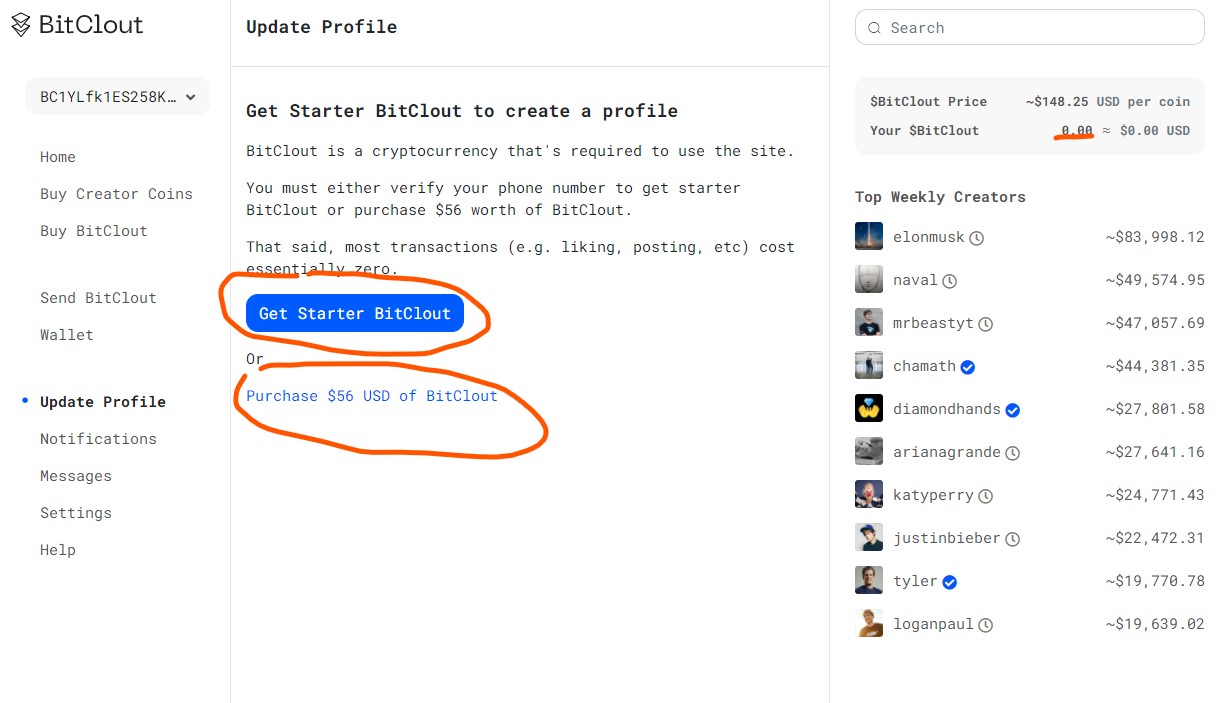
При разработке клиент-серверного приложения, у меня всегда
появляется вопрос, а как я его буду разворачивать на сервере,
упаковать его в jar/war/docker после написания кода, а потом еще
надо передать на сервер, и еще много сделать телодвижений чтоб
просто засунуть кусок кода на сервере.
Было бы хорошо просто передать на сервер код, как лямбду, так же
как мы передаем лямбду в функцию, так же на сервер ее передать.
Но у меня появилась мысль как сделать этот процесс проще, и у
меня что-то получилось.
1 | var query = TcpQuery2 | .create(IEnv.class).host("myserver.com").port(9988)3 | .build();4 |5 | query.apply( 6 | env -> env.processes().stream().filter(7 | p -> p.getName().contains("java")8 | )9 | .collect(Collectors.toList())10| ).forEach(System.out::println);
Вот код на java,
И это не псевдокод, это реальный рабочий код на Java (11).
Действительно код строк с 6 по 9 (само тело лямбды) передаются
на сервер и исполняются на сервере, при том сервер о этом куске
кода ничего не знает, он принимает этот код исполняет у себя, и
отдает обратно клиенту - а я дальше продолжаю писать код без
всякого deploy, не выходя из IDE (Idea/Eclipse/etc...).
Статья будет о том, что такое Serializable Lambda в Java, и как
передавать байт-код таких лямбд на сервер, без перезапуска сервера,
т.е. как можно в теории отказаться от привычных
схем deploy приложений и писать более удобный api (это моя
фантазия).
Допустим у нас есть такой интерфейс IEnv:
public interface IEnv {List<OsProc> processes();}
Который возвращает список процессов
public class OsProc implements Serializable {public Optional<Integer> getPpid(){ return ... }public int getPid(){ return ... }public void setPid(int pid){ ... }public String getName(){ return ... }public Optional<String> getCmdline(){ return ... }}
И вот таких простым способом я передаю лямбду на сервер
var query = TcpQuery .create(IEnv.class).host("myserver.com").port(9988) .build(); query.apply( env -> env.processes().stream().filter( p -> p.getName().contains("java") ) .collect(Collectors.toList()) ).forEach(System.out::println);
Введение - как это работает ?

При разработке клиентского приложения на Java
-
Мы создаем набор исходных файлов, допустим Client.java
-
Компилятор генерирует байт-код - файл Client.class
-
При вызове query.apply() - мы передаем ссылку на лямбду env
-> env.proc...toList())
-
Реализация query.apply():
-
Принимает ссылку на лямбду
-
Для лямбды обнаруживает имя класса (например Client) и метода
(например lambda1) реализующего лямбду
-
Отыскивает среди ресурсов программы соответствующий байт-код
класса (Client.class) и его метода
-
Загружает байт-код реализации лямбды и отправляет его на
сервер
-
Сервер принимает байт-код лямбды
-
Генерирует в памяти класс в который вставляет принятый
байт-код
-
Загружает этот класс в память и через рефлексию получает доступ
к лямбде
-
Возвращает идентификатор этого метода обратно
-
Принимает идентификатор метода и делает вызов его на сервере
-
Сервер выполняет ранее скомпилированный класс/метод/лямбду
-
Возвращает результат выполнения
-
Принимает результат серверного вызова и возвращает его как
результат локального вызова
-
Возврат результата вызова query.apply()
Далее в статье будет рассмотрено я на примере очень простой
библиотеки покажу, как запустить свои наработки в режиме
клиент-сервера, и писать клиентов без выхода из IDE и перезапуска
серверов.
Как воспользоваться?
Что бы с этим по играть, воспользуйтесь моим pet project-ом:
v 1.0 https://github.com/gochaorg/trambda/releases/tag/1.0
maven
<dependency> <groupId>xyz.cofe</groupId> <artifactId>trambda</artifactId> <version>1.0</version> <type>pom</type></dependency><dependency> <groupId>xyz.cofe</groupId> <artifactId>trambda-core</artifactId> <version>1.0</version></dependency><dependency> <groupId>xyz.cofe</groupId> <artifactId>trambda-tcp</artifactId> <version>1.0</version></dependency>
Чтобы воспользоваться, у вас должна быть какая нибудь библиотека
к которой вы хотите обращаться по сети (TCP)
В моем примере это будет очень простая библиотека, в ней
всего три файла:
-
OsProc.java - описывает процесс ОС (описание было выше)
-
IEnv.java - Интерфейс получения списка процессов для ОС
(описание было выше)
-
LinuxEnv.java - Получение списка процессов для ОС Linux -
реализация IEnv
Библиотека из примера работает так:
package xyz.cofe.trambda.demo.api;import org.junit.jupiter.api.Test;public class LinuxEnvTest { @Test public void test(){ var env = new LinuxEnv(); env.processes().stream() .filter(p->p.getName().equalsIgnoreCase("java")) .forEach(System.out::println); }}

LinuxEnv - это простой класс, он устроен так:
package xyz.cofe.trambda.demo.api;import java.util.ArrayList;import java.util.List;import xyz.cofe.io.fs.File;public class LinuxEnv implements IEnv { @Override public List<OsProc> processes(){ ArrayList<OsProc> procs = new ArrayList<>(); File procDir = new File("/proc"); procDir.dirList().stream() .filter( d -> d.getName().matches("\\d+") && d.isDir() ) .map(OsProc::linuxProc) .forEach(procs::add); return procs; }}
Код его тривиален, он сканирует каталог /proc и находит описание
процесса ОС, (для Linux все процессы сервера отображаются в виде
файлов/подкаталогов /proc)
Скомпилируем библиотеку (или
возьмем свою)
Клонируем репозиторий (git commit 67ec260)
> git clone https://github.com/gochaorg/trambda.gitКлонирование в trambda...remote: Enumerating objects: 978, done.remote: Counting objects: 100% (978/978), done.remote: Compressing objects: 100% (464/464), done.remote: Total 978 (delta 308), reused 862 (delta 195), pack-reused 0Получение объектов: 100% (978/978), 715.70 KiB | 559.00 KiB/s, готово.Определение изменений: 100% (308/308), готово.
Собираем библиотеку для демонстрации
user@user-Modern-14-A10RB:22:10:35:~/Загрузки/sample-tr:> cd trambda/trambda-demo/tr-demo-api/user@user-Modern-14-A10RB:22:10:49:~/Загрузки/sample-tr/trambda/trambda-demo/tr-demo-api:> mvn clean package install...[INFO] ------------------------------------------------------------------------[INFO] BUILD SUCCESS[INFO] ------------------------------------------------------------------------[INFO] Total time: 13.933 s[INFO] Finished at: 2021-04-18T22:11:11+05:00[INFO] ------------------------------------------------------------------------
В каталоге target должен оказаться файл jar с нашей
библиотекой
user@user-Modern-14-A10RB:22:13:13:~/Загрузки/sample-tr/trambda/trambda-demo/tr-demo-api:> ll target/итого 48drwxrwxr-x 10 user user 4096 апр 18 22:11 ./drwxrwxr-x 4 user user 4096 апр 18 22:11 ../drwxrwxr-x 3 user user 4096 апр 18 22:11 classes/drwxrwxr-x 3 user user 4096 апр 18 22:11 generated-sources/drwxrwxr-x 3 user user 4096 апр 18 22:11 generated-test-sources/drwxrwxr-x 2 user user 4096 апр 18 22:11 maven-archiver/drwxrwxr-x 3 user user 4096 апр 18 22:11 maven-status/drwxrwxr-x 4 user user 4096 апр 18 22:11 site/drwxrwxr-x 2 user user 4096 апр 18 22:11 surefire-reports/drwxrwxr-x 3 user user 4096 апр 18 22:11 test-classes/-rw-rw-r-- 1 user user 6337 апр 18 22:11 tr-demo-api-1.0-SNAPSHOT.jar
Запуск сервера
Теперь когда библиотека собрана копируем сервер с github и
распаковываем архив
user@user-Modern-14-A10RB:22:37:25:~/Загрузки/sample-tr:> wget https://github.com/gochaorg/trambda/releases/download/1.0/trambda-tcp-serv-cli.zip--2021-04-18 22:37:31-- https://github.com/gochaorg/trambda/releases/download/1.0/trambda-tcp-serv-cli.zipРаспознаётся github.com (github.com)... 140.82.121.4Подключение к github.com (github.com)|140.82.121.4|:443... соединение установлено.HTTP-запрос отправлен. Ожидание ответа... 302 FoundАдрес: https://github-releases.githubusercontent.com/350075998/47380d00-9b40-11eb-90a4-4e353f42e67c?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20210418%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20210418T173731Z&X-Amz-Expires=300&X-Amz-Signature=97ade1f58bfbe1eaa320805179987e8c4df730b9f5eddf24c05662fb676caafe&X-Amz-SignedHeaders=host&actor_id=0&key_id=0&repo_id=350075998&response-content-disposition=attachment%3B%20filename%3Dtrambda-tcp-serv-cli.zip&response-content-type=application%2Foctet-stream [переход]--2021-04-18 22:37:31-- https://github-releases.githubusercontent.com/350075998/47380d00-9b40-11eb-90a4-4e353f42e67c?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20210418%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20210418T173731Z&X-Amz-Expires=300&X-Amz-Signature=97ade1f58bfbe1eaa320805179987e8c4df730b9f5eddf24c05662fb676caafe&X-Amz-SignedHeaders=host&actor_id=0&key_id=0&repo_id=350075998&response-content-disposition=attachment%3B%20filename%3Dtrambda-tcp-serv-cli.zip&response-content-type=application%2Foctet-streamРаспознаётся github-releases.githubusercontent.com (github-releases.githubusercontent.com)... 185.199.111.154, 185.199.108.154, 185.199.109.154, ...Подключение к github-releases.githubusercontent.com (github-releases.githubusercontent.com)|185.199.111.154|:443... соединение установлено.HTTP-запрос отправлен. Ожидание ответа... 200 OKДлина: 12107487 (12M) [application/octet-stream]Сохранение в: trambda-tcp-serv-cli.ziptrambda-tcp-serv-cli.zip 100%[========================================================================================================================================>] 11,55M 3,75MB/s за 3,1s 2021-04-18 22:37:35 (3,75 MB/s) - trambda-tcp-serv-cli.zip сохранён [12107487/12107487]user@user-Modern-14-A10RB:22:37:35:~/Загрузки/sample-tr:> llитого 11836drwxrwxr-x 3 user user 4096 апр 18 22:37 ./drwxr-xr-x 11 user user 4096 апр 18 22:00 ../drwxrwxr-x 10 user user 4096 апр 18 22:10 trambda/-rw-rw-r-- 1 user user 12107487 апр 12 03:36 trambda-tcp-serv-cli.zipuser@user-Modern-14-A10RB:22:37:42:~/Загрузки/sample-tr:> unzip trambda-tcp-serv-cli.zip Archive: trambda-tcp-serv-cli.zip creating: trambda-tcp-serv-cli/ creating: trambda-tcp-serv-cli/jars/ inflating: trambda-tcp-serv-cli/jars/asm-9.1.jar inflating: trambda-tcp-serv-cli/jars/jline-2.14.6.jar inflating: trambda-tcp-serv-cli/jars/iofun-1.0.jar inflating: trambda-tcp-serv-cli/jars/groovy-swing-3.0.7.jar inflating: trambda-tcp-serv-cli/jars/groovy-console-3.0.7.jar inflating: trambda-tcp-serv-cli/jars/groovy-xml-3.0.7.jar inflating: trambda-tcp-serv-cli/jars/trambda-tcp-serv-cli-1.0.jar inflating: trambda-tcp-serv-cli/jars/ecolls-1.10.jar inflating: trambda-tcp-serv-cli/jars/trambda-core-1.0.jar inflating: trambda-tcp-serv-cli/jars/slf4j-api-1.7.25.jar inflating: trambda-tcp-serv-cli/jars/asm-tree-9.1.jar inflating: trambda-tcp-serv-cli/jars/asm-util-9.1.jar inflating: trambda-tcp-serv-cli/jars/fs-1.2.jar inflating: trambda-tcp-serv-cli/jars/logback-classic-1.2.3.jar inflating: trambda-tcp-serv-cli/jars/trambda-tcp-1.0.jar inflating: trambda-tcp-serv-cli/jars/groovy-groovysh-3.0.7.jar inflating: trambda-tcp-serv-cli/jars/groovy-templates-3.0.7.jar inflating: trambda-tcp-serv-cli/jars/asm-analysis-9.1.jar inflating: trambda-tcp-serv-cli/jars/text-1.0.jar inflating: trambda-tcp-serv-cli/jars/logback-core-1.2.3.jar inflating: trambda-tcp-serv-cli/jars/groovy-3.0.7.jar inflating: trambda-tcp-serv-cli/jars/cbuffer-1.3.jar creating: trambda-tcp-serv-cli/bin/ inflating: trambda-tcp-serv-cli/bin/trambda-tcp-serv.bat inflating: trambda-tcp-serv-cli/bin/trambda-tcp-serv user@user-Modern-14-A10RB:22:37:50:~/Загрузки/sample-tr:> rm trambda-tcp-serv-cli.zip
После копируем нашу библиотеку в каталог
trambda-tcp-serv-cli/jars
ser@user-Modern-14-A10RB:22:40:47:~/Загрузки/sample-tr:> cp -v trambda/trambda-demo/tr-demo-api/target/tr-demo-api-1.0-SNAPSHOT.jar trambda-tcp-serv-cli/jars/'trambda/trambda-demo/tr-demo-api/target/tr-demo-api-1.0-SNAPSHOT.jar' -> 'trambda-tcp-serv-cli/jars/tr-demo-api-1.0-SNAPSHOT.jar'
Нам понадобиться подготовить скрипт запуска, скрипт на языке
groovy (не беспокойтесь, это не обязательно именно так запускать,
все можно сделать на голой Java)
Возьмем скрипт из примера:
> cat trambda/trambda-tcp-serv-cli/src/test/samples/sample-1.groov
// Сервис xyz.cofe.trambda.demo.api.LinuxEnv // будет запущен на порту 9988, и будет доступен с любого IPapp.service( "0.0.0.0:9988", new xyz.cofe.trambda.demo.api.LinuxEnv() ) { daemon false // Указываем настройки безопасности security { // Какие API/Методы будут доступны извне allow { // method("System") { // methodOwner ==~ /java.lang.System/ && methodName in ['gc'] // } // field( "System.out" ) { // fieldOwner ==~ /java.lang.System/ && fieldName in ['out','in','err'] && readAccess // } invoke( 'Java compiler' ){ methodOwner ==~ /java\.lang\.invoke\.(LambdaMetafactory|StringConcatFactory)/ } invoke( 'Java collections' ){ methodOwner ==~ /java\.util\.(stream\.(Stream|Collectors)|(List))/ } invoke( 'Java lang' ){ methodOwner ==~ /java\.lang\.String/ } invoke( 'Api '){ methodOwner ==~ /xyz\.cofe\.trambda\.demo\.api\.(IEnv|OsProc)/ } } // Для всех остальных случаев - запрещаем вызов deny { any("ban all") } }}
Запускаем сервер
user@user-Modern-14-A10RB:22:56:08:~/Загрузки/sample-tr:> bash ./trambda-tcp-serv-cli/bin/trambda-tcp-serv -s trambda/trambda-tcp-serv-cli/src/test/samples/sample-1.groovy# [main] INFO x.c.t.tcp.serv.cli.TcpServerCLI - starting xyz.cofe.trambda.tcp.serv.cli.TcpServerCLI # [main] INFO x.c.t.tcp.serv.cli.TcpServerCLI - executeScript( "trambda/trambda-tcp-serv-cli/src/test/samples/sample-1.groovy", UTF-8 ) # [main] INFO x.c.t.tcp.serv.cli.TcpServerCLI - registry class xyz.cofe.trambda.demo.api.LinuxEnv on 0.0.0.0:9988 # [main] INFO x.c.t.tcp.serv.cli.TcpServerCLI - starting service xyz.cofe.trambda.demo.api.LinuxEnv@55e7a35c on /0.0.0.0:9988 # [main] DEBUG x.c.t.tcp.serv.cli.TcpServerCLI - create server socket # [main] DEBUG x.c.t.tcp.serv.cli.TcpServerCLI - bind server socket /0.0.0.0:9988 # [main] DEBUG x.c.t.tcp.serv.cli.TcpServerCLI - server started
Все, сервер запущен, теперь можем им пользоваться
Запуск клиента
Клиента можно взять из примера (ClientTest.java)
package xyz.cofe.trambda.demo.client;import java.util.stream.Collectors;import org.junit.jupiter.api.Test;import xyz.cofe.trambda.demo.api.IEnv;import xyz.cofe.trambda.tcp.TcpQuery;public class ClientTest { @Test public void test01(){ var query = TcpQuery .create(IEnv.class).host("localhost").port(9988) .build(); query.apply( env -> env.processes().stream().filter(p -> p.getName().contains("java")) .collect(Collectors.toList()) ).forEach(System.out::println); }}
Запустим и посмотрим, что он выведет, часть логов я опущу - т.к.
для пояснения работы они не важны




Что происходит на сервере ?
часть логов я опущу - т.к. для пояснения работы они не важны


Настройка безопасности сервера
Совсем не обязательно использовать сервер через скрипты запуска,
сервер можно встроить как часть своего приложения и настраивать
так:
// Создание TCP сокетаServerSocket ssocket = new ServerSocket(port);// Настраиваем сокетssocket.setSoTimeout(1000*5);// Создаем серверserver = new TcpServer<IEnv>( // Передаем сокет ssocket, // Передаем функцию получения сервиса для новой сессии s -> new LinuxEnv(), // Настраиваем безопасность SecurityFilters.create(s -> { // Разрешаем вызовы строго - определенных методов s.allow( a -> { // Публикуемый API нашего сервиса a.invoke("demo api", c-> c.getOwner().matches( "xyz\\.cofe\\.trambda\\.tcp\\.demo\\.([\\w\\d]+)")); // Работа с коллекциями a.invoke("java collections api", c->c.getOwner().matches( "java\\.util\\.(List)|java\\.util\\.stream\\.([\\w\\d]+)")); // Работа с Java строками a.invoke("java lang api", c-> c.getOwner().matches("java\\.lang\\.(String)")); // Методы которые использует компилятор Java a.invoke("java compiler", c-> c.getOwner().matches( "java\\.lang\\.invoke\\.(LambdaMetafactory|StringConcatFactory)")); }); // Все остальное запрещаем s.deny().any("by default"); }));// Указываем что Thread сервера будет запущен как фоновыйserver.setDaemon(true);// Запускаем серверserver.start();// Создание TCP сокетаServerSocket ssocket = new ServerSocket(port);// Настраиваем сокетssocket.setSoTimeout(1000*5);
Код приведенный выше вроде кажется понятным, но наверно следует
дать несколько пояснений
-
Правила проверки безопасности указываются в виде списка
фильтров
-
Список фильтров обрабатывается последовательно и соответственно
первые правила имеют более высокий приоритет, нежели последние
-
В списке могут быть как разрешающие, так и запрещающие
правила
-
Java компилятор генерирует
-
Вы также можете контролировать обращения к полям класса на
чтения/запись - см. SecurityFilters.java /
PredicateBuilder#field
-
Для доступа к стандартным функция, там даже как
Object.toString() то, же надо будет задать правила
доступа
Более подробную информацию о работе можно найти на странице
проекта, например на github или git pages
Чем это может быть полезно?
Резонный вопрос, чем может быть полезно и чем оно отличаеться от
уже существующих, например RMI, gRPC ? Давайте рассмотрим
отличия
Протоколов передачи данных и вызова процедур много, будут
рассмотрены некоторые из известных автору. Эти протоколы можно
разделить на несколько категорий/свойств:
|
Фича
|
Java-RMI
|
SOAP
|
REST-JSON
|
SQL
|
GraphQL
|
Hadoop
|
|
Передача данных
|
+
|
+
|
+
|
+
|
+
|
+
|
|
Строго ограниченные форматы данных
|
+/-
|
+/-
|
-
|
-
|
+
|
-
|
|
Гибкие форматы данных
|
+/-
|
+/-
|
+
|
+
|
-
|
+
|
|
Передача программного кода
|
-
|
-
|
-
|
+
|
-
|
+
|
|
Простые выражения
|
-
|
-
|
-
|
+
|
-
|
+
|
|
Циклы/ветвления
|
-
|
-
|
-
|
+
|
-
|
+
|
|
Процедуры/функции
|
-
|
-
|
-
|
+
|
-
|
+
|
|
программные объекты
|
-
|
-
|
-
|
?
|
-
|
?
|
|
Слабая типизация
|
-
|
-
|
+
|
-
|
-
|
+
|
|
Строгая типизация
|
+
|
+
|
-
|
+
|
+
|
-
|
|
авторизация
|
+
|
+
|
+
|
+
|
+
|
+
|
|
время исполнения
|
?
|
?
|
?
|
+/-
|
?
|
?
|
|
Потребность в перезапуске серверов
|
+
|
+
|
?
|
-
|
+
|
-
|
|
Возможность находу опробывать новые решения
|
-
|
-
|
?
|
+
|
-
|
+
|
|
Профилирование выполнения
|
+
|
+
|
?
|
+
|
+
|
?
|
-
Большинство протоколов ориентированы только на передачу данных
(Java-RMI, SOAP, REST-JSON, GraphQL)
-
Часть из них работают со строго типизированными данными
(Java-RMI, SOAP, GraphQL)
-
Другие (REST-JSON, Hadoop) со слабо типизированными
-
Небольшое кол-во протоколов поддерживают еще передачу
программного кода (SQL, Hadoop)
Наличие строгой типизации и передачу программного кода из
рассмотренных есть только в SQL
В предлагаемом проекте есть следующие возможности, с
оговорками
-
Передача данных (*)
-
Передача программного кода
-
Простые выражения
-
Циклы/ветвления
-
Процедуры/функции/
-
программные объекты (**)
-
Ограничения на интерпретацию алгоритмов
-
Строгая типизация
-
Безопасность (***)
-
Поддержка существующий решений
Оговорки
-
(*)
-
(**)
-
(***)
-
реализована проверка байт-кода, без учета текущего
пользователя
-
не реализован механизм аутентификации, см план
реализации
-
(****)
Область применения
Поскольку проект только начат, говорить о реальном применении
рано, можно говорить о потенциальном применении
Возможны следующий области применения
-
фильтрация данных в программах написанных на Java по аналогии
SQL WHERE (уже есть)
-
выполнение серверных процедур по аналогии RPC/RMI/SOAP/ (уже
есть)
-
подписка клиента на события сервера
-
масштабирование нагрузки (как частный случай реализации сетевого
протокола)
При дальнейшем развитии возможно автоматическая прозрачная
трансляция JAVA/Kotlin/Scala кода в целевые системы (SQL, MongoDB,
REST, )
Данное возможно при условии развития функции декомпиляции
байт-кода в код AST/Java/, по факту такая функция реализована в
декомпиляторе JAD
Что собственно ведет к уменьшению издержек при разработке
ПО.
Как же оно внутри работает ?
Идея была проста, весь код Java который компилируется, обычно
сохраняется в виде байт-кода который является файлом с расширением
.class, а для любого объекта java можно узнать класс, обычно это
выглядит так: obj.getClass()
Через объект Class можно узнать его название, и соответственно
через Class.getResource(имя класса) можно получить URL
ссылку на данный файл.
Гладко было на бумаге, но забыли про овраги
Такова была идея, но есть нюансы
Процесс разработки, как найти байт код?
Допустим у нас есть такой код
package xyz.cofe.trambda.l1;import java.util.function.Function;import org.junit.jupiter.api.Test;public class SimpleLambdaTest { @Test public void javaLambda01(){ Function<Function<String,String>,String> test = (f) -> { System.out.println("f="+f.getClass()); return null; }; test.apply( x -> x.repeat(4) ); }}
При выполнении теста будет вот это:
f=class
xyz.cofe.trambda.l1.SimpleLambdaTest$$Lambda$235/0x0000000800142040
По идее у нас в каталоге test-classes/ должен быть файл
SimpleLambdaTest$$Lambda$235, но такого файла не видно
user@user-Modern-14-A10RB:00:41:32:~/code/trambda/trambda-core/target/test-classes/xyz/cofe/trambda/l1:> llитого 12drwxrwxr-x 2 user user 4096 апр 25 00:40 ./drwxrwxr-x 5 user user 4096 апр 25 00:40 ../-rw-rw-r-- 1 user user 2162 апр 25 00:40 SimpleLambdaTest.class
Тогда посмотрим байт код
> javap -p SimpleLambdaTest.class Compiled from "SimpleLambdaTest.java"public class xyz.cofe.trambda.l1.SimpleLambdaTest { public xyz.cofe.trambda.l1.SimpleLambdaTest(); public void javaLambda01(); private static java.lang.String lambda$javaLambda01$1(java.lang.String); private static java.lang.String lambda$javaLambda01$0(java.util.function.Function);}
По факту где-то lambda$javaLambda01$1 или lambda$javaLambda01$0
находиться код нашей лямбды, но можно долго гадать, но это не наш
подход
По факту сопоставить class и лямбду в Java с разбегу не удастся,
а гадать это сразу путь на костыли.
В Java есть интересный интерфейс Serializable, и этим
интерфейсом можно пометить лямбду
Например так
package xyz.cofe.trambda.l2;import java.io.Serializable;import java.util.function.Function;public interface Fn<A,Z> extends Function<A,Z> , Serializable {}
или вот так
Runnable r = (Runnable & Serializable)() -> System.out.println("Serializable!");
Фактически это заставит компилятор Java сгенерировать
дополнительный код, давайте возьмем код теста выше и немного его
модифицируем
package xyz.cofe.trambda.l2;import java.lang.invoke.SerializedLambda;import java.lang.reflect.InvocationTargetException;import java.lang.reflect.Method;import java.util.function.Function;import org.junit.jupiter.api.Test;public class SerialLambdaTest { @Test public void serLambda01(){ Fn<Fn<String,String>,String> test = (lambda) -> { System.out.println("lambda="+lambda.getClass()); Method writeReplace = null; try{ writeReplace = lambda.getClass().getDeclaredMethod("writeReplace"); writeReplace.setAccessible(true); SerializedLambda sl = (SerializedLambda) writeReplace.invoke(lambda); System.out.println(sl); } catch( NoSuchMethodException | InvocationTargetException | IllegalAccessException e ) { e.printStackTrace(); } return null; }; test.apply( x -> x.repeat(4) ); }}
Теперь результат будет таким, его разбор будет ниже.
lambda=class xyz.cofe.trambda.l2.SerialLambdaTest$$Lambda$235/0x0000000800142040SerializedLambda[capturingClass=class xyz.cofe.trambda.l2.SerialLambdaTest, functionalInterfaceMethod=xyz/cofe/trambda/l2/Fn.apply:(Ljava/lang/Object;)Ljava/lang/Object;, implementation=invokeStatic xyz/cofe/trambda/l2/SerialLambdaTest.lambda$serLambda01$3fed5817$1:(Ljava/lang/String;)Ljava/lang/String;, instantiatedMethodType=(Ljava/lang/String;)Ljava/lang/String;, numCaptured=0]
А при просмотре байт кода мы увидим
user@user-Modern-14-A10RB:00:51:48:~/code/trambda/trambda-core/target/test-classes/xyz/cofe/trambda/l2:> javap -p SerialLambdaTest.class Compiled from "SerialLambdaTest.java"public class xyz.cofe.trambda.l2.SerialLambdaTest { public xyz.cofe.trambda.l2.SerialLambdaTest(); public void serLambda01(); private static java.lang.Object $deserializeLambda$(java.lang.invoke.SerializedLambda); private static java.lang.String lambda$serLambda01$3fed5817$1(java.lang.String); private static java.lang.String lambda$serLambda01$47b6c34$1(xyz.cofe.trambda.l2.Fn);}
Первое что мы можем заметить - у нас появился метод
$deserializeLambda$ пока не важно что делает этот метод, есть факт
что добавление интерфейса Serializable меняет поведение
компилятора.
java.lang.invoke.SerializedLambda - это final класс, который
содержит ряд интересных свойств, а именно
-
String getImplClass() - Имя класса, содержащего метод
реализации.
-
String getImplMethodName() - название метода реализации.
В stdout можно заметить фрагмент
implementation=invokeStatic
xyz/cofe/trambda/l2/SerialLambdaTest.lambda$serLambda01$3fed5817$1:(Ljava/lang/String;)Ljava/lang/String;
И в байт коде:
private static java.lang.String
lambda$serLambda01$3fed5817$1(java.lang.String);
Т.е. можно однозначно установить байт-код для лямбды
Сериализация байт кода
Теперь, на данном этапе прочесть байт код лямбды - дело техники,
а именно так:
SerializedLambda sl = (SerializedLambda)writeReplace.invoke(lambda);var implClassName = sl.getImplClass()var implClassUrl =labmda.getClass().getResource("/"+implClassName.replace(".","/")+".class");
implClassUrl - указывает на файл класса содержащего байт код
получаем байт код из URL как массив байтов
byte[] classByteCode = null;try{ classByteCode = IOFun.readBytes(implClassUrl);} catch( IOException e ) { throw new IOError(e);}
После этого передаем этот набор байтов в библиотеку ASM для прочтения байт кода
var classReader = new ClassReader(classByteCode);
и читаем байт код нужного метода
ClassVisitor cv = new ClassVisitor(Opcodes.ASM9) { @Override public MethodVisitor visitMethod(int access, String name, String descriptor, String signature, String[] exceptions) { if( methName.equals(name) && descriptor!=null && descriptor.equals(methSign) ){ mdef0.set(new MethodDef(access,name,descriptor,signature,exceptions)); return dump(byteCodes::add); } return null; }};cr.accept(cv, 0);
MethodVisior - это класс который получает байт код
конкретного метода. Методы этого класса можно переопределить,
рассмотрим часть реализации MethodDump extends
MethodVisitor:
package xyz.cofe.trambda;public class MethodDump extends MethodVisitor implements Opcodes {...@Overridepublic void visitParameter(String name, int access){ emit(new MParameter(name,access));}@Overridepublic void visitInsn(int opcode){ emit(new MInsn(opcode));}...}
Данный класс принимает байт код через вызовы методов
visitXXXX(...) - их много методов (по этому показа только
часть)
При каждом вызове метода генерируется объект который описывает
вызов, например для visitInsn( op ) генерируется new MInsn(op), а
потом этот объект передается выше emit(..) где уже этот объект
передается в сеть
Восстановление классов из байт кода
После этого как код передан по сети в виде набора объектов, эти
объекты обратно собирается в байт код (с дополнительными проверками
безопасности)
Для этого в моей библиотеке есть класс
xyz.cofe.trambda.MethodRestore его работа заключается примерно в
следующем
public synchronized byte[] generate(){ // генерируем имя целевого класса binClassName = className.replace('.', '/');// Создаем ClassWriter (часть ASM) // в котором будем вызывать методы visitXXXX( op )var cw = new ClassWriter(ClassWriter.COMPUTE_MAXS|ClassWriter.COMPUTE_FRAMES);cw.visit(Opcodes.V11, Opcodes.ACC_PUBLIC|Opcodes.ACC_SUPER, binClassName,null, "java/lang/Object", null);// генерация методаvar mv = cw.visitMethod( acc, // флаги как static public name, // имя метода desc, // параметры метода sign, // сигнатура если есть Generic параметры excepts); // исключения которые может генерировать метод// Потом в цикле для каждого переданного объекта // генерируем соответствующий вызов visitXXXX()// генерируем код в той же последовательности, что и был прочитанfor( var bc : byteCodes ){ if( bc instanceof MCode )build((MCode) bc); else if( bc instanceof MEnd )build((MEnd) bc); else if( bc instanceof MLabel )build((MLabel) bc); else if( bc instanceof MLineNumber )build((MLineNumber) bc); else if( bc instanceof MVarInsn )build((MVarInsn) bc); ...}// Получаем байт кодreturn cw.toByteArray();}// Вызов visitCode() - начало методаprotected void build(MCode code){ mv.visitCode(); }// Вызов visitEnd() - конец методаprotected void build(MEnd end){ mv.visitEnd(); }protected void build(MTypeInsn tinst){ mv.visitTypeInsn(tinst.getOpcode(), tinst.getOperand());}
Теперь когда у нас есть на сервере байт код, остается его
загрузить и вызвать соответствующий метод
Для этого создаем свой ClassLoader
var byteCode = new MethodRestore() .className(clName) .methodName("lambda1") .methodDef(mdef) .generate();ClassLoader cl = new ClassLoader(ClassLoader.getSystemClassLoader()) { @Override protected Class<?> findClass(String name) throws ClassNotFoundException{ if( name!=null && name.equals(clName) ){ return defineClass(name,byteCode,0,byteCode.length); } return super.findClass(name); }};
Загружаем класс
System.out.println("try read class "+clName);Class c = null;try{ c = Class.forName(clName,true,cl); System.out.println("class found "+c);} catch( ClassNotFoundException e ) { e.printStackTrace(); return;}
Ищем нужный нам метод класса
Method m = null;System.out.println("methods");for( var delMeth : c.getDeclaredMethods() ){ System.out.println(""+delMeth); if( delMeth.getName().equals(methName) ){ m = delMeth; }}
и вызываем его с параметрами
try{ Object arg0 = "abc"; System.out.println("call with "+arg0); Object res = m.invoke(null, arg0); System.out.println("result "+res);} catch( IllegalAccessException | InvocationTargetException e ) { e.printStackTrace();}
Ограничения
Конечно у данного решения есть ряд ограничений
-
Не для любого языка подойдет
-
например для Kotlin придется дописывать реализацию, т.к. Kotlin
по другому компилирует лямбды, такая же ситуация с Scala
-
для динамических языков (Groovy, JavaScript) вообще наверно не
подойдет - но там наверно можно и по другому передавать лямбды,
например передавать AST дерево лямбд - все зависит от их
представления промежуточного кода, чем бы это не являлось.
-
Гарантировать типо безопасность - особенно когда разные версии
библиотек на сервере и на клиенте - задача непростая, но еще не
означает что невозможно
-
Потенциально на клиенте может Java более новая, с другим
байт-кодом нежели на сервере, сервер может не знать о каких либо
конструкциях новой Java
-
Библиотека не весь байт код передает, это связано с тем, что не
весь байт код имеет объектное представление - наверно это решаемый
вопрос, вопрос доработки.
-
Отдельно - это вопрос передачи по сети
-
Вопрос безопасности - технически это решаемо, но требует
допиливание напильником
-
Протокол передачи, моя библиотека использует TCP, но этот
сетевой уровень всегда можно сменить на более подходящий вам, но
конечно потребует реализации его, по факту сериализация лямбды и ее
восстановления никак, не ограничивают сетевой уровень.








 Фотография: Alexander Popov. Источник: Unsplash.com
Фотография: Alexander Popov. Источник: Unsplash.com


































 Советский атомный ледокол Ленин
Советский атомный ледокол Ленин
 Российский атомный ледокол 50 лет Победы
Российский атомный ледокол 50 лет Победы
 Nucleon
первый проект атомобиля
Nucleon
первый проект атомобиля
 Проект Кадиллака на ториевом двигателе
Проект Кадиллака на ториевом двигателе
 Советский
атомолет Ту-95 ЛАЛ
Советский
атомолет Ту-95 ЛАЛ
 Атомный стратегический бомбардировщик В-36
Атомный стратегический бомбардировщик В-36
 В Канаде собирались добывать нефть с
помощью ядерных взрывов
В Канаде собирались добывать нефть с
помощью ядерных взрывов