Что думаешь о проектах, которые повышают доступность и качество информации в масштабах человечества: Web Archive, Википедия, Google (и Google Books), Quora?
Я уже не работаю в Google (хотя и являюсь акционером), но меня продолжает вдохновлять их миссия: организовать информацию мира и сделать ее универсально доступной и полезной. Эта миссия привлекает многих талантливых специалистов, внутри компании создается множество подпроектов, но не все доходят до официального релиза.
Я болею за эту миссию и хочу, чтобы вся информация мира была организована, от этого люди будут только в плюсе. Я изучал миссии многих компаний. Миссия работает, потому что люди думают о ней, вдохновляются ею. Как акционер и как болельщик, я хотел бы, чтобы в области организации информации разрабатывали больше проектов. С другой стороны, остается куча задач для стартапов. У человечества есть Google, Wikipedia, Quora, но в области информации и структуризации знаний, думаю, можно создавать еще сотни стартапов. Очень приятно что Ontol взялся за одну из сфер, мне очень нравится этот проект.
Проект Онтол это гибридная человеко-машинная сеть коллективного мышления, которая на выходе выдает структурированную, отфильтрованную и верифицированную информацию по самым значимым вопросам (присоединяйтесь к новостному каналу в телеграм).
Wikipedia. Я считаю, что Wikipedia это чудо света. Википедии могло бы не быть, была бы только цифровая Britannica. Wikipedia достижение человечества, которое создали вместе. Я рад, что Wikipedia существует. Очень благодарен ей. Там организовано столько информации.
Quora классный сервис, но пока не кажется чудом света, по крайней мере для меня.
Internet Archive цифровая библиотека, миссия которой дать общечеловеческий доступ ко всем знаниям. Этот проект помогал мне: находил статьи и интервью со мной, которые удалили с сайтов. Для информации в сети тоже нужна библиотека, с исходом лучше, чем у Александрийской, для это нужно больше проектов, чем один Web Archive.
Мне кажется, что ни Facebook, ни Twitter не улучшают структурированность информации. Из гигантов только Google старается в этом направлении.
Может еще ЦРУ?
Возможно они и собирают, но на счет их технологий не уверен. Думаю, у них какие-то технологии хорошо развиты, а большой процент, возможно, на Microsoft Excel.
Может Palantir?
Я мало знаю об этой компании. Знаю, что у них сильные программисты, уровня Google и Facebook. У Palantir 3-4 продукта для анализа данных. Palantir работает так: они идут в организацию, где нет сильных программистов, и интегрируют данные этой организации в одну платформу. Так Palantir помогает компаниям с большим количеством данных проанализировать их, делают дашборды, стоят графики, статистику, возможно выстраивают простое машинное обучение. Это называется data warehouse.
Palantir супер секретная организация, даже внутри компании все проекты называют кодовыми именами. Сотрудникам нельзя рассказывать, над каким проектом они работают. О компании известно мало, это все, что я знаю о них.
Google это коммерческая компания, её цель получение прибыли. Это не идет в разрез с проектами, цель которых благо для человечества? Как в Google избегают конфликта интересов?
Это баланс. Проект по сканированию книг Google Books не приносит компании денег. На проекте Google Street View сложно заработать, как и на Google Maps.
Реклама в поиске приносит больше половины дохода Google. В Google Maps рекламу показывают редко, Google Books мало людей используют.
Проект Google Cultural Institute организует информацию о 2-х и 3-х мерных произведениях визуального искусства. Это проекты, которые создают во многом для миссии, а не с расчетом на прибыль.
Google открылся бы в Китае и стал бы использовать цензуру для поисковой выдачи, если бы оптимизировал проекты только под прибыль. В 2010 году Google принял стратегическое решение не входить в Китай из-за цензуры.
Google не сводит проекты только к получению прибыли, он балансирует между деньгами и миссией.
Ты говорил, что до какого-то момента в мире не было формата энциклопедическая статья, а сейчас это всем знакомый и часто используемый формат. Что потенциально нового в области структурирования информации может появиться в ближайшее время? Какие есть ниши и возможности?
Да, согласен, было время, когда не было энциклопедических статей, но были рассказы, легенды, мифы, поэмы, пословицы, приметы. Несметное количество форматов, и только намного позже появился формат энциклопедической статьи.
Со своей стороны ты придумал онтолы, мне кажется это очень классная находка, такой формат хранения и структуризации информации, который люди не осознают, но уже используют. Ты дал этому название, и теперь это можно организовать.
Не знаю, разработали ли уже такую штуку, но одна из моих маленьких мечт это организовать и категоризировать пословицы разных народов.
Представь, сколько в мире пословиц. Семь раз отмерь, один отрежь продумай много раз, а только потом делай. Уверен, что в каждой культуре придумали синонимы к этой пословице. Утро вечера мудренее 100% люди придумали вариации для каждого языка. Здорово найти такие соотношения.
Я представляю это как некоммерческий проект. Я бы реализовал этот проект, если бы жил супердолго и имел намного большее количество времени.
Я после разговора с тобой осознал что давно уже сам делал онтолы, чтобы сохранить и передать информацию. Я это делал в неструктурированном виде. Было бы классно если бы онтолы в тот момент оказались под рукой. Я также мечтаю о многих других форматах в дополнение к онтолам.
Я пару дней занимался шуточным проектом (см. статью Альтернативная конституция) какие на сегодняшний день существуют цифровые инструменты, чтобы написать свою конституцию. И наткнулся на интересный проект от Google.
Я удивлен, что ты знаешь этот проект, и мне приятно, потому что это малоизвестный проект Google. Точнее даже не Google, а Jigsaw компании-сестры Google, которая оттуда вышла.
В Кыргызстане часто меняют конституции, возможно слишком часто, в 2005 была революция, в 2010 была революция. (Прим. ред: Сейчас происходит третья. На момент интервью все было спокойно. )

Слева направо: сотрудник Google Тилек Мамутов, со-основатель Google Эрик Шмидт, экс-президент Кыргызстана Роза Отунбаева в Бишкеке.
Я в 2011 году был представителем по Центральной Азии в Google. Я организовывал встречу бывшего CEO Google Эрика Шмидта и Джареда Коэна с президентом нашей страны, с премьер-министром, вице-премьером и с бывшим президентом Розой Отунбаевой. На этой встрече обсуждали много проектов: некоторые открытые (к примеру, Google Street View запустили), некоторые конфиденциальные.
И проект Jigsaw полезен для стран вроде Кыргызстана. Когда происходит переворот, нет времени, чтобы написать конституцию, нужно действовать быстро. Часто страны копируют у другой страны, чаще у ближайшей. В Кыргызстане много законов копируют у России, потому что русский язык понимают, и Россия страна, на которую часто смотрят. Я думаю это само по себе неплохо, но желательно чтобы изучали больше опций.
Проект Constitute хорош тем, что можно быстро сравнить, какие существуют опции, а не копировать все подряд.
Расскажи, как ты ищешь и проверяешь информацию?
Я читаю Twitter.
Недооцененный ресурс World Science University. Это бесплатный онлайн-университет. Там много курсов по теоретической физике, даже с нуля, для тех кто не знает физику. Гравитацию, теорию относительности учителя объясняют с понятными графиками, невероятно захватывает.
Брайан Грин по-моему, один из лучших учителей в мире, он простыми словами объясняет теорию струн и многие другие темы из теоретической физики. В этом университете читают много других лекции, в том числе и о свободе воли, например. Освещают передний край исследований в этой области.
Я бы хотел, чтобы подобные темы освещали ярче. Думаю, это важнее, чем личная жизнь знаменитостей, стоит научиться популяризировать этот контент.
Хороший пример про современное потребление информации коронавирус. Становится очевидно, как люди живут, проверяют соцсети, новости, смотрят телевизор. Там информация часто предвзятая, там выгодно шокировать, чтобы привлечь внимание, потому дают шокирующие цифры. Х кейсов коронавируса, х смертей. Да, такая информация привлечет внимание, возможно даже удержит на сайте новостных СМИ. Эта информация никак не образовывает, не дает понимания, что происходит.
Я пользуюсь сайтом ourworldindata.org
примеры инфографики


Это супер-сайт, без эмоций. Вот статистика. Вот график роста в США, России, Китае. Вот комментарий от сообщества, почему статистические данные могут быть предвзятыми. Это шикарный проект в области организации информации, я мечтал о таком проекте, называю его дашборд для человечества. Представь, что ты product-менеджер человечества и тебе нужно улучшить состояние человечества. Тебе нужна статистика, чтобы понять, что происходит. Нужна приборная панель, которая отражает состояние здоровья, образования, экономики и тому подобное.
Когда в мире происходят глобальные события, я стараюсь использовать источники с научным подходом к организации информации не предвзятым и неэмоциональным, чтобы принять решение. Эмоций в Интернете сейчас слишком много, по-моему.
Если всё будет непредвзято и не эмоционально, будет тоже перекос. Станет слишком скучно, если будут только цифры. Думаю Internet на заре зарождения был таким: только данные. Ученым там было легко и понятно, обычным людям скучно. Но сейчас информацию переполняют эмоциями. Даже научную информацию переделывают.
Как с этим бороться? Как фильтруют информацию в Долине?
По-моему, в Долине есть много интересных сообществ, какие-то из них, кстати, есть и в русскоязычных странах. Самые популярные, например, это сообщество blockchain, сообщество etherium. Они встречаются, общаются, устраивают конференции, обмениваются идеями.
Есть сообщества рационалистов, которые хотят, чтобы люди жили более рационально, сами стараются вести себя рационально, без предвзятости. Они продвигают эту идею в мир.
Такие люди хотят знать реальную информацию. Они часто отказываются от смартфонов или переключаются на черно-белый режим экрана, покидают соцсети. Среди подобных сообществ витают много идей о фильтрации информации.
Сообщества, которое фокусируется на организации знаний, не знаю. Такое ощущение, что люди забросили эту тему после успеха Google. Возможно, надо создать такое сообщество.
Какие видео или статьи стали для тебя озарением, после которых твоя жизнь поменялась? Читал ли ты Пола Грэма или Ричарда Хэмминга, например?
Я читал Пола Грэма, но в тот момент я уже знал много похожей информации. Мне нравятся статьи Грэма. Ричарда Хэмминга я не читал. Думаю, TED ощутимо повлиял.
Когда я учился в Кыргызстане в университете, то читал информацию для учебы, читал Wikipedia. Когда я переехал в Европу в Ирландию работать в Google, появилось больше свободного времени для книг и лекций. TED мне понравился тем, что он предлагает такую тему, о которой раньше ты не задумывался. К примеру, о медитации. Сам бы я возможно не начал искать информация о медитации.
После переезда в Ирландию, я оставался религиозным человеком, молился. Видео, которое серьезно повлияло на мое мировоззрение выступление Ричарда Докинза Militant atheist.
После этого видео у меня произошло первое пробуждение. В Google я оказался окружен многими европейскими нерелигиозными людьми, и мое мировоззрение начало потихоньку меняться.
Я перестал молиться, через год-два стал нерелигиозным, стал еще больше читать, начал задавать вопросы.
Почему получилось так, что я стал религиозным?
Кто написал историю Корана, историю Библии?
После этого у меня поменялось мнение о нашей вселенной, поменялась философия. Как я живу, ради чего живу, какие принципы в моей жизни должны быть.
Также я прочитал статью, узнал как много парниковых газов появляется от скота, и том, что поедание мяса сильно влияет на потепление климата. После этого задумался о вегетарианстве. Не сразу, но я стал вегетарианцем. Тоже серьезное решение.
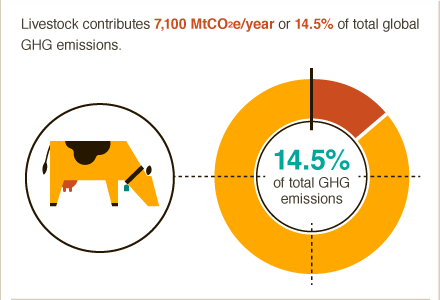
Источник
Я увидел калькулятор на одном сайте и он поменял мою диету, биологические привычки. Это сильный момент в моей жизни.
Думаю, я для любой области жизни найду видео или текст, который сильно повлиял на мое мнение.
Что думаешь о современном образовании? В чем главная проблема/задача? Какие есть точки приложения усилий?
Я много думал об образовании. Я бы хотел жить в мире, где люди умные, добрые и счастливые.
Думаю, проблема образования психологическая, проблема уверенности в себе. Вся важная информация, по-моему, уже доступна. Можно освоить любую науку на уровне лучших университетов мира. Учишь английский и для тебя нет границ.
Проблема чисто психологическая. Насколько я сам верю, что смогу? Если повезло с родителями, они в меня верят, то у меня получится. Если не повезло с родителями, они не верят в себя, не верят в детей, то будет гораздо сложнее. Тогда и я в себя не поверю, то не смогу. Тут вопрос везения. Хотя, уверенность дают и окружающие люди, не только родители. Я бы хотел, чтобы каждый человек в себя верил.
Еще мешает отсутствие критического мышления. Информация доступна, но люди не хотят в нее верить, потому что в нее верить неприятно. Они не хотят об этом думать, потому что это депрессивно. Рациональные люди смотрят на цифры и отделяют эмоции, принимают взвешенные решения. К примеру, о том, как они влияют на потепление климата.
Критическое мышление это, по-моему, основа интеллекта. Если ты прокачал память, наработал навыки решения задач, но не освоил критическое мышление, ты будешь решать не те задачи.
Критическое мышление логическое мышление без предвзятости, словно робот без эмоций решает задачу. Тема религии в этом плане показательна. Если заговорить с человеком о религии, то его легко обидеть заявлением, что его религия не права. Это обижает еще семью и друзей этого человека. Ситуация супер-эмоциональная. Мало кто умеет абстрагироваться и обсудить смысл религии, ее философию.
Критическое мышление чисто логическое мышление, где нет биологической составляющей человека. Где нет: Я плохо поел потому говорю, что завтра дела будет плохо. Такие вещи как голод не должны влиять на логические вычисления.
Президент страны с самой большой армией в мире говорит, что потепления климата нет и ситуация улучшится. Это громадная проблема. Мы живем в мире, где нехватка критического мышления проблема номер один. У Трампа есть вся информация. У тех, кто голосовал за Трампа, есть вся информация. Больше 4 млрд людей имеют доступ к Internet, но они не хотят верить в то, что им неприятно.
Мы животные. У нас много shortcuts. Ускоренный тип мышления хорош, когда человек увидел льва в кустах, и надо быстро убежать. Но когда гражданин выбирает президента страны, нужно мыслить логически, а не пользоваться сокращенным мышлением.
Вот полезные сайты на эту тему:
Какой первый шаг к критическому мышлению?
Изучить себя как животное. Если мало спать, то решения не рациональны. Если есть слишком мало или слишком много, решения принимать тяжелее.
Мы предвзяты и ищем закономерности слишком быстро. Черная кошка перешла дорогу, потом случилось что-то плохое. Это закономерность. Ты впервые приехал в Венгрию, встретил одного грубого человека, второго. Вернувшись домой, ты скажешь, что в Венгрии грубые люди. Слишком быстрый вывод.
Когда человек озвучивает неприятные выводы о нации или о конкретном человеке, я интересуюсь, сколько примеров неприятного есть у человека. Часто один-два. Пару примеров для выводах о миллионах людей также странно, как machine learning на основе двух точек.
У искусственного интеллекта не было бы такой проблемы. У ИИ другие проблемы. К примеру, отсутствие эмпатии. Человеку хватит взглянуть на собеседника, чтобы понять, что с ним. Не на основе анализа, а очень глубоко. ИИ этого будет не хватать. Или при общении парня и девушки человек предскажет, как у них сложатся отношения. Тут нам сильно помогаем биология, наша животная часть приспособилась к этому, но не приспособилась к big data.
У человека есть те или иные предвзятости, потому что эти предвзятости помогли выжить. Если бы мы размышляли лев в кустах спрятался или нет, нас бы съели. Надо помнить об этих предвзятостях.
Расскажи чем ты сейчас занимаешься?
Я давно увлекаюсь темой образования. Решил после 11 лет уйти из Google, потому что хотел поменять то, как образование работает.
Я сфокусировался на программистах, потому что я сам программист. Мы хотим чтобы образование было нацеленным, давало результаты.
Мы создали трехмесячную программу, где обучаем распределенным системам, алгоритмам и готовим к собеседованиям. В нашей команде работают менторы из Google, Facebook, Stripe, Amazon. Через три месяца обучения люди подают заявки в зарубежные компании, вроде Google.
Они составляют список компаний куда хотят попасть. Мы помогли десяткам программистов попасть в Google, Facebook, Stripe, Amazon, Microsoft, Bloomberg, DeepMind. Программисты, наши клиенты, платят только если получают желанную работу за границей.
Мы стараемся организовать информацию так, чтобы сохранить как можно больше информации о собеседованиях, о советах менторов. К примеру, ментор дает совет: На собеседованиях интервьюер иногда дает подсказку, чувствуйте этот момент. Ментор дал совет, мы его сразу фиксируем.
Мы стремимся, чтобы ментор один и тот же совет не повторял. Такая наша мечта. Чтобы знания ментор передавал за один раз. В других проектах ментор повторяет много раз: В резюме добавь хобби. Мы хотим, чтобы время человека не тратилось повторно. У нас такой подход к сохранению информации.
Всю информацию после интервью, в зависимости от NDA, люди отчуждают, мы это сохраняем, и категоризируем. В проекте уже более сотни интервью, скоро до нескольких сотен дойдем. Мы накапливаем информацию и после каждого интервью пополняем базу знаний. Когда новый человек присоединяется к программе, наша база знаний улучшается. Мы знаем, что важно на собеседовании, что происходит компаниях, какая у них культура в этих компаниях, чем отличается стиль.
У нас это работает. В последней группе 100% получили работу, 83% наших клиентов устроились в Google, Facebook, Amazon топ-3 компаний по мнению наших кандидатов.
Философия организации знаний работает. Мы это делаем не через онтолы, по-своему, у нас есть docs.outtalents.com. Тут мы публикуем большую часть документов. Какую-то часть не публикуем, держим внутри. Мы пытаемся помочь людям, даже если это не наши клиенты.
Мы экспериментируем с форматами, делаем видеозаписи семинаров. Возможно, скоро будем их публиковать. Создаем документы, постоянно их обновляем. После каждого интервью googledocs. После каждого комментария. Основной поток информации через текст. Мы экспериментируем с roam research, диаграммы, Whimsical, много экспериментируем, чтобы чтобы максимально эффективно помочь программистам добиться их целей.
Какие 2-3 совета можешь дать тем программистам и не только, кто хочет вырасти над собой, сменить работу/воспользоваться твоими услугами?
Советую всем найти способ проверить свой уровень по всем типам собеседований (для программистов это часто архитектура распределенных систем, алгоритмы, поведенческие вопросы), а также резюме и английский язык с теми, кто работал или работает в компаниях куда вы хотите попасть. Часто люди себя недооценивают (особенно с английским) или переоценивают (например, у программистов это часто происходит с поведенческими вопросами и архитектурой распределенных систем).
Обязательно ли быть программистом чтобы стать твоим клиентом? Может ли автор Хабра подаваться в Гугл или Амазон?
Подаваться в Гугл могут многие конечно, но Outtalent специализируется на только программистах пока.
Возьмут ли меня в Google X с реактивным ранцем?
Надеюсь, да! :)
Какие есть 2-3 очень интересных кейса из твоего проекта?
Алия Рысбек, например, попала в Google DeepMind, это их лаборатория искусственного интеллекта. Кроме этого она получила офферы от Facebook, Bloomberg, Amazon. Юра, который на мировой финал соревнования ICPC ездил, получил офферы от Google и Facebook. Есть ещё много старших программистов из России, Украины, Казахстана и Кыргызстана, которые получили офферы в Google, Facebook, Amazon, Microsoft. Планируем скоро много объявлений о таких успехах.
Какие 2-3 удивительных инсайта про трудоустройство ты обнаружил работая над своим проектом?
Мы думали, что из-за коронавируса рекрутинг и иммиграция почти остановится, но в конце лета компании крайне активно начали нанимать программистов. Выпускники нашего последнего выпуска собеседуются с Amazon, Bloomberg, Facebook, Google, Microsoft, Reddit, Snapchat, SpaceX, Spotify, Tesla и многими другими компаниями. Большинство компаний из этого списка нанимают сейчас и на многих из них мы фокусируемся.
Также мы поняли что очень важно правильно выстраивать последовательность собеседований в зависимости от скорости процессов компаний. Думаю, многим понятно, что надо сначала тренироваться на менее желанных компаниях и что важно чтобы несколько офферов параллельно приходило. Тогда легче торговаться о зарплате. Недавно мы помогли нашему выпускнику выторговать на $20,000 больше при переговорах с Amazon, но это было сложнее чем когда есть несколько офферов. Особенно сильно конкурируют между собой, по-моему, Google и Facebook. Чтобы эффективно синхронизировать процессы надо научиться общаться с рекрутерами и знать какие компании с какой скоростью обычно двигаются и какие компании требуют быстрого ответа если дают вам оффер.
Последний инсайт с которым готов поделиться это то, что конкуренция на должности с меньшим опытом по нашему вычислению в десятки раз выше. Поэтому мы теперь решили фокусироваться на программистах с опытом 2 или более лет после окончания учебы, но в любом случае, людей всех возрастов и профессий хотел бы призвать попробовать свои силы и подать в компанию мечты. Я понял, что реально многие смогут добиться этого.
Еще публикации с Тилеком Мамутовым
- Forbes: Как программист из Киргизии построил карьеру в Google и теперь помогает талантам из СНГ находить работу в США
- VC: Экс-сотрудник Google запустил сервис помощи русскоязычным программистам с трудоустройством в иностранные ИТ-компании
- Как программист из Кыргызстана Тилек Мамутов построил карьеру в Google
- YouTube: Секретная лаборатория Google X | 11 лет в Google