/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
Анализ данных является одним из наиболее важных этапов решения многих задач в области искусственного интеллекта. Он необходим для их понимания, а также последующей обработки и представления на вход модели. Однако, этот процесс часто требует больших временных затрат, а постепенно увеличивающиеся объёмы данных могут сделать многие традиционные методы анализа (часто ручные) и вовсе недоступными. В статье проведён обзор библиотеки pandas profiling, которая позволяет автоматизировать первичный анализ данных и, тем самым, значительно его упростить и ускорить.
0. Установка.
Библиотека устанавливается стандартными способами pip и conda:
pip install pandas-profiling
conda install -c conda-forge pandas-profilingМожно произвести установку и в оффлайн режиме. Для этого нужно скопировать репозиторий проекта, указать к нему путь и выполнить:
python setup.py installТребования к необходимым библиотекам указаны здесь.
1. Использование.
Пользоваться библиотекой очень просто — надо всего лишь указать объект DataFrame для которого нужно выполнить исследование. Это осуществляется методом:
df.profile_report(), где df - исследуемый DataFrame.Методу можно передать следующие параметры:
title - название отчёта
pool_size (int) - количество потоков для выполнения (по умолчанию = 0 - используются все потоки)
progress_bar (bool) - если True, то показывается прогресс бар
explorative (bool) - если True, то выполняется более глубокий анализ (для текстов и файлов)
minimal (bool) - если True, то ресурсоёмкие вычисления не выполняются. Рекомендуется при работе с большими датасетами.
Для работы с конфиденциальной информацией можно задать параметры duplicates=None и samples=None — тогда в отчёте не будут отображаться дубликаты и фрагменты данных.
Полный список параметров приведён здесь.
В результате для каждого столбца массива в зависимости от его типа выводится следующая статистика:
- Основная информация: тип, уникальные значения, количество нулевых и пропущенных значений
- Квантильная статистика: минимальное и максимальное значения, квартили, интерквартильный размах и др.
- Описательная статистика: среднее значение, мода, стандартное отклонение, коэффициенты асимметрии, самые частые значения и др.
- Графическая информация: гистограмма, корреляционные матрицы и др.
Кроме этого, pandas profiling может работать с текстами, файлами и картинками
Оценим работу этой библиотеки, выполнив анализ популярного датасета adult.data.
# импорт библиотек
import pandas as pd
import pandas_profiling
# загружаем датасет
df = pd.read_csv('adult.data.csv')
# создаём отчёт
profile = df.profile_report(title='Pandas Profiling Report', progress_bar=False)
# смотрим отчёт в HTML формате
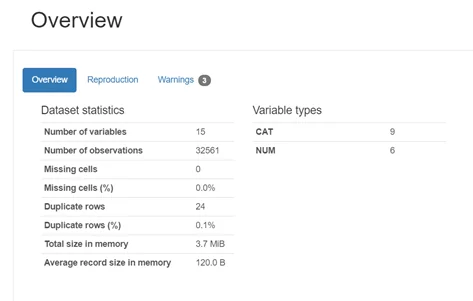
profileПервая часть отчёта (Overview) содержит основные сведения о датасете.
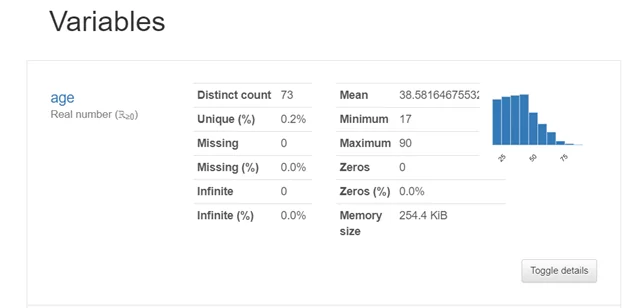
Вторая часть (Variables) показывает развёрнутую статистику по каждой переменной. Toggle details позволяет получить более расширенную статистику.
После этого приведена графическая информация о взаимодействии (Interactions) и корреляции признаков (Correlations), выводится статистика по пропущенным значениям (Missing values), дубликатам (Duplicate rows), а также показаны первые и последние 10 строк датасета (Sample).
Можно оформить отчёт в виде виджета следующим способом:
profile.to_widgets()2. Сохранение отчёта.
Для дальнейшего использования отчёт можно сохранить в HTML и JSON форматах:
profile.to_file("your_report.html")
json_data = profile.to_json(), или profile.to_file("your_report.json")Заключение.
Pandas profiling — мощный инструмент data science, позволяющий значительно ускорить предварительный анализ данных. Его использование особо эффективно при работе с большими датасетами, когда исследовать каждый признак вручную не представляется возможным.
В качестве бонуса приведены несколько примеров использования этой библиотеки:
- NASA Meteorites (comprehensive set of meteorite landings)
- Stata Auto (1978 Automobile data)
- NZA report (open data from the Dutch Healthcare Authority)
- Titanic