Аннотация
Прогнозкликабельности(CTR), цель которого-предсказать
вероятность того, что пользователь нажмет на объявление или товар,
имеет решающее значение для многих онлайн-приложений, таких как
онлайн-реклама иконсультирующие(рекомендательные)системы. Эта
проблема очень сложна, поскольку:1) входные функции (например,
идентификатор пользователя, возраст пользователя, идентификатор
элемента, категория элемента) обычно разрежены;2) эффективное
предсказание опирается на комбинаторные функции высокого порядка
(они же кросс-функции), которые очень трудоемки для
ручнойобработкиэкспертамипредметной области и не перечислимы.
Поэтому были предприняты усилия по поиску низкоразмерных
представлений разреженных ивысокоразмерныхнеобработанных объектов и
их значимых комбинаций.
В этой статье мы предлагаем эффективный и действенный
методAutoIntдля автоматическогоанализавзаимодействий объектов
высокого порядка входных объектов. Предлагаемый нами алгоритм
является очень общим и может быть применен как к числовым, так и к
категориальным входным признакам. В частности, мы сопоставляем как
числовые, так и категориальные признаки в одном и том же
низкоразмерном пространстве. Затем предлагается
многоцелеваясамонастраиваемаянейронная сеть с остаточными связями
для явного моделирования взаимодействий признаков в низкоразмерном
пространстве. С помощью различных слоев многоцелевыхсамонапряженных
нейронных сетей можно моделировать различные порядки комбинаций
признаков входных признаков. Вся модель может быть
эффективноприменена ккрупномасштабнымнеобработаннымданнымсквозным
способом. Экспериментальные результаты на четырех реальных наборах
данных показывают, что предложенный нами подход не только
превосходит существующие современные подходы к прогнозированию, но
и обеспечивает хорошую объясняющую способность сети. Код доступен
по адресу:https://github.com/DeepGraphLearning/RecommenderSystems.
-
Введение
Прогнозирование вероятностей кликов пользователей по объявлениям
или товарам (также известное как прогнозированиекликабельности)
является критической проблемой для многихвеб-приложений, таких
какинтернет-реклама и рекомендательные системы [8, 10, 15].
Эффективность прогноза оказывает непосредственное влияние на
конечную выручку бизнес-провайдеров. Благодаря своей важности она
вызывает растущий интерес,как в академических кругах, так и
вкоммерческихкругах.
Машинное обучение играет ключевую роль в прогнозировании
скорости кликов, которое обычно формулируется как контролируемое
обучение с профилями пользователей и атрибутами элементов в
качестве входных функций. Эта проблема очень сложна по нескольким
причинам. Во-первых, входные объекты чрезвычайно разрежены и
многомерны [8, 11, 13, 21, 32]. В реальных приложениях,значительная
часть демографических характеристик пользователя и атрибутов
элемента обычно дискретнаяи/или категориальная. Чтобы
сделатьприменимымиметоды контролируемого обучения, эти функции
сначала преобразуются в вектор однократного кодирования, который
может легко привести к объектам с миллионами измерений. Если взять
в качестве примера хорошо известные данные прогнозирования
CTRCriteo, то размерность объекта составляет примерно 30 миллионов
с разреженностью более 99,99%. С такими разреженными и многомерными
входными функциями модели машинного обучения легко перестраиваемы
(настраиваемы). Во-вторых, как показано в обширной литературе [8,
11, 19, 32], взаимодействие функций высокого порядка имеет решающее
значение для хорошей производительности. Например, целесообразно
рекомендовать Марио,изизвестнойвидео-игры, Давиду, десятилетнему
мальчику. В этом случае комбинаторный признак третьего порядка
<Gender=Male,Age=10,productCategory=VideoGame> очень
информативен для прогнозирования. Однако поиск таких значимых
комбинаторных функций высокого порядка в значительной степени
зависит от экспертов предметной области. Более того, практически
невозможно вручную создать все значимые комбинации [8, 26].
Можнозадаться вопросом:можем ли мы перечислить все возможные
функции высокого порядка и позволить моделям машинного обучения
выбрать значимые?Однако перечисление всех возможных объектов
высокого порядка приведет к экспоненциальному увеличению
размерности и разреженности входных объектов, что приведет к более
серьезной проблеме переоснащения модели. Поэтому в
сообществахпредпринимались обширные усилияпо поиску низкоразмерных
представлений разреженных и высокомерных входных объектов
и,одновременно,моделированию различных порядков комбинаций
объектов.
Например,факторизационныемашины (ФМ) [26], сочетающие
полиномиальные регрессионные модели с методами факторизации,
разработаны для моделирования взаимодействий признаков и доказали
свою эффективность для различных задач [27, 28]. Однако,
ограниченный полиномиальным временем подгонки, он эффективен только
для моделирования взаимодействий объектов низкого порядка и
непрактичен дляучетавзаимодействий объектов высокого порядка. В
последнее время,во многих работах [8, 11, 13, 38],на основе
глубоких нейронных сетей было предложено моделировать
взаимодействия признаков высокого порядка. В частности, несколько
слоев нелинейных нейронных сетей обычно используются для захвата
взаимодействий объектов высокого порядка. Однако такие методы имеют
два ограничения. Первый,какбыло показано,-полностью связанные
нейронные сети неэффективны при обучении мультипликативным
взаимодействиям признаков [4]. Во-вторых, поскольку эти модели
изучают взаимодействие признаков неявным образом, им не хватает
хорошего объяснения того, какие комбинации признаков имеют смысл.
Поэтому мы ищем подход, способныйявно моделировать различные
порядки комбинаций признаков, представлять все объекты в
низкоразмерных пространствах и в то же время предлагать хорошую
объяснимость модели.
В данной работе мы предлагаем такой подход, основанный на
многослойноммеханизме само-внимания [36]. Предложенный нами подход
изучает эффективные низкоразмерные представления разреженных
ивысокоразмерныхвходных признаков,и применим как к категориальным,
так и к числовым входным признакам. В частности, как
категориальные, так и числовые признаки сначала внедряются в
низкоразмерные пространства, что уменьшает размерность входных
признаков и в то же время позволяет различным типам признаков
взаимодействовать друг с другом с помощью векторной арифметики
(например, суммирования и внутреннего произведения). Затем мы
предлагаем новый взаимодействующий слой, способствующий
взаимодействию различных объектов. Внутри каждого
взаимодействующего слоя,каждому объекту разрешено взаимодействовать
со всеми другими объектами и он способен автоматически
идентифицировать соответствующие объекты для формирования значимых
объектов более высокого порядка с помощью механизма
многоцелевоговнимания [36]. Более того, механизм с
несколькимицелями (слоями)проецирует объект на несколько
подпространств, и, следовательно, он может фиксировать
различныевзаимодействия объектов в разных подпространствах. Такой
слой взаимодействий моделирует одношаговое взаимодействие между
объектами. Накладываянесколько взаимодействующих слоев, мы можем
моделировать различные порядки взаимодействия объектов. На практике
к взаимодействующему слою добавляется остаточная связь [12], что
позволяет комбинировать различные порядки комбинаций признаков. Мы
используем механизм внимания для измерения корреляций между
признаками, что обеспечивает хорошую объяснимость модели.
Подводя итог, в этой статье мы делаем следующие выводы:
-
предлагаем изучить проблему явного обучения взаимодействий
признаков высокого порядка и одновременно найти модели с хорошей
объяснимостью для этой задачи;
-
предлагаем новый подход, основанный на самообучающейсянейронной
сети, которая может автоматически изучать взаимодействия объектов
высокого порядка и эффективно обрабатывать крупномасштабные
высокомерные разреженные данные;
-
провели обширные эксперименты на нескольких наборах реальных
данных, экспериментальные результаты по задаче прогнозирования CTR
показывают, что предложенный нами подход не только превосходит
существующие современные подходы к прогнозированию, но и
обеспечивает хорошую объяснимость модели.
Наша работа организована следующим образом. В разделе 2. мы
анализируем соответствующие работы.В разделе3приводитсяформальная
постановка нашейпроблемы. В разделе 4. предложен подход к изучению
взаимодействия признаков. В разделе 5 представлены результаты
экспериментов и их детальный анализ. Мы завершаемстатью,указываяна
будущие исследования в разделе 6.
2.Сопутствующие работы
Наше исследование относится к трем направлениям работы:
1)прогнозированиекликабельностив рекомендательных системах и
онлайн-рекламе;2) методы обучения взаимодействиям признаков; 3)
механизм самоконтроля и остаточные сети в литературе по глубокому
обучению.
2.1Прогнозирование рейтингакликабельности
Прогнозированиекликабельностиважно для многих интернет-компаний,
и различные системы были разработаны разными компаниями [8-10, 15,
21, 29, 43]. Например,Googleразработала систему
обученияWide&Deep[8] для рекомендательных систем, которая
сочетает в себе преимущества линейных неглубоких моделей,а
такжеглубоких моделей. Система достигает замечательной
производительности в рекомендательных системах. Эта проблема также
получает большое внимание в академических кругах.
Например,Шанисоавт. [31] предложили контекстно-зависимыйметод
прогнозированиякликабельности, которые раскладывает тензор на
множители по трем направлениям <пользователь, объявление,
контекст>.Oentaryoисоавт. [24] разработана машина факторизации с
иерархическойподчиненностьюдля моделирования динамического
воздействия рекламы.
2.2Взаимодействие Функций Обучения
Изучение взаимодействия признаков является фундаментальной
проблемой,поэтому широко изучается в литературе. Хорошо известным
примером являютсяфакторизационныемашины (ФМ) [26], которые были
предложены в основном для захвата взаимодействий признаков первого
и второго порядка и доказали свою эффективность для многих задач в
рекомендательных системах [27, 28]. Впоследствии были предложены
различные вариантыфакторизационныхмашин. Например,
полевыефакторизационныемашины (FFM) [16] моделировали
мелкозернистые взаимодействия между объектами разных полей. GBFM
[7] и AFM [40] рассматривали важность различных взаимодействий
признаков второго порядка. Однако все эти подходы сосредоточены на
моделировании взаимодействийобъектов низкого порядка.
Есть некоторые недавние работы, которые моделируют
взаимодействия объектов высокого порядка. Например, NFM [13]
укладывал глубокие нейронные сети поверх выходных данных
взаимодействий объектов второго порядка для моделирования объектов
более высокого порядка. Аналогично, PNN [25], FNN
[41],DeepCrossing[32],Wide&Deep[8] иDeepFM[11] использовали
нейронные сети обратной связи для моделирования взаимодействий
признаков высокого порядка. Однако все эти подходы изучают
взаимодействия признаков высокого порядка неявным образом,поэтому
не имеют хорошей объясняющей способностимодели. Напротив, есть три
направления работ, которые изучают взаимодействие признаков в явном
виде. Во-первых, Deep&Cross[38] иxDeepFM[19] использовали
внешнее произведение признаковна битовом и векторном уровнях
соответственно. Хотя они выполняют явные взаимодействия признаков,
объяснить, какие комбинации полезны нетривиально. Во-вторых,
некоторые древовидные методы [39, 42, 44] сочетали в себе мощь
моделей, основанных на внедрении и древовидных моделей, но должны
были разбить процедуру обучения на несколько этапов. В-третьих,
HOFM [5] предложил эффективные обучающие алгоритмы для машин
факторизации высокого порядка. Однако HOFM требует слишком большого
количества параметров, и практически можно использовать только
егонизкопорядковую(обычно менее 5) форму. В отличие от существующей
работы, мы явно моделируем взаимодействие признаков с механизмом
внимания сквозным образом ивизуализируемизученные комбинации
признаков.
2.3Внимание и остаточные сети
Предложенная нами модель использует новейшие методы в литературе
по глубокому обучению: внимание [2] и остаточные сети [12].
Внимание впервые предложено в контексте нейронного машинного
перевода [2] и доказало свою эффективность в различных задачах,
таких как ответы на вопросы [35], обобщение текста [30] и
рекомендательные системы [14, 33, 43].Васвании др. [36] далее
предложили многоцелевоесамо-внимание для моделирования сложных
зависимостей между словами в машинном переводе.
Остаточные сети [12] достигли высочайшего уровня
производительности в конкурсеImageNet. Поскольку остаточная связь,
которую можно просто формализовать как y = F (x) +
x, способствует градиентному потоку через интервальные
слои, она становится популярной сетевой структурой для обучения
очень глубоких нейронных сетей.
3.Определение проблемы
Сначала мы формально определим задачу прогнозирования рейтинга
кликов (CTR) следующим образом:
Определение 1. (Прогноз CTR) Пусть x R
n обозначает конкатенацию функций пользователя
u и характеристик элемента v, где
категориальные особенности представлены с помощью однократного
кодирования, а n - размерность
объединяемыхфункций. Задача прогнозирования рейтинга кликов
направлена на прогнозирование вероятности того, что пользователь
u нажмет на элемент v в
соответствии с вектором признаков x.
Простое решение для прогнозирования CTR состоит в том, чтобы
рассматривать x как входные характеристики и
развертывать готовыеклассификаторы, такие как логистическая
регрессия. Однако, поскольку исходный вектор признаков
x очень разрежен и многомерен, модель будет
легкоадаптирована. Поэтому желательно представлять исходные входные
объекты в низкоразмерных непрерывных пространствах. Кроме того, как
показано в существующей литературе, крайне важно использовать
комбинаторные функции более высокого порядка для получения хорошей
производительности прогнозирования [6, 8, 11, 23, 26, 32].

Рисунок 1: Обзор предлагаемой нами модели
AutoInt. Подробности встраиваемого слоя и взаимодействующего слоя
показаны на рисунках 2 и 3 соответственно.
В частности, мы определяем комбинаторные особенности высокого
порядканижеследующим образом.
Определение 2(комбинаторная функция p-порядка).При
заданном входном векторе признаков xR n
комбинаторный признак p-го порядка определяется
как g (xi1 , ...,xip), где
каждый признакзадан надотдельнымполем, p-число
задействованных полей признаков, а g () -
неаддитивная комбинированная функция, такая как умножение [26] и
внешнее произведение [19, 38]. Например, xi1
xi2-это комбинаторная функция второго порядка,
включающая xi1 и
xi2.
Традиционно значимые комбинаторные функции высокого порядка
подбираются эвристически экспертами предметной области. Однако это
очень трудоемко и трудно распространить на другие области. Кроме
того, практически невозможно вручнуюподобратьвсе значимые
высокоуровневые функции. Поэтому мы стремимся разработать подход,
который способен автоматически обнаруживать значимые комбинаторные
особенности высокого порядка и одновременно отображать все эти
особенности в низкоразмерные непрерывные пространства. Формально мы
определяем нашу проблему следующим образомс помощью нижеследующего
определения.
Определение 3(определение проблемы).Учитывая входной
вектор признаков xRn для
прогнозирования рейтинга кликов, наша цель - изучить низкоразмерное
представление x, которое моделирует комбинаторные
признаки высокого порядка.
4.Autoint: функция
автоматическогообеспечениявзаимодействий
В этом разделе мы сначала даем обзор предлагаемого
подходаAutoInt, который может автоматически изучать взаимодействие
функций для прогнозирования CTR. Далее мы представляем
исчерпывающее описание того, как изучить низкоразмерное
представление, которое моделируеткомбинаторные признаки высокого
порядка без ручного проектирования признаков.
4.1Обзор
Цель нашего подхода состоит в том, чтобы отобразить исходный
разреженный и высокоразмерный вектор признаков в низкоразмерные
пространства и одновременно смоделировать взаимодействия объектов
высокого порядка. Как показано на Рис.1, предлагаемый нами метод
принимает в качестве входных данных разреженный вектор признаков x,
за которым следует слой вложения, проецирующий все признаки (т. е.
как категориальные, так и числовые) в одно и то же низкоразмерное
пространство. Затем мы вводим вложения всех полей в новый
взаимодействующий слой, который реализуется как многоцелевая
(многослойная) самонапряженная нейронная сеть. Для каждого
взаимодействующего слоя объекты высокого порядка объединяются с
помощью механизма внимания, различные виды комбинаций могут быть
оценены с помощью многослойныхмеханизмов, которые отображают
объекты в различные подпространства. Путем наложения нескольких
взаимодействующих слоев можно моделировать различные порядки
комбинаторных объектов.
Результатом последнего взаимодействующего слоя является
низкоразмерное представление входного объекта, которое моделирует
комбинаторные признаки высокого порядкаидалее используется для
оценки рейтинга кликов с помощью сигмоидальной функции. Далее мы
познакомим вас с деталями предлагаемого нами метода.

Рисунок 2: Иллюстрация входного и
встраиваемого слоев, где как категориальные, так и числовые поля
представлены низкоразмерными плотными векторами.
4.2Входной слой
Сначала мы представляем профили пользователя и атрибуты элемента
в виде разреженного вектора, который является конкатенацией всех
полей. Конкретно,
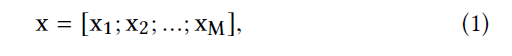
где M - общее количество полей признаков,
аxi- представление признаков
i-го поля.xi-это
одномерный вектор, если i-е поле категориально
(например, x1 на Рис.
2).xi-скалярное значение, если
i-е поле числовое
(например,xMна Рис. 2).
4.3Встраиваемый слой
Поскольку представления категориальных признаков очень разрежены
и многомерны, общепринятым способом является представление их в
низкоразмерные пространства (например, вложения слов). В
частности,мы представляем каждый категориальный признак с помощью
низкоразмерного вектора, т. е.,

гдеVi- матрица вложения для поля
i, аxi- одноразовый
вектор. Часто категориальные признаки могут быть многозначными, то
естьxi- это многозначный вектор.
Возьмем в качестве примера прогнозирование просмотра фильмов. Может
существовать функциональное поле Жанр, которое описывает типы
фильма, и оно может быть многозначным (например, Драма и Романтика
для фильма Титаник). Для совместимости с многозначными входными
данными мы дополнительно модифицируем уравнение 2 и представляем
многозначное поле признаков как среднее значение соответствующих
векторов внедрения признаков:

где q - количество значений, которые имеет
выборка для i-гополя,
аxi- мульти-горячее векторное
представление для этого поля.
Чтобы обеспечить взаимодействие между категориальными и
числовыми признаками, мы также представляем числовые признаки в том
же низкоразмерном пространстве признаков. В частности, мы
представляем числовую характеристику как

гдеvm- вектор вложения для поля
m, аxm- скалярное
значение.
Таким образом, выход слоя встраивания будет представлять собой
конкатенацию нескольких векторов встраивания, как показано на
Рис.2.
4.4Взаимодействующий слой
Как только числовые и категориальные признакиперенесеныв одно и
то же низкоразмерное пространство, мы переходим к моделированию
комбинаторных признаков высокого порядка в этом пространстве.
Ключевая проблема состоит в том, чтобы определить, какие признаки
должны быть объединены для формирования значимых признаков высокого
порядка. Традиционно это делается экспертами по предметной области,
которые создают значимые комбинации на основе своих знаний. В этой
статье мы решаем эту проблему с помощью нового метода -
многослойного механизма само-внимания [36].
Многослойнаяясамосознательнаясеть (Multi-head self-attentive
network) [36] в последнее время достигла замечательных результатов
в моделировании сложных отношений. Например, он показывает
превосходство для моделирования произвольной зависимости слов в
машинном переводе [36] и встраивании предложений [20], а также был
успешно применен для захвата сходства узлов при встраивании графов
[37]. Здесь мы расширяемэтот новейший метод для моделирования
корреляций между различными полями признаков.
В частности, мы применяем механизм вниманияключ-значение[22],
чтобы определить, какие комбинации функций имеют смысл. Взяв в
качестве примера функцию m, далее мы объясним, как
идентифицировать несколько значимых функций высокого порядка,
включающих функцию m. Сначала мы определяем корреляцию между
признаком m и признаком k в
рамках особого внимания головы(слоя)h следующим
образом:

где (h) (, ) - функция внимания, определяющая
сходство между характеристикой m и k. Его можно
определить как нейронную сеть или просто как внутренний продукт, то
есть, . В этой работе мы используем внутренний
продукт из-за его простоты и эффективности.
W(h)Query,
W(h)KeyRd dв уравнении 5
- это матрицы преобразования, которые отображают исходное
пространство вложенияRdв новое
пространствоRd. Затем мы обновляем
представление признака m в подпространстве h,
комбинируя все соответствующие признаки, руководствуясь
коэффициентами (h)m, k:

поскольку результат (6) представляет собой комбинацию признака
m и его соответствующих признаков (под заголовком
h), он представляет собой новую комбинаторную
особенность, изученную с помощью нашего метода. Кроме того, функция
также может быть задействована в различных комбинаторных функциях,
мы достигаем этого с помощью нескольких заголовков, которые создают
разные подпространства и изучают различные взаимодействия функций
отдельно. Мы собираем комбинаторные особенности, изученные во всех
подпространствах, следующим образом:

где- оператор конкатенации, а H - количество общих голов.
 m.")
Рисунок 3: Архитектура взаимодействующего
уровня. Комбинаторные свойства обусловлены весами внимания, т.е.
(h) m.
Чтобы сохранить ранее изученные комбинаторные функции, включая
необработанные индивидуальные (т. е. первого порядка) функции, мы
добавляем стандартные остаточные соединения в нашу сеть.
Формально,
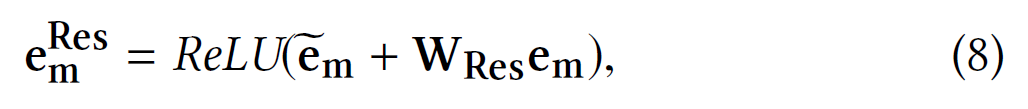
гдеW ResR d H d - матрица
проекции в случае несовпадения размерностей [12], а
ReLU(z) = max (0, z) - нелинейная функция
активации.
С таким взаимодействующим слоем представление каждого
объектаemбудет обновлено до
нового представления объекта
eResm, котороеявляется
представлением объектов высокого порядка. Мы можем складывать
несколько таких слоев с выходом предыдущего взаимодействующего слоя
в качестве входа следующего взаимодействующего слоя. Делая это, мы
можем моделировать комбинаторные особенности произвольного
порядка.
4.5Выходной слой
Выход взаимодействующего слоя представляет собой набор векторов
признаков
{eResm}Mm=1,
который включает в себя необработанные индивидуальные признаки,
зарезервированные остаточным блоком, и комбинаторные признаки,
изученные с помощью многоголового
(многослойного)механизмасамовнимания. Для окончательного
прогнозирования CTR мы просто объединяем их все, а затем применяем
нелинейную проекцию следующим образом:

где wR d H M - вектор проекции
столбца, который линейно объединяет сцепленные функции,
b - смещение, а (x) = 1 / (1 +
ex) преобразует значения в вероятности
нажатия пользователем.
4.6Обучение
Наша функция потерь - это журнал потерь, который определяется
следующим образом:

гдеyjиyj-
достоверные данные о кликах пользователя и оцененном CTR
соответственно, j индексирует обучающие выборки, а
N - общее количество обучающих выборок. Параметры,
которые необходимо изучить в нашей модели:
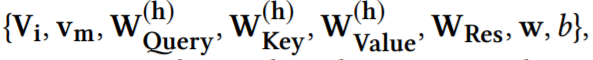
которые обновляются путем минимизации общейloglossс
использованием градиентного спуска.
4.7АнализAutoInt
Моделирование комбинаторных признаков произвольного порядка.
Учитывая оператор взаимодействия функций, определенный уравнением
5-8, мы теперь анализируем, как комбинаторные особенности низкого и
высокого порядка моделируются в предлагаемой нами модели.
Для простоты предположим, что имеются четыре поля функций (т.е.
M = 4), обозначенных как x1, x2,
x3 и x4 соответственно. Внутри
первого взаимодействующего уровня каждая отдельная функция
взаимодействует с любыми другими характеристиками через механизм
внимания (например, уравнение 5) и, следовательно, набор комбинаций
функций второго порядка, таких как g (x1,
x2), g (x2, x3) и g(x3,
x4)применяетсяс различными весами
корреляции, где неаддитивное свойство функциивзаимодействия g ()
(Определение2) может быть обеспечено нелинейностью функции
активацииReLU(). В идеале комбинаторные признаки, которые включают
x1, могут быть закодированы в
обновленное представление первого поля признака
eRes1. Поскольку то же самое
может быть полученоидля других полей объектов, все взаимодействия
объектов второго порядка могут быть закодированы в выходных данных
первого взаимодействующего слоя, где веса внимания отбирают
полезные комбинации объектов.
Затем мы докажем, что взаимодействия функций высшего порядка
можно моделировать во втором взаимодействующем слое. Учитывая
представление первого поля признаков
eRes1 и
представление третьего поля признаков
eRes3,
сгенерированного первым взаимодействующим слоем, комбинаторные
признаки третьего порядка, которые включают
x1, x2 и
x3, можно смоделировать, разрешив
eRes1
присутствовать на
eRes3, потому что
eRes1 содержит
взаимодействие g (x1,
x2), а
eRes3 содержит
индивидуальный признак x3 (из
остаточной связи). Более того, максимальный порядок комбинаторных
свойств растет экспоненциально по отношению к количеству
взаимодействующих слоев. Например, взаимодействие характеристик
четвертого порядка g (x1, x2,
x3, x4) может быть захвачено
комбинацией eRes1и
eRes3, которые
содержат взаимодействия второго порядка g
(x1, x2) и g
(x3 , x4) соответственно.
Следовательно, нескольких взаимодействующих слоев будет достаточно
для моделирования взаимодействий функций высокого порядка.
Основываясь на приведенном выше анализе, мы можем видеть,
чтоAutoIntизучает взаимодействия функций с механизмом внимания
иерархическим образом, то есть от низкого порядка к высокому, и все
взаимодействия функций низкого порядка осуществляются остаточными
связями. Это многообещающе и разумно, потому что обучение
иерархическому представлению оказалось довольно эффективным в
компьютерном зрении и обработке речи с помощью глубоких нейронных
сетей [3, 18].
Используемое пространство
Слой внедрения, который является общим компонентом в методах на
основе нейронных сетей [11, 19, 32], содержитndпараметров, где
n - размер разреженного представления
входного объекта, а d - размер внедрения.
Поскольку взаимодействующий уровень содержит следующие весовые
матрицы: {W (h)Query, W
(h)Key, W
(h)Value,WRes},
количество параметров в сети L-уровня равно
L (3dd + d Hd),и ононе зависит от количества полей
признаков M. Наконец, в выходном слое есть
d HM + 1параметров. Что касается взаимодействующих
слоев, сложность пространства равна O (LddH).
Обратите внимание, что H и d
обычно малы (например, H = 2 и d = 32 в наших
экспериментах), что делает взаимодействующий слой эффективным с
точки зрения памяти.
Используемое время
Внутри каждого взаимодействующего слоя вычислительные затраты
удваиваются. Во-первых, вычисление веса внимания для одной
головы(одного слоя)занимает O(Mdd' + M2d')времени.
Впоследствии формирование комбинаторных признаков под одной
головкой также занимает O(Mdd' + M2d') времени.
Поскольку у нас есть H голов(слоев), это занимает
O(MHd' (M + d)) времени в целом. Поэтому он
эффективен, потому чтоH,dи d '
обычно малы. Мы приводим время работыAutoIntв разделе 5.2.
5.Эксперимент
В этом разделе мы переходим к оценке эффективности предлагаемого
нами подхода. Мы стремимся ответить на следующие вопросы:
RQ1)Как предлагаемый намиAutoIntрешает проблему
прогнозирования CTR?Эффективен ли он для крупномасштабных
разреженных и многомерных данных?
RQ2)На что влияют разные конфигурации
моделей?
RQ3)Каковы структуры зависимостей между
различными функциями?Объяснима ли предложенная нами модель?
RQ4)Будет ли интеграция неявного взаимодействия
функций улучшать производительность? Прежде чем отвечать на эти
вопросы, мы сначала опишем экспериментальные настройки.

Таблица 1: Статистика наборов оценочных данных.
5.1Настройка эксперимента
5.1.1Наборы данных. Мы используем четыре
общедоступных набора реальных данных. Статистика наборов данных
сведена в Таблицу 1.
Criteo.Это эталонный набор данных для
прогнозирования CTR, в котором 45 миллионов пользователейкликают по
отображаемой рекламе. Он содержит 26категорийныхполей признаков и
13 числовых полей признаков.
Avazu.Этот набор данных содержит данные о
поведении пользователей на мобильных устройствах, в том числе о
том, нажимает ли пользователь на отображаемое мобильное объявление.
Он имеет 23 поля функций, от функций пользователя/устройства до
атрибутов рекламы.
KDD12. Этот набор данных был выпущенKDDCup2012,
изначально предназначавшимся для прогнозирования количества кликов.
Поскольку наша работа сосредоточена на прогнозировании CTR, а не на
точном количестве кликов, мы рассматриваем эту проблему как
проблему двоичной классификации (1 для кликов> 0, 0 для кликов
без кликов), которая аналогична FFM [16].
MovieLens-1M.Этот набор данных содержит оценки
пользователей фильмов. Во время бинаризации(бинарного
представления)мы обрабатываем образцы с рейтингом менее 3 как
отрицательные, потому что низкий балл указывает на то, что
пользователю не нравится фильм. Мы обрабатываем образцы с рейтингом
выше 3 как положительные и удаляемобразцынейтральныес рейтингом,
равным 3.
Подготовка данных. Во-первых, мы удаляем редко
встречающиеся функции (появляющиеся в экземплярах ниже порогового
значения) и рассматриваем их как одну функцию <неизвестно>,
где порог установлен на {10, 5, 10} для наборов данныхCriteo,Avazuи
KDD12 соответственно. Во-вторых, поскольку числовые характеристики
могут иметь большую дисперсию и вредить алгоритмам машинного
обучения, мы нормализуем числовые значения, преобразуя значение
z вlog2(z)
если z> 2,какпредложенопобедителем
конкурсаCriteoCompetition. В-третьих, мы случайным образом выбираем
80% всех выборок для обучения и случайным образом разделяем
остальные навалидационныеи тестовые наборы равного размера.
5.1.2Показатели Оценки. Мы используем две
популярные метрики для оценки эффективности всех методов:
Область AUC под кривой ROC (AUC)измеряет
вероятность того, что предсказатель CTR присвоит более высокий балл
случайно выбранному положительному элементу, чем случайно
выбранному отрицательному элементу. Более высокий AUC указывает на
лучшую производительность.
Logloss.Поскольку все модели пытаются
минимизироватьloglossпотери, определяемые уравнением 10, мы
используем его в качестве простой метрики.
Замечено, что несколько более высокий AUC или более
низкийLoglossна уровне 0,001 считается значимым для задачи
прогнозирования CTR, на что также указывалось в работах [8, 11,
38].
5.1.3Конкурирующие Модели. Мы сравниваем
предложенный подход с тремя классами предыдущих моделей:A) линейный
подход, который использует только индивидуальные особенности;Б)
методыфакторизации на основе машин, учитывающие комбинаторные
особенности второго порядка;C) методы, которые могут захватывать
взаимодействия объектов высокого порядка. Мы связываем классы
моделей с именами моделей соответственно.
LR (А). LR моделирует только линейную
комбинацию необработанных функций.
FM [26] (B). FM использует методы факторизации
для моделирования взаимодействия функций второго порядка.
АFМ [40] (B). AFM - одна из самых современных
моделей, которые фиксируют взаимодействия функций второго порядка.
Он расширяет FM, используя механизм внимания, чтобы различать
важностикомбинаторных свойств второго порядка.
DeepCrossing[32] (C).DeepCrossingиспользует
глубокиеполносвязныенейронные сети с остаточными связями для
изучения нелинейных взаимодействий признаков неявным способом.
NFM [13] (C). NFM укладывает глубокие нейронные
сети поверх слоя взаимодействия объектов второго порядка.
Взаимодействия признаков высокого порядка неявно фиксируются
нелинейностью нейронных сетей.
CrossNet[38] (С). Кросс-сеть, являющаяся ядром
моделиDeep&Cross, использует внешнее произведение сцепленного
вектора признаков на битовом уровне для явного моделирования
взаимодействий признаков.
CIN [19] (C). Сжатая сеть взаимодействия,
являющаяся ядром моделиxDeepFM, принимает внешнее произведение
сложенной матрицы признаков на векторном уровне.
HOFM[5] (С). HOFM предлагает эффективные
алгоритмы на основе ядра для обучения машин факторизации высокого
порядка. Следуянастройкам вBlondeletal. [5] иЧуа[13], мы строим
машину факторизации третьего порядка, используя публичную
реализацию.
Позже мы сравним с полными моделямиCrossNetи CIN, то
естьDeep&CrossиxDeepFM, при настройке совместного обучения
сplainDNN (т. е. раздел 5.5).
5.1.4Деталиреализации. Все методы реализованы
вTensorFlow[1]. ДляAutoIntи всех базовых методов мы эмпирически
установили размерность вложения d равным 16, а размер пакета -
1024.AutoIntимеет три взаимодействующих слоя, а количество скрытых
блоков d по умолчанию равно 32. Внутри каждого взаимодействующего
слоя число внимания головы(по слою)- два. Чтобы предотвратить
переоснащение, мы используем поиск по сетке для выбора коэффициента
отсева [34] из {0.1 - 0.9} для набора данных MovieLens-1M, и мы
обнаружили, что отсев неявляется необходимым для других трех
больших наборов данных. Для базовых методов мы используем один
скрытый слой размером 200 поверх слоя Би-взаимодействия для NFM,
как это рекомендовано в их статье. Для CN и CIN мы используем три
уровня взаимодействия после AutoInt.DeepCrossingимеет четыре слоя
обратной связи и количество из скрытых единиц получается 100,
потому что она плохо работает при использовании трех нейронных
слоев. Как только все сетевые структуры будут исправлены, мы также
применим сеточныйпоиск к базовым методам для получения оптимальных
параметров шума. Наконец, мы используемAdam[17] для оптимизации
всех моделей, основанных на глубоких нейронных сетях.

Таблица 2: сравнение эффективности
различных алгоритмов. Мы подчеркиваем, что предложенная нами модель
почти превосходит все базовые показатели по четырем наборам данных
и обеим метрикам. Дальнейший анализ представлен в разделе 5.2.
5.2Количественные результаты (RQ1)
Оценка эффективности.Мы суммируем результаты,
усредненные по 10 различным прогонам, в Таблицу 2. У нас есть
следующие наблюдения: 1) FM и AFM, которые исследуют взаимодействия
функций второго порядка, последовательно превосходят LR с большим
отрывом по всем наборам данных, что указывает на то, что отдельные
функции недостаточны для прогнозирования CTR;2)интересное
наблюдение - неполноценность некоторых моделей, которые фиксируют
взаимодействия функций высокого порядка;например, хотяDeepCrossingи
NFM используют глубокую нейронную сеть в качестве основного
компонента для изучения взаимодействий функций высокого порядка,
они не гарантируют улучшения по сравнению с FM и AFMи это может
быть связано с тем, что они изучают взаимодействие функций неявным
образом(напротив, CIN делает это явно и последовательно превосходит
модели более низкого порядка);3) HOFM значительно превосходит FM по
наборам данныхCriteoи MovieLens-1M, что указывает на то, что
моделирование взаимодействий функций третьего порядка может быть
полезным для производительности
прогнозирования;4)AutoIntобеспечивает наилучшую производительность
общих базовых методов на трех из четырех реальных наборов
данных.
В наборе данныхAvazuCIN работает немного лучше, чемAutoIntв
оценке AUC, но мы получаем более низкийLogloss. Обратите внимание,
что предлагаемый намиAutoIntимеет те же структуры, что
иDeepCrossing, за исключением слоя взаимодействия функций, который
указывает на то, что использование механизма внимания для изучения
явных комбинаторных функций имеет решающее значение.

Рисунок 4. Сравнение эффективности
различных алгоритмов с точки зрения времени выполнения. "DC и CN -
это DeepCrossing и CrossNet для краткости, соответственно.
Поскольку HOFM не может быть помещен на одну графическую карту для
набора данных KDD12, дополнительные затраты на связь делают его
наиболее трудоемким. Дальнейший анализ представлен в разделе 5.2.
Оценка эффективности моделиМы представляем
результаты выполнения различных алгоритмов для четырех наборов
данных на рисунке 4. Неудивительно, что LR является наиболее
эффективным алгоритмом из-за его простоты. FM и NFM работают
одинаково с точки зрения времени выполнения, потому что NFM только
накладывает один скрытый уровень прямых связейповерх уровня
взаимодействия второго порядка. Среди всех перечисленных методов
CIN, который обеспечивает лучшую производительность для
прогнозирования среди всех базовых линий, требует гораздо больше
времени из-за своего сложного пересекающегося слоя. Это может
сделать его непрактичным в промышленных сценариях. Обратите
внимание, что AutoInt достаточно эффективен, что сопоставимо с
эффективными алгоритмамиDeepCrossingи NFM.
Мы также сравниваем размеры разных моделей (то есть количество
параметров) как еще один критерий оценки эффективности. Как
показано в таблице 3, по сравнению с лучшей моделью CIN в базовых
моделях количество параметров вAutoIntнамного меньше.
Подводя итог, можно сказать, что предложенный
намиAutoIntдостигает наилучшей производительности среди всех
сравниваемых моделей. По сравнению с наиболее конкурентоспособной
базовой моделью CIN,AutoIntтребует гораздо меньшего количества
параметров и гораздо более эффективен при онлайн-выводе.

Таблица 3: сравнение эффективности
различных алгоритмов с точки зрения размера модели на наборе данных
Criteo. DC и CN - это DeepCrossing и CrossNet для краткости,
соответственно. Подсчитанные параметры исключают слой встраивания.
5.3Анализ (RQ2)Для дальнейшей валидации и
получения глубокого понимания предложенной модели,мы проводим
абляционное исследование и сравниваем несколько
вариантовAutoInt.
5.3.1Влияние остаточной структуры.
СтандартныйAutoIntиспользует остаточные связи, которые переносят
все изученные комбинаторные функции и, следовательно, позволяют
моделировать комбинации очень высокого порядка. Чтобы оправдать
вклад остаточных единиц, мы отделяем их от нашей стандартной модели
и оставляем другие структуры такими, какие они есть. Как показано в
Таблице 4, мы видим, что производительность снижается для всех
наборов данных при удалении остаточных соединений. В частности,
полная модель превосходит вариантс большим отрывом по данным KDD12
и MovieLens-1M, что указывает на то, что остаточные связи имеют
решающее значение для моделирования взаимодействий функций высокого
порядка в предлагаемом нами методе.

Таблица 4: Исследование абляции, сравнение
эффективности AutoInt с остаточными соединениями и без них. AutoInt
w это полная модель, в то время как AutoInt w/o модель без
остаточного соединения.
5.3.2Влияние глубины сети.Наша модель изучает
комбинации объектов высокого порядка путем укладки нескольких
взаимодействующих слоев (введено в разделе 4). Поэтому нас
интересует, как изменяется
производительностьотносительноколичествавзаимодействующих слоев, то
есть порядок комбинаторных признаков. Заметим, что когда нет
взаимодействующего слоя (то есть количество слоев равно нулю), наша
модель принимает в качестве входных данных взвешенную сумму
необработанных индивидуальных признаков, то есть комбинаторные
признаки не рассматриваются.
Результаты представлены на рисунке 5. Мы видим, что если
используется один взаимодействующий уровень, то есть учитывается
взаимодействие функций, производительность резко возрастает для
обоих наборов данных, показывая, что комбинаторные функции очень
информативны для прогнозирования. По мере дальнейшего увеличения
числа взаимодействующих слоев, т. е. учета комбинаторных свойств
более высокого порядка, производительность модели еще больше
возрастает. Когда количество слоев достигает трех,
производительность становится стабильной, показывая, что добавление
функций очень высокого порядка неинформативно для
прогнозирования.

Рисунок 5: Производительность относительно
количества взаимодействующих слоев. Результаты на Criteo, и Avazu
наборов данных, аналогичны и, следовательно, опущено.

Рисунок 6: производительность относительно
количества размеров вложения. Результаты на Criteo, и Avazu наборов
данных, аналогичны и, следовательно, опущено.
5.3.3влияние различных измерений. Далее мы
исследуем производительностьотносительнопараметраd, который
является выходным размером слоя вложения. На наборе данных KDD12 мы
видим, что производительность постоянно увеличивается по мере
увеличения размера измерения, поскольку для прогнозирования
используются более крупные модели. Результаты отличаются в наборе
данных MovieLens-1M. Когда размер измерения достигает 24,
производительность начинает снижаться. Причина в том, что этот
набор данных невелик, и модель переоснащается, когда используется
слишком много параметров.
5.4Объяснимые рекомендации (RQ3)
Хорошая рекомендательная система может не только дать хорошие
рекомендации, но и предложить хорошую объяснимость. Поэтому в этой
части мы представляем, как нашAutoIntможет объяснить результаты
рекомендаций. В качестве примера возьмем набор данных
MovieLens-1M.
Рассмотрим результат рекомендации, предложенный нашим
алгоритмом, то есть пользователь любит товар. На рис. 7 (а)
представлены корреляции между различными полями входных признаков,
полученные с помощью оценки внимания.Мы видим, чтоAutoIntспособен
идентифицировать значимый комбинаторный признак
<Gender=Male,Age=[18-24),MovieGenre=Action&Triller> (т.
е. красный пунктирный прямоугольник).Это очень разумно, так как
молодые люди, скорее всего, предпочтут боевики и триллеры.
.")
Таблица 5: Результаты интеграции неявных
взаимодействий функций. Мы указываем базовую модель каждого метода.
Последние два столбца представляют собой средние изменения AUC и
Logloss по сравнению с соответствующими базовыми моделями (+:
увеличение, -: уменьшение).
Нас также интересует, каковы корреляции между различными полями
признаков в данных. Поэтому мы измеряем корреляции между полями
признаков в соответствии с их средним показателем внимания во всех
данных. Корреляции между различными полями суммированы на рис. 7
(б). Мы видим, что <Gender,Genre>, <Age,Genre>,
<RequestTime,ReleaseTime> и <Gender,Age,Genre> (т. е.
сплошная зеленая область) сильно коррелируют, что является
объяснимыми правилами рекомендации в этой области.
 карты весов внимания для взаимодействия функций на уровне случая и глобального уровня на MovieLens-1M. Оси представляют поля функций <Пол, Возраст, Занятие, Почтовый индекс, RequestTime, RealeaseTime, Genre>. Мы выделяем некоторые изученные комбинаторные функции в прямоугольниках.")
Рисунок 7: Тепловые (фазовые) карты весов
внимания для взаимодействия функций на уровне случая и глобального
уровня на MovieLens-1M. Оси представляют поля функций <Пол,
Возраст, Занятие, Почтовый индекс, RequestTime, RealeaseTime,
Genre>. Мы выделяем некоторые изученные комбинаторные функции в
прямоугольниках.
5.5 Интеграция неявных взаимодействий (RQ4)
Нейронные сети с обратным влияниемспособнымоделировать неявные
взаимодействия признаков и широко интегрированыв существующие
методы прогнозирования CTR [8, 11, 19]. Чтобы исследовать, улучшает
ли интеграция неявных взаимодействий признаков дальнейшую
производительность, мы объединяемAutoIntс двухслойной нейронной
сетью обратной влияния путем совместного обучения. Мы называем
совместную модельAutoInt+ и сравниваем ее со следующими
алгоритмами:
-
Wide&Deep[8].Wide&Deepинтегрирует результаты
логистической регрессии и нейронных сетей обратного влияния;
-
DeepFM[11].DeepFMсочетает в себе обучающие машиныфакторизации
второго порядка и нейронную сеть обратнойсвязи с общим слоем
встраивания;
-
Deep&Cross[38].Deep&Cross-эторасширениеCrossNetза счет
интеграции нейронных сетей с обратной связью;
-
xDeepFM[19].xDeepFM- это расширение CIN путем интеграции
нейронных сетей с прямой связью.
В таблице 5 представлены усредненные результаты (более 10
прогонов) моделей совместного обучения.У нас есть следующие
наблюдения: 1) производительность нашего метода улучшается при
совместном обучении с нейронными сетями обратного влиянияна всех
наборах данных, чтоуказывает на то, что интеграция неявных
взаимодействий признаков действительно повышает прогностическую
способность предлагаемой нами модели, но, как видно из последних
двух столбцов, величина улучшения производительности довольно мала
по сравнению с другими моделями, что показывает, что наша
индивидуальнаямодельAutoIntдовольно мощна;2) после интегрирования
неявного характеристика взаимодействия,AutoInt+ превосходит все
конкурентные способы, и достигаетновыхсовременныххарактеристик
используемых наборов данных прогнозирования CTR.
6.Заключение и будущая работа
В этой работе мы предлагаем новую модель прогнозирования CTR,
основанную на механизме само-внимания, который может автоматически
изучать взаимодействия признаков высокого порядка в явном виде.
Ключом к нашему методу являетсявновьвводимыйвзаимодействующий слой,
который позволяет каждой функции взаимодействовать с другими и
определять релевантность посредством обучения. Экспериментальные
результаты на четырех наборах реальных данных демонстрируют
эффективность и действенность предложенной нами модели. Кроме того,
мы обеспечиваем хорошую объяснимость модели с помощью визуализации
изученных комбинаторных функций. Интегрируясь с неявными
взаимодействиями признаков,охватываемыминейронными сетями обратного
влияния, мы достигаем лучших автономных оценок AUC иLoglossпо
сравнению с предшествующимисовременными методами.
Для будущей работымы заинтересованы во включении контекстной
информации в наш метод и улучшении его производительности длясистем
онлайн-рекомендаций. Кроме того, мы также планируем
расширитьAutoIntдля решения общих задач машинного обучения, таких
как регрессия, классификация и ранжирование.
Ссылки
[1] Martn Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy
Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey
Irving, et al. 2016. TensorFlow: A System for Large-Scale Machine
Learning.. In OSDI, Vol. 16. 265283.
[2] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2015.
Neural machine translation by jointly learning to align and
translate. In International Conference on Learning
Representations.
[3] Yoshua Bengio, Aaron Courville, and Pascal Vincent. 2013.
Representation learning: A review and new perspectives. IEEE
transactions on pattern analysis and machine intelligence 35, 8
(2013), 17981828.
[4] Alex Beutel, Paul Covington, Sagar Jain, Can Xu, Jia Li,
Vince Gatto, and Ed H Chi. 2018. Latent Cross: Making Use of
Context in Recurrent Recommender Systems. In Proceedings of the
Eleventh ACM International Conference on Web Search and Data
Mining. ACM, 4654.
[5] Mathieu Blondel, Akinori Fujino, Naonori Ueda, and Masakazu
Ishihata. 2016. Higher-order factorization machines. In Advances in
Neural Information Processing Systems. 33513359.
[6] Mathieu Blondel, Masakazu Ishihata, Akinori Fujino, and
Naonori Ueda. 2016. Polynomial Networks and Factorization Machines:
New Insights and Efficient Training Algorithms. In International
Conference on Machine Learning. 850858.
[7] Chen Cheng, Fen Xia, Tong Zhang, Irwin King, and Michael R
Lyu. 2014. Gradient boosting factorization machines. In Proceedings
of the 8th ACM Conference on Recommender systems. ACM, 265272.
[8] Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked,
Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei
Chai, Mustafa Ispir, et al.Wide & deep learning for recommender
systems. In Proceedings of the 1st Workshop on Deep Learning for
Recommender Systems. ACM, 710.
[9] Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep
neural networks for youtube recommendations. In Proceedings of the
10th ACM Conference on Recommender Systems. ACM, 191198.
[10] Thore Graepel, Joaquin Quionero Candela, Thomas Borchert,
and Ralf Herbrich. 2010. Web-scale Bayesian Click-through Rate
Prediction for Sponsored Search Advertising in Microsofts Bing
Search Engine. In Proceedings of the 27th International Conference
on International Conference on Machine Learning. 1320.
[11] Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and
Xiuqiang He. 2017. DeepFM: A Factorization-machine Based Neural
Network for CTR Prediction. In Proceedings of the 26th
International Joint Conference on Artificial Intelligence. AAAI
Press, 17251731.
[12] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.
2016. Deep residual learning for image recognition. In Proceedings
of the IEEE conference on computer vision and pattern recognition.
770778.
[13] Xiangnan He and Tat-Seng Chua. 2017. Neural factorization
machines for sparse predictive analytics. In Proceedings of the
40th International ACM SIGIR conference on Research and Development
in Information Retrieval. ACM, 355364.
[14] Xiangnan He, Zhankui He, Jingkuan Song, Zhenguang Liu,
Yu-Gang Jiang, and Tat-Seng Chua. 2018. NAIS: Neural attentive item
similarity model for recommendation. IEEE Transactions on Knowledge
and Data Engineering 30, 12 (2018), 23542366.
[15] Xinran He, Junfeng Pan, Ou Jin, Tianbing Xu, Bo Liu, Tao
Xu, Yanxin Shi, Antoine Atallah, Ralf Herbrich, Stuart Bowers, et
al. 2014. Practical lessons from predicting clicks on ads at
facebook. In Proceedings of the Eighth International Workshop on
Data Mining for Online Advertising. ACM, 19.
[16] Yuchin Juan, Yong Zhuang, Wei-Sheng Chin, and Chih-Jen Lin.
2016. Fieldaware factorization machines for CTR prediction. In
Proceedings of the 10th ACM Conference on Recommender Systems. ACM,
4350.
[17] Diederick P Kingma and Jimmy Ba. 2015. Adam: A method for
stochastic optimization. In International Conference on Learning
Representations.
[18] Honglak Lee, Roger Grosse, Rajesh Ranganath, and Andrew Y
Ng. 2011. Unsupervised learning of hierarchical representations
with convolutional deep belief networks. Commun. ACM 54, 10 (2011),
95103.
[19] Jianxun Lian, Xiaohuan Zhou, Fuzheng Zhang, Zhongxia Chen,
Xing Xie, and Guangzhong Sun. 2018. xDeepFM: Combining Explicit and
Implicit Feature Interactions for Recommender Systems. In
Proceedings of the 24th ACM SIGKDD International Conference on
Knowledge Discovery and Data Mining. ACM, 1754 1763.
[20] Zhouhan Lin, Minwei Feng, Cicero Nogueira dos Santos, Mo
Yu, Bing Xiang, Bowen Zhou, and Yoshua Bengio. 2017. A structured
self-attentive sentence embedding. In International Conference on
Learning Representations.
[21] H. Brendan McMahan, Gary Holt, D. Sculley, Michael Young,
Dietmar Ebner, Julian Grady, Lan Nie, Todd Phillips, et al. 2013.
Ad Click Prediction: A View from the Trenches. In Proceedings of
the 19th ACM SIGKDD International Conference on Knowledge Discovery
and Data Mining. ACM, 12221230.
[22] Alexander Miller, Adam Fisch, Jesse Dodge, Amir-Hossein
Karimi, Antoine Bordes, and Jason Weston. 2016. Key-Value Memory
Networks for Directly Reading Documents. In Proceedings of the 2016
Conference on Empirical Methods in Natural Language Processing.
Association for Computational Linguistics, 14001409.
[23] Alexander Novikov, Mikhail Trofimov, and Ivan Oseledets.
2016. Exponential machines. arXiv preprint arXiv:1605.03795
(2016).
[24] Richard J Oentaryo, Ee-Peng Lim, Jia-Wei Low, David Lo, and
Michael Finegold. Predicting response in mobile advertising with
hierarchical importanceaware factorization machine. In Proceedings
of the 7th ACM international conference on Web search and data
mining. ACM, 123132.
[25] Yanru Qu, Han Cai, Kan Ren, Weinan Zhang, Yong Yu, Ying
Wen, and Jun Wang.Product-based neural networks for user response
prediction. In Data Mining (ICDM), 2016 IEEE 16th International
Conference on. IEEE, 11491154.
[26] Steffen Rendle. 2010. Factorization machines. In Data
Mining (ICDM), 2010 IEEE 10th International Conference on. IEEE,
9951000.
[27] Steffen Rendle, Christoph Freudenthaler, and Lars
Schmidt-Thieme. 2010. Factorizing personalized markov chains for
next-basket recommendation. In Proceedings of the 19th
international conference on World wide web. ACM, 811820.
[28] Steffen Rendle, Zeno Gantner, Christoph Freudenthaler, and
Lars Schmidt-Thieme. Fast context-aware recommendations with
factorization machines. In Proceedings of the 34th international
ACM SIGIR conference on Research and development in Information
Retrieval. ACM, 635644.
[29] Matthew Richardson, Ewa Dominowska, and Robert Ragno. 2007.
Predicting clicks: estimating the click-through rate for new ads.
In Proceedings of the 16th international conference on World Wide
Web. ACM, 521530.
[30] Alexander M. Rush, Sumit Chopra, and Jason Weston. 2015. A
Neural Attention Model for Abstractive Sentence Summarization. In
Proceedings of the 2015 Conference on Empirical Methods in Natural
Language Processing. Association for Computational Linguistics,
379389.
[31] Lili Shan, Lei Lin, Chengjie Sun, and Xiaolong Wang. 2016.
Predicting ad clickthrough rates via feature-based fully coupled
interaction tensor factorization. Electronic Commerce Research and
Applications 16 (2016), 3042.
[32] Ying Shan, T Ryan Hoens, Jian Jiao, Haijing Wang, Dong Yu,
and JC Mao. 2016. Deep crossing: Web-scale modeling without
manually crafted combinatorial features. In Proceedings of the 22nd
ACM SIGKDD International Conference on Knowledge Discovery and Data
Mining. ACM, 255262.
[33] Weiping Song, Zhiping Xiao, Yifan Wang, Laurent Charlin,
Ming Zhang, and Jian Tang. 2019. Session-based Social
Recommendation via Dynamic Graph Attention Networks. In Proceedings
of the Twelfth ACM International Conference on Web Search and Data
Mining. ACM, 555563.
[34] Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya
Sutskever, and Ruslan Salakhutdinov. 2014. Dropout: A simple way to
prevent neural networks from overfitting. The Journal of Machine
Learning Research 15, 1 (2014), 19291958.
[35] Sainbayar Sukhbaatar, Jason Weston, Rob Fergus, et al.
2015. End-to-end memory networks. In Advances in neural information
processing systems. 24402448.
[36] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
Llion Jones, Aidan N Gomez, ukasz Kaiser, and Illia Polosukhin.
2017. Attention is all you need. In Advances in Neural Information
Processing Systems. 60006010.
[37] Petar Velickovic, Guillem Cucurull, Arantxa Casanova,
Adriana Romero, Pietro Lio, and Yoshua Bengio. 2018. Graph
Attention Networks. In International Conference on Learning
Representations.
[38] Ruoxi Wang, Bin Fu, Gang Fu, and Mingliang Wang. 2017. Deep
& Cross Network for Ad Click Predictions. In Proceedings of the
ADKDD17. ACM, 12:112:7.
[39] Xiang Wang, Xiangnan He, Fuli Feng, Liqiang Nie, and
Tat-Seng Chua. 2018. TEM: Tree-enhanced Embedding Model for
Explainable Recommendation. In Proceedings of the 2018 World Wide
Web Conference on World Wide Web. International World Wide Web
Conferences Steering Committee, 15431552.
[40] Jun Xiao, Hao Ye, Xiangnan He, Hanwang Zhang, Fei Wu, and
Tat-Seng Chua. Attentional factorization machines: learning the
weight of feature interactions via attention networks. In
Proceedings of the 26th International Joint Conference on
Artificial Intelligence. AAAI Press, 31193125.
[41] Weinan Zhang, Tianming Du, and Jun Wang. 2016. Deep
learning over multi-field categorical data. In European conference
on information retrieval. Springer, 4557.
[42] Qian Zhao, Yue Shi, and Liangjie Hong. 2017. GB-CENT:
Gradient Boosted Categorical Embedding and Numerical Trees. In
Proceedings of the 26th International Conference on World Wide Web.
International World Wide Web Conferences Steering Committee,
13111319.
[43] Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu,
Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep
Interest Network for ClickThrough Rate Prediction. In Proceedings
of the 24th ACM SIGKDD International Conference on Knowledge
Discovery and Data Mining. ACM, 10591068.
[44] Jie Zhu, Ying Shan, JC Mao, Dong Yu, Holakou Rahmanian, and
Yi Zhang. 2017. Deep embedding forest: Forest-based serving with
deep embedding features. In Proceedings of the 23rd ACM SIGKDD
International Conference on Knowledge Discovery and Data Mining.
ACM, 17031711.

 Фотография: Ali Saadat. Источник: Unsplash.com
Фотография: Ali Saadat. Источник: Unsplash.com
 Фотография: Taras Chernus. Источник: Unsplash.com
Фотография: Taras Chernus. Источник: Unsplash.com
 Принцип работы нашей системы - и пример
кусочка её выдачи
Принцип работы нашей системы - и пример
кусочка её выдачи







 Фотография: Kevin Grieve. Источник: Unsplash.com
Фотография: Kevin Grieve. Источник: Unsplash.com
 Фотография: Christopher Ott. Источник: Unsplash.com
Фотография: Christopher Ott. Источник: Unsplash.com
 Фотография: Glenn Carstens-Peters.
Источник: Unsplash.com
Фотография: Glenn Carstens-Peters.
Источник: Unsplash.com
 Фотография: Dodi Achmad. Источник: Unsplash.com
Фотография: Dodi Achmad. Источник: Unsplash.com


















 Эго-граф Хоппера
Эго-граф Хоппера








 Это GIF длиной 1 минуту
Это GIF длиной 1 минуту


 где d - размерность пространства эмбеддингов, - граница
ошибки аппроксимации. Это проверяется путем выучивания скалярного
произведения через сэмплирование векторов из нормально
распределенной генеральной совокупности, вычислением их скалярных
произведений с добавлением шума с низким отклонением и обучении
аппроксимирующей модели. В результате несколько различных
конфигураций персептрона не смогли выучить функцию скалярного
произведения с нужной точностью за допустимое количество шагов.
где d - размерность пространства эмбеддингов, - граница
ошибки аппроксимации. Это проверяется путем выучивания скалярного
произведения через сэмплирование векторов из нормально
распределенной генеральной совокупности, вычислением их скалярных
произведений с добавлением шума с низким отклонением и обучении
аппроксимирующей модели. В результате несколько различных
конфигураций персептрона не смогли выучить функцию скалярного
произведения с нужной точностью за допустимое количество шагов.






