На схеме видно, что зашифровать можно почти все потоки внутри Zabbix. В этой статье мы расскажем и покажем как это сделать, а еще расскажем о новой интеграции Zabbix с хранилищем секретов Hashicorp Vault. Там можно хранить любую чувствительную информацию от логина/пароля в БД до значений макросов. Это позволит централизованно управлять авторизационными данными, вести аудит и не хранить их на файловой системе или в БД Zabbix. Такой функционал появился в последней (на момент публикации статьи) версии Zabbix 5.2.
Интересный факт: включение шифрования на компонентах Zabbix не требует открытия дополнительных портов на фаерволлах, демоны Zabbiх поддерживают шифрованные и нешифрованные соединения одновременно.
Велкам ту подкат.
В Zabbix есть следующие основные информационные потоки:
- Пользователь (web-браузер) <-> Zabbix web-сервер. Управление конфигурацией Zabbix, представление метрик. Шифрование настраивается средствами web-сервера.
- Zabbix web-сервер <-> Zabbix-сервер. Web-сервер проверяет запущен ли Zabbix-сервер, запрашивает текущее состояние очереди, выполняет тест элементов данных и некоторые другие операции. Единственный поток, который в соответствии с архитектурой Zabbix нельзя зашифровать. Мы даже пытаться не будем.
- Zabbix web-сервер <-> База данных Zabbix. Web-сервер обновляет конфигурацию в БД, извлекает данные для визуализации, удаляет исторические данные (по нажатию на Очистить историю) и запускает задания Выполнить сейчас (Execute now). Можно настроить при установке или позже в файле конфигурации zabbix.conf.php. Поддерживается TLS-шифрование при помощи ключей. Для хранения логина и пароля для БД можно использовать Vault. Важный факт: сертификаты, защищённые паролем не поддерживаются.
- Zabbix-сервер <-> База данных Zabbix. Zabbix-сервер через configuration syncer загружает в свой кэш конфигурацию, через history syncer записывает собранные данные в БД, очищает историю (housekeeping) и выполняет некоторые другие операции. Настройки шифрования выполняются через присваивание значений специальным ключам в конфигурационном файле zabbix_server.conf.
- Zabbix-сервер <-> Zabbix-агент. Поддерживаются общий ключ PSK и сертификаты. Взаимодействие этих компонентов делится на две части: к узлу сети (TLSAccept для пассивных проверок) и от узла сети (TLSConnect для активных проверок).
- Zabbix-сервер <-> Zabbix-прокси. Поддерживаются общий ключ PSK и сертификаты. Настройки выполняются через присваивание значений специальным ключам в конфигурационном файле zabbix_proxy.conf.
- Zabbix-прокси <-> Zabbix-агент. Поддерживаются общий ключ PSK и сертификаты. Взаимодействие этих компонентов делится на две части: к узлу сети (TLSAccept для пассивных проверок) и от узла сети (TLSConnect для активных проверок).
- Zabbix-прокси <-> БД Zabbix-прокси. Настройки выполняются через присваивание значений специальным ключам в конфигурационном файле zabbix_proxy.conf.
- Zabbix sender -> Zabbix-прокси. Поддерживаются общий ключ PSK и сертификаты в качестве параметров при вызове через командную строку.
- Zabbix-агент -> Zabbix get. Поддерживаются общий ключ PSK и сертификаты в качестве параметров при вызове через командную строку.
Пользователь (web-браузер) <-> Zabbix web-сервер
Шифрование этой коммуникации не поддерживается со стороны Zabbix, нужно самостоятельно выполнить настройку на стороне Apache или Nginx. В этой статье мы рассмотрим настройку Nginx с самоподписанным SSL-сертификатом, т.к. преимущественно используем именно Nginx в своих проектах по мониторингу на базе Zabbix. Можно использовать сертификат доверенного центра сертификации, например, бесплатный от Let's Encrypt. Это позволит избежать страшных предупреждений в браузере. Обращаем внимание, что использование самоподписанного сертификата никак не умаляет надежности шифрованного соединения, оно будет таким же защищённым как и при использовании сертификата от доверенного CA.
Листинг настройки
# mkdir -p /etc/ssl/private/
# chmod 0750 /etc/ssl/private
# openssl req \
> -newkey rsa:2048 -nodes -keyout /etc/ssl/private/zabbix.key
\
> -x509 -days 365 -out /etc/ssl/certs/zabbix.crt \
> -subj
"/C=RU/ST=Russia/L=Moscow/O=Gals/OU=Gals_Dev/CN=gals.software/emailAddress=welcome@gals.software"
# chmod 0400 /etc/ssl/certs/zabbix.crt
# chmod 0400 /etc/ssl/private/zabbix.key
# mv /etc/nginx/conf.d/zabbix.conf
/etc/nginx/conf.d/zabbix-ssl.conf
# vi /etc/nginx/conf.d/zbx-ssl.conf
listen 443 ssl default_server;
ssl on;
ssl_certificate /etc/ssl/certs/zabbix.crt;
ssl_certificate_key /etc/ssl/private/zabbix.key;
# vi /etc/nginx/conf.d/zabbix.conf
server {
listen 80;
return 301 https://$host$request_uri;
}
# systemctl restart nginx
В браузере появится замочек и можно посмотреть детали сертификата. Соединение зашифровано.

Zabbix web-сервер <-> База данных Zabbix
Перед началом настройки на стороне Zabbix, в БД должны быть созданы пользователи и роли с атрибутами, требующими шифрованное подключение.
Листинг создания пользователей для Zabbix
web-сервера и Zabbix-сервера
mysql> CREATE USER 'zabbix_srv'@'%' IDENTIFIED WITH mysql_native_password BY '<strong_password>', 'zabbix_web'@'%' IDENTIFIED WITH mysql_native_password BY '<strong_password>' REQUIRE SSL PASSWORD HISTORY 5; mysql> CREATE ROLE 'zabbix_srv_role', 'zabbix_web_role'; mysql> GRANT SELECT, UPDATE, DELETE, INSERT, CREATE, DROP, ALTER, INDEX, REFERENCES ON zabbix.* TO 'zabbix_srv_role'; mysql> GRANT SELECT, UPDATE, DELETE, INSERT ON zabbix.* TO 'zabbix_web_role'; mysql> GRANT 'zabbix_srv_role' TO 'zabbix_srv'@'%'; mysql> GRANT 'zabbix_web_role' TO 'zabbix_web'@'%'; mysql> SET DEFAULT ROLE 'zabbix_srv_role' TO 'zabbix_srv'@'%'; mysql> SET DEFAULT ROLE 'zabbix_web_role' TO 'zabbix_web'@'%';
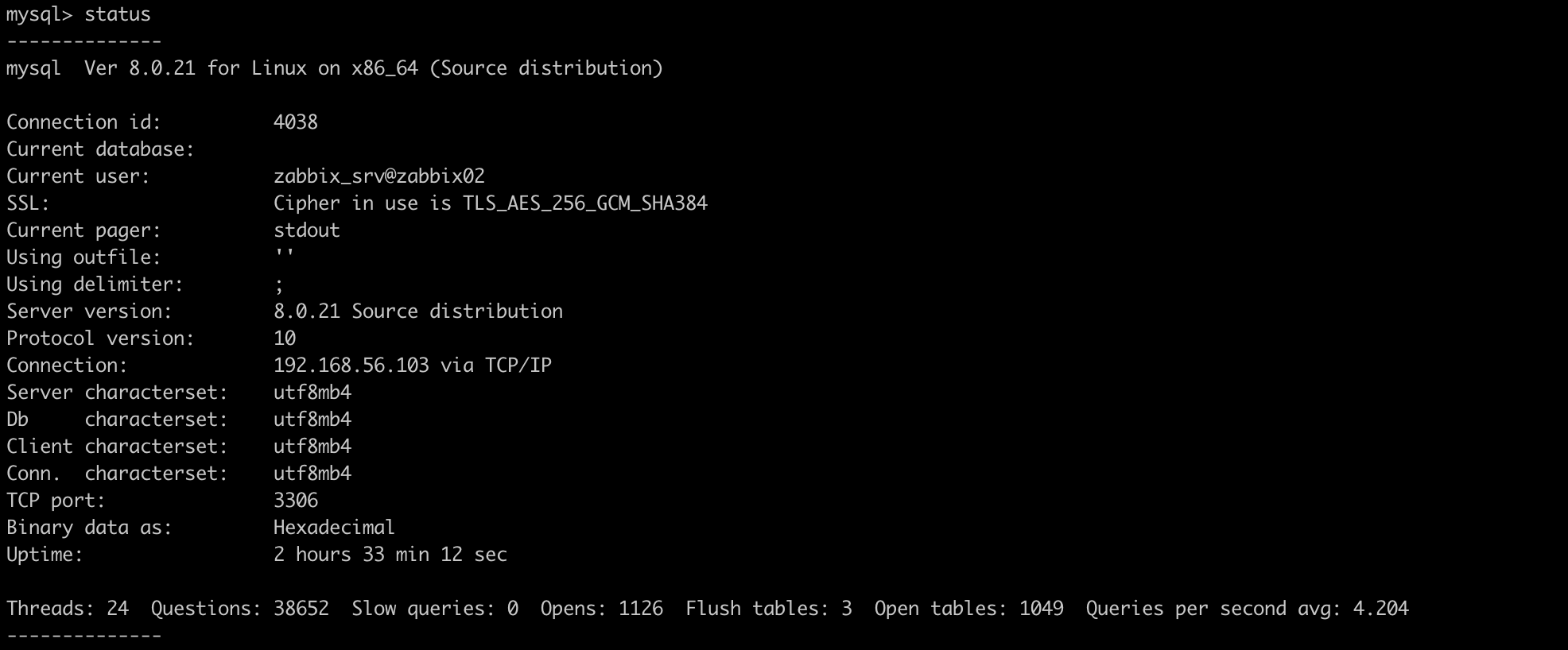
Вызов статуса вернет, в том числе, данные по настройкам шифрования. Убедимся, что в строке SSL указаны алгоритмы шифрования.
Настройку шифрования между Zabbix и базой данных можно выполнить сразу при первичной настройке Zabbix через web-интерфейс. Обратите внимание на подпись напротив Database TLS encryption. Из-за того, что для подключения к локальной БД используется socket file, нет возможности настроить шифрованное подключение. Поэтому в поле Хост базы данных должны быть указаны IP-адрес или имя сервера с БД.

Меняем localhost на IP-адрес сервера и появляется чекбокс.

На двух скриншотах выше можно увидеть нововведение в Zabbix версии 5.2 поддержку интеграции с хранилищем Vault. Перед началом настройки Zabbix мы создали пару ключей и учетными данными для подключения к БД.

Берем клиентские ключи MySQL, заполняем необходимые поля и нажимаем Далее.

Другой способ настроить то же самое соответствующие ключи в конфигурационном файле zabbix.conf.php.
$DB['ENCRYPTION'] = true;
$DB['KEY_FILE'] = '/etc/ssl/mysql/client-key.pem';
$DB['CERT_FILE'] = '/etc/ssl/mysql/client-cert.pem';
$DB['CA_FILE'] = '/etc/ssl/mysql/ca.pem';
$DB['VERIFY_HOST'] = true;
$DB['CIPHER_LIST'] = '';
Zabbix-сервер <-> База данных Zabbix
На предыдущем шаге мы уже создали пользователя для подключения, клиентские ключи для подключения тоже есть. Осталось прописать эти данные в конфигурационный файл Zabbix-сервера.
DBTLSConnect=required
DBTLSCAFile=/etc/ssl/mysql/ca.pem
DBTLSCertFile=/etc/ssl/mysql/client-key.pem
DBTLSKeyFile=/etc/ssl/mysql/client-cert.pem
DBTLSCipher=''
После выполненных настроек, необходима перезагрузка службы Zabbix-сервера. Логин и пароль для подключения Zabbix-сервера к БД мы также храним в Vault.

Использование Vault требует добавления значений к следующим переменным в конфигурации Zabbix-сервера:
VaultDBPath=kv/secret/zabbix
VaultToken=s.Ev50RnGXNM3FmmcVBMRrR4Nz
VaultURL=http://192.168.56.101:8200
Переменная VaultDBPath отвечает за хранение учетных данных для подключения к БД. Подробнее о шифровании подключений к БД можно узнать в документации Zabbix.
Zabbix-сервер <-> Zabbix-прокси
Как многие пользователи Zabbix знают, в системе существует два типа подключений для передачи метрик: пассивные и активные. Пассивные подразумевают запрос к источнику данных, а активные отправку данных от источника вне зависимости запроса приемника. Аналогичным образом, соединение между сервером и прокси могут быть пассивными или активными. На скриншоте ниже настроен активный прокси, соединение, с которым зашифровано по технологии PSK.

Обратите внимание, что исходящие соединения (пассивные) могут выполняться каким-то одним способом на выбор, а для входящих доступны комбинации вариантов: без шифрования, PSK или сертификат.
На стороне прокси все настройки выполняются в конфигурационном файле. Для активных проверок:
TLSConnect=psk
TLSPSKIdentity=test_zabbix
TLSPSKFile=/var/zabbix/agentd.psk
Для пассивных проверок:
TLSAccept=psk
TLSPSKIdentity=test_zabbix
TLSPSKFile=/var/zabbix/agentd.psk
Второй способ шифрования подключения использование сертификатов. Заметим, что для pre-shared key (PSK) и сертификатов, закрытый ключ хранится на файловой системе в открытом виде.
Подробная информация доступна в документации Zabbix.
Zabbix-сервер <-> Zabbix-агент и Zabbix-прокси <-> Zabbix-агент
Мы не будем повторяться, настройка этих соединений аналогична настройке соединения сервера с прокси: для исходящих соединений доступен один вариант, для входящих один или несколько.

Названия переменных для настройки шифрования на стороне агента полностью аналогичны переменным в конфигурации прокси.
Zabbix-прокси <-> БД Zabbix-прокси
Подход к настройке аналогичен настройке шифрованного соединения между Zabbix-сервером и БД. Названия переменных такие же, указываются в конфигурационном файле Zabbix-прокси.
Zabbix sender -> Zabbix-прокси и Zabbix-агент -> Zabbix get
Шифрование соединения с утилитами Zabbix sender и Zabbix get выполняется при помощи специальных параметров при вызове соответствующих утилит.
zabbix_sender -z 127.0.0.1 -s zabbix02 -k Encrypt -o 18 --tls-connect psk --tls-psk-identity test_zabbix --tls-psk-file /etc/zabbix/keys/agent.psk
zabbix_get -s 127.0.0.1 -k agent.version \
--tls-connect psk --tls-psk-identity test_zabbix --tls-psk-file /etc/zabbix/keys/agent.psk
Авторегистрация с шифрованием
Шифрование также поддерживается и для процесса авторегистрации.

После авторегистрации нового узла, настройки соединения с ним будут автоматически настроены на использование шифрования PSK.
Хранение чувствительной информации в Vault
Приятное нововведение, которое появилось в версии Zabbix 5.2 поддержка хранилища Vault. Его можно использовать как для хранения учетных данных для доступа к БД так и для значений макросов. Так значения макросов выглядят в Vault:

А так на них можно сослаться в интерфейсе Zabbix:

Хранение значений макросов очень сильно упрощает управление учетными данными для разных шаблонов, позволяет легко отзывать учетные данные и вести аудит. Разумеется, из Vault можно брать значения любых макросов и это добавляет ещё одну степень свободы при автоматизации мониторинга в Zabbix.
Заключение
В статье мы рассказали о возможностях шифрования в Zabbix. Перед решением об использовании шифрованных подключений, важно понимать, что это снижает производительность системы мониторинга и сильнее утилизирует аппаратное обеспечение. Без понятной причины шифрование использовать не стоит.
Мы давно и успешно работаем с Zabbix, если у вас есть задачи по развитию, сопровождению или обновлению системы, оставьте заявку через форму обратной связи или свяжитесь другим удобным способом.
А ещё можно почитать:
Добавляем CMDB и географическую карту к Zabbix
Мониторинг принтеров дело благородное
Структурированная система мониторинга на бесплатных решениях
Elastic под замком: включаем опции безопасности кластера Elasticsearch для доступа изнутри и снаружи
Для обработки событий от Zabbix, Prometheus, Elastic и других систем рекомендуем использовать Amixr (презентация по запросу).