Безопасный обмен мгновенными сообщениями используется в двух вариантах: личное общение и групповое общение. В то время как первый вариант получил большое внимание в последнее время, мало что известно о криптографических механизмах и гарантиях безопасности безопасного группового общения в режиме реального времени.
Протокол групповой коммуникации
Безопасный протокол групповой связи должен обеспечивать уровень безопасности, сравнимый с тем, когда группа людей общается в приватной комнате: все в комнате слышат связь (отслеживаемая доставка), все знают, кто говорил (подлинность) и как часто эти слова были сказаны (отсутствие дублирования), никто за пределами комнаты не может ни говорить в комнату (отсутствие создания), ни слышать внутреннее общение (конфиденциальность), и комната может быть открыта только для приглашенных (закрытость).
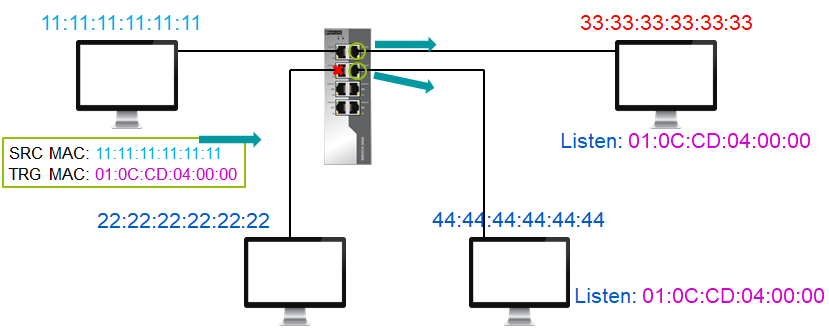
Общая схема групповых протоколов обмена мгновенными сообщениями, показывающая интерфейсы взаимодействующего пользователя (слева) и сетевые интерфейсы приложения (справа), выглядит следующим образом:

Состав группы
Группа в общей схеме состоит из множества членов группы и множества администраторов группы, где последнее множество является подмножеством первого. Каждая группа имеет свой уникальный ID и необходимую информацию, такую как имя.
Каждый участник группы хранит долгосрочные секреты для первоначального контакта с другими участниками и состояние сеанса для каждой группы, членом которой он является. Состояние сеанса содержит служебные переменные и секреты исключительно для использования в группе. Сообщения, доставленные в группе, не сохраняются в состоянии сеанса.
Протокол обмена сообщениями
Для обеспечения точной модели безопасности, мы определяем протокол обмена мгновенными сообщениями в группе как набор алгоритмов:
- $inline$sndс$inline$: Отправляет шифротекст, назначенный центральному серверу.
- $inline$rcv( c )$inline$: Получает зашифрованный текст от центрального сервера и обрабатывает его, вызывая один из алгоритмов доставки и, возможно, алгоритм $inline$snd$inline$.
- $inline$SndM( gr,m )id$inline$: отправка сообщения $inline$m$inline$ в группу $inline$gr$inline$.
- $inline$Add( gr,V )id$inline$: добавление пользователя $inline$V$inline$ в группу $inline$gr$inline$.
- $inline$Leave( gr )id$inline$: выход пользователя $inline$U$inline$ из группы $inline$gr$inline$.
- $inline$Rmv( gr,V )id$inline$: удаление пользователя $inline$V$inline$ из группы $inline$gr$inline$.
- $inline$DelivM( id,gr,V,m )$inline$: Сохраняет $inline$m$inline$ с идентификатором $inline$id$inline$ от отправителя $inline$V$inline$ в группе $inline$gr$inline$ для отображения его пользователю $inline$U$inline$.
- $inline$ModG( id,gr )$inline$: Обновляет группу после удаленного обновления с идентификатором $inline$id$inline$.
- $inline$Ackid$inline$: Подтверждает, что действие с идентификатором $inline$id$inline$ было доставлено и обработано всеми получателями.
Первые два алгоритма обеспечивают доступ приложения к сети (сетевой интерфейс). Тем самым $inline$snd$inline$ отправляет шифротексты, а $inline$rcv$inline$ принимает и обрабатывает шифротексты. Последние семь алгоритмов обрабатывают действия пользователя или доставляют удаленные действия других пользователей в графический интерфейс пользователя.
Каждый алгоритм, который обрабатывает действия вызывающего пользователя, отправляет уникальный идентификатор. Действия, инициированные другими пользователями, сначала принимаются в виде шифротекстов алгоритмом $inline$rcv$inline$, а затем передаются в следующие алгоритмы, которые доставляют результат целевому пользователю.
Одна из практических реализаций алгоритма $inline$Ack$inline$ для подтверждения доставки сообщения отправителю изображена ниже: первая галочка установлена, когда сообщение доставлено на центральный сервер, а вторая галочка установлена, только если сообщение было доставлено всем участникам группы.

Модель угроз
Здесь мы определяем противников, стремящихся сломать одну из впоследствии определенных целей безопасности в одной определенной группе, называемой целевой группой.
Злонамеренный пользователь. Поскольку все протоколы открыты для новых пользователей, злоумышленник может действовать как злонамеренный пользователь, который может произвольно отклоняться от протокола. Чтобы исключить тривиальные атаки на мгновенную доставку сообщений, мы предполагаем, что члены целевой группы ведут себя правильно, всегда следуя протоколу.
Сетевой атакующий. Этот злоумышленник имеет полный контроль над каналом связи, может получать доступ и изменять весь незащищенный трафик.
Вредоносный cервер. Помимо прямого олицетворения центрального сервера, этот злоумышленник моделирует атаки на безопасность транспортного уровня между пользователями и центральным сервером.
Для анализа устойчивости протоколов против компрометации пользовательских секретов, для определения совершенной прямой секретности и будущей секретности, к ранее описанным противникам добавляются следующие две возможности.
Компрометация долгосрочных секретов. Это позволяет злоумышленнику скомпрометировать конкретного пользователя во время или после выполнения протокола, чтобы получить его долгосрочные секреты. Как описано для злонамеренного пользователя, олицетворения рассматриваются как тривиальные атаки, и поэтому сеансы, запускаемые после компрометации, не считаются безопасными.
Компрометация сеанса. Это позволяет злоумышленнику скомпрометировать пользователя для получения полного состояния сеанса на некоторой промежуточной стадии выполнения протокола. В отличие от компрометации долгосрочного пользования, эта дополнительная возможность не ограничена в отношении олицетворения членов целевой группы в явном виде, поскольку соответствующие определения совершенной прямой секретности и прямой секретности учитывают это соответственно.
Цели безопасности
Безопасность и надежность в динамическом групповом общении можно разделить на три аспекта: 1) конфиденциальность содержания разговоров, 2) целостность разговора и 3) конфиденциальность управления группой.
Конфиденциальность. Мы используем понятие односторонней безопасности для конфиденциальности передаваемого контента. Как таковое, определение чистой конфиденциальности применимо только к некомпрометирующим злоумышленникам. Затем мы используем это определение для совершенной прямой секретности и будущей секретности для учета компрометирующих злоумышленников.
- Сквозная конфиденциальность. Ни одно сообщение $inline$m$inline$ отправленное участником в целевую группу $inline$gr$inline$ посредством $inline$SndM( gr,m )$inline$ не может быть получено злоумышленником.
- Совершенная прямая секретность. При утечке состояния сеанса пользователя U сохраняется конфиденциальность прошлых сообщений $inline$U$inline$ в группе $inline$gr$inline$.
Соответственно, мы определяем одну групповую передачу как последовательность действий, после которой все члены группы выводят шифротексты через $inline$snd$inline$, а все члены группы получают назначенные им шифротексты через $inline$rcv$inline$.
Целостность. Определение целостности в качестве цели для последовательной связи направлено не только на сквозную целостность отдельных сообщений, но и на весь передаваемый контент.
- Аутентификация сообщений. Если сообщение $inline$m$inline$ доставлено посредством $inline$DelivM( id,gr,U,m )$inline$, тогда верно то, что это сообщение было отправлено пользователем $inline$U$inline$ посредством вызова $inline$SndM( gr,m )$inline$.
- Отсутствие создания. Если сообщение $inline$m$inline$ было доставлено пользователем в группу посредством $inline$DelivM( id,gr,V,m )$inline$ с отправителем $inline$V$inline$, тогда $inline$V$inline$ должен быть в комнате.
Каждый участник группы может отправлять сообщения, поэтому для получателя важно знать отправителя.
- Отсутствие дублирования. Для каждого действия $inline$Actn( gr )id$inline$ инициированного пользователем $inline$U$inline$ для группы результат $inline$Deliv( id,gr )$inline$ должен вызываться только один раз для каждого члена группы.
- Отслеживаемая доставка. Если доставка действия $inline$Actn( gr )id$inline$ пользователя $inline$U$inline$ подтвердилась одним пользователем посредством вызова $inline$Ackid$inline$, тогда соответствующий алгоритм $inline$Deliv( id,gr )$inline$ должен вызваться всеми участниками.
Отслеживаемая доставка означает, что если участник уведомлен о завершении действия, выполненного в группе, то соответствующее подтверждение о доставке было дано всеми его участниками.
Конфиденциальность управления группой. Групповые протоколы должны соответствовать дополнительным требованиям для обеспечения конфиденциальности в качестве цели безопасности. Хотя аутентификация для сообщений содержимого определяется с помощью аутентификации сообщений, следующие определения также подразумевают аутентичность для действий управления группой:
- Аддитивная закрытость. Если один из участников группы модифицирует набор участников тогда администратор вызывает $inline$Add( gr,V )$inline$, добавляя нового участника в группу.
- Субтрактивная закрытость. Если пользователь один из участников группы модифицирует набор участников тогда администратор вызывает $inline$Rmv( gr,V )$inline$, удаляя участника из группы, или участник $inline$V$inline$ вызывает $inline$Leave( gr )$inline$ для выхода из группы.
Безопасный и надежный групповой обмен мгновенными сообщениями.
Определение: Протокол является безопасным и надежным групповым протоколом обмена мгновенными сообщениями, если он обеспечивает сквозную конфиденциальность, аутентификацию сообщений, отсутствие дублирования, отслеживаемую доставку, аддитивную и субтрактивную закрытость в присутствии злонамеренного пользователя, сетевого атакующего и злонамеренного сервера.
Кроме того, протокол может достигать совершенной прямой секретности и будущей секретности для защиты от компрометирующих злоумышленников.
Алгоритмы групповой криптографии
Методы формирования составных ключей на сегодня представляют собой разнообразные расширения фундаментального алгоритма, предложенного Диффи и Хеллманом в 1976. Оригинальный протокол предлагает метод установления общего ключа двумя взаимодействующими сторонами, групповые же его расширения предлагают обобщение данной схемы до случая N взаимодействующих сторон. Как и для оригинального протокола, сложность раскрытия устанавливаемого группового ключа основывается на сложности нахождения дискретного логарифма, поэтому если двусторонний протокол считается защищенным, то же самое можно утверждать для всех его расширений.
Протокол GDH.3 был представлен вместе с протоколами GDH.1 и GDH.2. Это особенно подходит для сред, которые требуют минимальных вычислительных мощностей от каждого члена группы. Протокол развивается в четыре этапа, и здесь я расскажу об оригинальном алгоритме GDH.3 и об аналоге, представленном в материале Design, Analysis and Perfomance Evaluation of Group Key Establishment in Wireless Sensor Networks. Протокол Диффи-Хеллмана для групп с эллиптической кривой позволяет использовать ключи намного меньшего размера, чем обычные криптосистемы на основе дискретного логарифма (160-битный ключ в криптосистеме с эллиптической кривой обеспечивает эквивалентную защиту с 1024-битным ключом в обычной криптосистеме).
GDH.3 на эллиптической кривой
Предположим, что каждый член группы согласился на использование тех же параметров эллиптической кривой. Количество участников $inline$n$inline$ и мы будем обозначать $inline$M_i$inline$ каждого $inline$i$inline$-го участника.
- На первом этапе каждый член группы $inline$M_i$inline$ генерирует случайное секретное значение $inline$k_i$inline$. Участник $inline$M_1$inline$ выбирает точку $inline$P$inline$ и отправляет $inline$M_2$inline$ точку $inline$Q_1 = k_1P$inline$. Затем $inline$M_2$inline$ отправляет $inline$M_3$inline$ точку $inline$Q_2 = k_1k_2P$inline$ и так далее, пока протокол не достигает члена $inline$M_{n1}$inline$. Обратите внимание, что протокол должен пройти каждого участника только один раз.
- Член группы $inline$M_{n1}$inline$ вычисляет точку $inline$Q_{n1} = k_1k_2 ... k_{n 1}P$inline$ и отправляет ее всем членам.
- На третьем этапе каждый член группы $inline$M_i, i [1, n-1]$inline$ вычисляет точку $inline$G_i = k^{i1} Q_{n 1}$inline$ и отправляет его последнему члену группы $inline$M_n$inline$.
- $inline$M_n$inline$ вычисляет значения $inline$k_nG_i$inline$ и отправляет их соответствующим членам $inline$M_i$inline$
После этих этапов каждый член группы $inline$M_i$inline$ может вычислить ключ группы $inline$Q_n = k_1k_2 ... k_nP$inline$ путем умножения значения $inline$k_nG_i$inline$ на его секретное число $inline$k_i$inline$. Несмотря на его эффективность, недостатком протокола GDH.3 является то, что он не обеспечивает симметричность операции, потому что все участники протокола не выполняют одно и то же количество операций. Если количество участников велико, то усилия $inline$M_n$inline$ могут быть разрушительными для него.
Аналог GDH.3 на эллиптической кривой
Мы придерживаемся распределенного подхода, который не требует обмена сообщениями многие-ко-многим, как в случае второго и третьего этапов протокола GDH.3, и не полагается на какой-либо глобальный порядок устройств. Наш протокол основан на наблюдении, что на первом этапе протокола GDH.3 член группы $inline$M_n$inline$ может вычислить общий ключ группы $inline$Qn$inline$ путем получения точки $inline$Q_{n1}$inline$ из $inline$M_{n1}$inline$ и умножения его на его секретное значение $inline$k_n$inline$. Кроме того, точки $inline$Q_i = k_1k_2 ... k_iP$inline$, которые генерируются каждым членом группы $inline$M_i$inline$ могут быть использованы в качестве своих открытых ключей, в то время как их закрытые ключи являются значениями $inline$k_i$inline$. Используя это наблюдение, наш протокол полностью избегает третий и четвертый этапы протокола GDH.3.
- На первом этапе каждый член группы $inline$M_i$inline$ генерирует случайное секретное значение $inline$k_i$inline$. Участник $inline$M_1$inline$ выбирает точку $inline$P$inline$ и отправляет $inline$M_2$inline$ точку $inline$Q_1 = k_1P$inline$ который является его открытым ключом и может использоваться $inline$M_2$inline$. Затем $inline$M_2$inline$ отправляет $inline$M_3$inline$ точку $inline$Q_2 = k_1k_2P$inline$ (которая является открытым ключом $inline$M_2$inline$) и так далее пока протокол не достигает члена $inline$M_n$inline$. Точка $inline$Q_n$inline$ является общим секретным ключом и рассчитывается участником $inline$M_n$inline$.
- Теперь $inline$M_n$inline$ шифрует $inline$Q_n$inline$ с помощью открытого ключа $inline$M_{n-1}$inline$$inline$Q_{n-1}$inline$ и отправляет его в $inline$M_{n-1}$inline$. $inline$M_{n-1}$inline$ может расшифровать сообщение с помощью своего закрытого ключа $inline$k_{n-1}$inline$. Получив секретное значение $inline$Q_n$inline$, шифрует его открытым ключом $inline$M_{n-2}$inline$ и отправляет результат $inline$M_{n-2}$inline$. Такая же операция будет выполнена $inline$M_{n-2}$inline$ и так далее, пока протокол не достигнет члена $inline$M_1$inline$.
В частности, мы используем распределенный алгоритм последовательного обхода, который посещает каждого участника группы для создания общего секретного ключа (начиная с $inline$M_1$inline$ и достигая $inline$M_n$inline$). Это похоже на первую стадию GDH.3, не обязательно требует прямого общения между всеми членами группы и по-прежнему гарантирует что каждый участник посещается только один раз. Когда обход закончен и все участники посещаются, протокол достигает члена $inline$M_n$inline$, который вычисляет точку $inline$Q_n$inline$, что является общим секретным ключом. Наконец, для того, чтобы $inline$M_n$inline$ сообщил общий секретный ключ всем участникам группы, повторяет этот обход, но в обратном порядке. $inline$M_n$inline$ теперь шифрует $inline$Q_n$inline$ открытым ключом $inline$M_{n-1}$inline$$inline$Q_{n-1}$inline$ и отправляет его участнику $inline$M_{n 1}$inline$. $inline$M_{n-1}$inline$ может расшифровать сообщение с помощью своего закрытого ключа $inline$k_{n-1}$inline$, получить секретное значение $inline$Q_n$inline$, зашифровать его открытым ключом $inline$M_{n-2}$inline$ и отправить $inline$M_{n2}$inline$. Это же проделает $inline$M_{n-2}$inline$ и так далее, пока протокол не достигнет члена $inline$M_1$inline$.
Заключение
Да, я знаком с правилом больше двух говори вслух, но все же проблема безопасности переписок стоит очень остро, особенно в наше время. И эта статья то, чем я хотел поделиться по этой теме, т.к в русскоязычном сегменте крайне мало материала, особенно по вопросам криптографии. Буду рад критике.
Источники
- Paul Rsler, Christian Mainka, Jrg Schwenk / More is Less: On the End-to-End Security of Group Chats in Signal, WhatsApp, and Threema
- Ioannis Chatzigiannakis, Elisavet Konstantinou, Vasiliki Liagkou, Paul Spirakis / Design, Analysis and Performance Evaluation of Group Key Establishment in Wireless Sensor Networks