Об игре
Club Bing это набор игр, в которые можно было играть
в 2007-2012 годах. Все игры были связаны со словами, в них нужно
было играть онлайн, чтобы зарабатывать очки, которые можно было
тратить в онлайн-магазине для покупки призов. Одна из игр
называлась Chicktionary. Цель игры: использовать 7 слов, чтобы
составить как можно больше слов.
Буквы, которые можно использовать, указаны внизу, а слова, которые
нужно составить это маленькие яйца сверху. Всегда есть одно слово
из семи букв.
В первые дни после выпуска этих игр можно было заработать множество
призов. Хотя сайт позволял получать на один адрес только один приз,
можно было запросто добавить номер квартиры к адресу собственного
дома и создать множество уникальных адресов:
- 123 Main St. Apt #1, Anywhere, YZ, USA
- 123 Main St. Apt #2, Anywhere, YZ, USA
- 123 Main St. Apt #3, Anywhere, YZ, USA
Очевидно, наилучшим соотношением стоимости к очкам обладал
контроллер XBox, поэтому можно было оставить компьютер набирать
очки на нескольких аккаунтах, а затем тратить все очки на покупку
контроллеров. На одном форуме был пост с фотографией парня,
получившего почтой примерно 100 контроллеров за один день. Он сразу
же выложил их на Ebay и продал.
Другими
призами были:
- Телескопы
- Проигрыватель
- Xbox
- Наручные часы Michael Kors
- Одежда North Face
- Надувной каяк
На всех призах была маркировка Bing.
Microsoft выпустила эту игру для рекламы своего поискового движка
Bing. Каждый раз, когда ты вводил ответ, браузер
выполнял его поиск в отдельном фрейме. Вероятно, это позволяло
убедить людей больше пользоваться Bing, а также увеличивало
количество пользователей, якобы использующих Bing. А этот
показатель позволял Microsoft требовать больше денег у
рекламодателей, желавших появляться в результатах поиска Bing. Я
подсчитал, что все играющие в Chicktionary скриптеры составляли
2-4% от всех поисковых запросов Bing. К тому же я провёл небольшие
вычисления, сравнив доход и ежемесячное количество поисковых
запросов Google и Bing, и выяснил, что Microsoft получала от игры
довольно неплохую прибыль. Иллюзия того, что
Bing стал популярнее, вероятно, принесла больше
рекламных долларов, чем стоили призы.
Скриптинг
Существовало несколько скриптов для автоматической игры, часто в
них использовался
AutoHotKey. Я написал собственный скрипт на VB.Net,
у него был встроенный браузер. Я назвал его Chicken в честь
Chicktionary, а ещё потому, что в моей стране был забавный
телевизионный скетч о курице.
Так как игра была написана на Flash, было не очень легко
взаимодействовать с элементами в DOM, поэтому игровой процесс
состоял из сочетания:
- Взаимодействий DOM
browser.Go(<URL>)- Скриншотов и поиска пикселей
- Windows API для имитации ввода и нажатий мыши
В Microsoft работают не дураки. Они знали о
существовании хакеров. Они отлично справлялись с выявлением
пользователей, слишком быстро решающих головоломки, и обнуляли их
призы. Кроме того, они усовершенствовали распознавание дубликатов
адресов доставки. И, разумеется, они использовали
капчу.
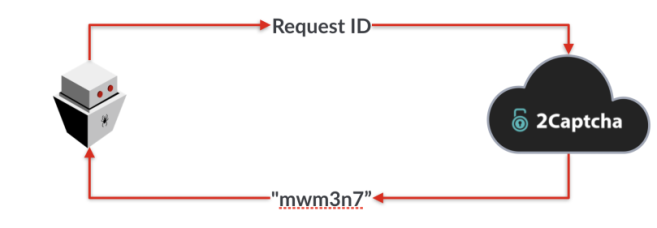
Captcha
Знаете, такие кривые буквы, которые нужно вводить, чтобы доказать,
что ты человек:
Можно подумать, что они бы полностью препятствовали автоматизации,
но это не так. Существует больше десятка
онлайн-сервисов решения captcha. Их цена
составляет примерно
1
доллар за 500 решённых капч. Club Bing отображал капчу через
каждые четыре игры. За каждую игру ты получал 20 билетов (если
ввести все слова правильно), а Xbox стоил 55000 билетов.
(55000 билетов / Xbox) * (1 игра / 20 билетов) *
(1 капча/ 4 игры) * (1 доллар / 500 капч) = 1,375 доллара за
Xbox
Довольно выгодная сделка. Кроме того, для этого понадобится 55
дней, потому что в день можно зарабатывать только по 1000 билетов.
Но можно завести несколько разных аккаунтов, чтобы через 55 дней
получить несколько консолей Xbox. С более дешёвыми призами всё было
ещё быстрее: видеоигра стоила 5000 билетов.
Существование сервисов для решения капч объясняет, почему читерство
было настолько популярным: эти сервисы имеют партнёрские программы.
Скрипт, выполнявший решение, отправляет вместе с запросом
партнёрский код, благодаря чему когда пользователь платит, партнёр
получает часть денег. Поэтому у скриптописателей была мотивация
распространять свои скрипты и писать самые качественные.
Капча с котами
Примерно в 2010 году Microsoft заменила алгоритм капчи с кривых
букв на
Asirra. Asirra выглядит вот так:
На каждом из этих изображений есть кошка или собака. Чтобы решить
задачу, нужно правильно определить 12 из 12 кошек или 11 из 12
дважды подряд.
Когда Club Bing перешёл на эту капчу, всё сообщество читеров Club
Bing приостановило свою деятельность. Я приступил к работе.
Первым делом я попробовал отправлять сервису решения капч кошек и
собак. В 2010 году эти сервисы
не обладали мощными
средствами распознавания изображений. Это были просто
люди из Бангладеша, отвечавшие на ваши запросы.
Я попытался прикинуть, сколько они зарабатывали:
(2000 рабочих часов / год) * (1 капча/ 5 секунд)
* (1 доллар / 500 капч) = 2880 долларов / год при полной
занятости.
Вероятно, половина оставалась у владельца веб-сайта, потому что,
знаете ли,
капитализм, то есть работники зарабатывали
примерно столько же, сколько администратор на ресепшене, если
верить
случайно выбранному сайту.
Я захотел узнать, смогут ли они решать Asirra. Вот изображение,
которое я отправил:
Используемый мной сервис
de-captcher вернул такой ответ:
cat or dog?
Строго говоря, он был верным, но меня не устраивал. Я
отправил картинку ещё несколько раз:




Чтобы получить полезный ответ, потребовалось четыре попытки:
dog
Это не предвещало ничего хорошего. Во-первых, мне нужно было 12
правильных ответов. Если предположить, что каждый раз на поиск
работника в Бангладеше, способного сделать всё правильно,
потребуется 4 попытки, то это составит 48 запроса. Цена Xbox только
увеличилась до 66 долларов! А если они ошибутся хотя бы один раз,
мне придётся удвоить эту сумму. Немыслимо! Мне нужно было решение
получше.
Почему бы просто не использовать глубокое обучение?
Не забывайте, что дело происходило в 2010 году. Глубокое обучение
(deep learning) тогда было развито совсем не так хорошо, как
сейчас.
В этой статье Стэнфордского университета
говорится, что авторам удавалось использовать машинное обучение для
правильного решения головоломок всего примерно в 10% случаев.
Совершенно неприемлемо! (В основном они просто замечали зелёный
цвет, потому что собаки лежат на лужайке с большей вероятностью,
чем кошки.)
Также Microsoft использовала схему
token-bucket, которая временно блокировала
пользователя, если он слишком много раз подряд ошибается. Хотя
token-bucket не выполнялась на тестовом сервера Asirra, её
применяли в Club Bing.
Harvest: новая надежда
Исследовательский отдел Microsoft создал веб-сайт для демонстрации
новой технологии Asirra.
На нём была тестовая площадка, на которой можно было проверить
работу сервиса, она сообщала, если вы решали всё правильно. Снова
взглянем на изображение:
Видите эту маленькую кнопку Adopt me (Приюти меня)? Она там есть,
потому что Asirra была результатом партнёрства с
petfinder.com. Petfinder это сервис поиска новых
хозяев для домашних питомцев, у которого есть большие списки
животных. При нажатии на кнопку Adopt me браузер переходит к
профилю этого животного. Разумеется, в профиле указан его вид:
кошка или собака.
Повторюсь,
в Microsoft работают не дураки. Они
знали, что кто-то попробует нажимать на
Adopt me под
каждым изображением и получить правильный ответ. Поэтому они делали
недействительными саму задачу капчи
и все ссылки
на профили после первого нажатия на кнопку Adopt me. То есть можно
было получить только один ответ.
Я решил написать программу, которая сделает это много раз и
сопоставит каждое изображение с числом:
- 0: неизвестно
- 1: собака
- 2: кошка
Я назвал её Harvest (уборка урожая), чтобы продолжить тему куриц и
сельского хозяйства.
Каждая попытка занимала довольно мало времени, но я не знал,
сколько животных мне нужно узнать. На веб-сайте Asirra
утверждалось, что их 3,1 миллиона. Но на самом ли деле это так?
Обратный парадокс дней рождения
Многим людям известен
парадокс дней рождения: несмотря на то, что в
году 365 дней, достаточно собрать в одной комнате всего 22
человека, чтобы получить вероятность 50 на 50 того, что у двух из
них день рождения совпадает. Если
d=365, а
n=22, то вероятность можно посчитать так:
Обратность заключается в том, что если мы знаем, что 22 человека в
комнате дают вероятность 50 на 50 нахождения двух людей с
одинаковым днём рождения, то можно перевернуть уравнение и
вычислить, сколько дней в году.
Аналогично если я буду запрашивать серверы Asirra и отслеживать
каждое встреченное изображение, то как долго мне надо будет ждать
повтора? Я провёл примерно такой эксперимент (но на VB.Net, а не на
псевдокоде python):
def trial(): images_seen = [] while True: p = fetch_puzzle() for image in p.images(): if image in images_seen: break images_seen.append(image) return len(images_seen)
В каждой попытке я запрашивал задачи, пока не получу в попытке
повтор кошки или собаки. Я проводил множество попыток и отслеживал,
сколько изображений получалось до первого повтора. Затем я брал
медиану всех этих попыток, что позволяло мне определить, сколько
животных нужно увидеть, прежде чем вероятность повтора составит 50
на 50. Далее я вычислил в обратном порядке представленное выше
уравнение, чтобы получить количество изображений. И в самом деле,
мой ответ оказался достаточно близок к 3,1 миллиона.
Распределённая уборка урожая
Я записал свой скрипт на USB-флэшки и раздал их друзьям. Также я
написал программу слияния для объединения баз данных. Через каждые
один-два дня мои друзья возвращали мне свои флэшки, я запускал
Combine (комбайн, снова сельскохозяйственная тема) и записывал базу
на все флэшки, чтобы мои уборщики урожая не повторяли свою работу.
Уборщики нажимали Adopt me только на неизвестных изображениях,
поэтому поддержание актуальности распределённых баз данных
позволяло избегать повторной работы.
Можно ли ускориться?
Спустя 2-3 недели я собрал примерно 1,5 миллиона изображений. Я
приближался к этапу, когда задачу иногда можно было почти решить из
базы данных. Однако в базе данных присутствовали никогда не
заполняемые дыры, потому что ссылка по кнопке Adopt me была
сломана. Возможно, это животное уже забрали? Я добавил в базу
данных ещё один результат:
- 0: неизвестно
- 1: кошка
- 2: собака
- 3: нерабочая ссылка
Но есть и другой способ получить правильный ответ: отгадать!
Asirra давала знать, если пользователь решил задачу правильно. Я
погонял код какое-то время и замерил следующие показания:
adopt_time: сколько времени нужно для нажатия на
ссылку Adopt me, загрузку petfinder.com и получить ответ
кошка/собака.adopt_success_rate: вероятность того, что при
нажатии на Adopt me мы получим ответ, а не сломанную ссылку.guess_time: сколько времени нужно на то, чтобы
отправить случайную догадку и узнать, правильно ли решена задача.
(На это требовалось меньше времени, чем на загрузку
petfinder.com.)
Предположив, что соотношение кошек к собакам 50 на 50 (на самом
деле оно было ближе к 40 на 60, ну да ладно), я мог вывести
уравнение того, сколько животных я узнаю за секунду при помощи
adopt me:
adopt_learning_rate = 1 / adopt_time *
adopt_success_rate
Также можно было вычислить скорость узнавания при догадках. Если
количество неизвестных животных равно
n, то
вероятность угадать правильно равна 1 к 2
n. Но если я
угадаю их правильно, то узнаю все
n животных:
guess_learning_rate = n / guess_time * (1 /
2**n)
Приравняв эти два значения и вычислив
n, я смог
выяснить, что если знаю больше, чем 7 из 12 животных, то смогу
просто угадывать остальных, и это будет эффективнее, чем
adopt me. Я поместил этот код в уборщик урожая, и пару
недель спустя у меня и друзей была достаточная для работы база
данных.
Cats Be Gone: сервер решений
Microsoft Research проделал хорошую работу, но допустил пару ошибок
в протоколе. Во-первых, они не ограничили частоту запросов к
сервису. Благодаря этому и стала возможной уборка урожая.
Во-вторых, они неправильно реализовали proofs-of-work.
В процессе решения капчи есть три стороны:
- Поставщик captcha (например, Microsoft Asirra или Google
reCaptcha)
- Сервер captcha (например, Club Bing или другой веб-сервер)
- Пользователь captcha (например, игроки в Club Bing)
Один из способов
возможной реализации этой схемы: сервер
запрашивает у поставщика задачу и ответ. Затем сервер отправляет
задачу пользователю, пользователь решает её, и сервер подтверждает
решение.
Эта идея плоха по нескольким причинам:
- Теперь вся обработка производится на сервере. Что если сервер
реализует её неправильно?
- Если Asirra когда-нибудь захочет изменить протокол, то каждому
серверу придётся обновлять своей веб-сайт.
- Сервер-имитатор может стать самым эффективным уборщиком
урожая.
Вот как это работало на самом деле (на этот раз для удобства чтения
Asirra размещён посередине):
Теперь серверу не нужно знать подробностей работы системы. У него
даже нет ответа! Но здесь Microsoft совершила ошибку:
- В Club Bing было ограничение по частоте, поэтому нельзя было
совершать слишком много ошибок подряд, но такого ограничения не
было у Asirra.
- Отсутствовала проверка токена по IP-адресу.
Поэтому я с лёгкостью смог создать веб-сайт
cats-be-gone.kicks-ass.org, передававший действительные токены по
HTTP. Вот так:
(Хотя IP-адреса токенов не проверялись, проверялась их метка
времени. Токены были действительны только примерно один час. Сервер
Cats Be Gone (Кошки, брысь) на самом деле генерировал их заранее, и
всегда имел наготове 20 токенов, чтобы они были под рукой, когда
потребуются.)
Мы с друзьями успешно попользовались какое-то время этим сервером,
и в процессе сбора сервером новых ответов ситуация становилась всё
лучше.
Превращаем эту систему в бизнес (доход за всё время: 0
долларов)
Поговорив с друзьями, я подумал: Стоит открыть сервер для всех и
сделать из него бизнес! Люди уже привыкли к сервисам платы за
капчи, поэтому я решил, что они будут вместо этого платить мне. Я
решил брать по 1 доллару за 200 решений, это больше, чем
стандартная ставка 1 доллар/500, но у меня не было конкурентов. Я
выложил клиент на
один из самых популярных форумов для подобных
вещей и открыл Google Store для приёма платежей.
На форумах много болтали о том, что это какой-то способ обхода, а
не солвер, поэтому когда дойдёт время до покупки приза, полученные
билеты будут деактивированы. В прошлом уже были проблемы с
программами обхода капчи. Люди имели полное право на подозрения.
Поэтому я на какое-то время сделал сервис бесплатным. А после того,
как он начал доказывать свою действенность при отсутствии
альтернатив, у меня появились клиенты и 50 долларов на
потенциальных продажах.
Ого, да я теперь богач! Ага,
точно! Даже бангладешцы выгоднее тратили своё время.
Я обещал, что не буду обрабатывать оплату, пока не будет потрачено
10% платежа, и что верну деньги неудовлетворённым покупателям.
Однако всего спустя неделю я отменил все заказы, потому что защита
Microsoft полностью уничтожила мою идею.
Империя Microsoft наносит ответный удар
Всё это время Microsoft пыталась использовать различные способы,
чтобы победить моё читерство. Первым делом они попробовали
переименовать все изображения.
Это оказалось полной
катастрофой и мне пришлось начинать всё сначала, потому что
единственная привязка к кошке или собаке была по имени
файла!
Да не,
шучу, конечно. Я уже скачал все
изображения. 3,1 миллиона изображений по 1 МБ каждый это
всего 3,1 терабайта. Даже в те времена 3 терабайта были
вполне доступны. Это на меня никак не повлияло. Я знал, что они
могут попробовать что-то подобное, поэтому написал
уборщик-скачиватель.
Ещё они попытались изменять изображения. Случайным образом
выбирались 10-20 пикселей изображения и менялся их цвет. Этого было
бы более чем достаточно для поломки любого криптографического хэша,
который бы я мог использовать, например, сопоставление
SHA1(image), -> cat/dog. Но я его не использовал. Я
пользовался
MinHash.
Хэширование изображений, v1: MinHash
MinHash очень прост: выбираем десять пикселей изображения и
выполняем конкатенацию их значений. Вот и всё. Пока вы выбираете
одни и те же десять пикселей, результат будет постоянным.
Если Microsoft изменит пару пикселей, то это особо ни на что не
повлияет. Каковы шансы, что они совпадут? А если и совпадут, то
это, вероятно, будет всего 1 из 12 изображений, поэтому я могу
просто попробовать угадать ответ для него. В худшем случае придётся
получить ещё одну задачу и попробовать снова.
И это сработало. Я также сделал так, чтобы сервер обновлялся
самостоятельно при правильной догадке и база данных со временем
пополнялась.
Microsoft побеждает Cats Be Gone
Microsoft наконец ограничил частоту запросов Asirra, поэтому один
сервер Cats-Be-Gone больше не мог создавать токены для всех.
И они начали сопоставлять токены с IP-адресами, поэтому
токены сервера Cats-Be-Gone потеряли свою ценность.
Хуже всего
то, что они удалили 3,1 миллиона изображений с petfinder.com и
создали совершенно новый набор.
Теперь я не мог собирать их из-за ограничения частоты и не мог
продавать их из-за проверки IP-адреса, поэтому полностью отказался
от идеи делать на этом бизнес. Я так и не обработал ни один платёж,
однако всё равно чувствовал себя обязанным перед клиентами и
хотел выиграть призов, поэтому обратился к
краудсорсингу.
Краудсорсинг
Я знал, что некоторые из пользователей захотят отвечать на капчи
самостоятельно, поэтому настроил клиент таким образом, чтобы он
запрашивал у сервера ответы, а затем просил пользователя просто
ответить на неизвестные картинки. Затем клиент должен был
отправлять результаты на сервер для обновления базы данных.
Чтобы усложнить злоумышленникам задачу заполнения моей базы данных
мусором, я зашифровал всю передачу данных жёстко прописанным ключом
и пропускал релизы клиента через обфускатор .Net, чтобы его было
сложнее найти. Это бы помешало устраивать хаос в базе данных только
обычным пользователям, но такой защиты было вполне достаточно.
Единственными, кто бы разобрался, как получить доступ к базе данных
при помощи реверс-инжиниринга, были те, кто хотел бы скачать всю
базу целиком. Я решил, что меня это не волнует и пусть будет
так.
Кроме того, поскольку у меня не было изображений, всё хэширование
выполнялось в коде клиента, потому что не хотел отправлять 12
изображений на сервер при каждом запросе. И я знал, что MinHash
недостаточно надёжен, поэтому решил перейти на pHash.
Хэширование изображений, v2: pHash
pHash великолепен. Его принцип примерно таков:
- Преобразуем изображение в оттенки серого.
- Применяем гауссово размытие.
- Ужимаем до одинакового квадратного размера.
- Применяем к нему дискретное косинусное преобразование.
- Сохраняем только 64 наиболее значимые значения.
- Для каждого значения записываем
1, если оно больше
медианы, в противном случае 0.
- Теперь у нас есть 64-битное число!
Для этого у pHash есть библиотека, и естественно, она написана не
на VB.Net, поэтому я реализовал её самостоятельно. Сегодня можно
было бы просто использовать другой язык, в котором есть библиотека,
но я объясню, как работает pHash, потому что это довольно
круто.
Преобразование в оттенки серого
Тут всё довольно просто, достаточно преобразовать RGB-значение
каждого пикселя в яркость. Существует несколько способов сделать
это, вот тот, который описан в Википедии:
Y = 0.2126 * R + 0.7152 * G + 0.0722 *
B
Вот как это сделать на python:
from PIL import Imageimage = Image.open('dog.jpg')image.show()for x in range(image.size[0]): for y in range(image.size[1]): (r, g, b) = image.getpixel((x,y)) brightness = 0.2126 * r + 0.7152 * r + 0.0722 * b new_pixel = tuple([int(brightness)] * 3) image.putpixel((x,y), new_pixel)image.show()
Довольно просто.
Гауссово размытие
Заменяем каждый пиксель взвешенной суммой окружающих его пикселей.
Вот пример размытия с радиусом 8.
(Я пропущу этап сжатия до квадратного размера, потому что это
довольно скучно и очевидно.)
Дискретное косинусное преобразование
Дискретное косинусное преобразование (Discrete
cosine transform, DCT) похоже на преобразование Фурье тем, что
можно преобразовать последовательность чисел из одной формы в
другую, а также обратить преобразование.
inverse_dct(dct(image)) == image. Вам необязательно
знать всё о частотном анализе. Достаточно знать, что можно взять
матрицу чисел, например, изображение в оттенках серого, и
преобразовать её в ещё одну матрицу чисел. И обратное
преобразование тоже возможно.
В отличие от преобразования Фурье, DCT состоит из косинусов, а не
из степеней
e, поэтому все результаты вещественны, без
мнимых чисел. Этот способ используется в
JPEG для сжатия изображений.
Вот код, который я нашёл онлайн, выполняющий эту
задачу на Python. Я немного его изменил. Вот самая важная
часть:
im = rgb2gray(imread('dog.jpg')) #read in the image to grayscaleimF = dct2(im) #DCTfraction = 1for y in range(len(im)): for x in range(len(im[y])): if x > len(im[y])//fraction or y > len(im)//fraction: im[y][x] = 0 # blacken pixels that aren't in the top left corner imF[y][x] = 0 # blacken pixels that aren't in the top left cornerim1 = idct2(imF) # inverse DCT
Мы считываем изображение и выполняем с ним DCT. Затем мы зачерняем
часть исходного изображения, а также ту же часть преобразованного
изображения. А затем инвертируем преобразование. Вот как это
выглядит без зачернения:
Здесь нет ничего неожиданного. DCT обратим, поэтому логично, что
выходные данные эквивалентны входящим. Немного странно, что
изображение DCT только чёрное; вскоре мы к этому вернёмся!
Давайте посмотрим, что произойдёт, если мы отбросим три четверти
изображения:
Преобразованное DCT изображение по-прежнему выглядит довольно
неплохо, несмотря на потерю трёх четвертей информации. Давайте
зачерним его ещё больше.
Оригинал потерял кучу данных, но изображение DCT по-прежнему
выглядит приемлемо! В этом и заключается сила DCT: все важные биты
находятся в одном углу, а всё остальное можно отбросить.
Теперь давайте приблизим левый верхний угол изображения DCT, ту
часть, которую мы не отбросили.
Это левый верхний кусок изображения DCT. Мы видим, что все значимые
биты находились в углу. Вот почему DCT сработал, даже несмотря на
то, что мы отбросили столько много бит: мы отбросили те биты,
которые были неважны. Такой подход работает только с фотографиями,
но именно с ними мы и хотим работать.
Чтобы закодировать это в число, мы используем упомянутый выше
способ: взяв только 64 числа из левого верхнего угла, закодируем
1, если значение выше медианы, в противном случае
закодируем
0. Результатом будет 64-битное число с
половиной нулей. Существует более 10
18 таких чисел, что
намного больше, чем 3,1 миллиона изображений,
которые нам нужно закодировать, так что вероятность коллизии
мала.
Теперь нам просто нужно найти эффективный способ хранения всех этих
чисел для поиска.
VP-деревья
Vantage point tree это своего рода двоичное
дерево, работающее следующим образом: для каждого узла мы задаём
центр и радиус. Если точка, которую мы ищем, находится внутри
радиуса, движемся влево. Если снаружи, то движемся вправо.
Продолжаем двигаться так, пока не найдём ответ.
Преимущество такого дерева в том, что расстояние можно сделать
любым. Для нашего хэша изображения мы хотим взвесить все биты
равномерно, поэтому используем
расстояние Хэмминга. Расстояние Хэмминга это
количество бит, на которые различаются два числа.
01101010111001 10100010010010отличающиеся биты: ^^ ^ ^ ^ ^^Расстояние Хэмминга равно 7
Хэш довольно неплохо сочетается с расстоянием Хэмминга, потому что
оказывается, что если два изображения приблизительно одинаковы, но
не имеют одинаковый хэш, то их расстояние Хэмминга будет малым.
Chicken и pHash
Теперь, когда мы решили полностью положиться на краудсорсинг, мне
показалось несправедливым зарабатывать на этом деньги. Но я
продолжил хостить сервер, чтобы кто угодно мог делиться ответами на
задачи. Я выдавал результаты Asirra бесплатно и собирал новые
ответы, когда о них сообщали. Через каждую пару дней я повторно
генерировал дерево на основе последних данных и перезапускал
сервер. Максимум я получал примерно 10 запросов в секунду на моём
самодельном, написанном на VB.Net HTTP-сервере. Всего у меня было
около 2000 уникальных пользователей. Я вычислил примерное
количество очков, полученных пользователями с помощью Chicken и
среднюю стоимость очка на основании продаваемых на ebay товаров.
Похоже, благодаря Chicken пользователи в сумме получили призов
примерно на полмиллиона долларов.
Позже Microsoft начала передавать случайным образом
пикселизированные
и повёрнутые изображения. Они
оказались настолько искажёнными, что приводили pHash в
растерянность. Компания препятствовала читерству и другими
способами. Например, в Club Bing забанили мою страну целиком. В
2012 году работа Club Bing прекратилась.
Я так и не получил Xbox, а мой надувной каяк до меня не добрался. В
основном я отправлял призы в качестве неожиданных подарков друзьям
и членам семьи. Единственное, что я оставил себе это дешёвый
телескоп и куртку, которая мне понравилась.
На правах рекламы
Надёжный и недорогой VDS от
VDSina позволит разместить
любой проект, на любой операционной системе Linux или Windows. Всё
будет работать без сбоев и с высоким uptime!




















") Рис.1
пример изображений (CAPTCHA)
Рис.1
пример изображений (CAPTCHA)
 Рис. 2 пример определение диапазона символа
Рис. 2 пример определение диапазона символа
 Рис.3 Цветовая модель RGB
Рис.3 Цветовая модель RGB
 и HSV") Рис.4 Цветовые модели RGB (BGR) и HSV
Рис.4 Цветовые модели RGB (BGR) и HSV
 Исходное изображение
Исходное изображение



 Рис.5 Результат фон и часть шума имеют значения 255
Рис.5 Результат фон и часть шума имеют значения 255
 Рис.6 Разделение символов по определенном диапазонам
Рис.6 Разделение символов по определенном диапазонам
 Рис.7 Определение областей 1 и 3 символа,
где нет данных 2-го символа
Рис.7 Определение областей 1 и 3 символа,
где нет данных 2-го символа
 Рис.8 Отображение результата в виде pandas dataframe
Рис.8 Отображение результата в виде pandas dataframe
 Рис.9 Удаление из 2-го символа данных 1 и
3-го символов
Рис.9 Удаление из 2-го символа данных 1 и
3-го символов
 Рис.10 Корректировка данных, заполнение пропусков
Рис.10 Корректировка данных, заполнение пропусков
 Рис.11 Расположение символов в средине матрицы
Рис.11 Расположение символов в средине матрицы
 Рис.13 Пример подобранного текста и
размещение символов в матрицах
Рис.13 Пример подобранного текста и
размещение символов в матрицах

























