
Введение
Основная цель - обнаружение лица и маски в браузере, не используя бэкенд на Python. Это простое приложение WebApp / SPA, которое содержит только JS-код и может отправлять некоторые данные на серверную часть для следующей обработки. Но начальное обнаружение лица и маски выполняется на стороне браузера и никакой реализации Python для этого не требуется.
На данный момент приложение работает только в браузере Chrome.
В следующей статье я опишу более технические подробности реализации на основе наших исследований.
Есть 2 подхода, как можно это реализовать в браузере:
Оба они поддерживают WASM, WebGL и CPU бэкенд. Но мы будем сравнивать только WASM и WebGL, так как производительность на CPU очень низкая и не может быть использована в конечной реализации.
TensorFlow.js
На официальном сайте TensorFlow.js предлагает несколько обученных и готовых к использованию моделей с готовой постобработкой. Для обнаружения лиц в реальном времени мы взяли BlazeFace модель, онлайн демо доступно тут.
Больше информации о BlazeFace можно найти тут.
Мы создали демо, чтоб немного поиграться со средой выполнения и моделью, выявить любые существующие проблемы. Ссылки для запуска приложения с различными моделями и средой выполнения можно найти ниже:
WASM (размер изображения для определения лица: 160x120px; размер изображения для определения маски: 64x64px)
WebGL (размер изображения для определения лица: 160x120px; размер изображения для определения маски: 64x64px)
Результаты производительности: получение кадров
Мы можем получать кадры с помощью соответствующих функций HTML API. Но и этот процесс занимает время. Поэтому нам нужно понимать, сколько времени мы потратим на такие действия. Ниже приведены соответствующие временные метрики.
Наша цель - обнаружить лицо как можно быстрее, поэтому мы должны получать каждый кадр стрима и обрабатывать его. Для этой задачи мы можем использовать requestAnimationFrame, который вызывается каждые 16,6мс или каждый фрейм.
Метод grabFrame() из интерфейса ImageCapture позволяет нам взять текущий кадр из видео в MediaStreamTrack и вернуть Promise, который вернет нам изображение в формате ImageBitmap.

Одиночный режим - это максимальная производительность при получении кадра. Режим синхронизации - это то, как часто мы можем получать кадр с распознаванием лиц.
Результаты производительности: определения лица и маски

Цветовая схема: < 6 fps красный, 7-12 fps оранжевый, 13-18 fps желтый, 19+ fps зеленый.
Результаты:
Мы не учитываем временные метрики при запуске приложения. Очевидно, что во время запуска приложения и первых запусков модели оно будет потреблять больше ресурсов и времени. Когда приложение находится в "теплом" режиме, только тогда стоит получать показатели производительности. Теплый режим в нашем случае - это просто позволить приложению проработать 5-10 секунд, а затем получать показатели производительности.
Возможные неточности в собранных временных показателях - до 50мс.
Модель BlazeFace была разработана специально для мобильных устройств и помогает достичь хорошей производительности при использовании TFLite на платформах Android и IOS (~ 50-200 FPS).
Больше информации тут.
Набор данных для переобучения модели с нуля недоступен (исследовательская группа Google не поделилась им).
BlazeFace содержит 2 модели:
-
Фронтальную камеру: размер изображения 128 x 128px, быстрее, но с меньшей точностью.
-
Задняя камера: размер изображения 256 x 256px, медленнее, но с высокой точностью.
Размер изображения
Исходное изображение может быть любого размера в соответствии с настройками камеры и бизнес требованиями. Но когда мы обрабатываем кадры для обнаружения лица и маски, размер исходного кадра изменяется до подходящего размера в зависимости от модели.
Изображение, используемое BlazeFace для распознавания лиц, имеет размер 128 x 128px. Исходное изображение будет изменено до этого размера с учетом его пропорций. Изображение, которое используется для обнаружения маски, имеет размер 64 x 64px.
Мы выбрали минимальные разрешения для обоих изображений с учетом требований к производительности и результатам. Такие минимальные изображения показали наилучшие результаты на ПК и мобильных устройствах. Мы используем изображения размером 64 x 64px для обнаружения маски, потому что размера 32 x 32px недостаточно для обнаружения маски с достаточной точностью.
Как получить лучшие изображения для анализа приложением?
Используя TensorFlow.js у нас есть следующие опции для получения лучшего изображения, чтоб использовать в приложении:
-
BlazeFace позволяет настроить точность определения лица. Мы установили этот показатель с высоким значением (> 0,9), чтобы избежать неожиданных положительных результатов (например "призраки" в темном помещении или затылок человека определяло как лицо).
-
BlazeFace позволяет настроить максимальное количество лиц, которые возвращаются после анализа изображения. Можно указать для этого параметра значение 1, чтобы вернуть только 1 лицо; можно установить значение 2 и более и в этом случае при обнаружении более 1-го лица сообщать о том, что один человек / лицо может находиться перед камерой.
-
BlazeFace возвращает область лица и ориентиры (глаза, уши, нос, рот). Таким образом у нас есть все возможности для проверки этих результатов, чтобы убедиться, что обнаруженные лица подходят для последующей обработки.
Такие проверки могут быть следующими:
-
Область лица должна находиться в калибровочной рамке в X%.
-
Все ориентиры или их часть должны быть в калибровочной рамке.
-
Ширина и высота области лица должны быть достаточными для дальнейшего анализа
-
Проверки ширины / высоты области лица и ориентиров выполняются очень быстро на стороне клиента с помощью JS.
Выбранные изображения, в соответствии с указанными выше правилами, будут отправлены на следующие этапы обработки: обнаружение маски. Такая логика обеспечит более быстрое обнаружение лица до того момента, когда мы будем уверены, что обнаруженное лицо хорошего качества.
Размер моделей определения маски

Для определения маски мы использовали MobileNetV2 и MobileNetV3 с различными типами и мультипликаторами.
Мы предлагаем использовать легкие или сверхлегкие модели с TensorFlow.js в браузере (<3Mb). Основная причина в том, что WASM работает быстрее с такими моделями. Это указано в официальной документации, а также подтверждено нашими тестами производительности.
Дополнительные ресурсы
-
WASM JS бэкенд: ~60Kb
-
OpenCV.js: 1.6Mb
-
Наше SPA приложение (+TensorFlow.js): ~500Kb
-
BlazeFace модель: 466Kb
Для веб приложений время до взаимодействия (TTI) с ~3.5Mb JavaScript кода и бинарниками + JSON модели размером 1.5Mb to 6Mb будет >10 сек в холодном режиме; в прогретом режиме ожидается TTI - 4-5 сек.
Если использовать Web Worker (и OpenCV.js будет только в воркерах), это значительно уменьшит размер основного приложения до 800-900Kb. TTI будет 7-8 секунд в холодном режиме; в прогретом режиме <5 сек.
Возможные подходы к запуску моделей нейронных сетей в браузере
Однопоточная реализация

Это реализация по умолчанию для браузеров. Мы запускаем обе модели для обнаружения лиц и масок в одном потоке. Ключевым моментом является обеспечение хорошей производительности для обеих моделей для работы с любыми проблемами в одном потоке. Это текущий подход, который использовался для получения указанных выше показателей производительности.
У этого подхода есть некоторые ограничения. Если мы хотим добавить дополнительные модели для запуска последовательной обработки, то они будут выполняться в том же потоке хоть и асинхронно, но последовательно. Это снизит общие показатели производительности при обработке кадров.
Использование Web Workers для запуска моделей в разном контексте и распараллеливание в браузере

В основном потоке JS запускается модель BlazeFace для обнаружения лиц, а обнаружение маски выполняется в отдельном потоке через Web Worker. Благодаря такой реализации мы можем разделить обе запущенные модели и ввести параллельную обработку кадров в браузере. Это положительно повлияет на общее восприятие UX в приложении. Веб-воркеры будут загружать библиотеки TensorFlow.js и OpenCV.js, основной поток JS - только TensorFlow.js. Это означает, что основное приложение будет запускаться намного быстрее, и тем самым мы сможем значительно сократить время TTI в браузере. Обнаружение лиц будет запускаться чаще, это увеличит FPS процесса обнаружения лиц. В результате процесс обнаружения маски будет запускаться чаще, а также будет увеличиваться FPS этого процесса. Ожидаемые улучшения до ~ 20%. Это означает, что указанные в статье выше FPS и миллисекунды могут быть улучшены на это значение.
При таком подходе к запуску разных моделей в разных контекстах с помощью веб-воркеров мы можем запускать больше моделей нейронных сетей в браузере с хорошей производительностью. Основным фактором здесь будут аппаратные характеристики устройства, на котором это запускается.
Мы реализовали такой подход в приложении, и он работает. Но у нас есть некоторые технические проблемы с обратным вызовом postMessage, когда веб-воркер отправляет сообщение обратно в основной поток. По каким-то причинам он вводит дополнительную задержку (до 200мс на мобильных устройствах), которая убивает улучшение производительности, которого мы достигли с помощью распараллеливания (эта проблема актуальна только для чистого JS, после реализации на React.js эта проблема исчезла).
Результаты реализации с Web Workers
Наша идея состоит в том, чтобы использовать веб-воркеры для запуска каждой модели в отдельном воркере / потоке / контексте и добиться параллельной обработки моделей в браузере. Но мы заметили, что callback-функция в воркере вызывается с некоторыми задержками. Ниже вы можете найти соответствующие измерения и выводы о том, от каких факторов это зависит.
Тестовые параметры:mobileNetVersion=V3mobileNetVersionMultiplier = 0.75mobileNetVersionType = float16thumbnailSize=32pxbackend = wasm
В приложении мы запускаем BlazeFace в основном потоке и модель обнаружения маски в веб-воркере.
Измерения времени обработки Web Worker на разных устройствах:


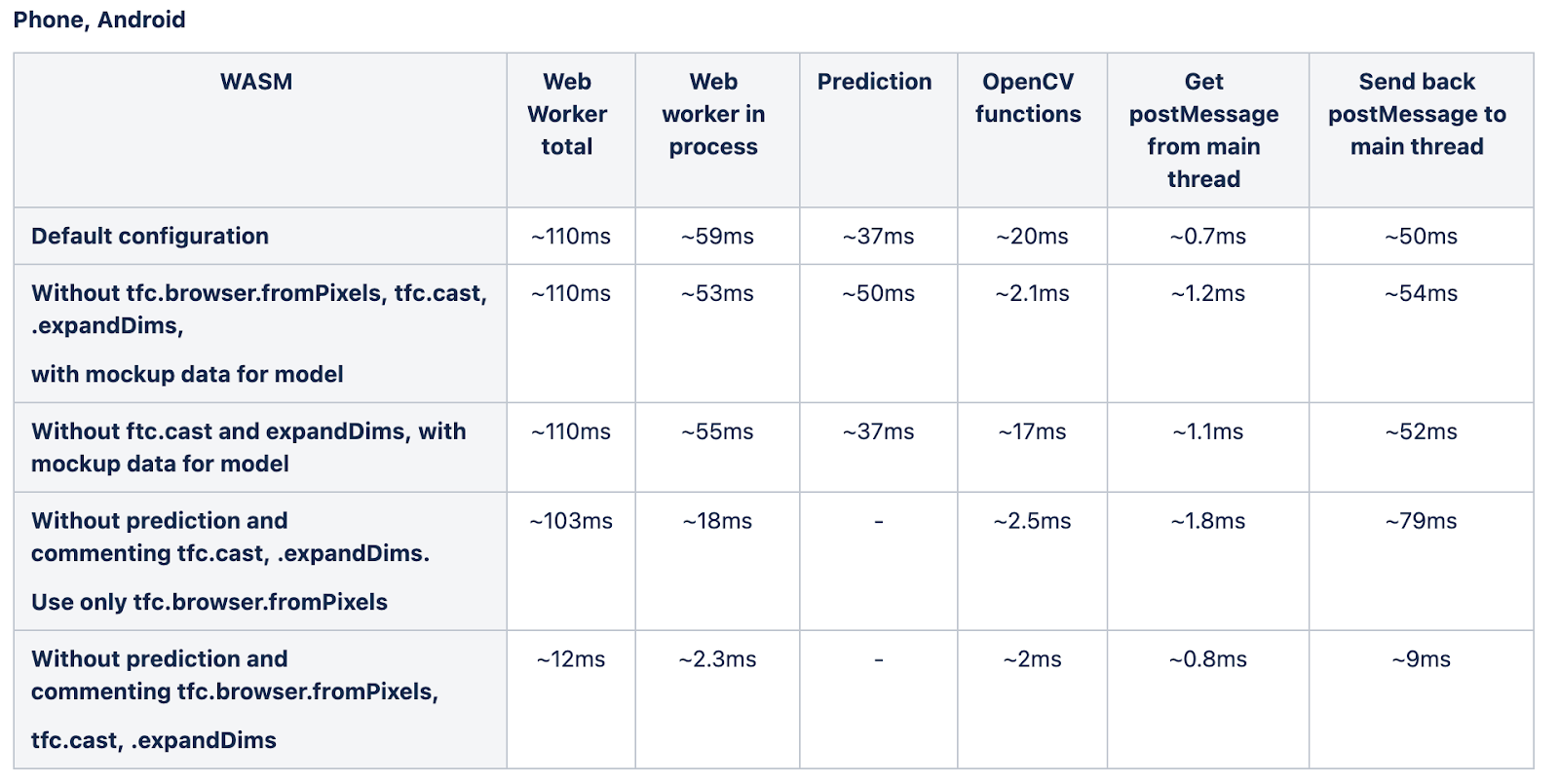
Приведенные выше результаты демонстрируют, что по некоторым причинам время для отправки обратного вызова из Web Worker в основной поток зависит от модели, работающей или использующей метод TensorFlow browser.fromPixels в этом Web Worker. Если он запущен с моделью, обратный вызов в Mac OS отправляется ~ 27мс, если модель не запущена - 5мс. Эта разница в 22мс для Mac OS может привести к задержкам 100300мс на более слабых устройствах и повлияет на общую производительность приложения при использовании Web Worker. В настоящее время мы не понимаем, почему это происходит.
Как повысить точность и уменьшить количество ложных срабатываний?
Нам нужно иметь больше контекста, чтобы принять соответствующее решение, чтобы сообщить об обнаружении лица и отсутствии маски. Такой контекст - это ранее обработанные кадры и их состояние (лицо есть или нет, лицо есть или нет, маска есть или нет). Мы реализовали плавающий сегмент для управления таким дополнительным контекстом. Длина сегмента настраивается и зависит от текущего FPS, но в любом случае она не должна быть больше 200300мс, чтобы не было видимых задержек. Ниже приведена соответствующая схема, описывающая идею:

Заключение:
Чем мощнее устройство, тем лучше результаты производительности при измерении:
Для ПК мы могли получить следующие показатели:
-
Определение лица: > 30fps
-
Определение лица + определение маски: до 45fps
Для мобильных устройств мы могли получить следующие показатели:
-
Определение лица: от 2.5fps до 12-15fps в зависимости от мобильного устройства
-
Определение лица + определение маски: от 2 до 12fps в зависимости от мобильного устройства
-
Обращаем внимание, что видео всегда в реальном времени и его производительность зависит от самого устройства, но всегда будет от 30 кадров в секунду.
-
Для модели обнаружения маски в большинстве случаев лучшие результаты демонстрирует модель MobileNetV2 0.35, типы не влияют на метрики производительности.
-
Размер модели обнаружения маски зависит от типов. Поскольку типы не влияют на показатели производительности, рекомендуется использовать модели uint16 или float16, чтобы иметь меньший размер модели в браузере и более быстрый TTI.
-
Среда выполнения WASM показывает лучшие результаты по сравнению с WebGL для модели BlazeFace. Это соответствует официальной документации TensorFlow.js относительно производительности небольших моделей (<3Mb):
Для большинства моделей серверная часть WebGL по-прежнему будет превосходить серверную часть WASM, однако WASM может быть быстрее для сверхлегких моделей (менее 3Mb и 60млн операций умножения и добавления). В этом случае преимущества распараллеливания GPU перевешиваются фиксированными накладными расходами на выполнение шейдеров WebGL.
-
Время TTI всегда лучше для моделей WASM по сравнению с WebGL с той же конфигурацией моделей.
-
Производительность среды выполнения и моделей TensorFlow.js можно повысить, используя расширение WASM для добавления инструкций SIMD, позволяющих векторизовать и выполнять несколько операций с плавающей точкой параллельно. Предварительные тесты показывают, что включение этих расширений обеспечивает ускорение в 23 раза по сравнению с WASM. Больше информации здесь. Это все еще экспериментальная функция, которая по умолчанию не поставляется со средой выполнения. Также после релиза он будет доступен во время выполнения по умолчанию или через дополнительные параметры конфигурации.
-
На стороне клиента ожидаемый размер приложения составляет ~ 3,5Mb JS кода со всеми зависимостями, 466Kb модели BlazeFace, от 1,1Mb до 5,6Mb модели обнаружения маски. Ожидаемое время TTI для приложения составляет > 10 секунд для мобильных устройств в холодном режиме; в теплом режиме - ~ 5сек.
-
При использовании веб-воркеров OpenCV.js может быть загружен только в веб-воркеры, это значительно снижает TTI для основного приложения.
-
Во время тестирования мы заметили, что устройства сильно нагреваются. Поскольку ожидается круглосуточная работа приложения, этот факт может иметь большое влияние на окончательное решение, какие устройства использовать. Вам необходимо принять во внимание эту информацию.
-
Также было замечено, что лучше, если устройства будут полностью заряжены и подключены к зарядному устройству во время работы. В этом случае производительность устройств по нашим наблюдениям лучше. Зарядка от USB не позволяет поддерживать батарею на одном уровне долго, поэтому следует использовать зарядку от розетки. Эту информацию следует принимать во внимание.
-
На наш взгляд, текущему решению достаточно даже 4-5 кадров в секунду, чтобы обеспечить хорошее восприятие пользователем UX. Но важно не показывать на экране область лица или ориентиры, а управлять всем на видео / экране:
-
Выделяя на экране, когда мы обнаружили человека.
-
Информирование о маске / отсутствии маски с помощью текстовых сообщений или другого выделения экрана.
-
-
При таком взаимодействии пользователя задержки между реальным временем и нашими метаданными на экране будут составлять 200300мс. Такие значения будут рассматриваться пользователями системы как некритические задержки.








 Пример работы нейронной сети ARShadowGAN-like
Пример работы нейронной сети ARShadowGAN-like
 Схема генератора
Схема генератора
 Полная схема обучения ARShadowGAN-like
Полная схема обучения ARShadowGAN-like
 Пример Style Transfer
Пример Style Transfer
 Пример Shadow-AR датасета.
Пример Shadow-AR датасета.





 Визуализация процесса обучения
Визуализация процесса обучения
 Графики обучения тренировочная выборка
Графики обучения тренировочная выборка
 Графики обучения валидационная выборка
Графики обучения валидационная выборка




























































 и рендеринг 3D модели лица (справа)") Фотография (слева) и рендеринг 3D модели лица
(справа)
Фотография (слева) и рендеринг 3D модели лица
(справа)
 Риг для съемки лица
Риг для съемки лица
 Пайплайн алгоритма
Пайплайн алгоритма
 Поэтапное улучшение исходного меша
Поэтапное улучшение исходного меша
 Диффузная и спекулярная карты нормалей
Диффузная и спекулярная карты нормалей

 и рендеринга 3D модели под тем же углом и освещением (справа)") Сравнение фотографии (слева) и рендеринга
3D модели под тем же углом и освещением (справа)
Сравнение фотографии (слева) и рендеринга
3D модели под тем же углом и освещением (справа)
 Уточненный меш и рендеринг под новым
ракурсом и освещением
Уточненный меш и рендеринг под новым
ракурсом и освещением
 Пример анализа жилых объектов при помощи нейросети
Пример анализа жилых объектов при помощи нейросети

 Подготовка к удалению опухоли мозга
локализация речевого и зрительного центров помогает улучшить
планирование операции и сократить время на локализацию этих центров
во время процедуры
Подготовка к удалению опухоли мозга
локализация речевого и зрительного центров помогает улучшить
планирование операции и сократить время на локализацию этих центров
во время процедуры
") (Сделано из палок и скотча за полчаса)
(Сделано из палок и скотча за полчаса)
























 Эта команда клонирует код GitHub в вашу среду Colab.
Эта команда клонирует код GitHub в вашу среду Colab.



 Источник:
https://www.facebook.com/watch/?v=678774242681114
Источник:
https://www.facebook.com/watch/?v=678774242681114






















 Кластер 0 светлые машины, задом.
Кластер 0 светлые машины, задом. Кластер 1 тёмные машины.
Кластер 1 тёмные машины. Кластер 2 светлые машины, передом.
Кластер 2 светлые машины, передом. Кластер 0 светлые машины, передом.
Кластер 0 светлые машины, передом. Кластер 1 тёмные машины, передом.
Кластер 1 тёмные машины, передом. Кластер 2 светлые машины, задом много
выбросов.
Кластер 2 светлые машины, задом много
выбросов. Кластер 3 тёмные машины, задом много выбросов.
Кластер 3 тёмные машины, задом много выбросов. много выбросов.") Кластер 0 светлые машины, передом, ракурс
направо, внедорожник (вэн) много выбросов.
Кластер 0 светлые машины, передом, ракурс
направо, внедорожник (вэн) много выбросов. Кластер 1 тёмные машины, задом, ракурс
влево много выбросов.
Кластер 1 тёмные машины, задом, ракурс
влево много выбросов.  Кластер 2 светлые машины, задом, ракурс
влево.
Кластер 2 светлые машины, задом, ракурс
влево. много выбросов.") Кластер 3 светлые машины, задом, ракурс
вправо, внедорожник (вэн) много выбросов.
Кластер 3 светлые машины, задом, ракурс
вправо, внедорожник (вэн) много выбросов. Кластер 4 синие машины, передом, ракурс
вправо.
Кластер 4 синие машины, передом, ракурс
вправо..") Кластер 5 белые машины, передом, ракурс
вправо, внедорожник (вэн).
Кластер 5 белые машины, передом, ракурс
вправо, внедорожник (вэн). Кластер 6 белые машины, задом, ракурс
вправо, седан много выбросов.
Кластер 6 белые машины, задом, ракурс
вправо, седан много выбросов. Кластер 7 белые машины, передом, ракурс
вправо, седан много выбросов.
Кластер 7 белые машины, передом, ракурс
вправо, седан много выбросов. Кластер 8 тёмные машины, передом, ракурс
вправо много выбросов.
Кластер 8 тёмные машины, передом, ракурс
вправо много выбросов. Кластер 0 красный, передом, влево много
выбросов из-за сливающегося цвета фар.
Кластер 0 красный, передом, влево много
выбросов из-за сливающегося цвета фар. Кластер 1 т.-серый, перед, вправо, кроссовер.
Кластер 1 т.-серый, перед, вправо, кроссовер. Кластер 2 синий, зад, вправо много выбросов.
Кластер 2 синий, зад, вправо много выбросов. Кластер 3 белый, перед, вправо нет
ошибок, кузов определён неточно: хэтчбек/кроссовер.
Кластер 3 белый, перед, вправо нет
ошибок, кузов определён неточно: хэтчбек/кроссовер. Кластер 4 св.-серый, зад, вправо, седан.
Кластер 4 св.-серый, зад, вправо, седан. Кластер 5 т.-серый/чёрный, перед, влево,
кроссовер.
Кластер 5 т.-серый/чёрный, перед, влево,
кроссовер. Кластер 6 белый, зад, вправо, кроссовер.
Кластер 6 белый, зад, вправо, кроссовер. Кластер 7 белые, перед, вправо, седан.
Кластер 7 белые, перед, вправо, седан. Кластер 8 белый, зад, влево, кроссовер.
Кластер 8 белый, зад, влево, кроссовер. Кластер 9 т.-серый, перед, вправо, седан.
Кластер 9 т.-серый, перед, вправо, седан. Кластер 10 т.-серый, зад, вправо, седан.
Кластер 10 т.-серый, зад, вправо, седан. Кластер 11 св.-серый, перед, влево, вэн.
Кластер 11 св.-серый, перед, влево, вэн.  Кластер 12 св.-серый, перед, вправо, вэн.
Кластер 12 св.-серый, перед, вправо, вэн. Кластер 13 белый, перед, вправо, седан.
Кластер 13 белый, перед, вправо, седан. Кластер 14 т.-серый/чёрный, перед, влево,
седан смешан с кластером 5.
Кластер 14 т.-серый/чёрный, перед, влево,
седан смешан с кластером 5. Кластер 15 белый, перед, влево, седан.
Кластер 15 белый, перед, влево, седан. Кластер 16 т.-серый, зад, влево, седан.
Кластер 16 т.-серый, зад, влево, седан. Кластер 17 св.-серый, перед, вправо,
кроссовер.
Кластер 17 св.-серый, перед, вправо,
кроссовер. Кластер 18 чёрный, перед, вправо,
кроссовер много выбросов.
Кластер 18 чёрный, перед, вправо,
кроссовер много выбросов. Кластер 19 чёрный, перед, вправо, седан.
Кластер 19 чёрный, перед, вправо, седан.




















 Датасет glove, размер эмбеддинга 100,
расстояние - angular
Датасет glove, размер эмбеддинга 100,
расстояние - angular























 Скриншот стрима матча континентальной
лиги. LCL Летний Сплит 2020.
Скриншот стрима матча континентальной
лиги. LCL Летний Сплит 2020.

 c предобученным efficientnet
энкодером и обучил решать задачу instance сегментации для
трех классов: башни (жёлтый цвет), золото
(зелёный цвет) и кол-во убийств
(фиолетовый цвет). Имплементация модели была взята из
репозитория
c предобученным efficientnet
энкодером и обучил решать задачу instance сегментации для
трех классов: башни (жёлтый цвет), золото
(зелёный цвет) и кол-во убийств
(фиолетовый цвет). Имплементация модели была взята из
репозитория  , а конкретно multihead
архитектуры. Идея такова, что если мы имеем последовательности
чисел фиксированной небольшой длины (а мы имеем), то мы можем не
возиться с RNN или же детектировать отдельные символы. Мы
можем взять энкодер и поставить за ним несколько отдельных голов по
количеству цифр в числе, с 11-ю (11-ый для случаев, когда цифры
нет) выходами в каждой. Каждая голова будет отвечать за
предсказание отдельной цифры в числе, но учится все они будут
вместе. Схожий подход можно найти имплементированным на
Pytorch
, а конкретно multihead
архитектуры. Идея такова, что если мы имеем последовательности
чисел фиксированной небольшой длины (а мы имеем), то мы можем не
возиться с RNN или же детектировать отдельные символы. Мы
можем взять энкодер и поставить за ним несколько отдельных голов по
количеству цифр в числе, с 11-ю (11-ый для случаев, когда цифры
нет) выходами в каждой. Каждая голова будет отвечать за
предсказание отдельной цифры в числе, но учится все они будут
вместе. Схожий подход можно найти имплементированным на
Pytorch  Multihead OCR архитектураНо зачем
таймер-то парсить?
Multihead OCR архитектураНо зачем
таймер-то парсить?










 Комплексирование данных локализации
Комплексирование данных локализации
 Как вам такое перед зачётной попыткой?
Как вам такое перед зачётной попыткой?
 Облако тегов
Облако тегов

 Источник:
era-tehnopolis.ru
Источник:
era-tehnopolis.ru
 А это мобильная базовая станция
А это мобильная базовая станция


") Неофициальный партнер соревнований Леруа Мерлен :)
Неофициальный партнер соревнований Леруа Мерлен :)
") Дрон команды QuadroZ (НИИ РиПУ, Таганрог)
Дрон команды QuadroZ (НИИ РиПУ, Таганрог)  от Airspector") Дрон ИПУ РАН (Москва) от Airspector
Дрон ИПУ РАН (Москва) от Airspector") БПЛА ВИТ
Эра (Геоскан Пионер)
БПЛА ВИТ
Эра (Геоскан Пионер) с нашим шпионом") Дрон и команда ИЦ ИУ РАН и Fast Sense
Studio (Москва) с нашим шпионом
Дрон и команда ИЦ ИУ РАН и Fast Sense
Studio (Москва) с нашим шпионом
 ЗагадкаОтвет
в спойлере
ЗагадкаОтвет
в спойлере

 Пит-стоп
Пит-стоп