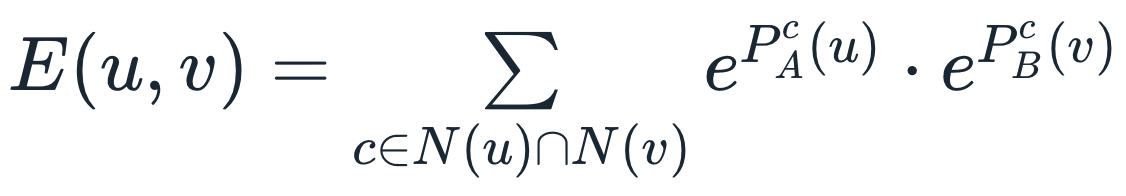Оценка временных затрат при разработке ПО может быть сложной задачей, но есть несколько хитростей, которые помогут получить точные цифры.

Помню, как меня впервые попросили дать оценку
Тогда это застало врасплох.
Меня завели в кабинет, где были мой начальник, его босс и кто-то из вышестоящего руководства, и мы сели за круглый стол, уставившись друг на друга.
Аналитики зачитали некоторые требования от клиента. Мы их коротко обсудили.
И тут мой начальник повернулся ко мне и спросил: Сколько времени это займет?
Я не знал, что сказать, меня к этому не готовили. Мне не сказали, что на этой встрече нужно будет давать оценку я думал, меня позвали поприсутствовать, чтобы я чему-то научился.
И вдруг на меня все смотрят и ждут ответа, а я растерялся и не знаю, что сказать.
Передо мной лежала бумага для заметок. Я взял один листок и начал писать какие-то числа без понятия, для чего, но точно не для этой оценки.
Где-то через минуту, которая показалась мне часом, я решил просто сказать первое, что пришло в голову: Не знаю часов 600?
Начальник рассмеялся, а затем сказал остальным рассчитывать на примерно 1200часов.
Не очень люблю вспоминать тот день.
Понятно, что мне еще многое предстояло узнать, но меня мучил один вопрос: как оценивать объем предстоящей работы?
Цель проведения оценки
Прежде чем приступать к оценке, нужно понять, для чего она будет использоваться. Вы сообщите цифры начальнику или вышестоящему руководству и что будет дальше?
Оценка объема работы используется в основном в двух целях:
-
Планирование.
-
Выставление счета клиенту.
Планирование
Старшие менеджеры, директора и вице-президенты компании заинтересованы в том, чтобы работа шла и выполнялась в срок. Им нужно знать, что и к какому времени будет сделано а для этого нужна оценка того, сколько времени уйдет на проект.
Они знают, какой объем работы какая группа разработчиков может на себя взять в месяц, квартал и год. И чтобы обеспечить занятость сотрудников, руководству нужно составить график работы над проектами. Данная вами оценка и поможет в таком планировании загрузки.
Допустим, в вашей команде разработчиков три человека. Каждый работает по 40часов в неделю это примерно 160часов в месяц, или 480часов в квартал (на троих примерно 1500часов).
Представьте, что ваша команда должна выполнить пять проектов с оценками объемов работ 800, 400, 300, 200 и 50часов. Планируя загрузку, вы будете видеть, что не сможете к концу квартала выполнить все проекты. Менеджеры составят график, использующий определенный процент максимальной загрузки на случай, если разработка займет больше времени, чем предполагалось.
С оценками из нашего примера можно было бы взяться за проекты на 800, 400 и 50часов, и при этом осталась бы некоторая свобода для маневра.
Выставление счета клиенту
Разработка программного обеспечения это бизнес, цель которого зарабатывать. Если клиент хочет, чтобы для него был выполнен индивидуальный проект, и он готов за это платить, ваша оценка поможет определить соответствующую стоимость.
Вам передают требования, вы говорите, сколько времени потребуется на разработку, отдел продаж переводит время в денежную сумму и сообщает ее клиенту, который после этого решает, стоит ли желаемое таких затрат.
Примечание. Это применимо не ко всем компаниям разработчикам ПО: не все занимаются разработкой на заказ. Если вы не разрабатываете ПО на заказ, то оценки объема работ будут использоваться в основном для планирования.
Ключевые факторы при оценке
Теперь, когда вы знаете, для чего вообще нужна оценка, пришло время выяснить, как ее проводить. Когда в следующий раз кто-нибудь спросит, сколько времени потребуется на разработку чего-либо, помните о следующих пяти ключевых факторах.
 Фото AbsolutVision, площадка Unsplash
Фото AbsolutVision, площадка Unsplash
1. Не оценивайте, сколько времени понадобится ВАМ
Первые два года своей карьеры в качестве оценщика я постоянно пытался определить, сколько времени на разработку ушло бы у меня но спрашивают-то не об этом.
Помните, что вы даете оценку с учетом продуктивности команды разработчиков. Не нужно думать, что те, кто будет этим заниматься, знают предметную область так же, как вы. Добавьте небольшой запас, чтобы они могли изучить кодовую базу и новую область знаний.
Часто полезным будет предположить, что работу будет выполнять самый неопытный в команде.
2. Не занижайте завышайте
Помните, что в первую очередь оценка делается для планирования. Поэтому не нужно давать цифры, которые, по вашему мнению, могут быть превышены.
Если разработчики выйдут за отведенный вами срок, это нарушит график работ.
Находиться в границах 20% это нормально, но только если оценка оказалась завышена а не занижена.
К какой бы цифре вы ни пришли, добавьте к ней 20%: задачи обычно оказываются сложнее в реализации, чем кажется.
3. Повышение квалификации
Потребуется ли команде для выполнения проекта изучать что-то новое? Например, если вы обычно разрабатываете приложения для толстых клиентов, а новый проект это создание веб-страницы.
Если есть компоненты, требующие приобретения новых навыков (повышение квалификации), учтите это и в оценке. Дайте команде время изучить все тонкости новых шаблонов, языков, фреймворков ит.д. это всё равно придется делать, поэтому время на обучение нужно заложить в оценку.
 Фото Matheus Frade, площадка Unsplash
Фото Matheus Frade, площадка Unsplash
4. Примеры аналогичных проектов
Проще всего давать оценку проектам, основанным на уже привычных для команды шаблонах.
Если у команды имеется некий опорный материал в виде ранее разработанного ПО, то объем работы может значительно снизиться. Разработчикам проще действовать по принципу копировать, вставить, заменить, и это отражается на скорости выполнения задач.
Обязательно подумайте, делали ли что-то подобное в этой компании раньше. Если у вас есть специалисты, которые занимались такого рода проектами, проконсультируйтесь с ними при оценке и обязательно используйте их код в качестве вспомогательного при разработке.
5. Не забывайте об аналитиках
Часто вас будут просить дать полную оценку, а она включает в себя время разработчиков, бизнес-аналитиков и специалистов по обеспечению качества.
В этом случае дать оценку только по разработчиками будет мало нужно учесть, что бизнес-аналитикам придется писать документацию, делать пользовательские истории и руководить обзорами спринтов.
Также потребуется учесть время, необходимое отделу контроля качества для тестирования. Возможно, у вас есть какая-то система автоматизации, которую нужно настроить и для этого проекта тоже? На всё это нужно время, которое также включается в оценку.
Заключение
Чтобы научиться давать оценку объему работу, нужно время. Этот навык, как и любой другой, требует практики.
Со временем оценки будут даваться вам всё легче. Запомните перечисленные моменты, научитесь понимать, сколько времени занимает разработка определенных элементов, и полагайтесь на свой опыт.
Если резюмировать самое главное, запомните вот что:
задача всегда сложнее, чем кажется, и лучше переоценить объем работ, чем недооценить.
Никто не будет злиться, если у вас всё пойдет по плану, начальство даже порадуется! И при этом у вас останется больше времени на другие проекты.
Так что не стесняйтесь выделять побольше времени и помните, что оценка это всего лишь оценка.
О переводчике
Перевод статьи выполнен в Alconost.
Alconost занимается локализацией игр, приложений и сайтов на 70 языков. Переводчики-носители языка, лингвистическое тестирование, облачная платформа с API, непрерывная локализация, менеджеры проектов 24/7, любые форматы строковых ресурсов.
Мы также делаем рекламные и обучающие видеоролики для сайтов, продающие, имиджевые, рекламные, обучающие, тизеры, эксплейнеры, трейлеры для Google Play и App Store.




















 по отношению к зрителю (j) в
момент времени (t) и спрогнозировать
по отношению к зрителю (j) в
момент времени (t) и спрогнозировать  (понравится ли Хуану
публикация). Математически для каждой публикации (i) мы оцениваем
(понравится ли Хуану
публикация). Математически для каждой публикации (i) мы оцениваем
 , где C представляет характеристику
c(1..C), такую как тип публикации или отношения между
пользователями и автором поста (например, отметили ли они друг
друга как членов семьи), а функция f(.) объединяет атрибуты в одно
значение.
, где C представляет характеристику
c(1..C), такую как тип публикации или отношения между
пользователями и автором поста (например, отметили ли они друг
друга как членов семьи), а функция f(.) объединяет атрибуты в одно
значение. ), например, лайков,
комментариев и репостов, каждое для разного значения k, которые все
должны каким-то образом агрегировать до одного значения Vijt. Ещё
больше усложняет ситуацию то, что для каждого человека в Facebook
есть тысячи сигналов, которые нам нужно оценить, чтобы определить,
что для этого человека может оказаться наиболее актуальным, поэтому
алгоритм становится очень сложным на практике.
), например, лайков,
комментариев и репостов, каждое для разного значения k, которые все
должны каким-то образом агрегировать до одного значения Vijt. Ещё
больше усложняет ситуацию то, что для каждого человека в Facebook
есть тысячи сигналов, которые нам нужно оценить, чтобы определить,
что для этого человека может оказаться наиболее актуальным, поэтому
алгоритм становится очень сложным на практике.
 ), которые мы можем использовать
для прогнозирования
), которые мы можем использовать
для прогнозирования  . Теперь, когда у нас
есть все прогнозы, мы можем объединить их в один результат. Для
этого необходимо несколько проходов для экономии вычислительной
мощности и применения правил, таких как разнообразие типов контента
(т. е. тип контента должен быть разнообразным, чтобы пользователи
не видели повторяющиеся типы контента, такие как несколько видео,
одно за другим), зависящих от начального рейтингового балла.
Во-первых, к каждому посту применяются определённые процессы
целостности. Они предназначены для определения того, какие меры по
обнаружению целостности, если таковые имеются, необходимо применить
к историям, выбранным для ранжирования. Затем на этапе 0
запускается облегчённая модель, чтобы выбрать примерно 500 наиболее
релевантных публикаций для Хуана, которые имеют право на
ранжирование. Это помогает нам ранжировать меньше историй с высокой
степенью запоминания на более поздних этапах, чтобы мы могли
использовать более мощные модели нейронных сетей. Первый проход это
основной проход для подсчёта очков, где каждая история оценивается
независимо, а затем все ~500 подходящих публикаций упорядочиваются
по количеству баллов. Наконец, у нас есть проход 2, который
является контекстным проходом. Здесь добавлены контекстные функции,
такие как правила разнообразия типов контента, чтобы помочь
разнообразить ленту новостей Хуана.
. Теперь, когда у нас
есть все прогнозы, мы можем объединить их в один результат. Для
этого необходимо несколько проходов для экономии вычислительной
мощности и применения правил, таких как разнообразие типов контента
(т. е. тип контента должен быть разнообразным, чтобы пользователи
не видели повторяющиеся типы контента, такие как несколько видео,
одно за другим), зависящих от начального рейтингового балла.
Во-первых, к каждому посту применяются определённые процессы
целостности. Они предназначены для определения того, какие меры по
обнаружению целостности, если таковые имеются, необходимо применить
к историям, выбранным для ранжирования. Затем на этапе 0
запускается облегчённая модель, чтобы выбрать примерно 500 наиболее
релевантных публикаций для Хуана, которые имеют право на
ранжирование. Это помогает нам ранжировать меньше историй с высокой
степенью запоминания на более поздних этапах, чтобы мы могли
использовать более мощные модели нейронных сетей. Первый проход это
основной проход для подсчёта очков, где каждая история оценивается
независимо, а затем все ~500 подходящих публикаций упорядочиваются
по количеству баллов. Наконец, у нас есть проход 2, который
является контекстным проходом. Здесь добавлены контекстные функции,
такие как правила разнообразия типов контента, чтобы помочь
разнообразить ленту новостей Хуана. . Обратите внимание, что у этой линейной
формулировки есть преимущество: любое действие, в котором редко
участвует человек (например, предсказание по лайкам, которое очень
близко к 0), автоматически получает минимальную роль в рейтинге,
поскольку
. Обратите внимание, что у этой линейной
формулировки есть преимущество: любое действие, в котором редко
участвует человек (например, предсказание по лайкам, которое очень
близко к 0), автоматически получает минимальную роль в рейтинге,
поскольку 






 Эго-граф Хоппера
Эго-граф Хоппера