Инструкция по диагностике проблем в работе баз данных в
случае аварии.

Привет. У каждого на работе иногда случаются чёрные дни. Для
меня такими днями являются аварии в работе сервисов, приводящие к
недоступности систем для конечных пользователей. По счастью, такое
происходит нечасто, но каждый такой случай заставляет меня долго
рефлексировать над вопросами что мы сделали не так.
После одной из аварий я поймал себя на мысли, что диагностика
причины недоступности сервиса заняла слишком много времени.
Инженеры, задействованные в разрешении инцидента, действовали не
совсем скоординированно: проверяли одни и те же гипотезы и тратили
время на изучение совсем уж фантастических вариантов. В
квалификации ребят никакого сомнения у меня нет, поэтому в рамках
рефлексии я списываю это на стрессовую ситуацию аварии.
Чтобы в следующий раз диагностика и устранение причин аварии
происходили быстрее, мы совместно с DevOps-инженером Алексеем
Поповым решили написать план эвакуации при пожаре: пошаговую
инструкцию, которую можно было бы использовать для быстрого
исследования инцидента.
Последняя проблема касалась работы базы данных и взаимодействия
web-приложения с базой. Поэтому инструкция касается диагностики
именно базы данных. Также хочу отметить, что эта схема не истина в
последней инстанции, а всего лишь наш опыт, перенесенный на бумагу.
Мы намеренно не стали включать слишком экзотические причины аварии,
поскольку схема становится слишком громоздкой и нечитаемой.
Я буду признателен за комментарии и описания аналогичных
проблем, которые происходили у вас.
Итак, при возникновении аварии обычно достаточно просто
диагностировать, возникла ли проблема в приложении, на стороне базы
данных или при взаимодействии базы данных и приложения. А вот что
делать дальше, зачастую непонятно и тут я предлагаю воспользоваться
следующей схемой:

Ниже я распишу каждый шаг схемы и инструментарий, применяемый
нами для каждого шага.
Шаг 1. Проверка нагрузки ядер процессоров на сервере БД (Load
Average)
В большинстве случаев внешним проявлением проблемы в работе базы
данных является возросшая нагрузка на ядра процессоров сервера БД.
Лучшей метрикой для диагностирования этого факта я считаю LOAD
AVERAGE. При этом мне больше нравится эта метрика в пересчете на
ядро процессора сервера БД. LA (Load Average) на ядро более 1
плохо. Это значит, что запрос к БД ожидает какое-то время, прежде
чем выполниться.
Для отслеживания этой метрики мы применяем систему мониторинга
Zabbix с возможностью настройки оповещений в различные каналы.
Пример такой метрики при возникновении аварии:

Шаг 2. Нагрузка на ядро процессора (LA) изменилась более чем на
30 % по отношению к тому же времени того же дня недели?
При возникновении серьёзной аварии LA обычно растёт
лавинообразно. Тем не менее, даже повышение на 30 % признак
какой-то аномалии. Если рост LA заметен и превышает заданный лимит,
то самое время перейти к шагу 3 и проверить количество подключений
к базе данных. Если же роста LA нет, то лучше переходить к шагу
27.
ШАГ 3. Проверка количества подключений приложений к БД и
динамика его роста
Это ещё один маркер, который даёт чёткое понимание, что с БД
что-то пошло не так. Тут в большей степени интересна динамика роста
количества подключений к базе.

В качестве инструмента мониторинга используем всё тот же Zabbix.
Максимально разрешенное количество подключений к БД можно узнать,
выполнив команду SHOW_MAX_CONNECTIONS.
Шаг 4.Количество подключений к БД резко выросло за короткий
промежуток времени?
Скорее всего, вы заметите, что количество подключений либо резко
возросло, либо постепенно росло, уперлось в лимит и стало ровным. В
зависимости от этого нужно переходить либо к шагу 7, либо к шагу
5.

Шаг 5. Увеличить количество подключений, поставив пулер
подключений
Если вы видите, что количество подключений драматически не
изменялось, а постепенно росло и достигло разрешенного лимита, то
дело, скорее всего, в том, что нагрузка на БД превысила лимит и
запросы стоят в очереди, ожидая освобождения подключения. Быстрое
решение в этом случае увеличить количество подключений. Это можно
сделать в конфиге базы данных с помощью атрибута
MAX_CONNECTIONS. Не стоит этим увлекаться, потому что
большое количество подключений это не нормально. Такую меру нужно
применять в качестве экстренного лекарства, чтобы выиграть
некоторое время для дальнейшего изучения проблемы.
Обращаю внимание, что если у вашей БД есть одна или несколько
реплик (не дай бог еще и каскадных), то в первую очередь необходимо
поменять количество подключений на этих репликах, причем начиная с
последней в каскаде. И только потом на мастере.
Если же приложение работает всё-таки оптимально, то стоит
задуматься над использованием пулера подключений (самый
распространенный PGBouncer). Этот сервис берёт на себя управление
подключениями и делает это достаточно эффективно. Приложение для
взаимодействия с БД будет обращаться к PGBouncer, а тот в свою
очередь будет перенаправлять запрос к БД через свои подключения.
Подробнее об этой технологии можно почитать тут:
http://personeltest.ru/aways/habr.com/ru/company/okmeter/blog/420429/.
Я также встречался с ситуацией, когда пулер подключений
(PGBouncer) был установлен, но в его работе возникали проблемы.
Стоит обратить внимание на лимит подключений к БД в самом пулере.
Также у PGBouncer (не знаю, как в аналогах) есть одна особенность
реализации: при установлении подключения к БД открывается файловый
дескриптор. Поэтому на нагруженных крупных экосистемах с большим
количеством сервисов и баз, использующих централизованный
PGBouncer, может возникнуть проблема с ограничением числа
одновременно открытых файловых дескрипторов на уровне операционной
системы
Шаг 7. Проверка наличия блокировок и запросов в ожидании в базе
данных
Это одна из частых причин замедления работы БД. Зачастую при
крупных миграциях может возникнуть длительная блокировка нескольких
строк в таблицах базы данных. В результате запросы, которые
обращаются к этим строкам, не могут выполниться и остаются в
ожидании (занимая при этом подключение). Через непродолжительное
время большая часть подключений может оказаться занятой, и уже все
запросы (даже те, которые не затрагивают заблокированные строки)
начинают томиться в ожидании.
Способ проверки этой гипотезы динамика с количеством запросом к
БД в статусе "IDLE IN TRANSACTION". Мы используем механизм
периодического замера количества запросов в этом статусе, с выводом
соответствующего графика в Grafana.

Шаг 8. В БД много блокировок и запросов в ожидании
Если ответ на этот вопрос да, то мы уже на полпути к решению.
Отправляемся пробовать быстрое решение (шаг 9). Если же большого
количества блокировок (повторяюсь большого
количества! Блокировки это нормально, если их стандартное
количество) и запросов В ожидании не наблюдается, то переходим к
шагу 11.
ШАГ 9. Убить все блокировки в БД
Иногда такая мера приводит к быстрой победе. Если, к примеру,
транзакция, в ходе которой открыт запрос, была инициирована
сервисом, в работе которого возникла проблема, и при этом сервис
уже был перегружен/переразвёрнут, то может помочь простое
устранение блокировок.
Сделать это можно устранив процесс, вызвавший блокировку
pg_terminate_backend(pid);.
Шаг 10. Ситуация исправилась?
Итак, мы устранили все блокировки в базе данных. Через несколько
минут ситуация может прийти в норму. Тогда мы молодцы. Или не
прийти тогда переходим к шагу 37.
Шаг 11. Получение списка выполняемых запросов, отсортированных
по частоте и стоимости
Для этого необходимо выполнить команду
PG_STAT_STAEMENTS. При вызове этой утилиты мы соберём
журнал всех выполняемых в БД запросов и сможем оценить, какие из
них на текущий момент времени занимают больше всего ресурсов (по
частоте и стоимости выполнения). Рекомендуется сбросить ранее
накопленную статистику командой PG_STAT_STAEMENTS_RESET
() и начать её собирать заново, уже во время инцидента.
Таким образом мы получим чистую статистику со стоимостью запросов
уже на этапе инцидента.
Шаг 12. Изучить SlowLog (запросы, которые выполняются дольше
критичного времени)
Эта операция, возможно, сразу даст ответ, какие запросы нужно
оптимизировать, без более трудоемкого анализа результатов
PG_STAT_STATEMENTS. Обычно мы оба шага (11 и 12)
выполняем параллельно, чтобы сразу получить представление о
нагрузке на БД. Еще один плюс SlowLog получив выборку
из него за более длительный период времени, мы сможем вычленить
запросы, которых раньше не было (т. е. они выполнялись быстро), но
в какой-то момент стали выполняться медленно, скорее всего из-за
аварии.
Шаг 13. Есть дорогие запросы, которые ранее выполнялись
быстро?
На этом шаге главной проблемой является определение, с какой
скоростью выполнялись запросы ранее (до аварии). Утилиты
SlowLog и PG_STAT_STATEMENTS дадут
понимание о скорости выполнения запросов сейчас. Но чтобы найти
проблемный запрос, нужно понимать, с какой скоростью запросы
выполнялись ранее. Для этой цели я рекомендую использовать
дополнительные утилиты PGHero или NewRelic. Это достаточно удобные
инструменты, которые позволяют понять динамику скорости выполнения
запросов.
Если видна деградация в скорости выполнения каких-то
определенных запросов, то переходим к шагу 14. Если зафиксировать
снижение скорости выполнения какого-то запроса не удалось, то
переходим к шагу 30.
Шаг 14. Проверка плана по дорогим запросам
Если вам удалось выделить конкретный запрос с ярко выраженной
негативной динамикой скорости выполнения, то следующий шаг
детальный анализ запроса посредством утилиты EXPLAIN
ANALYZE. Подробно о том, как работает эта команда и как
интерпретировать результаты её выполнения, можно ознакомиться тут:
https://thoughtbot.com/blog/reading-an-explain-analyze-query-plan.
Шаг 15. Требуется новый индекс?
Исходя из анализа результатов выполнения командыEXPLAIN
ANALIZE можно сделать вывод о том, нужен ли новый индекс,
или достаточно существующих. Если новый индекс нужен, то добро
пожаловать на шаг 29. Если индексов достаточно переходим к шагу
16.
Шаг 16. Индекс есть, но не используется (а раньше
использовался)
Такая ситуация может возникнуть в любой момент. При выборе
способа обработки данных планировщик запросов опирается на
накопленную статистику содержимого таблиц в базе данных. И в
какой-то момент времени статистика может начать давать неверные
результаты, и тогда планировщик решит не использовать индекс, хотя
по-хорошему он должен был бы использоваться. Это также может
случиться после крупных миграций данных или при превышении
какого-то объёма данных в таблице, при котором планировщик сделает
выбор в пользу последовательного перебора вместо использования
индекса.
В любом случае, если вы видите, что индекс создан и есть, но при
этом EXPLAIN ANALYZE говорит о том, что он не
используется, то переходим к шагу 17. Если же индекс используется
переходим к шагу 20.
ШАГ 17. Обновление статистики таблиц базы данных
Простая операция, которая может спасти положение. Для сбора
статистики большей точности достаточно выполнить команду
ANALYZE илиset default_statistics_target = 500;
ANALYZE . 500 это количественный коэффициент образца
таблицы, который PostgreSQL выбирает для расчёта статистики.
Подробнее о механизме работы статистики и карт видимости можно
почитать тут:
https://postgrespro.ru/docs/postgrespro/10/routine-vacuuming.
Шаг 18. Ситуация исправилась?
Если после обновления статистики содержимого таблиц скорость
выполнения запросов нормализовалась ура-ура, мы молодцы. Если
проблема наблюдается по-прежнему переходим к шагу 19.
Шаг 19. Пересоздание индекса
Напомню, что у нас есть проблемный запрос, который ранее
выполнялся быстро, а теперь вдруг неожиданно стал выполняться
медленно. Для ускорения выполнения запроса в БД существует индекс,
однако он не применяется планировщиком запросов. Обновление
статистики не помогло.
Пересоздаем индекс. Сделать это можно командой
REINDEX (подробнее читайте тут:
https://postgrespro.ru/docs/postgrespro/9.5/sql-reindex).
Переходим к шагу 31.
Шаг 20. Профиль работы с кешем (Hit/Miss)
Запрос вдруг неожиданно начал тормозить, но при этом индекс
используется. Следующий шаг проверить работу кеша базы данных. Для
этого лучше всего подойдёт метрика Hit/Miss количества записей,
полученных запросом из кеша или выбираемых из базы данных с нуля.
Мы для этих целей используем Zabbix.

Если вы по аналогичной метрике делаете вывод, что профиль работы
с кешем изменился, то переходим к шагу 21. Иначе нас ждёт шаг
22.
Шаг 21. Расширить размер буфера БД
Эта мера даст нам какое-то время, но только том в случае, если
можно расшириться на значительный объём. По сути, мы какую-то часть
данных БД перегоним в кеш, что ускорит доступ к этим данным.
Расширение размера буфера кеша БД определяется параметром
shared_buffers в конфиге базы.
Будьте внимательны: расширение размера буфера кеша потребует
перезагрузки БД. Впрочем, если у вас и так всё безбожно тормозит,
это не должно стать большой проблемой.
Шаг 22. Изменились параметры запроса?
Иногда может быть так, что скорость выполнения запроса снижается
изза дополнительных параметров, которые выступают в качестве
условия выборки данных. Например, если в роли фильтра выступал
какой-то атрибут, идентификаторы которого перечислялись в предикате
запроса (where atribut_id in (id1, id2, id3)), и
какой-то момент вместо 23 идентификаторов стали передаваться
несколько сотен, то очевидно, что скорость выполнения запросов
упадёт. Возможно, понадобится создание нового индекса, который
учитывал бы такой вариант выборки данных. Такое может случиться
после очередного релиза смежной системы, читающей данные из вашего
сервиса.
Чтобы идентифицировать подобную ситуацию, достаточно вытащить из
логов аналогичный запрос, который был несколько дней назад, и
сравнить его с таким же запросом сейчас. Обычно разницу в
драматическом количестве параметров запроса видно сразу.Если вы
нашли такую ситуацию переходим к шагу 26. Иначе к шагу 23.
Шаг 23. Изменилось ли количество и размер временных
файлов?
В процессе выполнения запроса база данных генерирует временные
данные, используемые для получения данных в нужном формате. Обычно
для этого используется оперативная память, объём которой
определяется параметром Work_Mem, настраиваемым в
конфигурации базы данных. Если этой памяти недостаточно, база
данных может создавать временный файлы, в которые записываются
промежуточные данные для выполнения запроса. Для определения такой
ситуации мы используем метрику по количеству временных файлов от
всё того же Zabbix.
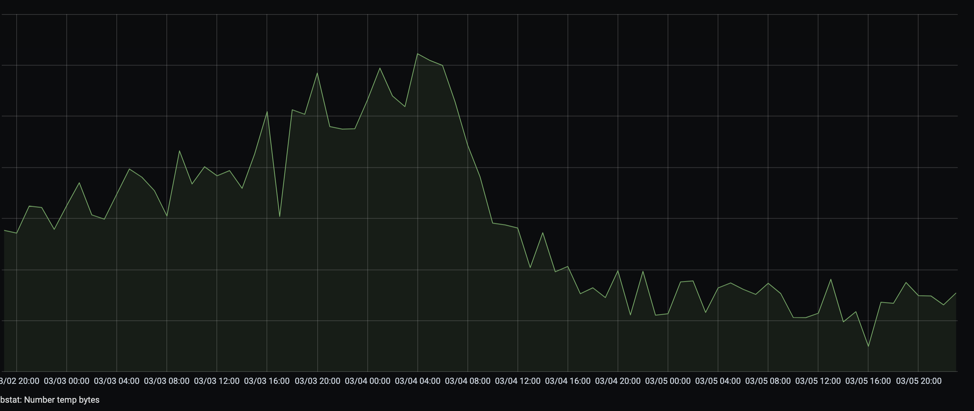
Если вы увидели, что количество временных файлов, создаваемых
базой данных, резко выросло, то переходим к шагу 25. Иначе к шагу
24.
Шаг 24. Пересоздать индекс
Пересоздаём индекс. Сделать это можно командой
REINDEX (подробнее можно почитать тут:
https://postgrespro.ru/docs/postgrespro/9.5/sql-reindex).
Переходим к шагу 31.
Шаг 25. Увеличить размер Work_mem, либо оптимизировать запрос
на стороне приложения
Если вы увидели, что количество создаваемых временных файлов
резко увеличилось, тот в качестве быстрого (но опасного!) решения
можно попробовать увеличить размер доступной памяти для обработки
временных данных. Управляет этим атрибут Work_mem,
настраиваемый в конфигурации базы данных.
Подчеркну, что это не исправление ситуации, а просто выигрыш
времени для более системного решения. Параллельно необходимо
анализировать запрос и способы его оптимизации.
Переходим к шагу 31.
Шаг 26. Создать новый индекс с учётом новых входных
параметров
Быстрее всего в этой ситуации будет создание нового индекса
(возможно, составного), который облегчил бы выборку данных с учётом
новых входных параметров запроса. Если это возможно, то переходим к
шагу 27. Иначе к шагу 28.
Шаг 27. Создать новый индекс с учётом новых входных параметров
запроса
Тут всё понятно: запрос идентифицирован, новый набор атрибутов
также понятен создаём новый индекс. При этом рекомендую обновить
статистику таблиц, чтобы новый индекс сразу начал применяться
планировщиком запросов. Далее переходим к шагу 31.
Шаг 28. Исправление самого запроса на стороне приложения,
исключение новых параметров
Вероятно, в ряде случаев проще и быстрее будет сразу же
оптимизировать запрос на стороне приложения (либо откатить
изменения, приведшие к изменению параметров запроса). Переходим к
шагу 31.
Шаг 29. Создать новый индекс
В том случае, если по результатам EXPLAIN ANALYZE
пришло понимание, что базе нужен новый индекс, то проще всего его
досоздать. Это можно сделать командой CREATE INDEX с
указанием параметра CONCURRENTLYдля неблокирующего
построения (подробнее можно почитать тут:
https://postgrespro.ru/docs/postgresql/11/sql-createindex).
Далее переходим к шагу 31.
Шаг 30. Проверка влияния дополнительных факторов
(взаимодействие с жёстким диском, сторонние процессы на сервере,
работа других БД)
Возможно, проблема с производительностью вызвана не самой нашей
базой данных, а внешними факторами. Поэтому важно проверить и
отсечь их влияние. В первую очередь это могут быть:
-
работа жёстких дисков/систем хранения данных;
-
нагруженные запросы на другие базы данных, находящиеся на том же
сервере что и ваша;
-
сторонние процессы, выполняемые на сервере БД (например, работа
антивируса);
-
создание репликационных баз данных, в процессе чего происходит
создание слепка данных с вашего мастера;
-
сетевые проблемы и потери при взаимодействии приложения и базы
данных.
Если таковые факторы найдены, то постарайтесь их устранить и
переходите к шагу 31.
Шаг 31. Ситуация исправилась?
Ситуация стабилизировалась и проблема решена? Мы молодцы! В
противном случае пора собирать всю королевскую рать и обращаться к
DB-администратору.
Шаг 32. В БД много блокировок и запросов в ожидании?
По аналогии с Шагом 8 - проверяем динамику количества запросов к
БД в статусе "IDLE IN TRANSACTION". Мы используем механизм
периодического замера количества запросов в этом статусе, с выводом
соответствующего графика в Grafana. Подчеркну, что блокировки
нормальное явление, они периодически будут возникать. Но вот если у
вас произошло резкое увеличение количества блокировок, то
переходите к шагу 37. Если же диагностировать увеличение количества
блокировок и запросов в ожидании не удалось, то переходите к шагу
33.
Шаг 33. Проверка логов PG Bouncer и логов приложений при
подключении к PG Bouncer
Иногда приложение обращается к базе данных не напрямую, а через
специализированный пулер подключений (самый распространенный
PGBouncer). Но помимо многочисленных преимуществ он всё-таки
представляет собой ещё одну точку отказа. Поэтому если в базе
данных не наблюдается повышенного LA, а блокировок и запросов в
ожидании нет, то рекомендуется посмотреть внимательно на журналы
пулера подключений и приложения, которое к нему подключается.
Переходим к шагу 34.
Шаг 34. Есть проблемы с PGBouncer?
Если в журналах есть ошибки, то рекомендуется перейти к шагу 35.
Иначе переходим к шагу 36.
Шаг 35. Исправление проблемы с работой PGBouncer/подключение
приложения напрямую к БД, в обход PGBouncer
Если проблему в работе PGBouncer можно быстро исправить (она
понятна, и очевидно, как её можно решить), то сделайте это (точных
рекомендаций дать не могу, зависит от типа проблемы). Если же это
невозможно сделать за короткое время, то рекомендую попробовать
подключить приложение в обход PGBouncer, напрямую к базе данных.
При этом стоит увеличить количество разрешенных подключений к БД,
поскольку приложение обычно не так эффективно управляет ими, как
PGBouncer.
Это временная мера для быстрого восстановления доступности
сервиса. Это не решение проблемы!
Переходим к шагу 31.
Шаг 36. Требуется консультация аналитика
Если вы дошли до этого пункта, то это означает, что случай
нетипичный, и для устранения поломки нужно привлечь узкопрофильного
специалиста Database analyst. Рекомендую для быстрого погружения в
проблему транслировать ему сразу же все журналы и метрики, которые
вы изучали на пути к этому пункту.
Шаг 37. Было ли недавнее изменение схемы данных БД?
Ситуация, когда неожиданно, без объявления войны в базе данных
растёт аномальное количество блокировок и запросов в ожидании,
крайне редка. Чаще всего это следствие релиза или миграции с
изменением схемы данных БД. Если такое было в последнее время, то
переходим к шагу 45. Если изменений в схеме данных не было, то
переходим к шагу 38.
Шаг 38. Проверка журналов БД (или PG_STAT_ACTIVITY) для
выявления запроса, вызвавшего блокировку
Блокировки инициируются какими-то запросами. Поэтому следующим
шагом важно определить запрос, при выполнении которого возникли
самые частые блокировки. Сделать это можно на основе журналов БД
либо при помощи утилиты PG_STAT_ACTIVITY.
Шаг 39. Выявление сервисаинициатора запроса, вызвавшего
блокировку
После того, как мы выявили запрос, вызвавший блокировку, надо
определить сервис или приложение, которое инициировало этот запрос.
Проще всего это сделать на основе журналов БД.
Шаг 40. Сервис, инициировавший запрос, работает штатно?
Иногда возникают ситуации, когда для при обращении к базе
данных, приложение открывает транзакцию, выполняет какую-то первую
операцию (например, Select для получения слепка
данных), затем обрабатывает данные по своей внутренней логике и
записывает обновленные в рамках той же транзакции. В этом случае,
при возникновении проблем в работе такого приложения может
возникнуть ситуация, когда при открытии транзакции не происходит
последующих операций и закрытия транзакции. В результате возникают
блокировки и зависшие в ожидании запросы.
Необходимо проверить приложение, инициировавшее запросы, которые
приводят к блокировкам. Если проблемы в работе сервиса,
инициировавшего блокирующий запрос, найдены, то переходим к шагу
43. Иначе добро пожаловать на шаг 41.
Шаг 41. Были ли недавно релизы сервиса, инициировавшего
блокирующий запрос?
Если релизы сервиса, который инициирует блокирующие запросы,
совпадают по времени с началом проблемы в БД, то неплохой мыслью
будет откатить последний релиз. Это может помочь (переходим к шагу
43).
Если релизов не было, то переходим к шагу 44.
Шаг 42. Диагностика и починка сервиса, инициировавшего
блокирующие запросы
Мы определили, что запросы, вызывающие блокировки, генерирует
сервис, в котором на данный момент также возникли проблемы в
работе. Гипотеза состоит в том, что ошибки в работе сервиса
приводят и к ошибкам в работе БД. Целесообразно будет откатить
последний релиз (если он был) или сосредоточиться на починке этого
сервиса. Если мы приведем сервис в нормальное состояние, то,
вероятно, и база данных начнёт работать в соответствии с
ожиданиями.
После починки сервиса переходим к шагу 31.
Шаг 43. Откат последнего релиза
Для ускорения решения проблемы проще всего откатить последний
релиз сервиса, инициирующего проблемные запросы. В этом случае мы
сразу увидим, исчезла проблема или нет. После этой операции
переходим к шагу 31.
Шаг 44. Требуется консультация аналитика
Если вы дошли до этого пункта, то это означает, что случай
нетипичный, и для устранения поломки нужно привлечь узкопрофильного
специалиста Database analyst. Рекомендую для быстрого погружения в
проблему транслировать ему сразу же все журналы и метрики, которые
вы изучали на пути к этому пункту.
Шаг 45. Откатить миграцию возможно?
Мы выяснили, что в проблемной базе данных недавно был релиз,
изменивший схему данных. Быстрее и проще всего откатить миграцию
изменения схемы. Если это возможно, то переходим к шагу 46. Если
невозможно к шагу 47.
Шаг 46. Откатить миграцию
Необходимо откатить последнюю миграцию или миграции. Проще всего
это сделать через утилиту Alembic, если вы её применяете. Затем
переходим к шагу 31.
Шаг 47. Ожидать завершения миграции
Лучше всего дождаться завершения миграции. Меньше проблем будет
в дальнейшем. Затем переходим к шагу 31.
Заключение
Надеюсь, эта схема поможет вам в трудной ситуации (например, во
время аварии). Она собрала значительную часть наших болячек и
травмоопасного опыта.
Хочу выразить огромную благодарность Алексею Попову за помощь в
подготовке статьи. Без его рецензии и консультаций статья была бы
не столь полной и точной.









 рис. 1 Архитектура сервиса API Management
рис. 1 Архитектура сервиса API Management
 рис. 2
рис. 2










 Рис. 3
Рис. 3
 Рис. 4
Рис. 4
 Рис. 5
Рис. 5
 Рис. 6
Рис. 6















































") Один делает, другой смотрит, третий
фотографирует, огнетушитель придерживает дверь - настоящая
командная работа =)
Один делает, другой смотрит, третий
фотографирует, огнетушитель придерживает дверь - настоящая
командная работа =)

























{kind=link}
{kind=link}
{kind=link}
{kind=link}