler and provides ARC for Objective C & Swift.
Ownership
It combines RAII with an ownership model, any value must have a variable as its owner(and only one owner at a time) when the owner goes out of scope the value will be dropped freeing the memory regardless of it being in stack or heap memory. It is kind of like Compile-time reference counting. It is used by Rust, in my research I couldn't find any other language using this exact mechanism.

We have just scratched the surface of memory management. Each programming language uses its own version of these and employs different algorithms tuned for different goals. In the next parts of the series, we will take a closer look at the exact memory management solution in some of the popular languages.
Stay tuned for upcoming parts of this series:
- Part 2: Memory management in JVM(Java, Kotlin, Scala, Groovy)
- Part 3: Memory management in V8(JavaScript/WebAssembly)
- Part 4: Memory management in Go
- Part 5: Memory management in Rust
- Part 6: Memory management in Python
References
- homepages.inf.ed.ac.uk
- javarevisited.blogspot.com
- net-informations.com
- gribblelab.org
- medium.com/computed-comparisons
- en.wikipedia.org/wiki/Garbage-collection
- en.wikipedia.org/wiki/Automatic-Reference-Counting
- blog.sessionstack.com
If you like this article, please leave a like or a comment.
You can follow me on Twitter and LinkedIn.
Image credits:
Stack visualization: Created based on pythontutor.
Ownership illustration: Link Clark, The Rust team under Creative Commons Attribution Share-Alike License v3.0.





Top comments (56)
Nice article! 😊
I'll just throw in a couple feedbacks:
%espor from some other location. The only speed difference there could be based on whether the target memory page is cached or not, but the stack is not any faster per se than the heap. And in both case there's still the same exact "lookup" (dereference).%esp.%esp + offset.I want to repeat it, the article is very well written and you did a great job, I'm just giving you my 2 cents here about a couple of details I noticed.
Cheers!
The statement about the stack not being faster than the heap is only in the fact that at the moment you have the address, the time to read/write is the same. The problem is that semantically, the stack addresses are known (through the Stack Pointer and Frame Pointer as well). As the author said, there is no such thing as a Heap Pointer (it just doesn't make sense). In that regard, let's say we have 2 integers in C like this:
First of all, it is clear that creating an element in the stack is way faster than the heap since
mallocneeds to find a place to put the continuous 32-bits (or 64-bits) free memory. This is because the stack just needs to look up the Stack pointer, add the element and move the stack pointer accordingly.After that, modifying an element in the stack is easy since it is basically an offset of the Stack pointer. But for the heap, first, you need to find the pointer in the stack, from that pointer you get the address in the heap and then you can read or write at that address.
And I didn't talk about the difference between reading address by offset vs full address since a lot of CPU have instruction sets that are too small to handle the full address in one instruction.
In conclusion, Stack is faster than Heap only because of the Stack Pointer.
I believe there has been a misunderstanding here. If you go back and read my original comment, I've made it clear that when I said the stack was equally as fast as the heap, it was in direct read/write operations to a memory location in either of those two segments. You can't compare a read/write to a local value type variable to one to a reference variable, for obvious reasons - those are handled differently. And you can't take the overhead of a
malloccall into consideration, or the garbage collection cost, that was completely besides my point, and I did mention that in my original message.What I said was that reading or writing to a specific memory location has always the same performance, regardless of whether that memory location is situation, be it in the stack or the heap.
As a practical example. Suppose you allocate a buffer of
intvalues on the stack, and one on the heap, and end up with twoint*pointers. One points to the buffer in the stack, one in the heap. If you read/write to any of those two pointers, the operation will be exactly the same down to the assembly level, and the performance will be exactly the same too.As another example, suppose you have a local value type variable, and you pass it by reference to another function. That function will have no way of knowing whether that reference points to a variable in some other stack frame, or to a memory location in the heap, and that makes absolutely no difference at all. Again, both cases are compiled to exactly the same instructions, it's just a pointer of some type anyway.
In conclusion, the speed of an operation is not intrinsically linked to where a value is located in the virtual memory address space, but just to how you're accessing that location.
I hope this clears things up regarding my original point on that 👍
EDIT: just to clarify, you do have a pointer lookup in both cases though. If you have a pointer to a heap location eg. in
%ecxand want to read that value, you'll domovl eax, [ecx]. If you want to read the value at the top of the stack, you'll domovl eax, [esp]. In both cases the operation is exactly the same and you do have an address lookup just the same. So you saying that you never look addresses up when accessing the stack is just not the case. You're correct in saying that if you have a pointer on the heap stored on the stack you need two dereferences there, sure. But even in the best case scenario on the stack, you still need at least one anyway. And if you have a pointer in a given register, reading from that location has exactly the same cost no matter if it points to somewhere in the heap or the stack.Your last edit is exactly the point, from a language point we care about cost of operation when we talk about speed, and the cost of operation for the stack is lower than heap and that is why we say stack is faster than the heap. The actual speed of writing/reading from any part of memory indeed is the same but for heap, there are more operations involved than stack when writing/reading value making the cost of operation higher for the heap.
That is not true, since in the stack everything is offset of the stack pointer that is in the CPU registers. So, for example in ARM CPUs, it will take something like 3 instructions to retrieve any of the int in the buffer sitting in the stack. On the situation of the one on the heap, the first element will take something like 4 instructions since you need to set a register with the address you will find on the stack (the pointer of your heap buffer), and AFTER the other elements will be read AS FAST AS the stack since the other int element of the buffer are an offset of that value. And like I said earlier, if you have the address as a label, you will need 2 instructions to set your register before LDR/STR that memory block.
I think what you are trying to say is that at the time you have the address loaded in a register, the read time will be the same, which is true. The danger is that people might believe it is always the best solution to use the heap since it is so large, but doesn't account for the way it is handled. Embedded systems are very sensitive to this considering low frequency (very so often below 100 MHz), no OS and small memory footprint. The good practice, in that case, is only to use the heap with object allocated at startup so there is NO malloc anywhere, making sure the system stays deterministic. I know that in a 12-core i9 CPU clocks at 4GHz, the impact on most of the system people work (except OS for that matter, or video games) will be so negligible.
This is what I have been trying to say, but I think you said it better :)
Thank you for the detailed feedback. I really appreciate it. Before I respond, let me put on a disclaimer 😉 I'm not a computer memory expert(I do not have a computer science background, I'm an electrical engineering major) so please bear with me.
Some of your points contradict what I have learned and what the language documentation regarding these concepts says. But I'm interested in learning more about your point of view, would you be kind enough to share some resources which detail these further, especially point 1 & 3.
Now, based on what I have learned and researched:
If we talk about absolute speed in terms of nanoseconds or less, the stack access should be faster than the heap access for various reasons. Heap is generally fragmented and the process needs to get a pointer address from the stack and look that up from the fragmented heap space. Some languages optimize the fragmentation during GC to reduce overhead. The same overhead is also present during normal operation though that is negligible. Now, to access from stack no pointer lookup is required as you just need to look at the block on top of the stack. So in terms of absolute speed, there is a difference as you need to get a pointer from the stack and fetch it from the heap. But I guess the difference is pretty negligible given the speed of the current hardware we have. Correct me if I'm wrong here, and would appreciate some resource explaining that.
Agree, and I believe I never said that this is not possible, I just said that any data stored on the stack must be finite in size(known at compile-time, hence no growing strings for example.
Well, this contradicts every definition of a stack I have seen, and so far I never found any resource which says that the stack memory is not FIFO. My understanding was that in order to read from the stack you need to pop it first. Now entire stack frames are pushed/popped and treated like individual blocks I believe and hence a function can read/write all its local values in any order in this block space, is that what you mean? If not, could you give me some reference explaining this in more detail?
same as 1, I'll update the post to say that I'm talking about the process of accessing the data on the heap and not heap itself, which I agree cannot be slower than stack as it's on the same RAM.
Agree, I think what I wrote might not be very generic and could have implications based on implementations used by the language as well. For example, in Java, you used to have the ability to control the max space that can be used for Heap and my point was more from such an angle. But you are right there are lot more factors to take into account. I'll try to explain more clearly in upcoming chapters so that it's more specific to how particular language behaves.
Again thank you very much for the detailed response. Look forward to learning more. I'll update the post to make some points clearer, let me know if you find it to be better
Hey, no problem, glad I could help, and I'm always interested in sparking up a discussion where everyone can hopefully learn something new 😄
To reply to your points:
Stack and heap are just two segments in the virtual address space of a process. They only real difference is the range of addresses they use, but they're fundamentally exactly the same: a given area in the virtual address space. Hence, the access time is exactly the same: in both case you'd still be dereferencing a pointer. I think you might be confusing what you see in a high level language (like Java, or even C) with what is actually happening at the hardware level (I mean in assembly). Even if you have a local value type variable in a function in Java, when you read it the CPU will still use a pointer to read it from the stack. The only difference is that the address in this case is automatically calculated by adding a certain offset to the
%espregister, which is a CPU register that always points to the top of the stack. Whereas with an object in the heap you'd be manually keeping track of the reference to it (either via a raw pointer in C#, or through a managed pointer in a managed language like Java). The GC doesn't have anything to do with this, nor does the possible fragmentation of the heap itself. The moment you're trying to read any value from your virtual address space you're always going to just load a pointer to your target location (be it in the heap or the stack) and then dereference it. Actually, in assembly it's even the same exact instruction (mov, in general) - the CPU doesn't really care what segment that address belong to at all. What's more, in many languages (eg. C, C++, C#) you can even get pointers to local variables on the stack, and pass those to functions. Once you're inside a function, that function can't possibly know (nor does it care either) whether that pointer actually points to a variable in the heap or the stack, but again, that doesn't matter. It's the same exact behavior, and the speed is the same too. As I've mentioned, the heap is generally considered slower because people associate the actual allocation cost to it, and the garbage collection cost. But just reading/writing data to it is equally as fast as doing so on the stack.I agree that the data on the stack must be finite in size (though the same could be said for the heap as well, the limit is just bigger but it's still finite), my point was that you don't need to know at compile time the amount of data stored on the stack at all. You could very much have a function that takes an
intand then allocates a buffer ofinton the stack, with a length equal to that inputint. In that case you'd have absolutely no way of knowing the size of that buffer at compile time, and yet the buffer is created on the stack just fine.Sure thing, you can read up here for instance. The stack is generally referred to as LIFO since that's the way new values are pushed and popped to it, including stack frames during function calls, but as I said you can actually read/write at any position in the stack at all times. There's a CPU register called
%esp(Stack Pointer) which keeps the address to the top of the stack, and you can index any position in the stack by just adding an offset to that address and dereferencing it. For instance, consider this function and the resulting assembly x86:You can see that while the compiler is passing the
aandbparameter through theecxandedxregisters to minimize memory access, thecanddparameters are passed through the stack, and they're being read with that[esp+0x4]and[esp+0x8]addresses, which are not the top of the stack. This happens all the time, eg. when you have many local parameters in a function that can't all fit in a register and need to be stored on the stack (which is much slower). Point is: you can read/write from any position within the stack with no problems, you're absolutely not limited to just the top value.Hope this helps, let me know if there's anything else! 😄
Hey, thanks for the quick response. Actually I updated my comment above as I made a mistake there, right before you added this reply, could you take a look? I'll respond to this once you have seen the update to avoid any confusion.
I've seen the updates, but what I said in my last comment still applies, so it's fine, you can go ahead and read/reply to that one if you want 😊
Thanks again. I did learn something new now.
I guess you are talking from a lower level, like assembly, point of view and I'm talking from a high-level language point of view.
I'm talking about individual data(variables & constants) and it has to be finite at compile time for most languages(Java, Rust, Go, etc) to be on Stack and you cannot have buffers on the stack in these and since the language automatically manages these we have no control over this. I guess C/C++ is an exception when you manage memory yourself, but then again they are very low-level languages. So yes this is very much language-dependent I would say but holds for most languages IMO.
Yes, it makes absolute sense at a low level. At a higher level, its easier to talk of it as LIFO though as the inner process is not exposed to end users in most languages
Add Nim to the series, has all those, including a Rust-like memory management, including Manual memory management too, has like +6 GC, you can configure them, and more.
Will give you a lot to write about. :)
Thanks for the comment. However, Nim does reference counting and GC, I don't think it's Rust like
Nim has 6 GCs - The default one is a reference counting one. See the nim documentation for more details
Nim calls all of them "GC" to keep things simple for new users,
but Nim memory management strategies may or may not fit the "Garbage Collector" definition whatsoever.
Ive meet people that considers whatever Rust uses a Garbage Collector too.
🤷♀️
Thanks and Yes, I'm aware. They did go all the way on the GC part 😜
Technically they all fit under definition of GC IMO. They don't have ARC or Ownership as far as I see
--gc:arcflat reference counting with move semantics and destructors with single ownership,
optimized with
sinkandlentannotations for zero-copy all the way is annotated,basically it is like a shared heap with subgraphs with a single owner,
all this is done at compile-time, and ownership can be checked at run-time too.
Not really a GC despite
--gc:.Not really the same as Swift and ObjectiveC lang ARC because those can not handle cycles.
Not really Atomic despite
ARC,it wont need atomic reference counting,
a graph is always owned by a single owner,
then no need to make the reference counting atomic
(real atomic is known to be kinda slow).
Well, in that case, it's just bad grouping coz ARC is not GC. And seems these are buried in the docs somewhere.
Just a little thing to add about heap memory: overtime, the heap become non-deterministic since the search for free memory takes more time. It has more impact on embedded system development though.
Great job.
Thank you and that makes sense.
The Rust example (in the graphic) is not a compiler error (for quiet sometime now). Compiler is smart enough to understand that "
yisn't using it anymore".I know, but the image is not that important here. I'll use correct representations for the Rust part coming next
Cool! No worries. (Though I'm not sure why you'd want to keep an incorrect representation.)
Thank you for writing the article. I enjoyed it and it is a very relevant topic.
I saw C# recommended in the comments - as a .NET developer since .NET 2.0 was new, I agree. I've noticed that C# has gained popularity, but I also know how relevant this topic can be in developing larger applications or chasing performance.
I'll add C# since this is the second request now :)
That was an excellent, and comprehensive summary of memory management. I look forward to future installments, starting with the already-there part-2. By way of a contribution; because I am unable to correct anything technical about the JVM, I've spotted a grammatical problem. Namely:
"..load any run-time systems that is required"
, should be:
"..load any run-time systems that are required"
Thank you I'll update that. Glad you liked it
It good be interesting to know how Dart manage memory. I think a lot of people would be interested especially since flutter in getting a lot of momentum.
AFAIK, Dart uses a mark & sweep GC similar to JVM & Go. I'll see if I can add more details in an upcoming chapter
Good one 😄 Do you have any plans to add Memory management in
C#for future series ?I was thinking of adding that, I might once I'm done with the current ones planned
I guess you posted here by mistake? if not care to explain what you mean?
Well, no worries. I just didn't understand what you meant
Maybe the Pony language to some extent can be compared to Rust re. memory management. I suggest you take a look. You could e.g. start here: tutorial.ponylang.io/reference-cap...
Interesting. Thanks for the comment
thanks for this waiting for the v8 part :)
Thank you. I hope to get to it soon
Thank you very much for listing all the references. Certainly makes us feel confident on sharing it with colleagues and friends. Very well written indeed! Thanks for the effort.
You are welcome and thank you
Just wanted to mention that the link for part 2 at the end of the article is not correct.
Thank you so much. Just corrected it
yow thank you for this. much love to you sir!
Thank you
Please add Elixir/Erlang comparisons as well if possible!
Unfortunately, I have never used those languages and also I wanted to do a language per type of memory management and I think almost everything except ARC is covered in my plan