

Ванильный Yahoo
Итак, начнем с получения данных. Классический путь в этом случае API Yahoo. Недостатком является что это API не публичное, и по словам пользующихся людей постоянно что-то меняется и будет отваливаться. Боль на эту тему можно найти, например, там. Если нас такое не страшит то вперед, навстречу приключениям.
Обширная статья с описанием yahoo finance API недавно была на Хабре, есть где разгуляться
тем, кто любит Node.js. Мы же будем теребить питона, поэтому чтобы упростить себе жизнь вместо прямого обращения к API используем библиотеку yfinance. Будем надеяться, что перемены в исходном API будут отслежены создателями библиотеки, а нам останется только поддерживать актуальность используемой версии. Помимо упрощения жизни это допущение грозит в один прекрасный день превратить ваше приложение в неработающий кирпич, поэтому для долгосрочной перспективы я бы смотрел на два варианта обсуждаемых позже в статье.
Для начала ограничимся акциями на американском рыннке. Чтобы не допустить ошибку
Возьмем данные американской комиссии по ценным бумагам для сопоставлеия имен и тикеров. JSON можно стащить с их сайта. Я воспользовался удобной csv-шкой добытой в другом месте основанной на тех же данных. Ахтунг, в подобых списках могут быть компании снятые с торгов, поэтому рекоммендуются дополнительные проверки.
Например, в скачанном листе есть произодитель оборудования для полупроводниковой промышленности VSEA которую скупил AMAT и убрали с рынка лет 10 назад.
Для простоты создания интерфейса мы пилим его в стримлите. Это красиво и ОЧЕНЬ быстро в плане написания. Но если мы запихаем весь лист в 14 000 позиций в стримлитный селект бокс то интерфейс будет тормозить просто невероятно. Поэтому сделаем предварительную фильтрацию по вводу пользователя.
Если, например, ввести Microsoft то вас сразу перекинет в нужное, а если therapeutics то вас ждет лист с длинным скроллом, зато все просто летает по скорости. Готовый интерфейс незатейлив и прост, на все про все с импортом и проверками ушло 40 строчек. Если несколько упростить как в следующем примере, то выходит как раз 20, никакого кликбейта все честно.

Внутренности
import yfinance as yfimport streamlit as stimport pandas as pdfrom datetime import datetime# read SEC registered comaniessec_list = pd.read_csv('cik_ticker.csv', sep='|', names=['CIK', 'Ticker', 'Name', 'Exchange', 'SIC', 'Business', 'Incorporated', 'IRS'])name_options = ['Microsoft Corp']name_hint = st.sidebar.text_input(label='Company name contains')if name_hint is not None: name_options = sec_list[sec_list['Name'].str.contains(name_hint, case=False)]['Name'].tolist()if not name_options: name_options = ['Microsoft Corp']# get ticker from company name and dates from UIcompany_name = st.sidebar.selectbox('SEC listed companies', name_options)ticker = sec_list.loc[sec_list['Name'] == company_name, 'Ticker'].iloc[0]tickerData = yf.Ticker(ticker)end_date = st.sidebar.date_input('end date', value=datetime.now()).strftime("%Y-%m-%d")start_date = st.sidebar.date_input('start date', value=datetime(2010, 5, 31)).strftime("%Y-%m-%d")# make API queryticker_df = tickerData.history(period='1d', start=start_date, end=end_date)md_chart_1 = f"Price of **{ticker}** "md_chart_2 = f"Volume of **{ticker}** "if len(ticker_df) == 0: tickerData = yf.Ticker('MSFT') ticker_df = tickerData.history(period='1d', start=start_date, end=end_date) md_chart_1 = f"Invalid ticker **{ticker}** showing **MSFT** price" md_chart_2 = f"Invalid ticker **{ticker}** showing **MSFT** volume"# Add simple moving averageticker_df['sma 15'] = ticker_df.Close.rolling(window=15).mean()# plot graphsst.markdown(f"Demo app showing **Closing price** and **trade volume** of a selected ticker from Yahoo! finance API")st.markdown(md_chart_1)st.line_chart(ticker_df[['Close', 'sma 15']])st.markdown(md_chart_2)st.line_chart(ticker_df.Volume)
Иcxодники можно найти в репозитории, а поиграть с живым интерфейсом на heroku, ну если ничего не отвалится.
Альтернатива 1
Теперь рассмотрим альтернативы. Если нас не устраивает непубличный API Yahoo, которому сложно доверять в долгосрочном плане? Отличной алтернативой может быть API предлагаемое Quandl.
Этот вариант интерсен тем, что API официальное, платное только за премиум данные, и имеет интерфейсы на R и Python от самих же создателей. API очень щедрое для пользователей с бесплатным ключом, можно сделать 300 запросов за 10 секунд, 2000 за 10 минут и 50 000 в день. Аттракциона такой невиданной щедрости трудно найти в наши дни. Знакомьтесь- Quandl
Из недостатков некоторые довольно тривиальные данные вроде S&P 500 попали в премиальные. Пилим тот же нехитрый дашборд на 20 строк кода. Все так же просто. Для менее чем 50 запросов в день не нужен даже бесплатный ключ. Если запросов больше то надо регистрировать. Несколько упростив исходное приложение умещаемся в 20 строк (не забудьте вставить API key, бесплатно регистрируется там)
Чудеса компактности
import quandlimport streamlit as stfrom datetime import datetimequandl.ApiConfig.api_key = "YOUR_API_KEY"ticker = st.sidebar.text_input("Ticker", 'MSFT')end_date = st.sidebar.date_input('end date', value=datetime.now())start_date = st.sidebar.date_input('start date', value=datetime(2010, 5, 31))ticker_df = quandl.get("WIKI/" + ticker, start_date=start_date, end_date=end_date)ticker_df['sma 15'] = ticker_df.Close.rolling(window=15).mean()# plot graphsst.markdown(f"Demo app showing **Closing price** and **trade volume** of a selected ticker from Quandl API")st.markdown(f"Price of **{ticker}** ")st.line_chart(ticker_df[['Close', 'sma 15']])st.markdown(f"Volume of **{ticker}** ")st.line_chart(ticker_df['Volume'])
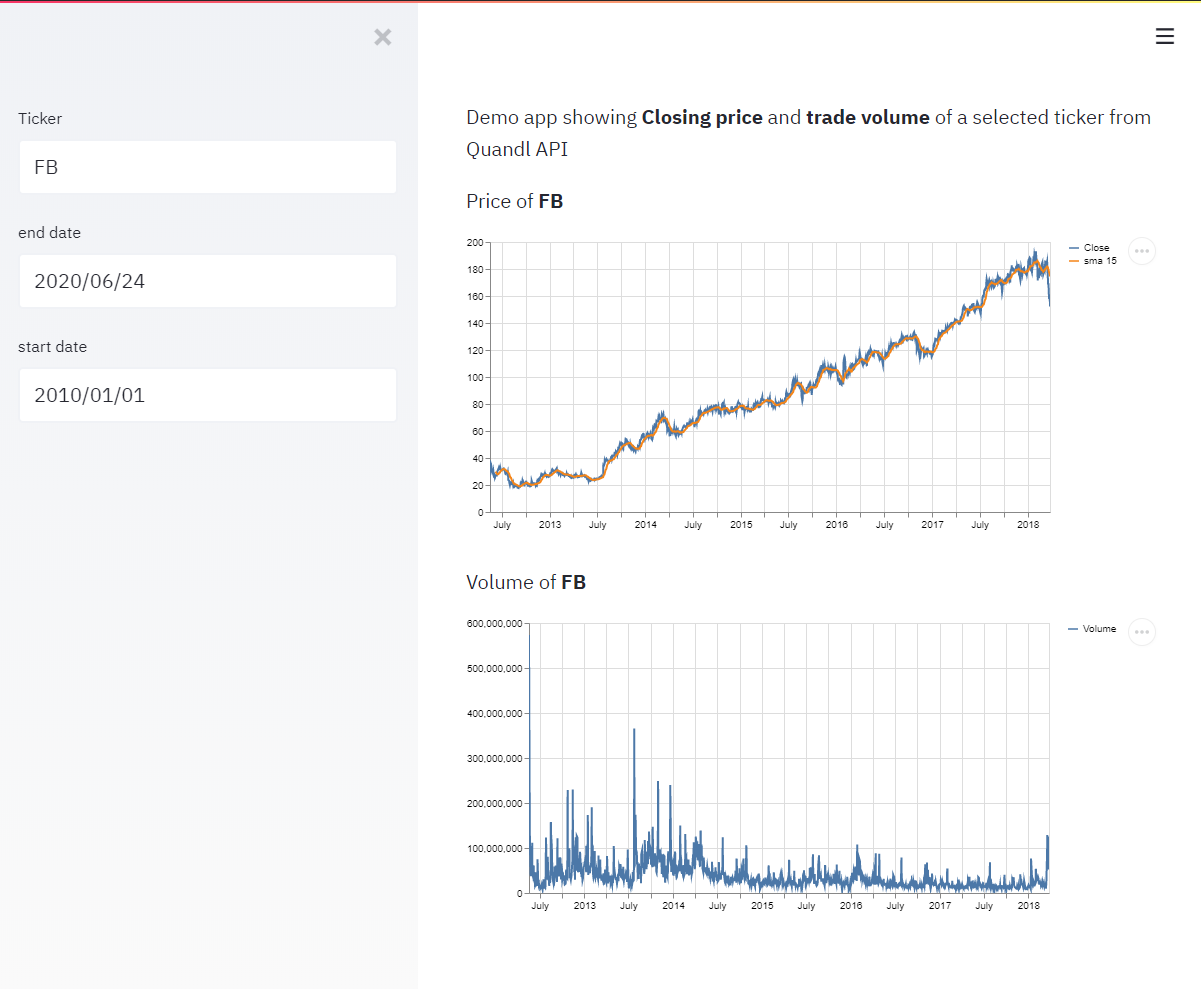
Далее можно повышать градус
Например, добавить классические метрики вроде корреляции с рынком (за рынок берем S&P 500). Для пущей научности добавляем сравнение с безрисковым инструментом (трехмесячные трежерис) и вычисляем альфу, бету и соотношение Шарпа. Это мы будем делать на примере другого источника, где на бесплатной подписке ограничивают не доступность групп данных, а только число запросов (хотя quandl нам тоже пригодится, данные про трежерис мы возьмем именно там).
Альтернатива 2
Наш второй конкурсант Alpha Vantage. Alpha Vantage API предлагает дневные и внутридневные данные по фондовым рынкам, технические индикаторы в готовом виде, данные рынков валют и даже крипты. По внутридневным доступны интервалы до 1 минуты. Если вы не занимаетесь
Смена источника данных требует минимальной коррекции кода, потому что все варианты умеют выдавать пандасовские датафреймы. Покрытие рынков вполне достойное, американским не ограничивается, по тикерам вроде GAZP.ME, SBER.ME вполне можно следить за нашим посконным. Из недостатков для Питона вам все равно понадобится некоторый обвес для работы с API если не хотите писать его сами. Он есть, но источник его не связан с авторами API и документированность оставляет желать лучшего.
Кроме того, если начать теребить API часто, то выясняется что бесплатно 500 запросов в день и 5 в минуту (пролистайте вверх и сравните с цифрами quandl, про невиданную щедрость я писал вполне серьезно!). Так что для всякой мелочи типа изменения временного диапазона или постоянно запрашиваемого тикера (вроде S&P 500) рекомендуется воспользоваться кешированием в стримлите, чтоб не дергать API понапрасну. Помните, что стримлит без кеширования перезапускает скрипт целиком после взаимодействия пользователя с интерфейсом, даже если он просто поменял границы отображаемого временного отрезка уже скачанных данных. Запрос с параметром outputsize='full' выдает всю историю за 20 лет, фильтрование по датам делаем уже на своей стороне, тоже помогает снизить число обращений.
Главное отличие от предыдущих случаев будет в том, что обращение к API теперь надо обернуть в функцию и навесить на нее кеширующий декоратор
@st.cache(suppress_st_warning=True, allow_output_mutation=True)def get_ticker_daily(ticker_input): ticker_data, ticker_metadata = ts.get_daily(symbol=ticker_input, outputsize='full') return ticker_data, ticker_metadata
В готовом виде наш новый апп с первичными признаками некой аналитики будет выглядеть примерно так:
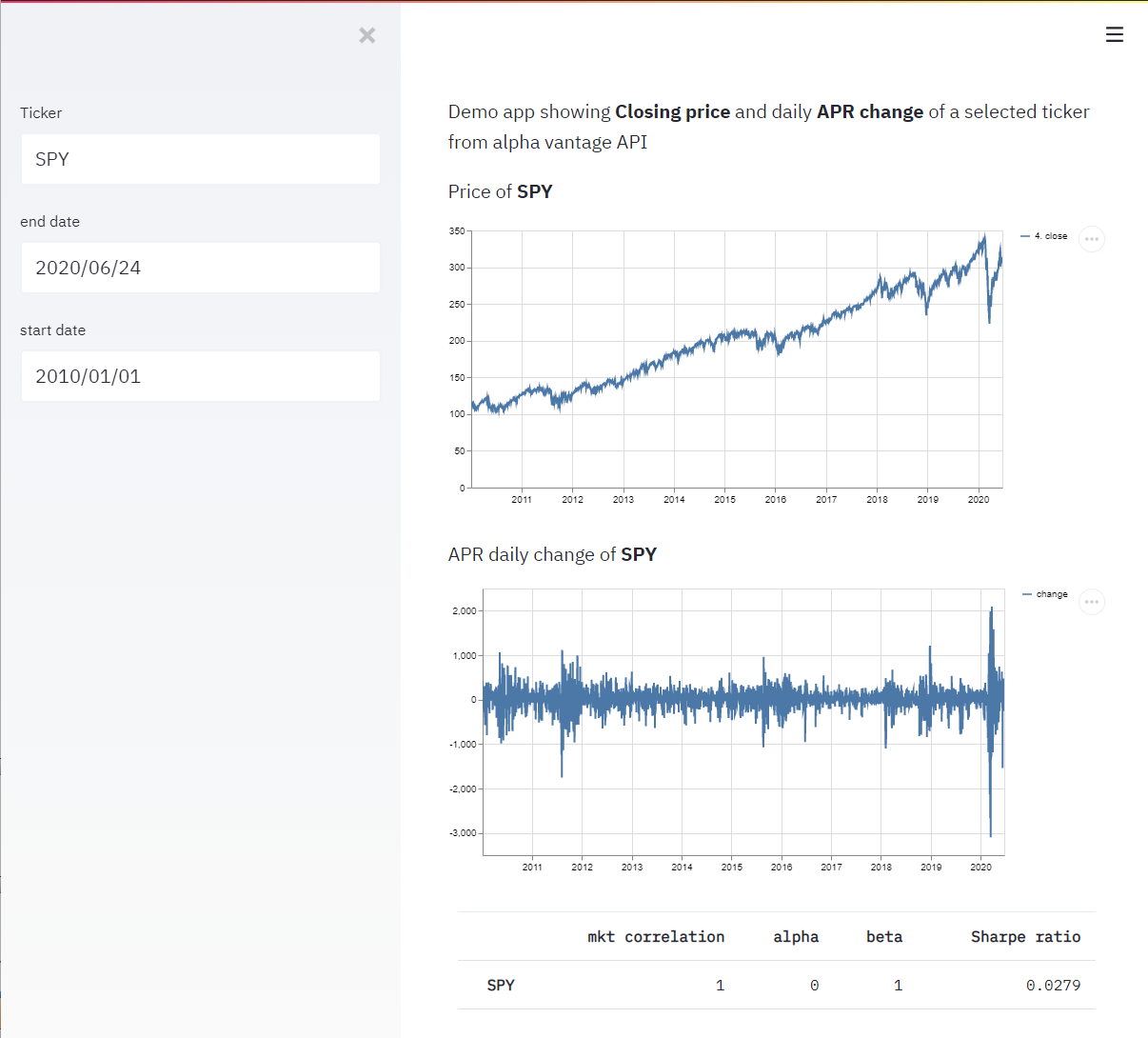
Потроха нехитрой аналитики
import streamlit as stfrom alpha_vantage.timeseries import TimeSeriesfrom datetime import datetimeimport quandlimport pandas as pdquandl.ApiConfig.api_key = "YOUR_QUANDL_API_KEY"ts = TimeSeries(key='YOUR_ALPHA_VANTAGE_API_KEY', output_format='pandas')st.markdown(f"Demo app showing **Closing price** and daily **APR change** of a selected ticker from alpha vantage API")ticker = st.sidebar.text_input("Ticker", 'MSFT').upper()end_date = st.sidebar.date_input('end date', value=datetime.now()).strftime("%Y-%m-%d")start_date = st.sidebar.date_input('start date', value=datetime(2015, 5, 31)).strftime("%Y-%m-%d")@st.cache(suppress_st_warning=True, allow_output_mutation=True)def get_ticker_daily(ticker_input): ticker_data, ticker_metadata = ts.get_daily(symbol=ticker_input, outputsize='full') return ticker_data, ticker_metadatatry: price_data, price_meta_data = get_ticker_daily(ticker) market_data, market_meta_data = get_ticker_daily('SPY') md_chart_1 = f"Price of **{ticker}** " md_chart_2 = f"APR daily change of **{ticker}** "except: price_data, price_meta_data = get_ticker_daily('MSFT') market_data, market_meta_data = get_ticker_daily('SPY') md_chart_1 = f"Invalid ticker **{ticker}** showing **MSFT** price" md_chart_2 = f"Invalid ticker **{ticker}** showing **MSFT** APR daily change of"def apr_change(pandas_series_input): return ((pandas_series_input - pandas_series_input.shift(periods=-1, fill_value=0)) / pandas_series_input) * 100 * 252price_data['change'] = apr_change(price_data['4. close'])market_data['change'] = apr_change(market_data['4. close'])price_data_filtered = price_data[end_date:start_date]market_data_filtered = market_data[end_date:start_date]stock_market_correlation = price_data_filtered['change'].corr(market_data_filtered['change'], method='pearson')# estimate risk free return via 3 months treasury bondstreasury_yield = quandl.get("FRED/TB3MS", start_date=start_date, end_date=end_date)rfr = treasury_yield['Value'].mean() # mean treasury yield over periodstock_volatility = price_data_filtered['change'].std()market_volatilidy = market_data_filtered['change'].std()stock_excess_return = price_data_filtered['change'].mean() - rfrmarket_excess_return = market_data_filtered['change'].mean() - rfrbeta = stock_market_correlation * stock_volatility / market_volatilidyalpha = stock_excess_return - beta * market_excess_returnsharpe = stock_excess_return / stock_volatilitymetrics_df = pd.DataFrame( data={'mkt correlation': [stock_market_correlation], 'alpha': [alpha], 'beta': [beta], 'Sharpe ratio': [sharpe]})metrics_df.index = [ticker]st.markdown(md_chart_1)st.line_chart(price_data_filtered['4. close'])st.markdown(md_chart_2)st.line_chart(price_data_filtered['change'])st.table(metrics_df)
Судя по хорошей корреляции индекса с самим собой и нулевой альфе грубой лажи удалось избежать. На всякий случай напомнбю альфа это превышение доходности инструмента над рынком, здесь и далее в процентах в годовом исчислении. Чем положительнее и больше тем бодрее растет акция по сравнению с рынком. Интервал сравнения для всех с 1 января 2010 года. Можно видеть на примере последних 10 лет, что Майкрософт (MSFT) растет не сильно выше рынка,

а вот Фейсбук (FB) или Амазон (AMZN) все еще существенно обгоняют.


Можно также убедиться, что, например, частные тюрьмы и прочий коммерческий ГУЛАГ (CXW, GEO)


не являются таким уж привлекательным активом, при Трампе так и вовсе стабильно идут вниз, в общем если только для хеджирования рисков.
Доставка streamlit аппа на дом
Переходим к последней части. Доставка конечного продукта пользователю, который сидит далеко за фаерволом, а публикация на открытом хостинге не вариант. Ну, например, вы сходили на тренинг по успешному успеху и теперь выдаете этот дашборд как часть пакета начинающего инвестора тем, кто прошел ваш вебинар за 199 000 руб (ходят слухи, что это разрушает карму и в следующих перерождениях такие люди становятся туалетными ершиками). Итак, пакуем продукт для доставки.
Просим пользователя установить ContainDS и Докера. Ставим себе. Запускаем базовый стримлит образ, указав папку с нашим поделием, кликнув на CMD доставляем нужные зависимости из requirements.txt. И наконец экспортируем все это добро в один *.containds файл. Сохраняем и шлем клиенту (не по емейлу конечно, наш образ весит без малого 600 мегабайт)

От клиента требуется загрузить файл и мышкой кликнуть на WEB. Никаких хакерных консолей, можно научить хоть тетенек в бухгалтерии. Будете потом гордиться, что у вас тетеньки в бухгалтерии гоняют сервисы в докерных контейнерах. Пошаговая инструкция.
Бонус
Ну и наконец для тех чтитателей или их клиентов, кто заинтересовался данными, но считает все эти докеры с жаваскриптами поверх питонов излишними свистелками и перделками. Для акул старой школы эксельный плагин для импорта данных из alpha vantage. Аналогичное для Quandl. Всем кто недавно ностальгировал в юбилейной трибьют-теме чуваки, про вас помнят!
Для фанатов винтажного на новый лад с маффинами, смузи и митболами есть вариант с гугловскими таблицами, и зиро кодинг и модное облако
Из моего короткого знакомства с тремя API мне показалось, что в целом самый щедрый это Quandl, особенно для платных клиентов. Если запросов мало, а платность не вариант то alpha vantage сгодится тоже. С yahoo настораживает вопрос кто же платит за угощение для всех, не исчезнет ли оно в один прекрасный день. Много примеров работы с Quandl и аналитики вообще можно найти во втором издании Mastering Python for Finance (есть на Либрусеке). Делитесь своими находками в области, в комментах статьи про yahoo finance API писали про Тинькова и другие варианты, но без подробностей
Фото на обложке поста Photo by M. B. M. on Unsplash