
Один из наших читателей обратил наше внимание на Espressif IoT
Development Framework. Он нашёл ошибку в коде проекта и
поинтересовался, смог бы её найти статический анализатор
PVS-Studio. Именно эту ошибку анализатор пока найти не может, зато
нашёл множество других. По мотивам этой истории и найденных ошибок,
мы решили написать классическую статью про проверку открытого
проекта. Приятного изучения того, из-за чего IoT устройства могут
"выстрелить вам в ногу".
Программно-аппаратные
системы
Отец языка C++ Бьярне Страуструп как-то сказал:
"Си" позволяет очень просто выстрелить себе в ногу. На
"Си++" сделать это сложнее, но, когда вы это делаете, отрывает всю
ногу.
В нашем случае, заявление начинает приобретать несколько иной
смысл. Из идеи, что программист может ошибиться и программа будет
функционировать как-то неправильно, мы подходим к ситуациям, когда
это может причинять реальный физический вред.
Такие проекты, как Espressif IoT Development Framework, служат
для реализации программно-аппаратных систем, взаимодействующих с
человеком и управляющие объектами в реальном мире. Всё это
накладывает дополнительные требования к качеству и надёжности
программного кода. Именно отсюда берут основы такие стандарты как
MISRA
или AUTOSAR.
Впрочем, это уже другая тема.
Вернёмся к
Espressif IoT Development Framework (исходный код на сайте
GitHub: esp-idf).
Вот его краткое описание:
ESP-IDF is Espressif's official IoT Development
Framework for the ESP32 and ESP32-S series of SoCs. It provides a
self-sufficient SDK for any generic application development on
these platforms, using programming languages such as C and C++.
ESP-IDF currently powers millions of devices in the field, and
enables building a variety of network-connected products, ranging
from simple light bulbs and toys to big appliances and industrial
devices.
Думаю, читателям интересно посмотреть, уделяется ли
разработчиками этого проекта достаточно внимания к качеству и
надёжности. К сожалению, такой уверенности, нет. Познакомившись со
статьей и описанием замеченных дефектов, вы поймете мои опасения.
Итак, заваривайте чай/кофе, вас ждёт много текста и кода.
Предыстория
Ещё хочется рассказать, как появилась эта статья. Мне написал
Юрий Попов (Hardcore IoT fullstack dev & CTO), который с
интересом следит за нашими публикациями. Незадолго до этого он
самостоятельно вручную нашёл ошибку в Espressif IoT Development
Framework и поинтересовался, может ли выявить этот дефект
PVS-Studio. Ошибка связана с опечаткой коде, а PVS-Studio всегда
славился тем, что хорошо выявляет подобные ошибки.
Некорректный код находился в файле
mdns.c:
mdns_txt_linked_item_t * txt = service->txt;while (txt) { data_len += 2 + strlen(service->txt->key) + strlen(service->txt->value); txt = txt->next;}
Происходит обход списка и определённым образом должны
суммироваться длины строк, на которые ссылаются различные объекты,
хранящиеся в списке. Вот только всё время считается длина строк,
хранящаяся в первом объекте.
Правильный код:
data_len += 2 + strlen(txt->key) + strlen(txt->value);
К обоюдному разочарованию меня и читателя Юры, PVS-Studio не
смог заметить эту ошибку. Он просто не знает про такой паттерн
ошибки. Собственно, и наша команда не знала про такой паттерн.
PVS-Studio, как и любой другой анализатор, умеет замечать только
то, на что его запрограммировали :).
Что ж, жаль, но не страшно. Это один из источников, где можно
черпать идеи по развитию PVS-Studio. Пользователи и клиенты
присылают различные паттерны ошибок, которые они выявили в коде
своих проектов, но про которые не знает PVS-Studio. И мы постепенно
создаём новые диагностические правила. Так произойдёт и с
рассмотренным выше паттерном. Мы уже выписали этот пример в TODO и
реализуем новое диагностическое правило для выявления схожих
ситуаций в одной из следующих версий анализатора.
По итогам всего этого, Юра сам написал небольшую заметку про эту
ошибку, как он её искал и про PVS-Studio: "Баг в ESP-IDF: MDNS,
Wireshark и при чём тут единороги". Плюс он уведомил авторов
проекта о найденной ошибке:
Spurious MDNS collision detection (IDFGH-4263).
На этом история не закончилось. Юра предложил нашей команде
проверить проект и написать заметку о результатах. Мы не стали
отказываться, так как весьма часто делаем подобные
публикации для популяризации методологии статического анализа
кода и заодно инструмента PVS-Studio :).
Правда проверку мы повели достаточно неуклюже. К сожалению, нет
примера "собрать всё". Ну или мы не разобрались. Мы начали с
getting_started\hello_world. Вроде бы он использует часть
фреймворка, но не полностью. Так что можно найти и другие ошибки,
добившись компиляции большего количества файлов фреймворка. Другими
словами, то, что в статье будет описана только 71 ошибка, это наша
недоработка :).
Надо понимать, что у меня не было задачи найти как можно больше
ошибок. Поэтому, когда я бегло пробежался по неполному отчёту, я
сразу понял, что материала и так более чем достаточно для статьи.
Поэтому я поленился углубляться дальнейшее изучение проекта.
К счастью, у Юрия Попова, который заварил всю эту кашу, гораздо
больше энтузиазма, чем у меня. Он сообщил, что смог добиться более
полной компиляции фреймворка и проверил гораздо больше файлов. И,
очень вероятно, вслед за моей статьей, выйдет его статья, где он
рассмотрит дополнительную порцию ошибок.
Примеры, откуда берутся ложные/бессмысленные срабатывания
Всех исследователей, которые захотят проверить Espressif IoT
Development Framework, я хочу предупредить, что понадобится
предварительная настройка анализатора. Без неё вы утоните в большом
количестве ложных/бесполезных срабатываний. Но анализатор не
виноват.
В коде проекта очень активно используются директивы условной
компиляции (#ifdef) и макросы. Такой стиль кодирования запутывает
анализатор и порождает множество однотипных бесполезных
предупреждений. Чтобы было понятнее, как и почему это происходит,
рассмотрим пару примеров.
Предупреждение PVS-Studio: V547 Expression 'ret != 0' is always
true. esp_hidd.c 45
esp_err_t esp_hidd_dev_init(....){ esp_err_t ret = ESP_OK; .... switch (transport) {#if CONFIG_GATTS_ENABLE case ESP_HID_TRANSPORT_BLE: ret = esp_ble_hidd_dev_init(dev, config, callback); break;#endif /* CONFIG_GATTS_ENABLE */ default: ret = ESP_FAIL; break; } if (ret != ESP_OK) { free(dev); return ret; } ....}
Выбран такой режим компиляции, при котором макрос
CONFIG_GATTS_ENABLE не объявлен. Поэтому, для анализатора
этот код выглядит так:
esp_err_t ret = ESP_OK;....switch (transport) {default: ret = ESP_FAIL; break;}if (ret != ESP_OK) {
Анализатор вроде прав, что условие всегда истинно. С другой
стороны, пользы от этого предупреждения нет, так как мы понимаем,
что код совершенно корректен и имеет смысл. Подобные ситуации
встречаются крайне часто, что затрудняет просмотр отчёта. Это такая
неприятная плата за активное использование условной компиляции
:).
Рассмотрим другой пример. В коде активно используется своя
разновидность assert-макросов. К сожалению, они тоже сбивают
анализатор с толку. Предупреждение PVS-Studio: V547 Expression
'sntp_pcb != NULL' is always true. sntp.c 664
#define LWIP_PLATFORM_ASSERT(x) do \ {printf("Assertion \"%s\" failed at line %d in %s\n", \ x, __LINE__, __FILE__); fflush(NULL); abort();} while(0)#ifndef LWIP_NOASSERT#define LWIP_ASSERT(message, assertion) do { if (!(assertion)) { \ LWIP_PLATFORM_ASSERT(message); }} while(0)#else /* LWIP_NOASSERT */#define LWIP_ASSERT(message, assertion)#endif /* LWIP_NOASSERT */sntp_pcb = udp_new_ip_type(IPADDR_TYPE_ANY);LWIP_ASSERT("Failed to allocate udp pcb for sntp client", sntp_pcb != NULL);if (sntp_pcb != NULL) {
Анализатор видит, что код в которой раскрывается
LWIP_ASSERT остановит выполнение программы (см. вызов
функции abort), если указатель sntp_pcb будет
нулевой. Поэтому PVS-Studio предупреждает, что следующая проверка
(sntp_pcb != NULL) не имеет смысла.
С одной стороны, анализатор прав. Но всё поменяется, если макрос
в другом режиме компиляции будет раскрыт в "ничто". В этом случае
проверка уже будет иметь смысл. Да, при втором сценарии анализатор
ругаться не будет, но сути это уже не меняет. В первом то случае у
нас лишнее предупреждение.
Впрочем, всё это не страшно. Если взяться за проект всерьез, то
можно настроить анализатор так, что большинство бессмысленных
сообщений исчезнет. Ещё в ряде мест можно улучшить ситуацию,
изменив стиль написания кода и макросов. Но это уже выходит за
рамки данной статьи. Дополнительно можно использовать механизм
подавления предупреждений в конкретных местах, в макросах и т.д.
Есть ещё и механизм массовой разметки. Про всё это подробнее можно
почитать в статье "Как
внедрить статический анализатор кода в legacy проект и не
демотивировать команду".
Security
Начнём с предупреждений, которые, на мой взгляд, связаны с темой
security. Разработчики операционных систем, фреймворков и других
подобных проектов, должны с особенным вниманием относиться к поиску
слабостей кода, которые потенциально могут приводить к
возникновению уязвимостей.
Для удобства классификации слабостей кода можно использовать
CWE
(Common Weakness Enumeration). В PVS-Studio можно включить
отображение CWE ID для предупреждений. Для предупреждений этой
главы я дополнительно приведу соответствующий CWE ID.
Подробнее тема поиска потенциальных уязвимостей раскрыта в
статье "Статический
анализатор кода PVS-Studio как защита от уязвимостей нулевого
дня".
Ошибка N1; Порядок
аргументов
Предупреждение PVS-Studio: V764 Possible incorrect order of
arguments passed to
'crypto_generichash_blake2b__init_salt_personal' function: 'salt'
and 'personal'. blake2b-ref.c 457
int blake2b_init_salt_personal(blake2b_state *S, const uint8_t outlen, const void *personal, const void *salt);intblake2b_salt_personal(uint8_t *out, const void *in, const void *key, const uint8_t outlen, const uint64_t inlen, uint8_t keylen, const void *salt, const void *personal){ .... if (blake2b_init_salt_personal(S, outlen, salt, personal) < 0) abort(); ....}
При вызове функции blake2b_init_salt_personal
перепутаны местами аргументы personal и salt. Мне
кажется, вряд ли это задумано специально и, скорее всего, это
ошибка, возникшая по невнимательности. Я не ориентируюсь в коде
проекта и в криптографии, но что-то мне подсказывает, что такая
путаница может иметь нехорошие последствия.
Согласно CWE эта ошибка классифицируется как
CWE-683: Function Call With Incorrect Order of Arguments.
Ошибка N2;
Отбрасывание значащих бит
Предупреждение PVS-Studio: V642 Saving the 'memcmp' function
result inside the 'unsigned char' type variable is inappropriate.
The significant bits could be lost breaking the program's logic.
mbc_tcp_master.c 387
static esp_err_t mbc_tcp_master_set_request( char* name, mb_param_mode_t mode, mb_param_request_t* request, mb_parameter_descriptor_t* reg_data){ .... // Compare the name of parameter with parameter key from table uint8_t comp_result = memcmp((const char*)name, (const char*)reg_ptr->param_key, (size_t)param_key_len); if (comp_result == 0) { ....}
Сохранять результат работы функции memcmp в
однобайтовую переменную это очень плохо. Это дефект, который вполне
может превратиться в реальную уязвимость, подобную этой: CVE-2012-2122.
Подробнее, почему так писать нельзя, описано в документации к
диагностике V642.
Если совсем кратко, то некоторые реализации функция
memset могут возвращать в случае несовпадения блоков
памяти не только значения 1 или -1. Функция, например, может
вернуть значение 1024. А это число, записанное в переменную типа
uint8_t превратится в 0.
Согласно CWE эта ошибка классифицируется как
CWE-197: Numeric Truncation Error.
Ошибка N3 N20; Приватные данные остаются в памяти
Предупреждение PVS-Studio: V597 The compiler could delete the
'memset' function call, which is used to flush 'prk' buffer. The
memset_s() function should be used to erase the private data. dpp.c
854
#ifndef os_memset#define os_memset(s, c, n) memset(s, c, n)#endifstatic int dpp_derive_k1(const u8 *Mx, size_t Mx_len, u8 *k1, unsigned int hash_len){ u8 salt[DPP_MAX_HASH_LEN], prk[DPP_MAX_HASH_LEN]; const char *info = "first intermediate key"; int res; /* k1 = HKDF(<>, "first intermediate key", M.x) */ /* HKDF-Extract(<>, M.x) */ os_memset(salt, 0, hash_len); if (dpp_hmac(hash_len, salt, hash_len, Mx, Mx_len, prk) < 0) return -1; wpa_hexdump_key(MSG_DEBUG, "DPP: PRK = HKDF-Extract(<>, IKM=M.x)", prk, hash_len); /* HKDF-Expand(PRK, info, L) */ res = dpp_hkdf_expand(hash_len, prk, hash_len, info, k1, hash_len); os_memset(prk, 0, hash_len); // <= if (res < 0) return -1; wpa_hexdump_key(MSG_DEBUG, "DPP: k1 = HKDF-Expand(PRK, info, L)", k1, hash_len); return 0;}
Очень распространённая ошибка. Компилятор вправе в целях
оптимизации удалить вызов функции memset, так как после
заполнения буфера нулями, он больше не используется. В результате
приватные данные на самом деле не затираются, а продолжат болтаться
где-то в памяти. Подробности можно узнать в статье "Безопасная
очистка приватных данных".
Согласно CWE эта ошибка классифицируется как
CWE-14: Compiler Removal of Code to Clear Buffers.
Другие ошибки этого типа:
- V597 The compiler could delete the 'memset' function call,
which is used to flush 'prk' buffer. The memset_s() function should
be used to erase the private data. dpp.c 883
- V597 The compiler could delete the 'memset' function call,
which is used to flush 'prk' buffer. The memset_s() function should
be used to erase the private data. dpp.c 942
- V597 The compiler could delete the 'memset' function call,
which is used to flush 'psk' buffer. The memset_s() function should
be used to erase the private data. dpp.c 3939
- V597 The compiler could delete the 'memset' function call,
which is used to flush 'prk' buffer. The memset_s() function should
be used to erase the private data. dpp.c 5729
- V597 The compiler could delete the 'memset' function call,
which is used to flush 'Nx' buffer. The memset_s() function should
be used to erase the private data. dpp.c 5934
- V597 The compiler could delete the 'memset' function call,
which is used to flush 'val' buffer. The memset_s() function should
be used to erase the private data. sae.c 155
- V597 The compiler could delete the 'memset' function call,
which is used to flush 'keyseed' buffer. The memset_s() function
should be used to erase the private data. sae.c 834
- V597 The compiler could delete the 'memset' function call,
which is used to flush 'keys' buffer. The memset_s() function
should be used to erase the private data. sae.c 838
- V597 The compiler could delete the 'memset' function call,
which is used to flush 'pkey' buffer. The memset_s() function
should be used to erase the private data. des-internal.c 422
- V597 The compiler could delete the 'memset' function call,
which is used to flush 'ek' buffer. The memset_s() function should
be used to erase the private data. des-internal.c 423
- V597 The compiler could delete the 'memset' function call,
which is used to flush 'finalcount' buffer. The memset_s() function
should be used to erase the private data. sha1-internal.c 358
- V597 The compiler could delete the 'memset' function call,
which is used to flush 'A_MD5' buffer. The memset_s() function
should be used to erase the private data. sha1-tlsprf.c 95
- V597 The compiler could delete the 'memset' function call,
which is used to flush 'P_MD5' buffer. The memset_s() function
should be used to erase the private data. sha1-tlsprf.c 96
- V597 The compiler could delete the 'memset' function call,
which is used to flush 'A_SHA1' buffer. The memset_s() function
should be used to erase the private data. sha1-tlsprf.c 97
- V597 The compiler could delete the 'memset' function call,
which is used to flush 'P_SHA1' buffer. The memset_s() function
should be used to erase the private data. sha1-tlsprf.c 98
- V597 The compiler could delete the 'memset' function call,
which is used to flush 'T' buffer. The memset_s() function should
be used to erase the private data. sha256-kdf.c 85
- V597 The compiler could delete the 'memset' function call,
which is used to flush 'hash' buffer. The memset_s() function
should be used to erase the private data. sha256-prf.c 105
Ошибка N21; Не удаляется буфер с приватными данными
Предупреждение PVS-Studio: V575 The null pointer is passed into
'free' function. Inspect the first argument. sae.c 1185
static int sae_parse_password_identifier(struct sae_data *sae, const u8 *pos, const u8 *end){ wpa_hexdump(MSG_DEBUG, "SAE: Possible elements at the end of the frame", pos, end - pos); if (!sae_is_password_id_elem(pos, end)) { if (sae->tmp->pw_id) { wpa_printf(MSG_DEBUG, "SAE: No Password Identifier included, but expected one (%s)", sae->tmp->pw_id); return WLAN_STATUS_UNKNOWN_PASSWORD_IDENTIFIER; } os_free(sae->tmp->pw_id); sae->tmp->pw_id = NULL; return WLAN_STATUS_SUCCESS; /* No Password Identifier */ } ....}
Если с паролем что-то не так и указатель pw_id не
нулевой, то выводится отладочное предупреждение и функция завершает
свою работу. Что интересно, далее происходит попытка освободить
буфер, используя нулевой указатель. Более того, в нулевой указатель
вновь записывается NULL. Всё это не имеет смысла. Скорее
всего, строчки освобождения памяти находятся не на своём месте. И
мне кажется, код должен быть таким:
if (!sae_is_password_id_elem(pos, end)) { if (sae->tmp->pw_id) { wpa_printf(MSG_DEBUG, "SAE: No Password Identifier included, but expected one (%s)", sae->tmp->pw_id); os_free(sae->tmp->pw_id); sae->tmp->pw_id = NULL; return WLAN_STATUS_UNKNOWN_PASSWORD_IDENTIFIER; } return WLAN_STATUS_SUCCESS; /* No Password Identifier */}
Во-первых, наверное, это устранит утечку памяти. Во-вторых,
приватные данные перестанут где-то зря храниться длительное время в
памяти.
Согласно CWE, эта формально ошибка классифицируется как
CWE-628: Function Call with Incorrectly Specified Arguments.
Так её классифицирует PVS-Studio, но, по сути и последствиям, это
какая-то другая слабость кода.
Ошибка N22, N23; Использование неинициализированного буфера в
качестве ключа
Предупреждение PVS-Studio: V614 Uninitialized buffer 'hex' used.
Consider checking the second actual argument of the 'memcpy'
function. wps_registrar.c 1657
int wps_build_cred(struct wps_data *wps, struct wpabuf *msg){ .... } else if (wps->use_psk_key && wps->wps->psk_set) { char hex[65]; wpa_printf(MSG_DEBUG, "WPS: Use PSK format for Network Key"); os_memcpy(wps->cred.key, hex, 32 * 2); wps->cred.key_len = 32 * 2; } else if (wps->wps->network_key) { ....}
Неинициализированный буфер hex используется для
инициализации какого-то ключа. Зачем так сделано непонятно.
Возможно, это попытка заполнить ключ какими-то случайным значением,
но всё равно это очень плохой способ.
В любом случае этот код нуждается во внимательной проверке.
Согласно CWE, эта ошибка классифицируется как
CWE-457: Use of Uninitialized Variable.
Аналогичная ошибка: V614 Uninitialized buffer 'hex' used.
Consider checking the second actual argument of the 'memcpy'
function. wps_registrar.c 1678
Опечатки и Copy-Paste
Ошибка N24;
Copy-Paste классический
Предупреждение PVS-Studio: V523 The 'then' statement is
equivalent to the 'else' statement. timer.c 292
esp_err_t timer_isr_register(....){ .... if ((intr_alloc_flags & ESP_INTR_FLAG_EDGE) == 0) { intr_source = ETS_TG1_T0_LEVEL_INTR_SOURCE + timer_num; } else { intr_source = ETS_TG1_T0_LEVEL_INTR_SOURCE + timer_num; } ....}
Есть подозрение, что строчку скопировали, но забыли что-то в ней
изменить. В результате, независимо от условия, в переменную
intr_source записывается одно и тоже значение.
Примечание. Бывает конечно, что так и задумано. Например, если
пока, значения действительно должны совпадать (т.е. это
"todo-код"). Но тогда такой код явно стоит снабдить поясняющим
комментарием.
Ошибка N25; Не там
поставлена скобка
Предупреждение PVS-Studio: V593 Consider reviewing the
expression of the 'A = B != C' kind. The expression is calculated
as following: 'A = (B != C)'. esp_tls_mbedtls.c 446
esp_err_t set_client_config(....){ .... if ((ret = mbedtls_ssl_conf_alpn_protocols(&tls->conf, cfg->alpn_protos) != 0)) { ESP_LOGE(TAG, "mbedtls_ssl_conf_alpn_protocols returned -0x%x", -ret); ESP_INT_EVENT_TRACKER_CAPTURE(tls->error_handle, ERR_TYPE_MBEDTLS, -ret); return ESP_ERR_MBEDTLS_SSL_CONF_ALPN_PROTOCOLS_FAILED; } ....}
Приоритет
оператора сравнения выше, чем приоритет оператора присваивания.
Поэтому условие вычисляется следующим образом:
TEMP = mbedtls_ssl_conf_alpn_protocols(....) != 0;if ((ret = TEMP)) PRINT(...., -ret);
В принципе, ошибочная ситуация поймается и обработается в коде,
но не так, как задумано. Предполагалось распечатывать статус
ошибки, который хранится в переменной ret. Но значение
ret всегда будет равно 0 или 1. Поэтому, если что-то
пойдёт не так, всегда будет распечатываться только одно значение
(-1).
Ошибка возникла из-за того, что не там поставлена скобочка.
Правильный код:
if ((ret = mbedtls_ssl_conf_alpn_protocols(&tls->conf, cfg->alpn_protos)) != 0)
Теперь всё будет вычисляться как нужно:
ret = mbedtls_ssl_conf_alpn_protocols(....);if (ret != 0) PRINT(...., -ret);
Рассмотрим ещё один очень похожий случай.
Ошибка N26;
MP_MEM превращается в MP_YES
V593 Consider reviewing the expression of the 'A = B != C' kind.
The expression is calculated as following: 'A = (B != C)'.
libtommath.h 1660
В начале рассмотрим некоторые константы. Они пригодятся нам чуть
ниже.
#define MP_OKAY 0 /* ok result */#define MP_MEM -2 /* out of mem */#define MP_VAL -3 /* invalid input */#define MP_YES 1 /* yes response */
Далее следует сказать, что существует функция
mp_init_multi, которая может возвращать значения
MP_OKAY и MP_MEM:
static int mp_init_multi(mp_int *mp, ...);
И теперь собственно код с ошибкой:
static intmp_div(mp_int * a, mp_int * b, mp_int * c, mp_int * d){ .... /* init our temps */ if ((res = mp_init_multi(&ta, &tb, &tq, &q, NULL) != MP_OKAY)) { return res; } ....}
Рассмотрим проверку более тщательно:
if ((res = mp_init_multi(....) != MP_OKAY))
Вновь не там поставлена скобка. Поэтому в начале
вычисляется:
TEMP = (mp_init_multi(....) != MP_OKAY);
Значение TEMP может быть только 0 или 1. Этим числам
соответствуют константы MB_OKAY и MP_YES.
Далее выполняется присваивание и одновременно проверка:
if ((res = TEMP)) return res;
Видите подвох? Статус ошибки MP_MEM (-2) вдруг
превратился в статус MB_YES (1). Последствия предсказать
не могу, но ничего хорошего в этом нет.
Ошибка N27; Забыли
разыменовать указатель
Предупреждение PVS-Studio: V595 The 'outbuf' pointer was
utilized before it was verified against nullptr. Check lines: 374,
381. protocomm.c 374
static int protocomm_version_handler(uint32_t session_id, const uint8_t *inbuf, ssize_t inlen, uint8_t **outbuf, ssize_t *outlen, void *priv_data){ protocomm_t *pc = (protocomm_t *) priv_data; if (!pc->ver) { *outlen = 0; *outbuf = NULL; // <= return ESP_OK; } /* Output is a non null terminated string with length specified */ *outlen = strlen(pc->ver); *outbuf = malloc(*outlen); // <= if (outbuf == NULL) { // <= ESP_LOGE(TAG, "Failed to allocate memory for version response"); return ESP_ERR_NO_MEM; } memcpy(*outbuf, pc->ver, *outlen); return ESP_OK;}
Сообщение анализатора, на первый взгляд, может показаться
непонятным. Давайте разбираться.
Если указатель pc->ver является нулевым, то функция
досрочно завершает свою работу и при этом записывает значение по
адресу, хранящегося в указателе outbuf:
*outbuf = NULL;
Запись по этому адресу происходит и далее:
*outbuf = malloc(*outlen);
А не нравится анализатору то, что затем этот указатель
проверяется:
if (outbuf == NULL)
Действительно, это неправильно, в начале разыменовывать
указатель, а только потом его проверять. Ляп в том, что на самом то
деле должны были проверять не сам указатель, а то, что в него
записали. Здесь просто в проверке опечатались и пропустили оператор
разыменования (*).
Правильный код:
*outbuf = malloc(*outlen);if (*outbuf == NULL) { ESP_LOGE(TAG, "Failed to allocate memory for version response"); return ESP_ERR_NO_MEM;}
Ошибка N28; Повторное
присваивание
Предупреждение PVS-Studio: V519 The 'usRegCount' variable is
assigned values twice successively. Perhaps this is a mistake.
Check lines: 186, 187. mbfuncholding.c 187
eMBExceptioneMBFuncReadHoldingRegister( UCHAR * pucFrame, USHORT * usLen ){ .... USHORT usRegCount; .... usRegCount = ( USHORT )( pucFrame[MB_PDU_FUNC_READ_REGCNT_OFF] << 8 ); usRegCount = ( USHORT )( pucFrame[MB_PDU_FUNC_READ_REGCNT_OFF + 1] ); ....}
Код явно писался методом Copy-Paste. Строчку скопировали, но
изменили только частично. По соседству есть вот такой осмысленный
код:
usRegCount = ( USHORT )( pucFrame[MB_PDU_FUNC_WRITE_MUL_REGCNT_OFF] << 8 );usRegCount |= ( USHORT )( pucFrame[MB_PDU_FUNC_WRITE_MUL_REGCNT_OFF + 1] );
Видимо, и в рассмотренном коде с ошибкой, следовало в первой
строке использовать оператор =, а во второй оператор |=.
Логические ошибки
Ошибка N29 N31; Неправильная работа с кодами возврата (Rare)
Предупреждение PVS-Studio: V547 Expression is always false.
linenoise.c 256
static int getColumns(void) { .... /* Restore position. */ if (cols > start) { char seq[32]; snprintf(seq,32,"\x1b[%dD",cols-start); if (fwrite(seq, 1, strlen(seq), stdout) == -1) { /* Can't recover... */ } flushWrite(); } ....}
Это безобидный вариант неправильной обработки статуса,
возвращаемого функцией. Ошибка безобидна в том смысле, что никакой
обработки и не предусмотрено. Не получилось записать строчку, так
не получилось :). Хотя, как я уже сказал, этот безобидный вариант,
такой стиль написания программ явно не является образцом для
подражания.
Суть же самой ошибки в том, что функция fwrite не
возвращает статус -1. Это физически невозможно, так как функция
fwrite возвращает значение целочисленного типа
size_t:
size_t fwrite( const void *restrict buffer, size_t size, size_t count, FILE *restrict stream );
А вот что возвращает эта функция:
The number of objects written successfully, which may
be less than count if an error occurs.
If size or count is zero, fwrite returns zero and performs no other
action.
Таким образом, проверка статуса является неверной.
Аналогичные места безобидной неправильной проверки статуса:
- V547 Expression is always false. linenoise.c 481
- V547 Expression is always false. linenoise.c 569
Ошибка N32, N33; Неправильная работа с кодами возврата
(Medium)
Предупреждение PVS-Studio: V547 Expression is always false.
linenoise.c 596
int linenoiseEditInsert(struct linenoiseState *l, char c) { .... if (fwrite(&c,1,1,stdout) == -1) return -1; ....}
Хотя перед нами та же ошибка, что и в предыдущем случае, она
более серьезна. Если не удаётся записать символ в файл, то функция
linenoiseEditInsert должна прекратить свою работу и
вернуть статус -1. Но этого не произойдёт, так как fwrite
никогда не вернёт значение -1. Перед нами логическая ошибка
обработки ситуации, когда не удаётся что-то записать в файл.
Аналогичную ошибку можно найти здесь: V547 Expression is always
false. linenoise.c 742.
Ошибка N34; Неправильная работа с кодами возврата (Well Done)
Предупреждение PVS-Studio: V547 Expression is always false.
linenoise.c 828
static int linenoiseEdit(char *buf, size_t buflen, const char *prompt) .... while(1) { .... if (fread(seq+2, 1, 1, stdin) == -1) break; .... } ....}
Ошибка в том, что, как и в случае с fwrite, функция
fread
не возвращает в качестве статуса значение -1.
size_t fread( void *restrict buffer, size_t size, size_t count, FILE *restrict stream );
Return value
Number of objects read successfully, which may be less than count
if an error or end-of-file condition occurs.
If size or count is zero, fread returns zero and performs no other
action.
fread does not distinguish between end-of-file and error, and
callers must use feof and ferror to determine which
occurred.
Этот код ещё более опасный. Ошибка чтения из файла не
отлавливается, и программа продолжает работать с данными, случайно
имеющимися в этот момент в буфере данных. Т.е. программа всегда
считает, что она успешно прочитала из файла очередной байт, хотя
это может быть и не так.
Ошибка N35; Использование оператора || там, где нужен оператор
&&
Предупреждение PVS-Studio: V547 Expression is always true.
essl_sdio.c 209
esp_err_t essl_sdio_init(void *arg, uint32_t wait_ms){ .... // Set block sizes for functions 1 to given value (default value = 512). if (ctx->block_size > 0 || ctx->block_size <= 2048) { bs = ctx->block_size; } else { bs = 512; } ....}
Эту ошибку можно, конечно, отнести просто к опечаткам, но, мне
кажется, по духу она ближе к логическим ошибкам. Думаю, читатель
понимает, что деление ошибок по категориям часто является
достаточным условным.
Итак, перед нами всегда истинное условие. Ведь некая переменная
всегда или больше 0 или меньше 2048. Из-за этого размер какого-то
блока не будет ограничен значением 512.
Правильный вариант кода:
if (ctx->block_size > 0 && ctx->block_size <= 2048) { bs = ctx->block_size;} else { bs = 512;}
Ошибка N35
N38; Переменная не изменяется
Предупреждение PVS-Studio: V547 Expression 'depth <= 0' is
always false. panic_handler.c 169
static void print_backtrace(const void *f, int core){ XtExcFrame *frame = (XtExcFrame *) f; int depth = 100; // <= //Initialize stk_frame with first frame of stack esp_backtrace_frame_t stk_frame = {.pc = frame->pc, .sp = frame->a1, .next_pc = frame->a0}; panic_print_str("\r\nBacktrace:"); print_backtrace_entry(esp_cpu_process_stack_pc(stk_frame.pc), stk_frame.sp); //Check if first frame is valid bool corrupted = !(esp_stack_ptr_is_sane(stk_frame.sp) && (esp_ptr_executable((void *)esp_cpu_process_stack_pc(stk_frame.pc)) || /* Ignore the first corrupted PC in case of InstrFetchProhibited */ frame->exccause == EXCCAUSE_INSTR_PROHIBITED)); //Account for stack frame that's already printed uint32_t i = ((depth <= 0) ? INT32_MAX : depth) - 1; // <= ....}
Переменной depth присваивается значение 100, и до
момента проверки этой переменной её значение нигде не изменяется.
Это весьма подозрительно. Где-то что-то забыли сделать?
Аналогичные случаи:
- V547 Expression 'xAlreadyYielded == ((BaseType_t) 0)' is always
true. event_groups.c 260
- V547 Expression 'xAlreadyYielded == ((BaseType_t) 0)' is always
true. tasks.c 1475
- V547 Expression 'xAlreadyYielded == ((BaseType_t) 0)' is always
true. tasks.c 1520
Ошибка N39; Использование неинициализированного буфера
Предупреждение PVS-Studio: V614 Potentially uninitialized buffer
'k' used. Consider checking the second actual argument of the
'sae_derive_keys' function. sae.c 854
int sae_process_commit(struct sae_data *sae){ u8 k[SAE_MAX_PRIME_LEN]; if (sae->tmp == NULL || (sae->tmp->ec && sae_derive_k_ecc(sae, k) < 0) || (sae->tmp->dh && sae_derive_k_ffc(sae, k) < 0) || sae_derive_keys(sae, k) < 0) return ESP_FAIL; return ESP_OK;}
Ошибка в логике. Предположим, что указатели ec и
dh являются нулевыми. В этом случае массив k не
инициализируется, но функция sae_derive_keys всё равно
начнёт его обрабатывать.
Ошибка N40; Всегда
ложное условие
Предупреждение PVS-Studio: V547 Expression 'bit_len == 32' is
always false. spi_flash_ll.h 371
static inline void spi_flash_ll_set_usr_address(spi_dev_t *dev, uint32_t addr, int bit_len){ // The blank region should be all ones if (bit_len >= 32) { dev->addr = addr; dev->slv_wr_status = UINT32_MAX; } else { uint32_t padding_ones = (bit_len == 32? 0 : UINT32_MAX >> bit_len); dev->addr = (addr << (32 - bit_len)) | padding_ones; }}
Как легко увидеть, условие bit_len == 32 всегда даст
ложный результат. Возможно, выше следовало написать не
больше-или-равно (>=), а просто больше (>).
Ошибка N41; Повторное
присваивание
Предупреждение PVS-Studio: V519 The '* pad_num' variable is
assigned values twice successively. Perhaps this is a mistake.
Check lines: 46, 48. touch_sensor_hal.c 48
void touch_hal_get_wakeup_status(touch_pad_t *pad_num){ uint32_t touch_mask = 0; touch_ll_read_trigger_status_mask(&touch_mask); if (touch_mask == 0) { *pad_num = -1; } *pad_num = (touch_pad_t)(__builtin_ffs(touch_mask) - 1);}
Код явно ошибочен и возможно здесь не хватает оператора
else. Я не уверен, но, возможно, код должен выглядеть
так:
void touch_hal_get_wakeup_status(touch_pad_t *pad_num){ uint32_t touch_mask = 0; touch_ll_read_trigger_status_mask(&touch_mask); if (touch_mask == 0) { *pad_num = -1; } else { *pad_num = (touch_pad_t)(__builtin_ffs(touch_mask) - 1); }}
Выход за границу массива
Ошибка N42;
Неправильная граничная проверка
Предупреждение PVS-Studio: V557 Array overrun is possible. The
value of 'frame->exccause' index could reach 16.
gdbstub_xtensa.c 132
int esp_gdbstub_get_signal(const esp_gdbstub_frame_t *frame){ const char exccause_to_signal[] = {4, 31, 11, 11, 2, 6, 8, 0, 6, 7, 0, 0, 7, 7, 7, 7}; if (frame->exccause > sizeof(exccause_to_signal)) { return 11; } return (int) exccause_to_signal[frame->exccause];}
Возможен выход за границу массива на 1 элемент. Для правильной
проверки следует использовать не оператор больше, а
больше-или-равно:
if (frame->exccause >= sizeof(exccause_to_signal)) {
Ошибка N43; Длинный
пример ошибки :)
В рассматриваемой функции выход за границу массива может
произойти в двух местах, поэтому и предупреждений анализатора сразу
два:
- V557 Array overrun is possible. The value of 'other_if' index
could reach 3. mdns.c 2206
- V557 Array overrun is possible. The '_mdns_announce_pcb'
function processes value '[0..3]'. Inspect the first argument.
Check lines: 1674, 2213. mdns.c 1674
Приготовьтесь, это будет сложный случай. Для начала взглянем на
следующие именованные константы:
typedef enum mdns_if_internal { MDNS_IF_STA = 0, MDNS_IF_AP = 1, MDNS_IF_ETH = 2, MDNS_IF_MAX} mdns_if_t;
Обратите внимание, что значение константы MDNS_IF_MAX
равно 3.
Теперь взглянем на определение структуры mdns_server_s.
Здесь нам важно, что массив interfaces состоит из 3
элементов:
typedef struct mdns_server_s { struct { mdns_pcb_t pcbs[MDNS_IP_PROTOCOL_MAX]; } interfaces[MDNS_IF_MAX]; const char * hostname; const char * instance; mdns_srv_item_t * services; SemaphoreHandle_t lock; QueueHandle_t action_queue; mdns_tx_packet_t * tx_queue_head; mdns_search_once_t * search_once; esp_timer_handle_t timer_handle;} mdns_server_t;mdns_server_t * _mdns_server = NULL;
Это ещё не всё. Нам понадобится заглянуть внутрь функции
_mdns_get_other_if. Обратите внимание, что она может
вернуть константу MDNS_IF_MAX. Т.е. она может вернуть
значение 3.
static mdns_if_t _mdns_get_other_if (mdns_if_t tcpip_if){ if (tcpip_if == MDNS_IF_STA) { return MDNS_IF_ETH; } else if (tcpip_if == MDNS_IF_ETH) { return MDNS_IF_STA; } return MDNS_IF_MAX;}
И вот, наконец, мы добрались до ошибок:
static void _mdns_dup_interface(mdns_if_t tcpip_if){ uint8_t i; mdns_if_t other_if = _mdns_get_other_if (tcpip_if); for (i=0; i<MDNS_IP_PROTOCOL_MAX; i++) { if (_mdns_server->interfaces[other_if].pcbs[i].pcb) { // <= //stop this interface and mark as dup if (_mdns_server->interfaces[tcpip_if].pcbs[i].pcb) { _mdns_clear_pcb_tx_queue_head(tcpip_if, i); _mdns_pcb_deinit(tcpip_if, i); } _mdns_server->interfaces[tcpip_if].pcbs[i].state = PCB_DUP; _mdns_announce_pcb(other_if, i, NULL, 0, true); // <= } }}
Итак, мы знаем, что функция _mdns_get_other_if может
вернуть тройку. Значит переменная other_if может быть
равна трём. И вот первый потенциальный выход за границу
массива:
if (_mdns_server->interfaces[other_if].pcbs[i].pcb)
Второе место, где опасно используется переменная other_if,
- это вызов функции _mdns_announce_pcb:
_mdns_announce_pcb(other_if, i, NULL, 0, true);
Заглянем в эту функцию:
static void _mdns_announce_pcb(mdns_if_t tcpip_if, mdns_ip_protocol_t ip_protocol, mdns_srv_item_t ** services, size_t len, bool include_ip){ mdns_pcb_t * _pcb = &_mdns_server->interfaces[tcpip_if].pcbs[ip_protocol]; ....}
Опять может использоваться индекс 3 для доступа к массиву,
состоящего из 3 элементов. А максимальный доступный индекс это
двойка.
Нулевые указатели
Ошибка N44 N47; Ошибка очерёдности проверки указателей
Предупреждение PVS-Studio: V595 The 'hapd->wpa_auth' pointer
was utilized before it was verified against nullptr. Check lines:
106, 113. esp_hostap.c 106
bool hostap_deinit(void *data){ struct hostapd_data *hapd = (struct hostapd_data *)data; if (hapd == NULL) { return true; } if (hapd->wpa_auth->wpa_ie != NULL) { os_free(hapd->wpa_auth->wpa_ie); } if (hapd->wpa_auth->group != NULL) { os_free(hapd->wpa_auth->group); } if (hapd->wpa_auth != NULL) { os_free(hapd->wpa_auth); } ....}
Неправильная последовательность проверки указателей:
if (hapd->wpa_auth->group != NULL)....if (hapd->wpa_auth != NULL)
Если указатель hapd->wpa_auth окажется нулевым, то
всё плохо. Последовательность действий нужно поменять местами и
сделать вложенной:
if (hapd->wpa_auth != NULL){ .... if (hapd->wpa_auth->group != NULL) ....}
Аналогичные ошибки:
- V595 The 'hapd->conf' pointer was utilized before it was
verified against nullptr. Check lines: 118, 125. esp_hostap.c
118
- V595 The 'sm' pointer was utilized before it was verified
against nullptr. Check lines: 1637, 1647. esp_wps.c 1637
- V595 The 'sm' pointer was utilized before it was verified
against nullptr. Check lines: 1693, 1703. esp_wps.c 1693
Ошибка N48 N64; Нет проверки указателя после выделения памяти
В целом, в проекте принято проверять, удалось выделить память
или нет. Т.е. много кода с подобными проверками:
dhcp_data = (struct dhcp *)malloc(sizeof(struct dhcp));if (dhcp_data == NULL) { return ESP_ERR_NO_MEM;}
Но местами про проверки забыли.
Предупреждение PVS-Studio: V522 There might be dereferencing of
a potential null pointer 'exp'. Check lines: 3470, 3469.
argtable3.c 3470
TRex *trex_compile(const TRexChar *pattern,const TRexChar **error,int flags){ TRex *exp = (TRex *)malloc(sizeof(TRex)); exp->_eol = exp->_bol = NULL; exp->_p = pattern; ....}
Этот вид ошибки сложнее и опаснее, чем может показаться на
первый взгляд. Подробнее эта тема разбирается в статье "Почему
важно проверять, что вернула функция malloc".
Другие места, где отсутствуют проверки:
- V522 There might be dereferencing of a potential null pointer
's_ledc_fade_rec[speed_mode][channel]'. Check lines: 668, 667.
ledc.c 668
- V522 There might be dereferencing of a potential null pointer
'environ'. Check lines: 108, 107. syscall_table.c 108
- V522 There might be dereferencing of a potential null pointer
'it'. Check lines: 150, 149. partition.c 150
- V522 There might be dereferencing of a potential null pointer
'eth'. Check lines: 167, 159. wpa_auth.c 167
- V522 There might be dereferencing of a potential null pointer
'pt'. Check lines: 222, 219. crypto_mbedtls-ec.c 222
- V522 There might be dereferencing of a potential null pointer
'attr'. Check lines: 88, 73. wps.c 88
- V575 The potential null pointer is passed into 'memcpy'
function. Inspect the first argument. Check lines: 725, 724.
coap_mbedtls.c 725
- V575 The potential null pointer is passed into 'memset'
function. Inspect the first argument. Check lines: 3504, 3503.
argtable3.c 3504
- V575 The potential null pointer is passed into 'memcpy'
function. Inspect the first argument. Check lines: 496, 495.
mqtt_client.c 496
- V575 The potential null pointer is passed into 'strcpy'
function. Inspect the first argument. Check lines: 451, 450.
transport_ws.c 451
- V769 The 'buffer' pointer in the 'buffer + n' expression could
be nullptr. In such case, resulting value will be senseless and it
should not be used. Check lines: 186, 181. cbortojson.c 186
- V769 The 'buffer' pointer in the 'buffer + len' expression
could be nullptr. In such case, resulting value will be senseless
and it should not be used. Check lines: 212, 207. cbortojson.c
212
- V769 The 'out' pointer in the 'out ++' expression could be
nullptr. In such case, resulting value will be senseless and it
should not be used. Check lines: 233, 207. cbortojson.c 233
- V769 The 'parser->m_bufferPtr' pointer in the expression
equals nullptr. The resulting value of arithmetic operations on
this pointer is senseless and it should not be used. xmlparse.c
2090
- V769 The 'signature' pointer in the 'signature +
curve->prime_len' expression could be nullptr. In such case,
resulting value will be senseless and it should not be used. Check
lines: 4112, 4110. dpp.c 4112
- V769 The 'key' pointer in the 'key + 16' expression could be
nullptr. In such case, resulting value will be senseless and it
should not be used. Check lines: 634, 628. eap_mschapv2.c 634
Ошибка N65, N66; Нет проверки указателя после выделения памяти
(показательный случай)
Следующий код содержит точно такую же ошибку, как мы
рассматривали выше, но она более показательная и яркая. Обратите
внимания, что для выделения памяти используется функция
realloc.
Предупреждение PVS-Studio: V701 realloc() possible leak: when
realloc() fails in allocating memory, original pointer
'exp->_nodes' is lost. Consider assigning realloc() to a
temporary pointer. argtable3.c 3008
static int trex_newnode(TRex *exp, TRexNodeType type){ TRexNode n; int newid; n.type = type; n.next = n.right = n.left = -1; if(type == OP_EXPR) n.right = exp->_nsubexpr++; if(exp->_nallocated < (exp->_nsize + 1)) { exp->_nallocated *= 2; exp->_nodes = (TRexNode *)realloc(exp->_nodes, exp->_nallocated * sizeof(TRexNode)); } exp->_nodes[exp->_nsize++] = n; // NOLINT(clang-analyzer-unix.Malloc) newid = exp->_nsize - 1; return (int)newid;}
Во-первых, если функция realloc вернёт NULL,
то будет потеряно предыдущее значение указателя
exp->_nodes. Возникнет утечка памяти.
Во-вторых, если функция realloc вернёт NULL,
то запись значения произойдёт вовсе не по нулевому указателю.
Имеется в виду эта строка:
exp->_nodes[exp->_nsize++] = n;
Значение exp->_nsize++ может быть любым, и, если
запись произойдёт в какую-то случайную область памяти, доступную
для записи, то программа продолжит своё выполнение, как ни в чём не
бывало. При этом будут разрушены структуры данных, что приведёт к
непредсказуемым последствиям.
Ещё одна такая ошибка: V701 realloc() possible leak: when
realloc() fails in allocating memory, original pointer
'm_context->pki_sni_entry_list' is lost. Consider assigning
realloc() to a temporary pointer. coap_mbedtls.c 737
Прочие ошибки
Ошибка N67; Лишний
или неверный код
Предупреждение PVS-Studio: V547 Expression 'ret != 0' is always
false. sdio_slave.c 394
esp_err_t sdio_slave_start(void){ .... critical_exit_recv(); ret = ESP_OK; if (ret != ESP_OK) return ret; sdio_slave_hal_set_ioready(context.hal, true); return ESP_OK;}
Это странный код, который можно сократить до:
esp_err_t sdio_slave_start(void){ .... critical_exit_recv(); sdio_slave_hal_set_ioready(context.hal, true); return ESP_OK;}
Есть здесь ошибка или нет, мне сказать сложно. Возможно, здесь
написано совсем не то, что задумано. А возможно, этот код появился
в процессе неудачного рефакторинга и, на самом деле, является
корректным. В этом случае его действительно достаточно немного
упростить, чтобы он смотрелся красивей и понятней. Одно точно этот
код заслуживает внимания и проверки автором.
Ошибка N68; Лишний
или неверный код
Предупреждение PVS-Studio: V547 Expression 'err != 0' is always
false. sdio_slave_hal.c 96
static esp_err_t sdio_ringbuf_send(....){ uint8_t* get_ptr = ....; esp_err_t err = ESP_OK; if (copy_callback) { (*copy_callback)(get_ptr, arg); } if (err != ESP_OK) return err; buf->write_ptr = get_ptr; return ESP_OK;}
В общем-то, всё то же самое, что и в предыдущем случае.
Переменная err является лишней или её забыли изменить.
Ошибка N69; Использование потенциально неинициализированного
буфера
Предупреждение PVS-Studio: V614 Potentially uninitialized buffer
'seq' used. Consider checking the first actual argument of the
'strlen' function. linenoise.c 435
void refreshShowHints(struct abuf *ab, struct linenoiseState *l, int plen) { char seq[64]; if (hintsCallback && plen+l->len < l->cols) { int color = -1, bold = 0; char *hint = hintsCallback(l->buf,&color,&bold); if (hint) { int hintlen = strlen(hint); int hintmaxlen = l->cols-(plen+l->len); if (hintlen > hintmaxlen) hintlen = hintmaxlen; if (bold == 1 && color == -1) color = 37; if (color != -1 || bold != 0) snprintf(seq,64,"\033[%d;%d;49m",bold,color); abAppend(ab,seq,strlen(seq)); // <= abAppend(ab,hint,hintlen); if (color != -1 || bold != 0) abAppend(ab,"\033[0m",4); /* Call the function to free the hint returned. */ if (freeHintsCallback) freeHintsCallback(hint); } }}
Буфер seq может быть заполнен, а может быть и не
заполнен! Он заполняется только при выполнении условия:
if (color != -1 || bold != 0) snprintf(seq,64,"\033[%d;%d;49m",bold,color);
Логично предположить, что условие может быть не выполнено, и
тогда буфер останется неинициализированным. В этом случае его
нельзя использовать для добавления к строке ab.
Чтобы исправить ситуацию, стоит изменить код следующим
образом:
if (color != -1 || bold != 0){ snprintf(seq,64,"\033[%d;%d;49m",bold,color); abAppend(ab,seq,strlen(seq));}
Ошибка N70; Странная
маска
Предупреждение PVS-Studio: V547 Expression is always false.
tasks.c 896
#ifndef portPRIVILEGE_BIT #define portPRIVILEGE_BIT ( ( UBaseType_t ) 0x00 )#endifstatic void prvInitialiseNewTask(...., UBaseType_t uxPriority, ....){ StackType_t *pxTopOfStack; UBaseType_t x; #if (portNUM_PROCESSORS < 2) xCoreID = 0; #endif #if( portUSING_MPU_WRAPPERS == 1 ) /* Should the task be created in privileged mode? */ BaseType_t xRunPrivileged; if( ( uxPriority & portPRIVILEGE_BIT ) != 0U ) { xRunPrivileged = pdTRUE; } else { xRunPrivileged = pdFALSE; } ....}
Константа portPRIVILEGE_BIT имеет значение 0. Поэтому
странно использовать его как маску:
if( ( uxPriority & portPRIVILEGE_BIT ) != 0U )
Ошибка N71, Утечка памяти
Предупреждение PVS-Studio: V773 The function was exited without
releasing the 'sm' pointer. A memory leak is possible. esp_wpa2.c
753
static int eap_peer_sm_init(void){ int ret = 0; struct eap_sm *sm; .... sm = (struct eap_sm *)os_zalloc(sizeof(*sm)); if (sm == NULL) { return ESP_ERR_NO_MEM; } s_wpa2_data_lock = xSemaphoreCreateRecursiveMutex(); if (!s_wpa2_data_lock) { wpa_printf(MSG_ERROR, "......."); // NOLINT(clang-analyzer-unix.Malloc) return ESP_ERR_NO_MEM; // <= } ....}
Если функция xSemaphoreCreateRecursiveMutex не сможет
создать мьютекс, то функция eap_peer_sm_init завершит свою
работу и при этом произойдёт утечка памяти. Как я понимаю, следует
добавить вызов функции os_free для очистки памяти:
s_wpa2_data_lock = xSemaphoreCreateRecursiveMutex(); if (!s_wpa2_data_lock) { wpa_printf(MSG_ERROR, "......."); os_free(sm); return ESP_ERR_NO_MEM; }
Что интересно, компилятор Clang тоже предупреждает об этой
ошибке. Однако автор кода почему-то проигнорировал и даже
специально подавил соответствующее предупреждение:
// NOLINT(clang-analyzer-unix.Malloc)
Наличие этого подавляющего комментария мне непонятно. Ошибка
ведь действительно есть. Возможно, автор кода просто не понял, что
не нравится компилятору и решил, что это ложное срабатывание.
Заключение
Спасибо за внимание. Как видите, ошибок весьма много. А это ведь
был только беглый просмотр неполного отчёта. Надеюсь, Юрий Попов
примет эстафету и опишет ещё больше ошибок в своей последующей
статье :).
Используйте статический анализатор PVS-Studio регулярно. Это
позволит:
- Находить многие ошибки на раннем этапе, что существенно
сократит расходы на их обнаружение и исправление;
- Находя и исправляя глупые опечатки и прочие ляпы с помощью
статического анализа, вы высвободите время, которое можно потратить
на более высокоуровневый обзор кода и алгоритмов;
- Лучше контролировать качество кода новичков и быстрее обучать
их писать красивый надежный код;
- Если речь идёт о программном обеспечении для встраиваемых
устройств, то очень важно устранить как можно больше ошибок до
выпуска устройств в эксплуатацию. Поэтому любая дополнительно
найденная ошибка с помощью анализатора кода, это здорово. Каждая
незамеченная ошибка в программно-аппаратном устройстве потенциально
несёт репутационные риски и затраты на обновление прошивок.
Приглашаю
скачать и попробовать демонстрационную версию анализатора
PVS-Studio. Также напоминаю, что если вы разрабатываете открытый
проект или используете анализатор в академических целях, то для
таких случаев мы предлагаем несколько вариантов
бесплатных лицензий. Не ждите, когда коварный баг съест вашу ногу,
начните использовать PVS-Studio прямо сейчас.
Если хотите поделиться этой статьей с англоязычной аудиторией,
то прошу использовать ссылку на перевод: Andrey Karpov.
Espressif IoT Development Framework: 71 Shots in the
Foot.

 Тимур Батыршин (erthad) в IT более 15 лет, за это время участвовал
в строительстве дистрибутивов Linux, виртуализации серверов, когда
это еще не было модным, автоматизировал разворачивание серверов на
облаках и строил архитектуру облачных приложений.
Тимур Батыршин (erthad) в IT более 15 лет, за это время участвовал
в строительстве дистрибутивов Linux, виртуализации серверов, когда
это еще не было модным, автоматизировал разворачивание серверов на
облаках и строил архитектуру облачных приложений. Дмитрий Зайцев (bhavenger) развивал DevOps- и SRE-практики, когда
это ещё не было модным. Совмещал их с ITIL и Cobit, пока те ещё
были в моде. Имеет опыт работы в gamedev, adtech, bigdata, fintech,
marketing. Является одним из организаторов DevOpsDays Moscow,
DevOps Moscow, Hangops Ru. Сейчас Head of SRE во flocktory.com.
Дмитрий Зайцев (bhavenger) развивал DevOps- и SRE-практики, когда
это ещё не было модным. Совмещал их с ITIL и Cobit, пока те ещё
были в моде. Имеет опыт работы в gamedev, adtech, bigdata, fintech,
marketing. Является одним из организаторов DevOpsDays Moscow,
DevOps Moscow, Hangops Ru. Сейчас Head of SRE во flocktory.com. Валерия Пилия работает во
flocktory.com Infrastructure Engineer, занимается поддержкой
инфраструктуры на AWS с k8s. Участвовала в адаптации русскоязычного
издания книги DevOps Handbook и является одним из организаторов
митапов DevOps Moscow и конференции DevOpsDays Moscow 2019. В
программный комитет DevOpsConf пришла два года назад, как и другие
участники беседы с подачи Александра Титова.
Валерия Пилия работает во
flocktory.com Infrastructure Engineer, занимается поддержкой
инфраструктуры на AWS с k8s. Участвовала в адаптации русскоязычного
издания книги DevOps Handbook и является одним из организаторов
митапов DevOps Moscow и конференции DevOpsDays Moscow 2019. В
программный комитет DevOpsConf пришла два года назад, как и другие
участники беседы с подачи Александра Титова. Мона Архипова (Mona_Sax) COO sudo.su (МИРЦ), до этого занимала
руководящие и экспертные должности в области безопасности и IT. В
ежедневной работе активно использует DevOps-практики и тоже
начинала, когда это еще не было мейнстримом. Мона присоединилась к
программному комитету после отличного доклада Как (вы)жить без
отдела безопасности о том, что безопасность это ответственность
каждого человека. Теперь несет безопасность в массы не только на
конференциях по безопасности, но и на DevOps Live.
Мона Архипова (Mona_Sax) COO sudo.su (МИРЦ), до этого занимала
руководящие и экспертные должности в области безопасности и IT. В
ежедневной работе активно использует DevOps-практики и тоже
начинала, когда это еще не было мейнстримом. Мона присоединилась к
программному комитету после отличного доклада Как (вы)жить без
отдела безопасности о том, что безопасность это ответственность
каждого человека. Теперь несет безопасность в массы не только на
конференциях по безопасности, но и на DevOps Live.


















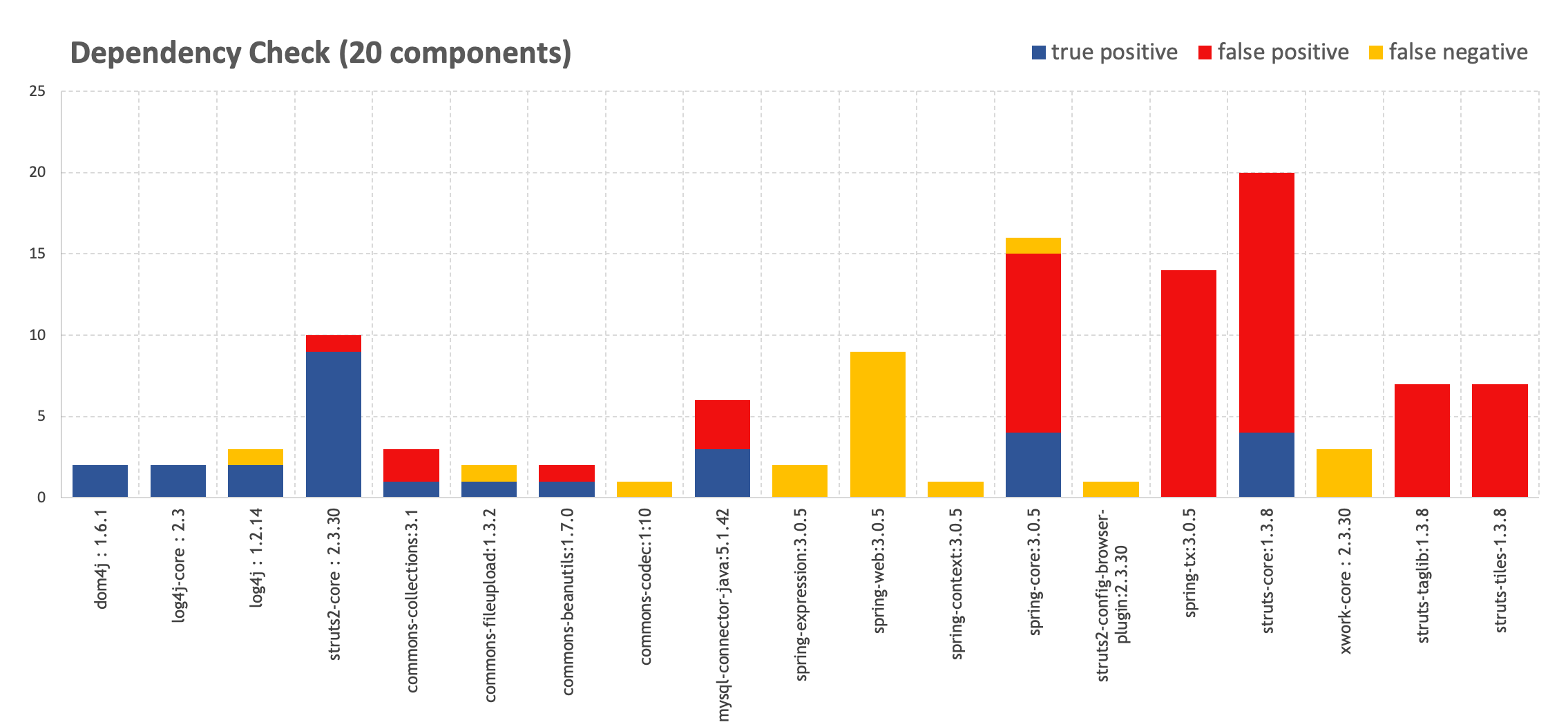

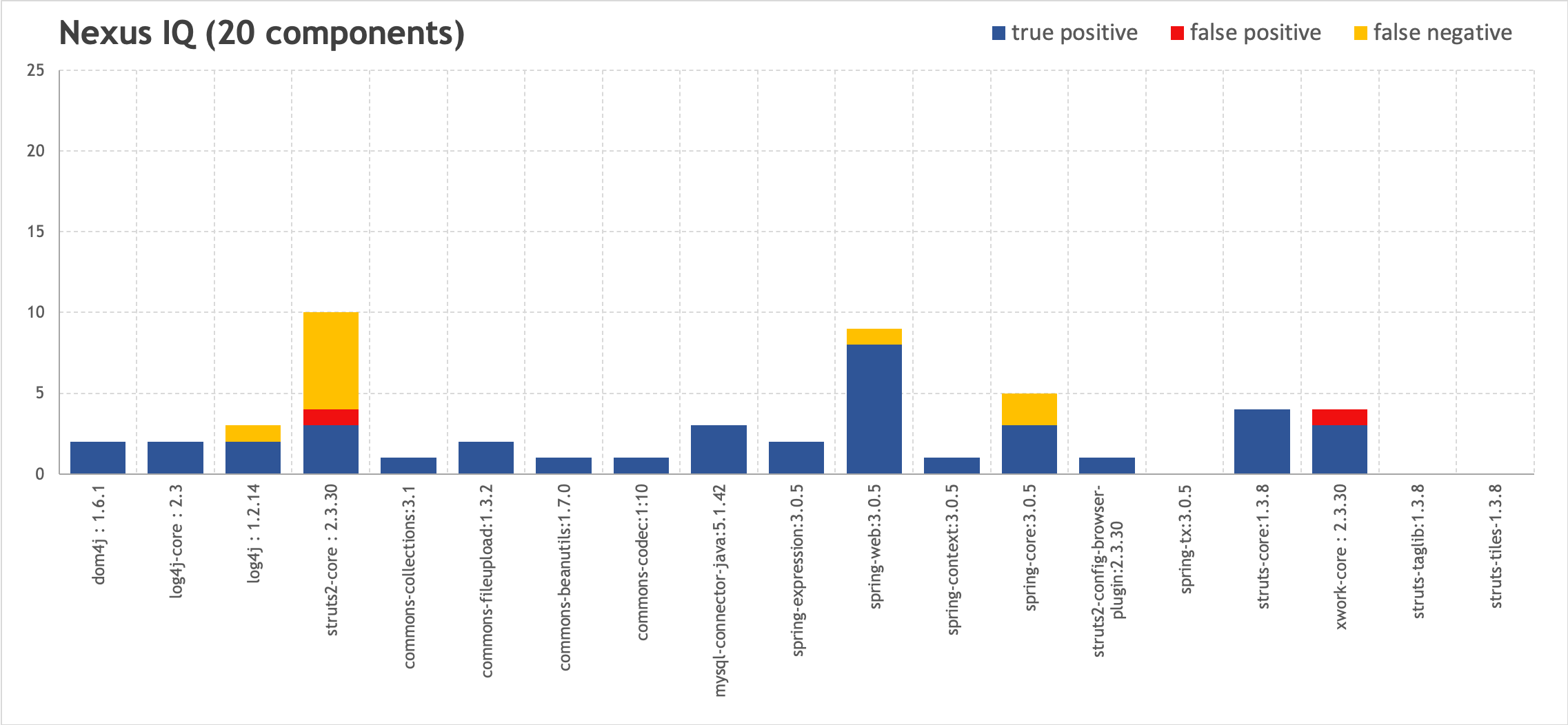



















 Одно из видений практик DevSecOps.
Источник:
https://holisticsecurity.io/2020/02/10/security-along-the-container-based-sdlc
Одно из видений практик DevSecOps.
Источник:
https://holisticsecurity.io/2020/02/10/security-along-the-container-based-sdlc



















 Схема интеграции Netsparker с AD через Keycloak
Схема интеграции Netsparker с AD через Keycloak
 Экран
настройки Netsparker SSO
Экран
настройки Netsparker SSO
 Экран входа в Netsparker для
неаутентифицированного пользователя
Экран входа в Netsparker для
неаутентифицированного пользователя Сохранение SAML мета-данных Netsparker
Сохранение SAML мета-данных Netsparker Экран добавления Realm'а
Экран добавления Realm'а Экран
добавления клиента Keycloak
Экран
добавления клиента Keycloak
 Данные сертификата клиента Keycloak
Данные сертификата клиента Keycloak Настройки клиента Keycloak
Настройки клиента Keycloak
 Настройка SSO в Netsparker
Настройка SSO в Netsparker Процесс входа в Netsparker
Процесс входа в Netsparker
 Экран создания пользователей в Netsparker
Экран создания пользователей в Netsparker Список "приглашенных" пользователей
Список "приглашенных" пользователей Экран регистрации нового пользователя Netsparker
Экран регистрации нового пользователя Netsparker Экран добавления пользователя в Keycloak
Экран добавления пользователя в Keycloak
 Создание пароля для пользователя Keycloak
Создание пароля для пользователя Keycloak
 Экран входа в Keycloak
Экран входа в Keycloak Перенаправление из Keycloak в Netsparker
Перенаправление из Keycloak в Netsparker Основной экран сканера Netsparker
Основной экран сканера Netsparker Следующий этап настройки: Keycloak + AD
Следующий этап настройки: Keycloak + AD
 Выбор провайдера аутентификации в Keycloak
Выбор провайдера аутентификации в Keycloak Опция импортирования пользователей
Опция импортирования пользователей
 Сводная страница настроек LDAP провайдера
Сводная страница настроек LDAP провайдера Настройка mapper'ов
Настройка mapper'ов
 Настройка отображения email адреса на имя
пользователя
Настройка отображения email адреса на имя
пользователя
 Искомый
пользователь Netsparker
Искомый
пользователь Netsparker Промежуточный экран входа в Netsparker SSO
Промежуточный экран входа в Netsparker SSO Экран входа в Keycloak
Экран входа в Keycloak Основной экран Netsparker для
аутентифицированного AD-пользователя Alex
Основной экран Netsparker для
аутентифицированного AD-пользователя Alex Дополнительная настройка клиента Keycloak
Дополнительная настройка клиента Keycloak Дополнительная настройка mapper'ов
Дополнительная настройка mapper'ов
 Настройка SAML-mapper'а для имени пользователя
Настройка SAML-mapper'а для имени пользователя
 Настройка SAML-mapper'а для фамилии пользователя
Настройка SAML-mapper'а для фамилии пользователя
 Список mapper'ов
Список mapper'ов
 Настройка автоматического создания
пользователей в Netsparker
Настройка автоматического создания
пользователей в Netsparker Удаление пользователя
Удаление пользователя Основной экран Netsparker для
пользователя, автоматически созданного при входе через AD
Основной экран Netsparker для
пользователя, автоматически созданного при входе через AD Настройка длительности SSO сессии
Настройка длительности SSO сессии
















 Изображение: freepik.com
Изображение: freepik.com
 Изображение:
ptsecurity.com
Изображение:
ptsecurity.com
 DevSecOps-конвейер в Positive
Technologies: безопасный цикличный процесс разработки, сборки,
развертывания, тестирования, продвижения, публикации, установки
обновлений, сбора телеметрии и мониторинга
DevSecOps-конвейер в Positive
Technologies: безопасный цикличный процесс разработки, сборки,
развертывания, тестирования, продвижения, публикации, установки
обновлений, сбора телеметрии и мониторинга
 Сканер PT Application Inspector в CI-инфраструктуре
Сканер PT Application Inspector в CI-инфраструктуре
 Типовые шаги процесса продуктовой сборки
Типовые шаги процесса продуктовой сборки
 Пример описания правил Security Gates в
файле aisa-codequality.settings.yaml
Пример описания правил Security Gates в
файле aisa-codequality.settings.yaml
 Пример портянки сообщений от SonarQube в
треде мердж-реквеста GitLab
Пример портянки сообщений от SonarQube в
треде мердж-реквеста GitLab
 Пример треда мердж-реквеста в GitLab, не
заблокированного ботом, так как правила Security Gates выполняются
Пример треда мердж-реквеста в GitLab, не
заблокированного ботом, так как правила Security Gates выполняются
 не более двух") Пример треда мердж-реквеста в GitLab,
заблокированного ботом, так как нарушено правило Security Gates:
major-проблем (Medium-уязвимостей от сканера) не более двух
Пример треда мердж-реквеста в GitLab,
заблокированного ботом, так как нарушено правило Security Gates:
major-проблем (Medium-уязвимостей от сканера) не более двух
 Пример интеграции отчета от сканера в
сборки на TeamCity
Пример интеграции отчета от сканера в
сборки на TeamCity
 Основные отличия в работе шаблонов сканирования
Основные отличия в работе шаблонов сканирования
 Схема пайплайна сборки со сканированием в
режиме информирования
Схема пайплайна сборки со сканированием в
режиме информирования
 Схема пайплайна сборки со сканированием в
режиме блокирования мердж-реквеста
Схема пайплайна сборки со сканированием в
режиме блокирования мердж-реквеста
 Схема пайплайна со сканированием в режиме
блокирования мердж-реквеста и самой сборки
Схема пайплайна со сканированием в режиме
блокирования мердж-реквеста и самой сборки
 Схема классического git-flow и
рекомендуемые шаблоны для различных веток
Схема классического git-flow и
рекомендуемые шаблоны для различных веток




