
Where is cutting-edge deep learning created and discussed?
One of the top places is ICLR – a leading deep learning conference, that took place on April 27-30, 2020. As a fully virtual event, with 5600+ participants and almost 700 papers/posters it could be called a great success. You can find comprehensive info about the conference here, here or here.
Virtual social meetings were one of the attractions of the ICLR 2020. We decided to run our own named “Open source tools and practices in state-of-the-art DL research“. We picked that topic because appropriate tooling is an inevitable part of deep learning research. Advancements in the field resulted in the proliferation of large frameworks’ ecosystems (TensorFlow, PyTorch, MXNet) as well as smaller targeted tools that serve specific needs.
The purpose of our social event was to meet open source tools’ creators and users and share the experience and impressions with the deep learning community. We gathered 100+ people in total, including tools’ maintainers to whom we gave short time slots to present their work. We were surprised and excited by the wide variety and creativity of tools and libraries presented.
In this post creators take the stage again, to tell us more about their projects.
Open Source MLOps: Platforms, Frameworks and Tools
Tools & libraries
Here, eight creators, who presented at the ICLR social event, share more bits and pieces about their tools. As a result, you – dear reader – have a first-hand knowledge about all the wonders now possible thanks to their work.
Each section tells you several things in the very concise way:
- What problem does the tool/library solve?
- How to run or create a minimalist example?
- Number of external resources to dive deeper into the library/tool.
- Creators profile, in case you want to reach out to them.
You can jump into specific section below or just skim through all of them one-by-one to get some inspiration:
(alphabetical order by the tool name)
Enjoy reading!
AmpliGraph
Knowledge graph embedding models
Language: Python

Description
Knowledge graphs are a universal language to represent complex systems.
Whether it is a social network, a bioinformatics dataset, or retail purchase data, modelling knowledge as a graph lets organizations capture patterns that would otherwise be overlooked.
Uncovering connections between this data, though, requires machine learning models specifically designed for graphs.
AmpliGraph is an Apache 2 licensed suite of neural machine learning models known as knowledge graph embeddings. Such models encode nodes and edges of a graph in low-dimensional vectors and combine them to predict missing facts. Knowledge graph embeddings have applications in knowledge graph completion, knowledge discovery, and link-based clustering, just to cite a few.
AmpliGraph lowers the entry barrier to knowledge graph embeddings, making such models accessible to inexperienced users, thus fostering a community of practitioners that can leverage the benefits of open source API for machine learning on knowledge graphs. We will learn how to generate and visualize embeddings from real-world knowledge graphs, and how to use them in downstream machine learning tasks.
To get you started, here’s a minimal code snippet to train a model over a benchmark graph dataset, and predict missing links:
from ampligraph.datasets import load_fb15k_237
from ampligraph.latent_features import TransE
# Load the Freebase benchmark dataset FB15K-237
X = load_fb15k_237()
# Initialise a model. Note embeddings will have 20 dimensions only
model = TransE(batches_count=100, epochs=20, k=20, verbose=True)
# Train a model for 20 epochs
model.fit(X['train'])
# Calibrate the output probabilities
model.calibrate(X['valid'], positive_base_rate=0.5)
# Let's see if the model can predict a missing triple.
# We will use the following held-out triple from the dataset test set:
# <St. Louis Rams(/m/06x76) /sports/sports_team/sport American football (/m/0jm_)>
X['test'][42]
# Predict the probability that St. Louis Rams are indeed an American
# football team. Turns out this has 84% of chances to be true!
model.predict_proba(X['test'][42])
# output is
# array([0.8404526], dtype=float32)


AmpliGraph was originally developed at Accenture Labs Dublin, where it is used in various industrial projects.
Resources and links
Automunge
Tabular data preprocessing platform
Language: Python

Description
Automunge is a Python library platform for preparing tabular data for machine learning. Through application, simple feature engineering transformations are applied to normalize, numerically encode, and insert infill. Transformations are “fit” to the properties of a train set and then consistently applied to test data on that basis. Transformations may be performed under automation, assigned from an internal library, or custom defined by user. Infill options include “ML infill”, in which automated machine learning models are trained for each column to predict infill.
In other words, put simply:
automunge(.)prepares tabular data for machine learning.postmunge(.)consistently prepares additional data very efficiently.
Automunge is available now for pip install:
pip install Automunge
Once installed, run in notebook to initialize:
from Automunge import Automunger
am = Automunger.AutoMunge()
Where for automated train set processing with default parameters run:
train, trainID, labels, validation1, validationID1, validationlabels1, validation2, validationID2, validationlabels2, test, testID, testlabels, labelsencoding_dict, finalcolumns_train, finalcolumns_test, featureimportance, postprocess_dict = am.automunge(df_train)
And for subsequent consistent processing of test data, using the postprocess_dict dictionary populated from the corresponding automunge(.) call, run:
test, testID, testlabels, labelsencoding_dict, postreports_dict = am.postmunge(postprocess_dict, df_test)
User specification of transformations or infill types can be performed in an automunge(.) call by way of the assigncat and assigninfill parameters. For example, for a train set with column headers ‘column1’ and ‘column2’, one could assign min-max scaling (‘mnmx’) with ML infill to column1 and one-hot encoding (‘text’) with mode-infill to column2. Any columns not explicitly specified will defer to automation.
train, trainID, labels,
validation1, validationID1, validationlabels1,
validation2, validationID2, validationlabels2,
test, testID, testlabels,
labelsencoding_dict, finalcolumns_train, finalcolumns_test,
featureimportance, postprocess_dict
= am.automunge(df_train,
assigncat = {'mnmx':['column1'], 'text':['column2']},
assigninfill = {'MLinfill':['column1'], 'modeinfill':['column2']})
Resources and links
Website | GitHub | Brief presentation
DynaML
Machine learning in Scala

Language: Scala

Description
DynaML is a Scala based toolbox for machine learning research and applications. It aims to provide the user with an end-to-end environment which can help in:
- Developing/prototyping models.
- Working with large, complex data pipelines.
- Visualising data and results.
- Reusing code in the form of scripts, notebooks.
DynaML leverages the strengths of the Scala language and ecosystem to provide an environment that can give performance and flexibility. It builds on excellent projects such as Ammonite scala shell, Tensorflow-Scala, and Breeze numerical computing library.
A key component of DynaML is the REPL/shell which has syntax highlighting and advanced autocomplete/command history.

Copy-paste snippets of code in the terminal session to run them on the fly.
The environment comes loaded with 2d and 3d visualisation support, results can be plotted directly from the shell session.

The data pipes module makes it convenient to create data processing pipelines in a composable and modular fashion. Create functions and wrap them using the DataPipe constructor and compose functional blocks using the > operator.

An experimental Jupyter notebook integration feature is also available, the notebooks directory in the repository contains some examples which use the DynaML-Scala Jupyter kernel.
The user guide contains extensive support and documentation for learning and getting the most out of the DynaML environment.
Some interesting applications that highlight the strengths of DynaML are:
- Physics inspired neural networks for solving the Burger’s equation and Fokker-Planck system.
- Training deep neural networks.
- Gaussian Process models for auto-regressive time series forecasting.
Resources and links
Hydra
Configuration and parameters manager
Language: Python

Description
Developed at Facebook AI, Hydra – a Python framework that simplifies the development of research applications – provides the ability to compose and override configurations via configuration files and the command line. It also provides parameter sweep support, remote and parallel execution via plugins, automatic working directory management and dynamic tab completion.
Using Hydra also makes your code more portable across different machine learning environments. Enabling you to move between personal workstations, public clusters, and private clusters without code changes. It achieves this via a pluggable architecture.
Basic example:
This example uses database config, but you can easily replace it with models, datasets or anything else you want.
config.yaml:
db:
driver: mysql
user: omry
pass: secret
my_app.py:
import hydra
from omegaconf import DictConfig
@hydra.main(config_path="config.yaml")
def my_app(cfg : DictConfig) -> None:
print(cfg.pretty())
if __name__ == "__main__":
my_app()
You can override anything in the config from the command line:
$ python my_app.py db.user=root db.pass=1234
db:
driver: mysql
user: root
pass: 1234
Composition example:
You may want to alternate between two different database configurations:
Create this directory structure:
├── db │ ├── mysql.yaml │ └── postgresql.yaml ├── config.yaml └── my_app.py
config.yaml:
defaults:
- db: mysql
# some other config options in your config file.
website:
domain: example.com
defaults is a special directive telling Hydra to use db/mysql.yaml when composing the configuration object.
You can now choose which database configuration to use from the and override values from the command line:
$ python my_app.py db=postgresql db.timeout=20
db:
driver: postgresql
pass: drowssap
timeout: 20
user: postgre_user
website:
domain: example.com
Check the tutorial to learn more.
In addition, some exciting new features are coming soon:
- Strongly typed configs (Structured Configs)
- Hyperparameter optimization via Ax and Nevergrad plugins
- AWS launching via a Ray launcher plugin
- Local parallel execution via a joblib plugin
And more.
Resources and links
Website | GitHub | Tutorial | Blog post | Twitter
Larq
Binarized neural networks
Language: Python

Description
Larq is an ecosystem of open-source Python packages for building, training and deploying Binarized Neural Networks (BNNs). BNNs are deep learning models in which the activations and weights are encoded not using 32, 16 or 8 bits, but using only 1 bit. This can drastically speed up inference time and lower energy usage, making BNNs a great fit for mobile and edge devices.
The open-source Larq ecosystem consist of three major components:
- Larq is a powerful yet easy-to-use library for building and training extremely quantized neural networks. It offers consistent and simple APIs that are extensible and fully compatible with the larger TensorFlow Keras ecosystem. This allows for gradual adoption in your current code base and enables fast iteration when developing models. While Larq is primarily focused on BNNs, it can also be used to train networks with arbitrary precision weights and activations
- Larq Zoo provides reference implementations of BNNs that are made available alongside pre-trained weights. Its aim is to encourage reproducible research, enabling researchers to build on top of the most recent BNN literature without spending endless amounts of time reproducing existing papers.
- Larq Compute Engine is an inference library for deploying BNNs. It is built on top of TensorFlow Lite and includes an MLIR-based converter to transform Larq models into FlatBuffer files compatible with the TF Lite runtime. It currently supports ARM64-based mobile platforms such as Android phones and the Raspberry Pi, and it achieves state of the art performance in on-device inference speed by using hand-optimized binary convolution kernels and network-level optimizations for BNN models.
We are continuously creating even better, faster models and expanding the Larq ecosystem to new hardware platforms and deep learning applications. For example, we are currently working on end-to-end integration of 8-bit quantization so you can train and deploy mixed binary and 8-bit networks using Larq.
Resources and links
Website | GitHub larq/larq | GitHub larq/zoo | GitHub larq/compute-engine | Tutorials | Blog | Twitter
McKernel
Approximate kernel expansions in log-linear time
Language: C/C++

Description
The first open-source C++ library to provide both kernel approximates via random features and also a fully-fledged DL framework.
McKernel provides four different possible uses:
- Stand-alone lighting fast open-source Hadamard. To use in: compression, encryption or quantum computing.
- Extremely fast kernel methods. To use in: wherever SVM is useful over DL. For example in some applications of robotics and ML for healthcare. Other exciting emerging uses include federated learning and channel estimation in communications.
- Integration of DL methods and kernel expansions. To foster new DL architectures with better human-induced/mathematical priors.
- DL research framework. To solve multiple-open questions in ML.
The equation that governs the whole computation is the following:
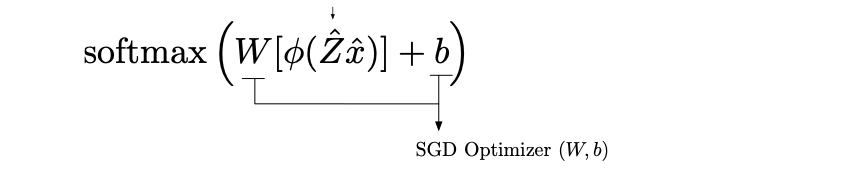
Here we pioneer a formalism to explain both DL and kernel methods (arxiv.org/pdf/1702.08159) by the use of random features. The theoretical background relies on four giants: Gauss, Wiener, Fourier and Kálmán. The building blocks were established by Rahimi and Recht (NIPS 2007) and Le et al. (ICML 2013).
Targeted user in mind
The main audience of McKernel are ML researchers and practitioners in the fields of robotics, ML for healthcare, signal processing and communications that are looking for an efficient and fast C++ implementation. In this sort of scenario, most DL libraries don’t address this specific need as they mainly rely on high level implementations in Python. As well as people in the broader ML and DL community that are trying to come up with better NN architectures by leveraging kernel methods.
A super-simple hands-on example to get the library running in no time is the following:

What’s next?
End-to-end training, self-supervised learning, meta-learning, integration with evolution strategies, NAS reducing substantially the search space,…
Resources and links
SCCH Training Engine

Automate DL development routines
Language: Python

Description
What is it?
A typical Deep Learning pipeline development is quite standard: data preprocessing, task design/implementation, training, and evaluation. Yet, its development from project to project requires a developer’s entry at every stage of the development process. This leads to the repetition of the same actions, code copy-paste and in the end, leads to bugs.
The goal of SCCH Training Engine is unification and automatization of the DL development routine for two most popular frameworks PyTorch and TensorFlow. The single entry allows to minimize development time and secures from development errors.
For whom?
Flexible architecture of SCCH Training Engine has 2 levels of user interaction:
Basic. At this level a user needs to provide his data and define training parameters in a configuration file. After this all processes including data processing, training and validation will be done automatically. As a result, a trained network in one of the defined frameworks will be provided.
Advanced. Due to the modular concept of the engine, a user can modify the engine on his needs by deploying his own models, loss and accuracy functions. Such modularity allows to add additional features without interfering with the core pipeline.
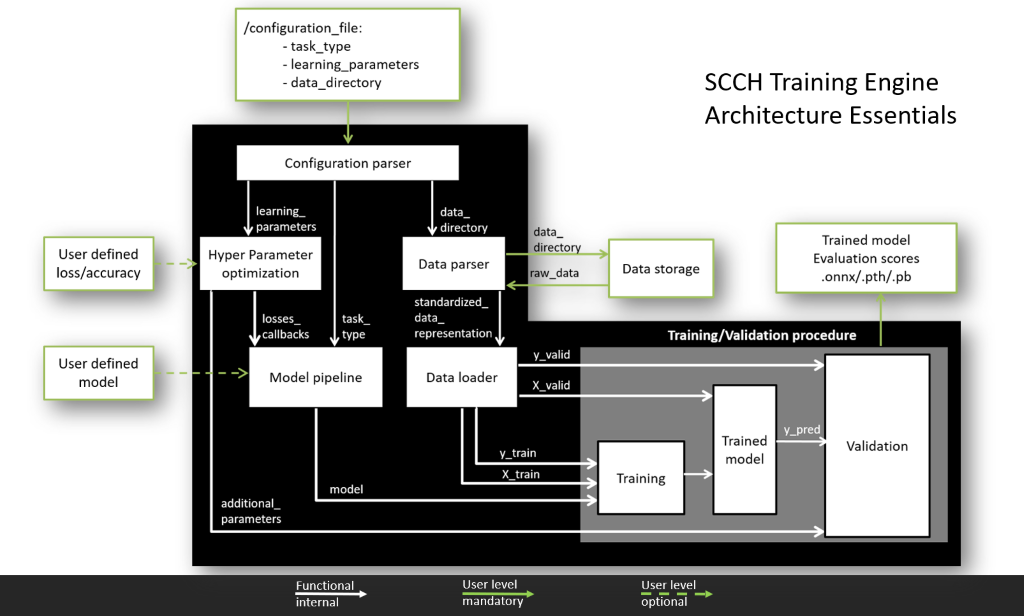
What can it do?
Current features are:
- works on TensorFlow and PyTorch
- standardized pipeline of data parsing from different formats
- standardized pipeline of training and validation
- supports classification, segmentation and detection tasks
- supports cross-validation
Features in development:
- hyperparameter search for training parameters
- weights loading and training from given checkpoint
- GAN architecture support
How does it work?
To see SCCH Training Engine in work you need to do 2 steps:
- Just copy repository and install requirements with
pip install requirements.txt - Run
python main.pyto see a toy example of MNIST processed and trained on LeNet-5
All information on how to create a configuration file and how to use advanced features can be found on our GitHub page.
Stable release with main features: end of May 2020
Resources and links
Tokenizers
Text tokenizers
Language: Rust with Python API

Description
huggingface/tokenizers provides access to state-of-the-art tokenizers, with a focus on performance and versatility. It makes training new tokenizers and using them a breeze. Whether you are an NLP researcher or an NLP practitioner, tokenizers can help you.
Key features:
- Extremely fast: The tokenization shouldn’t be the bottleneck in your NLP pipeline, nor should you have to pre-process your datasets. Thanks to a native implementation in Rust, tokenizing gigabytes of text only takes seconds.
- Offsets/Alignment: Provides alignment tracking even with complex normalization processing. This allows for easy text extraction, for tasks like NER or question answering.
- Pre-processing: Takes care of any preprocessing required before feeding your language model (truncation, padding, adding special tokens, …).
- Easy training: Train any tokenizer on a new corpus. For example, training a tokenizer for BERT on a new language has never been easier.
- Multi-languages: Bindings for multiple languages. Right now you can start using it with Python, Node.js, or Rust. More to come!
Example:

And soon:
- Single-file serialization and one-liner loading of any tokenizer.
- Support for Unigram.
At Hugging Face, our mission is to help advance and democratize NLP for everyone.
Resources and links
GitHub huggingface/transformers | GitHub huggingface/tokenizers | Twitter
Summary
First of all:
Thank you Anthony, J. de Curtó i Díaz, Luca, Lukas, Mandar, Natalia, Nicholas, and Omry for your effort that you put into this post!
Without you, it would never be created.
In this post, tools makers just highlighted the leading edge of what is now possible. Topics considered range from configuration management thought efficient text tokenizing to knowledge graph embeddings. We even touched binarized neural nets.
We strongly recommend to give them a try, as they can make your research easier and (potentially) faster – either in academic or industrial environments.
Finally, we are open to hearing out more about open source ecosystems in deep learning. If you have some questions, ideas or tools that you want to bring to the stage, please contact Kamil. You can find his contact details below.
This post was coordinated by the ICLR social event co-hosts:


PS:
We also built a series of posts focused on the main topics (source) discussed during ICLR 2020, that is:
- Deep learning (here)
- Reinforcement learning (here)
- Generative models (here)
- Natural Language Processing/Understanding (here)
Find some time to take a look at them!
