Вячеслав
Смирнов Ускоряем Apache JMeter

Apache
JMeter не требует рекламы, но нечасто время уделяют скорости
работы самих нагрузочных скриптов. Вячеслав рассматривает подходы к
оптимальному написанию скриптов, что позволяет сэкономить на
нагрузочных машинах и позволяет по-новому посмотреть на JMeter.
Apache JMeter является популярным инструментом тестирования
производительности с большим количеством компонентов и
возможностей. Одни и те же операции в Apache JMeter можно выполнить
несколькими способами.
В проектах, где нужна высокая нагрузка, важным становится вопрос
производительности нагрузочного скрипта. И хорошо бы иметь рейтинг
производительности компонентов Apache JMeter и подходов к написанию
скриптов.
Пользуясь средствами профилирования Java-приложений, такими как
Java Flight Recorder, jVisualVM, SJK, имея доступ к исходным кодам
инструмента, написав синтетические тесты и взяв примеры из
практики, мы подготовили отчёт по тестированию производительности
инструмента для тестирования производительности.
Доклад будет интересен инженерам по тестированию
производительности, использующим Apache JMeter, как начинающим, так
и опытным, а также разработчикам, использующим JVM/JDK в работе и
занимающихся профилированием и оптимизацией кода.
Всем привет! Я сегодня расскажу, как ускорить Apache JMeter.

Немного о себе. Я бываю на конференциях в качестве докладчика, в
качестве слушателя. Был преподавателем в университете, вел курсы по
тестированию, писал статьи на Hubr. Это достоинства.

Но есть у меня и недостатки. Их много. Мне говорят, что я
достаточно неторопливый парень, но кое-что я умею делать
быстро.

Я ускоряю системы в банках и в других компаниях раньше это
делал. И часто это делал с помощью Apache JMeter. Сегодня мы
постараемся ускорять с его помощью не какие-то системы, а сам
Apache JMeter.

Что такое JMeter, думаю, вы знаете.
- Это один из известнейших и старейших продуктов на рынке. Он
известен с 2003-го года.
- Имеет плагины к более, чем к 50 системам, форматам, способам
подготовки и обработки результатов.
- Сохраняет статистику в ClickHouse, InfluxDB, Graphite. Многие
системы сбора статистики, которые вы видели, отображают это в
Grafana или в html-отчете.
- Также его удобно встраивать в системы CI/CD.
- Он имеет хорошую интеграцию с различными инструментами
разработки.
- И есть прекрасное сообщество.

Сегодня мы рассмотрим 5 основных тем. Это:
- HTTP-запросы. Как сделать отправку HTTP-запросов с максимальной
интенсивностью.
- Как скачивать и отправлять файлы большого размера. И при этом
мы столкнемся с какими-нибудь проблемами.
- Также PostProcessor на HTTP-ответы.
- PreProcessor.
- И расскажу об одном секретном оружие. Это секретное оружие
позволит ускорить вообще все.

Моя цель развеять миф, возможно, известный многим, о том, что
JMeter тормозит.

А я бы хотел, чтобы вы добились следующих своих целей:
- Укрепили свои знания о том, как разрабатывать тест таким
образом, чтобы система тормозила, а не тесты.
- Как делать так, чтобы запуски тестов были экономными, и вы
могли запускать тесты во множестве экземпляров много раз и
встраивать это в CI/CD-конвейер, где нужны практически непрерывные
запуски нагрузки.
- И разрабатывали тесты быстро и просто.

Начнем с самого первого, с HTTP Request максимальная
интенсивность.

Samplers.HTTP.Request.X. Простой тест. Несколько GET-запросов на
локальный сервер. Для этой проверки я написал простенький скрипт.
Назвал его Samplers.HTTP.Request.X. X означает, что он
параметризирован. В нем параметризировано все. Сам тест достаточно
простой. Давайте разберем из чего он состоит. Он отправляет
GET-запросы в цикле и все.

Запуск и остановка nginx в тесте, используя OS Process
Sampler
В начале теста и в конце теста я запускаю локальный
nginx-сервер. Использую для этого setup-катушку и tearDown-катушку,
в которой с помощью OS Process Sampler запускается nginx и в конце
останавливается.

Nginx с конфигурацией по умолчанию. Для скорости два процесса
вместо одного.

А сердцем теста является одна Thread Group и внутри нее HTTP
Request. Я в нем запараметризировал все: на какой сервер отправлять
запрос, какую страницу скачивать. И настройки по умолчанию такие,
как Use KeepAlive. Она важна, на нее обратим внимание позже.

В данном тесте будем делать короткие сценарии, например, открыть
стартовую страницу это один запрос. И будем делать сценарии на 10
запросов открыть стартовую страницу, ввести логин-пароль, или на
100, на 1000 запросов, используя здесь Loop Controller. В нем
передавая параметр RequestCount, я могу изменить длину сценария.
Таким образом мы сможем проверить, насколько быстро JMeter при
разной длине сценария будет работать.

А вверху у Thread Group параметры: сколько потоков это Threads,
сколько итераций это LoopCount.

Таким образом сделаем серию экспериментов, в которых будем
изменять параметры в трех направлениях:
- Количество потоков: 1, 2, 3.
- Длину сценария. Короткие сценарии на 1, 10, 50, 100
запросов.
- И будем включать-отключать Keep-Alive.
Посмотрим, как изменения этих трех параметров скажутся на
производительности.
Изменяя эти параметры, я провел достаточно много тестов. Давайте
посмотрим на них.

Если запустить тест только на одном потоке, то мы увидим
следующую картину. На тесте с одним запросом (короткий запрос
просто открыть страницу) мы видим среднюю интенсивность, которую
можно достичь. Это примерно 300-400 запросов в секунду.
Если мы увеличиваем длину сценария, допустим, до 10, то
интенсивность возрастает примерно до 4 000 и т. д. по
возрастающей.
Понятное дело, что с отключенным Keep-Alive такой опции нет, для
нее каждое соединение новое.

При увеличении количества потоков (два потока, три потока)
значения, конечно, растут.

Между двумя и тремя потоками в моем конкретном тесте разница
была небольшая.
На что стоит обратить внимание? Зачем я включал и отключал
Keep-Alive? Давайте сравним, какой он дает эффект.

Что происходит на тестах, которые состоят только из одного
запроса? Все benchmarks, которые я видел на JMeter, состояли как
раз из одного запроса. Там ребята брали разные инструменты и
добавляли туда ровно один запрос и сравнивали, как JMeter, который
выполняет один запрос в цикле, соотносится с другими инструментами,
которые делают то же самое.
JMeter, который выполняет только один запрос, не такой уж и
быстрый. Даже если просто отключить Keep-Alive он станет быстрее.
Мой тест это показывает.

Если сделать тест подлиннее, то включение или отключение
Keep-Alive уже практически не играет роли. Они примерно уже равны
по скорости.

И вся сила Keep-Alive раскрывается, когда тест достаточно
большой, т. е. в 50-100 запросов.

Полезный вывод для тех, кто занимается нагрузкой или пишет
benchmarks: Keep-Alive полезен. Он включен по умолчанию. Отключать
его не надо. Но вся его сила раскрывается, когда сценарий
достаточно длинный, хотя бы больше 10 запросов. Запомним это.

И запомним другой уже несколько негативный момент. Если вы
пишите benchmarks на JMeter или на других инструментах, то не
делайте их совсем простыми, т. е. из одного запроса. Они получаются
слишком короткими. И там происходит избыток соединений, которые
лишний раз не закрываются. Это нам снижает максимальную
интенсивность.

Самые основные сценарии у нас все-таки состоят не из одного
запроса и не из 100, а из чего-то среднего, например, из 10. Это
зайти, залогиниться, куда-то перейти, выйти. Примерно это на 10
запросов.
Мы видим, что наш сценарий на 10 запросов выдавал примерно от 4
000 до 5 000 операций в секунду. Но мы видим также, что у JMeter
есть достаточно большой потенциал.

Попробуем разогнать наш простой сценарий с 4 000 до 16 000
операций в секунду. А, возможно, даже превысим эти значения. Думаю,
у нас получится

Для этого нам понадобятся:
- Инструменты мониторинга. Я использовал Telegraf, InfluxDB,
Grafana.
- Некоторые инструменты, которые позволяют замониторить сетевую
подсистему. Для этого есть отличная утилита в Linux это Netstat и
другие консольные программы.
- Настройки сетевой подсистемы ядра находятся в удобном доступе
через файловую систему в Linux: /proc/sys/net/*.
- Документация.
- Профилировщики: SJK, Java Fligth Recorder.
- И настройки самого JMeter.
Изменяя все это, попробуем ускорить с 4 000 до 16 000 наш
тест.

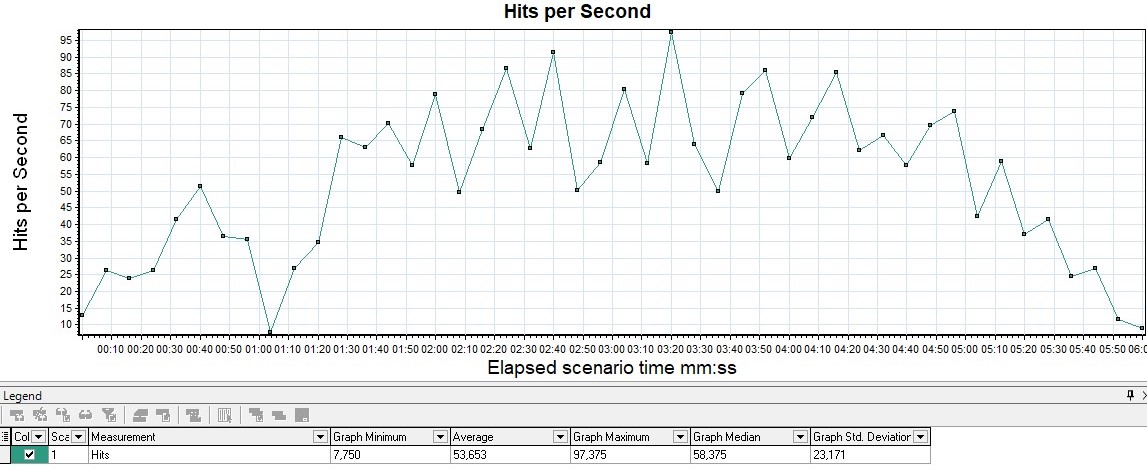
Для начала запустим наш эталонный тест на 10 запросов без
каких-либо изменений по новой. И замониторим не просто среднее
значение интенсивности, а как она выглядела на графике. Я
использовал JMeter Backend Listener. И это график из Grafana.
Я ожидал, что интенсивность будет стабильной, т. е. ровно 4
000-5 000. А она не стабильная, она скачет из нижней полки в 500
(на одном запросе) до верхней полочки в 16 000 (на 100 запросах).
Видим всплески.

Кроме того, есть ошибки. Например, Non HTTP response code. В
данном случае в Linux у меня выдается такая ошибка, как адрес
недоступен. В Windows могут быть другие ошибки: невозможно
установить соединение. Но у них одна и та же суть.
В данном случае я словил 5,24 % ошибок. И тест уже не совсем
успешный.

Если запрофилировать JMeter в этот момент с помощью SJK, то
профилирование показывает, что самый долгий метод, т. е. более 64 %
это socketConnect. Т. е. JMeter не занимается тем, что отправляет
запросы и получает ответы или что-то парсит, или что-то у него
внутри медленное. Он занимается тем, что ожидает, что ему дадут
новый сокет, чтобы подсоединиться к нашему локальному nginx. И на
это тратится большая часть времени работы.

Зная все это, попробуем как-то это ускорить. У нас есть три
пути, как у витязя на распутье. Какие это пути?

- Мы можем поменять сам скрипт, т. е. что-то изменить в
JMeter.
- Можем поменять настройки JMeter. Настроек достаточно много,
есть что поменять.
- И можем поменять настройки операционной системы, т. е. как-то
потюнить ядро, потюнить Linux, чтобы он работал быстрее.

Скрипт JMeter: увеличить количество запросов (RequestCount) до
50. Изменим сам скрипт.

Если вы помните, то я начал с того, что мы запускали тесты с
разной длиной сценария: 1, 10, 50, 100. И было видно, что когда
сценарий достаточно длинный (50 и 100), то нам выдавалось стабильно
16 000 или даже больше запросов в секунду.
Таким образом, если вы столкнулись с этими проблемами и хотите
ускорить, то способ ускорения тестов с помощью правки сценария это
сделать в нем больше запросов.
В данном случае мы решили ограничь длинной в 10 запросов и не
увеличивать, поэтому для нас увеличение это не самый лучший подход.
Попробуем какой-нибудь еще.

Может быть, HTTP Cache Manager ускорит работу? Сразу скажу, да,
он ускоряет, но у меня тут маленькая оговорка: я загружаю
достаточно простой html-документ. Он маленький.

И на маленьком документе, если добавить HTTP Cache Manager, то
эффект будет небольшой. Он будет практически незаметным.
Я получил ту же самую интенсивность в 4 800. И получил примерно
тот же самый процент ошибок, только чуть-чуть меньший.

JMeter по-прежнему с HTTP Cache Managerом большую часть времени
проводит на методе socketConnect. Т. е. мы ожидаем подключение к
нашему локальному nginx.

Таким образом в данном конкретном случае модификацией скрипта
разогнать тест не удалось, потому что мы решили не удлинять
сценарий. У нас по постановке задачи он 10. А HTTP Cache Manager на
маленьких ответах нам ничего не дал.

Откатим все изменения назад. Представим, что мы вернулись в
прошлое и никаких правок не было, HTTP Cache Manager не
добавлялся.

И попробуем какой-нибудь еще вариант. Покликаем настройки самого
JMeter.

Первую настройку, которую я решил выбрать, которую, возможно,
все видели, но никогда не меняли, это HttpClient4 на Java. По
умолчанию используется HttpClient4.
Если сменить реализацию java-клиента (в данном случае я
использовал 8-ую Java), то мы получим немалое ускорение в 3,3 раз и
не получим ни одной ошибки вообще. Т. е. это практически настройка
мечты. Можно ее, конечно, использовать с оговорками, потому что
JavaClient может не все то, что поддерживается в HttpClient4. Он
раскаченный специально для JMeter. Но если у вас простой HTTP, то
почему бы и нет?

В этот момент профилирование показывает, что JMeter уже занялся
делом. Большую часть времени он читает ответ. Какую-то часть
времени он уже отправляет запросы. Т. е. мы не висим на методе
socketConnect. Изменение этой настройки избавило нас от
проблемы.
Но откатимся снова в прошлое. Представим, что мы эту настройку
не меняли. Поищем какой-нибудь еще способ.

Есть еще одна настройка. Она позволяет отключить сброс состояния
между двумя итерациями, т. е. мы выполнили 10 запросов, и там
происходит сброс состояния. Мы закрываем все соединения, посылаем
TCP закройся, SSL переинициализируйся и начинаем все по новой.
Можно сказать false: не сбрасывай состояние, установил и
переиспользуй его.

Попробуем ее поменять. И, о чудо! Тест ускорился практически в 4
раза. В некоторых моментах я превысил даже полочку 20 000 в
секунду. И это имея лишь слабенький ноутбук с 4-мя ядрами и три
потока. Неплохо, но важно понимать, что эта настройка у нас
сократила все-таки некоторое количество соединений, которые мы
установили серверу, но она значительно ускорила интенсивность.

Резюмирую по этим двум настройкам. Если заменить реализацию
HttpClient4, то мы ускорились на 3,3 раза. А если сделать так,
чтобы использовался клиент по умолчанию, но не сбрасывал
соединение, то ускорение практически в 4 раза. Неплохой
результат.
Но снова откатимся назад. Представим, что мы эти настройки не
меняли. И попробуем что-то еще.

А у нас еще есть настройки операционной системы. И там большое
количество опций в сетевой подсистеме ядра, которые мы сейчас
попробуем задействовать, чтобы наши соединения быстрее возвращались
в JMeter, т. е. все было шустрее.

Для этого запускаем тест по новой, но включаем мониторинг всего,
что есть. Допустим, я замониторил nginx. Видим, что подключения к
nginx идут достаточно интенсивно, т. е. интенсивность подключения
скачет от 0 до 1 200-1 300-1 400. И в пике получается, что
максимальная планка подключений в секунду примерно в 10 раз меньше,
чем от интенсивности в тесте. Это логично. Мы делаем 10 запросов
подключение, 10 запросов подключение. Т. е. графики
коррелирует.

График утилизации процессора, где красная линия это системное
время, а синяя линия пользовательское время. А все остальные линии
это waits и что-то еще. И график показывает, что конфигурация по
умолчанию большую часть времени тратится как раз на системные
вызовы, а пользовательский код проигрывает в 3,5 раза.

Значит, обратим внимание на различные системные метрики. Прежде
всего на сетевые. И мониторинг метрик, который в Grafana, Telegraf
называется Netstat, в частности, метрика tcp_time_wati, показывает,
что с момента начала теста мы достаточно быстро доходим до полочки,
которая отчетливо вырисовывается в 28 231. Вот такое магическое
число. И держимся на этой полочке весь тест. Иногда лишь
прогибаясь, но потом возвращаясь. Т. е. что-то нас держит,
ограничивает значение tcp_time_wait этим числом.

Чтобы замониторить, кто подсоединяется к нашему локальному nginx
(я локальный nginx запускал на локальном порту 5555), используем
утилиту NetStat.
Она показывает, что там лишь одно соединение от JMeter к nginx
установлено, а все остальные находятся в состоянии TIME_WAIT. Т. е.
все эти 28 000 это JMeter установил соединение, потом итерация
закончилась, и он сказал: Соединение закройся. И теперь соединение
ожидает, когда nginx ему подтвердит: Да, я соглашаюсь, давай
закроемся, т. е. происходит некое согласование. Оно происходит не
мгновенно, поэтому какое-то время соединение в этом состоянии
висит.

Поиск по документации быстро нас выводит на опцию, которая
отвечает за количество соединений, которые мы можем открыть. Она
называется local_port_range. Ее значение по умолчанию в Ubuntu от
32 000 практически до 61 000.
И если из 61 000 вычислить 32 000, то мы получим наши 28
000.
Посмотреть эту настройку можно с помощью утилиты cat, выполнив
команду cat /название метрики, и нам выведется его значение по
умолчанию.

А чтобы изменить эту метрику можно воспользоваться командой
echo, вызвав ее с админскими правами.
Допустим, отодвинем левую границу в 32 000 еще левее и сделаем
наш диапазон несколько больше, т. е. в два раза: от 1 025 до 60
999. Совсем до нулей отодвигать не стал, потому что не знаю, к
каким последствиям это привело бы.
Очень мне помог
@blog.kireev.pro. Там очень хорошо описано, что такое
tcp_time_wait и почему это возникает, и что с этим делать.

Мы меняем настройку. Перезапускаем тест. И у нас есть ускорение
примерно в 1,6 раза. Теперь интенсивность скачет не от 500 до 16
000, а от 3 500 до 19 000. Это уже хорошо. Средняя составила 7
700.

Ошибки ушли, что немало важно. Практически победа.

Если посмотреть профилировщиком что же сейчас выполняет JMeter,
он по-прежнему висит на методе socketConnect.

Мы ускорились, избавились от ошибок Address not available за
счет опции ip_local_port_range.

Но мы лишь полечили симптомы, проблема осталась, мы все еще
висим на socketConnect. И если обратно вернуться на метрику
Netstat: tcp_time_wait, т. е. замониторить ее с помощью Telegraf,
посмотреть Grafana, то мы видим, что мы больше не упираемся в 28
000. Мы теперь упираемся в 32 768. Снова замечательное число,
думаю, знакомое айтишникам. И что-то нам подсказывает, что это
очередной лимит.

И, наверное, мы можем его найти. Такой лимит есть. И есть такая
опция tw_ buckets максимальное значение, максимальная длина очереди
TIME_WAIT.
Если снова выполнить команду cat, она подскажет, что в Ubuntu по
умолчанию значение как раз равно 32 768.

И мы его можем изменить, допустим, в два раза, записав туда
значение в 65 000. Давайте это сделаем.

Перезапустим тест, но увы, нагрузка осталась той же. Среднее
значение примерно то же. Она по-прежнему скачет от 3 500 до 19
000.

Какие плюсы? Tcp_time_wait упирался в полочку в 32 768, а теперь
он не упирается. Он вначале заскакивает на 46 000. И по ходу теста
плавает в более свободном интервале, т. е. полочки нет, но
разогнаться нам это не помогло.

Запомним этот момент. Это опыт. Если увеличить local_port_range,
а потом сверху, не откатываясь назад на машине времени еще
увеличить tw_buckets, то tw_buckets как-то не добавляет нам ничего
хорошего, но мы уходим от полочки. И это плюс.

Профилирование показывает, что с двумя настройками JMeter
по-прежнему висит на методе socketConnect, но уже меньшую долю
около 50 %. Будем искать настройки дальше.

И поиск по настройкам нас приводит к тому, что можно
переиспользовать TIME_WAIT-соединение. Для этого нужно записать 1 в
настройку tcp_tw_reuse. По умолчанию там 0.

Если это сделать, то интенсивность на данной машине без
каких-либо правок теста, без каких-либо опций увеличивается в 3,6
раза и достигает 19 000 иногда. Становится более стабильной.
Конечно, мы избавляемся от ошибок.

Профилирование показывает, что JMeter уже занялся делом. Он
делает socketRead, иногда socketWrite, т. е. делает осмысленные
действия. Теперь мы читаем заголовок ответа и тратим на это большую
часть времени.

Процессор задышал, мы не тратим большую часть времени в
системных вызовах, выполняется наш пользовательский код. Думаю,
JMeter заработал.

Но снова упираемся в подозрительную полочку по TIME_WAIT. Но на
данный момент мы уже выполнили все наши задачи. Если изначально
задача была побить планку в 16 000, то мы ее побили. Какая такая
есть настройка, которая нас ограничивает в 30 000, я не знаю, но
есть хорошее руководство у других инструментов по тестированию
производительности. Например, Gatling.

https://bit.ly/gatling-tuning
https://gatling.io/docs/current/general/operations/
Это можно найти в документации Gatling, в разделе General/
Operations. Там есть настройки по Java и тюнинговым операционным
системам.

Некоторые из них пересекаются с теми, которые я уже успел
использовать. Например, local_port_range.
Но эти настройки нужно использовать по одной и с осторожностью.
Почему? Например, некоторые настройки, рекомендации говорят, что в
5, 6 строчках мы увеличим максимальное количество файлов, которые
доступны на данной системе. Но по секрету скажу, что в операционной
системе Linux настройка nr_open по умолчанию равно миллиону. И если
бездумно выполнить рекомендацию, то мы ее не увеличим, а понизим до
300 000.
Вторая настройка file-max ровна 70 000 с лишним, и мы ее
понизим. Поэтому нужно внимательно смотреть на рекомендации, по
одной применять и тем или иным способом вы ускорите работу.

Там есть хорошая настройка tw_reuse = 1.

https://yandextank.readthedocs.io/en/develop/generator_tuning.html#tuning
И есть хорошая рекомендация от Yandex.Tank. Они тоже
пересекаются, их тоже нужно смотреть по одной, внимательно
читая.
Например, там есть некоторые старые настройки tw_recycle.
Tw_reuse рекомендуется выставить в ноль. Думаю, у разработчиков
Gatling были свои причины, чтобы сделать так. Возможно, эти две
настройки на другой версии ядра давали тот же самый эффект.
Смотрите настройки Yandex.Tank, Gatling, вы можете еще что-то
дополнительно затюнить, мы уже в эти подробности вдаваться не
будем.

Пока остановимся на том, что tw_reuse позволил нам в 3,6 раза
ускорить тест. И это здорово.

Если посмотреть на все настройки целиком, то что получилось?
- Если не сбрасывать состояние, а выставить значение reset_state
в false, то мы ускорились 3,9 раза.
- Если сменить Httpsampler на стандартную реализацию Java, то в
3,3 раза.
- А по настройкам Linux c tw_reuse в 3,6 раза при наличии всех
других настроек.
- И local_port_range в два раза нам все-таки ускорило тест.
Прошу обратить внимание на опции из других инструментов. Они нам
пригодятся.

Вы можете увидеть, что состояние нормальное у JMeter это не
когда он висит в методе в socketConnect. А когда он примерно треть
висит в read. 20 % он выставляет timeout это некие сервисные
функции. 11 % в BackendListener. И 12 % отправляет запросы. Вот это
состояние нормального и здорового JMeter.

Попробовать все эти настройки вы можете самостоятельно, можете
как-то их смешать. Думаю, у вас все получится.

А мы пока перейдем к следующей части. Это как скачивать файлы
большого размера в JMeter, во что мы упремся при этом и как мы это
ускорим.

Последовательное скачивание файла, используя Thread Group на
один поток и 200 итераций, имея 4 Гбайт Heap Size
Для этого теста я придумал такую задачу, что мы будем скачивать
200 гигабайт последовательно. Создается один поток и в нем 200 раз
скачивается гигабайт. И посмотрим, как JMeter справляется, и с
какими ограничениями мы столкнемся.
Файл точного размера 1 гигабайт. Я его создал с помощью утилиты
DD. Думаю, все ей доверяют.

Запускаем тест с настройками по умолчанию. И получаем неплохой
результат. 5 минут. Скорость загрузки каждого гигабайта достаточно
стабильна. В целом 1,5 секунды. Но мы употребили всю память,
которую я выделял по JMeter. Я выделял 4 гигабайта.

Если посмотреть с помощью Java Fligth Recorder, как
утилизируется память, то вот этот синий график показывает, что
память постоянно выделяется и очищается, т. е. сборок мусора за
время скачивания этих 200 гигабайт было неимоверное количество. А
средний memory traffic (метрика отображается в правом нижнем углу
данной вкладки) показывает, что мы примерно выделяли память со
скоростью 2 гигабайта в секунду. Т. е. JMeter скачивал 200 гигабайт
и каждую секунду выделял 2 гигабайта, а JFR их очищал. Думаю, был
большой overhead только на JFR.

Профилирование с помощью SJK показывало, что мы висели на
socketRead, т. е. читали, выделяли память, очищали.

Важно заметить следующую штуку. Если хоть чуть-чуть увеличить
размер файла, имея Heap в 4 ГБайта, допустим, я скачивал 1
гигабайт, а буду скачивать 1,1 гигабайт, то сразу получаю
OutOfMemoryError. Это соотношение важно запомнить. Я думаю, что
если скачивать 2 гигабайта, то мне нужно HEAP 8 гигабайт, т. е.
большой объем памяти нужно на нагрузочной станции, чтобы скачивать
большие документы с настройками по умолчанию.

Запомним этот опыт, как несколько негативный. Httpsampler с
настройками по умолчанию работает быстро, но требует гигантское
количество оперативной памяти.
И на этой неутешительной ноте, я думаю, что у нас есть три пути,
чтобы как-то это исправить.
Изменить скрипт, изменить настройки операционной системы или
изменить настройки JMeter.
Начнем с того, что изменим скрипт.

Документация по HTTP Request подсказывает нам, что есть такая
опция Save response as MD5 hash. Что она позволяет? Она позволяет
не сохранять все тело ответа, а превратить его в MD5 hash. И мы, я
думаю, сэкономим на памяти. Т. е. мы уже не будем хранить столько
всего.

Поставим ее, запустим тест. И, правда, мы память сэкономили.
Утилизация памяти стала равна нулю. Но мы несколько удлинили сам
процесс скачивания, т. е. аж до 18 минут. Среднее время теперь
составило 5,5 секунд на гигабайт.

Если запустить Java Flight Recorder, то он покажет, что мы
вообще не видим синюю линию. Т. е. память с начала теста чуть-чуть
выделилась и тут же ее сборщик мусора очистил ее все. Памяти
действительно ноль, ее нет.

Профилирование показывает, что MD5 занял 66 %, т. е. в два раза
больше, чем оставшуюся часть. 33 % socketRead. Таким образом, если
поставить галочку MD5, то мы замедляем наше скачивание ровно в три
раза. К нашему одному socketRead добавляется две части на MD5.

Запомним все-таки MD5 как компонент, который не врет. Там
написано, что он сокращает утилизацию памяти. Он ее сокращает до
нуля, но он замедляет скачивание до трех раз.
Откатим эту настройку назад, представим, что у нас снова
эталонный скрипт.

Мы скачиваем наши 200 гигабайт, но зададим себе следующую задачу
как скачать и быстро, и потратив немного памяти? Есть ли такой
способ в JMeter? Думаю, многие скачивали гигабайты с помощью
консольных утилит: wget, curl. И с помощью OS Process Sampler
консольные утилиты и скрипты можно легко встраивать в JMeter.
Давайте так и поступим.

Для этого я написал несложный скрипт. Это для Linux, который
использует wget. Назвал его wget-download.sh. В него передаются
параметр url. И он скачивает, отправляя весь результат в dev/null,
чтобы у меня на нагрузочной станции диск не переполнился. Если
проводить 2-3 итерации теста, то 400-600 гигабайт и все, станция
потеряна.

Тот же самый скрипт можно написать и для Windows. Wget с помощью
MinGW. Dev/null только в Windows выглядит иначе.

Кроме того, Wget может ограничить и скорость скачивания. Мы
можем притвориться, допустим, мобильным клиентом.

Это аналог опции characters per second, которая есть в JMeter,
но она там задает ограничение на весь JMeter в целом, а Wget мы
можем сказать, чтобы конкретный запрос скачивался медленно, а
другой запрос быстро, т. е. это несколько удобнее.

Кроме того, мы можем добавлять заголовки. Можем сказать, что мы
поддерживаем gzip.

И даже этот gzip можем разжимать с помощью gzip. Т. е. bash
утилиты дают нам полную свободу. Мы можем действовать как отличный
консольный клиент.

Но чтобы это выглядело в JMeter как родное, нужно
воспользоваться некоторой хитростью. Я ей воспользовался. Она
называется SampleResult. Есть программный доступ из PostProcessor,
который позволяет BodySize установить, content-type, все заголовки
заполнить.

И если им воспользоваться, то в JMeter будет видно все, что
выводит Wget в качестве body. Я не стал сохранять все тело
ответа.

И все заголовки. SampleRusult позволяет встраивать всякие
консольные штуки.

Запустим этот тест с wget. Он нам показывает на данный момент
победный результаты: 0 мегабайт утилизации памяти и всего лишь 2
минуты.

Таким образом, если смотреть на все три наших запуска, то:
- Стандартные настройки 5 минут,
- Включили галочку получили 18 минут,
- Использовали wget 2 минуты.

Запомним, что OS Process Sampler + JSR-223 с положительной
стороны. Они нам решили задачу, ускорили. По сравнению с MD5 даже
ускорили в 7 раз. Хорошая связка.
Откатим и эти настройки назад.
Попробуем теперь ускориться за счет настроек JMeter.

Есть такая настройка, которую будем считать секретной. Она в
документации особо не описана, но ее можно найти в JMeter
properties. Она ограничивает максимальное количество байт, которое
Sampler будет хранить из ответа. Ее значение по умолчанию 0. Это
означает, что если пришел гигабайт, я его скачал, то и гигабайт
буду хранить.
Выставим ее в 100, чтобы хранить только 100 байт.

Запустим тест. И это практически победа. Мы ускорились до 1
минуты. Съели не очень много памяти 180 мегабайт. А среднее время
было практически на протяжении всего теста стабильным и не
превышало 500 миллисекунд на файл.

Профилирование показывает ту же самую картину, что и раньше, т.
е. socketRead. С помощью профилирования нельзя будет выявить при
тесте с большим файлом какую же рекомендацию выбрать, они все
выглядят одинаково socketRead и все.

Но нужно знать, что MD5 hash замедляет тест. Можно уйти вообще в
консольные инструменты интеграции. И, допустим, с помощью wget
получить 2 минуты. Или использовать некий хак, например, скачать
гигабайт, но сохранить только часть этого гигабайта. И получить
самое максимальное ускорение. В данном тесте у нас опции JMeter
победили всех.

Вы можете попробовать их как-то смешать, но их особо не
смешаешь, они все слишком разные, потому что MD5 и так сжимает
тело. Wget вообще практически ничего не скачивает. А ограничение
времени ответа само по себе.
Итак, мы разобрали, как скачивать с максимальной интенсивностью
это первый момент.

Второй момент как скачивать большие файлы. И теперь давайте
разберем, как отправить большие файлы, но только быстро.

Я сразу скажу, что отправка больших файлов в JMeter достаточно
шустрая. Ее как-то особо тюнить не надо. Главное, воспользоваться
главной вкладкой. Она называется Files Upload. И эта вкладка
позволяет больше, чем видно на первый взгляд.

В ней есть неочевидный секретный вариант. Здесь, чтобы упростить
вам взаимодействие с непростым интерфейсом HTTP Request, я сделал
вот такую схему.
Обозначил способ задания параметра через Parameters. Этот способ
по умолчанию солнышко. Думаю, это любимый многими вариант.
Есть достаточно тяжелый вариант задания тела запроса с помощью
Body Data, где мы пишем большую строчку. Можем туда применить
функции и переменные. И мы его обозначим слоником. Он такой
тяжелый.
А шустрые и выносливые способы это Files Upload. Это лошадка. И
секретный единорог, если мы заполнили не все параметры, а только
один путь к файлу. Если мы заполнили только путь к файлу, то
загружается все тело запроса, а не один параметр.

И они комбинируются следующим образом. Parameters и Files Upload
комбинируются между собой.

А Files Upload (body data) и Body Data не комбинируются ни между
собой, ни с кем-либо еще. Вот это важно запомнить. Если вы
попробуете их как-то скомбинировать, то вам JMeter покажет ошибку,
так он не умеет.

Можно задавать как один параметр, при этом неважно, что будет
стоять в опции Use multipart/form-data. Если что-то заполнить, то
будет всегда form-data.

Можно заполнять несколько параметров.

Можно загружать тело запроса из файла целиком. И вроде бы все
замечательно, но главное не менять ни один параметр. Заполнить
только одно поле.

И если я захочу первый запрос отправить с текстом Маша, второй
Саша, а третий Петя, а у меня один файл? Что можно предложить?

Как готовить файлы большого объема, например, 10 гигабайт, если
вам нужна и скорость, и динамичность? Я использую следующий подход
в работе.

Допустим, мне нужно отправить 10 гигабайт файлов и это JSONs. Я
заранее готовлю эти JSONs. И оставляю там какой-нибудь якорь.
Допустим, номер счета или название организации. Это переменная.
Упаковываю это в архив. И перед отправкой использую следующую
штуку. Распаковываю архив и применяю утилиту Sed. Она работает
максимально быстро и это в 100 раз быстрее, чем если бы мы
компоновали 10 гигабайт строк или файлов с помощью Java или чего-то
еще. Мы все это сделали на диске, не тратя память.

Итог по отправке файлов: пользуйтесь вкладкой Files Upload, где
можно загружать не только параметры, но и тело целиком и
консольными инструментами.

Кратко пробежимся по ним. Когда мы уже получили ответ, мы можем
захотеть обработать. Как отличается скорость разных
PostProsserов?

Для этого теста я выбрал стартовую страницу JMeter. Будем
парсить из нее hint к этой стартовой картинке.

Тест на Boundary Extractor. Я его навесил на константный JRS223
Sampler, который ничего не делает, но загружаю не сайт Apache
JMeter, этот html-контент, а из переменной. Назвал ее html-контент.
И она вот здесь располагается в особом поле для переменных, т. е.
http-запроса нет. Чистое использование Extractor.

Такой тест есть для Boundary Extractor, регулярки.


JSR-223 PostProcessor, который повторяет Boundary Extractor.


BeanShell PostProcessor, который повторяет Boundary
Extractor.

Есть CSS Extractor.

И XPath Extractor в режиме tolerant parser. Особую галочку
ставишь, и тогда XPath может парсить и html.

Сравним их. Получаем следующие результаты довольно
предсказуемые.
Boundary, который просто ищет тест между правой и левой границей
всех победил с результатом более 55 000 запросов в секунду.
На втором месте с результатом в 50 000 запросов в секунду
регулярки.
Потом JSR223 и BeanShell. JSR223 быстрее, потому что он
компилированный.
Мой любимый CSS Selector проиграл.
А XPath проиграл совсем. XPath не используйте.

Общее влияние PostProcessorов небольшое
Я уже было расстроился, что CSS Selector проиграл, но он не
такой плохой. Если сравнить, как соотносится CSS Selector с некими
внутренними вещами в JMeter, допустим, с записью логов, то он всего
лишь в два раза дольше, чем запись логов. А запись логов мы не
отключаем, поэтому CSS Selector можно тоже использовать, но особо
там не накручивая по 200 CSS Selectors. 3-4 добавили и хватит.

Точно не надо использовать tolerant parser и XPath. Нужно
использовать регулярки и Boundary Extractor. Или CSS Selector, но
помня, что он имеет свою цену.
Попробуйте это. PostProcessors можно смешивать, друг на друга
накладывать в неограниченном количестве.

По PreProcessors совсем коротко.

В одном из тестов, где мне нужно было готовить тело запроса для
тела в виде XML для HTTP-запроса я использовал Groovy PreProcessor
и писал там, используя SimpleTemplateEngine, хорошую XML.
Выбор пал на SimpleTemplateEngine из всех возможностей
подготовки XML, потому что я попал в ментальную ловушку. Мне
показалось, что SimpleTemplateEngine простой, поэтому, наверное,
будет быстрым, а все другие называются XML.MarkupBuilder это сложно
и, наверное, они медленные.
Я так написал, как сумел ускорил. И жил себе не тужил. А потом
пришли ребята, мои коллеги, и просто переписали на
XML.MarkupBuilder, и весь тест ускорился в 5 раз. Все оптимизации
можно было выкинуть, потому что все залетало.
XML.MarkupBuilder просто волшебен. Он позволяет строить XML,
параметризируя все, что угодно, добавляя атрибуты динамические, в
цикле накидывать динамическое количество узлов в XML. И позволяет
задавать атрибуты этих подузлов с помощью переменных или тестовые
значения с помощью переменных. Groovy нам раскрывает широкие
возможности.
Единственный тут есть минус в том (он не самый важный), что в
Groove рекомендуется использовать одинарные кавычки для скорости.
Вот здесь в конце я использовал двойные, но это только одно
выполнение, большой роли это не сыграло.

Таким образом, если есть частая задача готовить XML в
PreProcessors, то обратите внимание на MarkupBuilder. И
документация на него на сайте Groovy хорошая. Он очень быстрый.
Позволяет сэкономить много времени.

Мы закончили 4 основные момента. И теперь я расскажу про
секретное оружие.
Секретное оружие позволяет:
- Разрабатывать скрипты на JMeter быстро,
- Быстро скачивать расширение библиотеки и не думать о
версиях,
- Быстро запускать профилирование тестов, подготавливать данную
презентацию. Я сделал, наверное, более 100 запусков. Подготовил 100
отчетов, запрофилировал все это, выбрал некоторые интересующие. Я
потратил на это не 10 лет жизни.
- И не терять ни одно изменение, потому что все будет гитоваться
на каждую станцию, у каждого нагрузочника будет одна и та же версия
вплоть до коммита.

Что это за секретное оружие? Это связка из трех богатырей:
Maven, jmeter-maven-plugin и IntelliJ IDEA. Они позволили за
последние два года ускорить мою работу раз в 10.
В чем их преимущество?

IntelliJ IDEA имеет колоссальное количество дополнений. И одно
из них касается JMeter. Оно позволяет подсвечивать синтаксис.
Какие есть фишки в IDEA? Там можно быстро искать текст, заменять
его, выполнять refactoring. Таким образом, если мы вдруг ошиблись с
названием переменной, например, html-content решили переименовать
просто в html, то мы быстро делаем refactoring. И он во всех
скриптах, во всех настройках меняется. Мы нигде и ничего не
забудем. Если кто-то выполнял refactoring в сложном JMeter-скрипте,
то знает, что это не просто.
И, кроме того, в IDEA хорошая интеграция с git. Она все
загитует.

Если нужно добавить плагин в JMeter, то как обычно мы это
делаем? Мы скачиваем плагин, кладем его в библиотеку. И потом
таскаем эту папочку с библиотечками и плагинами от станции к
станции, чтобы не потерять. Это плохой вариант.

Можно сделать более изящно и хранить с помощью
jmeter-maven-plugin только лишь название плагина, и он будет
скачиваться автоматически.
То же самое касается и любых библиотек. Их можно указывать явно
в разделе testPlanLibraries.

Либо можно еще сократить себе время и указывать только название
основной библиотеки, а для всех ее зависимостей сказать: Maven,
найди и скачай сам. И все скачается.

Кроме того, Maven за счет использования профилей и Properties
позволяет, не запуская JMeter, не меняя ничего в коде,
переопределить все, что угодно в скрипте.
Допустим, я менял количество итераций, сколько мне нужно скачать
файлов, сам путь к файлу, предварительно создавая этот файл тоже в
консоли. Т. е. пара кликов мышью и новый тест запущен.

Если мне захотелось бы запустить тест с большим размером кучи
Heap, то я бы добавил плюс еще один профиль, который бы мне
модифицировал размер Heap.

Если бы нужно было запустить профилирование, то еще одна
строчка, которая запускает SJK, и профилирование готово.

Java Flight Recorder то же самое. Здесь я реализовал через
профиль.

JVisual VM то же самое, тоже через профиль.

https://bit.ly/jmeter-bench
https://github.com/polarnik/Apache.JMeter.Benchmark.NG
Все эти примеры можно будет посмотреть в репозитории, который
сохранен на GitHub. Там более 20 скриптов ко всем плагинам со всеми
настройками. Есть подходы, как скомбинировать это в виде опций
jmeter-maven-plugin, как это все передавать. Есть там же и
документация.

Что я могу сказать, резюмируя все сказанное?
Мы пробовали менять следующие вещи:
- Скрипты. Они дают самый больший boost иногда.
- А также настройки JMeter.
- Настройки операционной системы дают меньший boost.
- А если вы просто хотите сделать вашу работу более итеративной,
более шустрой, то используйте связку из этих трех инструментов:
Maven, jmeter-maven-plugin, IntelliJ IDEA. И вы будете в единицу
времени выдавать больше скриптов, больше правок, будете более
спокойны.

Если хотите найти презентацию, то есть отличная группа: https://t.me/qa_load,
где примерно 300 специалистов по производительности пишут и
помогают друг другу. Заходите, присоединяйтесь, буду рад!
Вопросы
Спасибо за доклад! Может быть, глупый вопрос, возможно, был
ответ на одном из первых слайдов. Зачем надо было ускорять работу
JMeter? Одна из метрик это throughput, которую он выдает. И у вас
было недостаточно throughput, которыми вы нагружаете свои сервисы и
поэтому вы искали способ ускорить, нагрузить больше сервис или
какая-то причина была?
Спасибо за вопрос! Тут целый комплекс историй, они не на один
час. Но в общем и целом так: помогая ребятам в чатиках, просто при
личном общении, я слышал, что они жалуются на то, что JMeter
тормозит. Они спрашивали: Что делать?. При этом причины были самые
разные.
Некоторые причины касаются того, что человек просто не верно
сконфигурировал профиль нагрузки, т. е. сделал его недостижимым, но
хочет, чтобы у него было миллионов запросов в секунду.
Другие причины чисто технические, что как-то не так скомпоновано
и нужно изменить подход, изменить опции. С некоторыми причинами я
сталкивался сам.
Пока вы запускаете тесты разово, единично и не поставили это на
поток, вам особо не нужно заботиться о том, насколько они шустрые и
сколько ресурсов потребляют. Но как только вы захотели на каждый
build запускать нагрузочный тест, вам захочется, чтобы pool
нагрузочных станций был поменьше, чтобы ресурсов он требовал
поменьше. И не чтобы JMeter тормозил, а, чтобы тормозила
система.
И как можно заметить, в некоторых моментах вы можете получить
абсолютно разное время: 1,5 секунды на скачивание, 7 секунд, 5
секунд это же важно. В некоторых моментах хочется
минимально-минимальное время. И его можно достичь.
И из всех этих аспектов, а также из-за того, что некоторые
ребята говорят, что JMeter тормозит, я подготовил эти примеры и не
только их, чтобы была возможность самому разобраться.
Вы говорили про настройки операционной системы, что можно
это дело как-то ускорить. Это касалось только Linux?
Да, Linux.
А в Windows есть что-то подобное?
Если делать аналогичные опции в Windows, то их можно сделать
другим путем. Когда я пробовал сделать такое в Windows, то все мои
поиски заканчивались очередной статьей на форуме службы поддержки,
где говорилось, что это сделать нельзя.
Но что известно? Чем характеризуется соединение? Это IP-адрес
клиента, IP-адрес сервера и порты. Если мы не можем как-то
увеличить диапазон портов, настройки переиспользования, то мы,
возможно, сможем увеличить диапазон IP-адресов. Т. е. разделить наш
сервер, допустим, на два IP, чтобы мы отправляли запросы не в local
host 5555, а в local host и еще куда-то. Тогда наш диапазон
увеличится в два раза.
В старом JMeter еще была такая опция, когда мы могли привязать
текущий клиент к определенному IP. И мы могли расширять диапазон IP
на клиенте. Таким образом не залазить ни в одну настройку, а просто
говорить, что тест сейчас запускается с трех-четырех-пяти адресов.
В актуальной версии это удалили. Это как-то можно придумать
иначе.
Я уже с Windows, перешел на Linux. В некоторых моментах
приходится возвращаться к Windows, когда идет тестирование
скриптографии, но там не нужны большие интенсивности и какие-то
запредельные вещи.

 Source: W. Playfair.
Source: W. Playfair.
 Рис. 1. TSS
Рис. 1. TSS  Рис. 2. Декомпозиция TSS
Рис. 2. Декомпозиция TSS Рис. 3. Коррелограмма TSS
Рис. 3. Коррелограмма TSS

 Рис. 4. Гистограмма Fk, линейный масштаб
Рис. 4. Гистограмма Fk, линейный масштаб Рис. 5. Гистограмма Fk, логарифмический масштаб
Рис. 5. Гистограмма Fk, логарифмический масштаб
 Рис. 6.
Коробчатая диаграмма Fk
Рис. 6.
Коробчатая диаграмма Fk

 Рис. 7. TSE
Рис. 7. TSE
 Рис. 8. Декомпозиция TSE
Рис. 8. Декомпозиция TSE
 Рис. 9. Коррелограмма TSE
Рис. 9. Коррелограмма TSE





















































 Flame-график бенчмарка заполнения
непредаллоцированного ArrayList
Flame-график бенчмарка заполнения
непредаллоцированного ArrayList

 Import Project to IntelliJ
Import Project to IntelliJ
 Select build.gradle file
Select build.gradle file
 Open Sample Simluation
Open Sample Simluation
 Setup Scala SDK
Setup Scala SDK
 Choose Scala SDK
Choose Scala SDK

 Download Gatling
Download Gatling
 Choose
Gatling Simulation to run
Choose
Gatling Simulation to run

 Gatling
Recorder screenshot
Gatling
Recorder screenshot
 Choose Gatling Version
Choose Gatling Version
 Import
IntelliJ Gatling project
Import
IntelliJ Gatling project
 Import
Scala SDK in IntelliJ
Import
Scala SDK in IntelliJ
 Scala versions in IntelliJ
Scala versions in IntelliJ
 Download Scala in Intelli
Download Scala in Intelli
 Download Scala binaries from Scala-lang
Download Scala binaries from Scala-lang
 Add
the Scala binaries to IntelliJ
Add
the Scala binaries to IntelliJ
 Select the Lib folder to import Scala Binaries
Select the Lib folder to import Scala Binaries
 Add Scala Support
Add Scala Support
 Mark Test Sources as Root in IntelliJ
Mark Test Sources as Root in IntelliJ
 Mark Sources Root
Mark Sources Root
 Run
the Engine Object in IntelliJ
Run
the Engine Object in IntelliJ