Рассматриваемая нами группировка отличилась тем, что она невыбрала для заражения какое-то определенное семейство RAT. Ватаках врамках кампании были замечены сразу несколько троянов (все вшироком доступе). Этой чертой группировка напомнила нам окрысином короле мифическом животном, которое состоит изгрызунов спереплетенными хвостами.
Оригинал взят измонографии К.Н.Россикова Мыши имышевидные грызуны, наиболее важные вхозяйственном отношении (1908г.)
Вчесть этого существа мыназвали рассматриваемую нами группировку RATKing. Вэтом посте мырасскажем подробно отом, как злоумышленники проводили атаку, какие инструменты они использовали, атакже поделимся своими соображениями относительно атрибуции этой кампании.
Ход атаки
Все атаки вэтой кампании проходили последующему алгоритму:
- Пользователь получал фишинговое письмо соссылкой наGoogle Drive.
- Поссылке жертва скачивала вредоносный VBS-скрипт, который прописывал DLL-библиотеку для загрузки конечного пейлоада вреестр Windows изапускал PowerShell, чтобы исполнитьее.
- DLL-библиотека внедряла конечный пейлоад собственно, один изиспользуемых злоумышленниками RAT всистемный процесс ипрописывала VBS-скрипт вавтозапуск, чтобы закрепиться взараженной машине.
- Конечный пейлоад исполнялся всистемном процессе идавал
злоумышленнику возможность управлять зараженным
компьютером.
Схематически это можно представить так:

Далее мысосредоточимся напервых трех этапах, поскольку нас интересует именно механизм доставки ВПО. Мынестанем подробно описывать механизм работы самих вредоносов. Они находятся вшироком доступе либо продаются наспециализированных форумах, либо ивовсе распространяются как проекты соткрытым исходным кодом, азначит, неуникальны для группировки RATKing.
Анализ этапов атаки
Этап1. Фишинговая рассылка
Атака начиналась стого, что жертва получала вредоносное письмо (злоумышленники использовали разные шаблоны стекстом, наскриншоте ниже приведен один изпримеров). Всообщении была ссылка налегитимное хранилище
drive.google.com, которая якобы вела
настраницу загрузки документа вформате PDF.
Пример фишингового письма
Однако наделе загружался вовсе неPDF-документ, аVBS-скрипт.
При переходе поссылке изписьма наскриншоте выше загружался файл сименем
Cargo Flight Details.vbs. Вэтом случае
злоумышленники даже непытались замаскировать файл под легитимный
документ.Втоже время врамках этой кампании мыобнаружили скрипт сименем
Cargo Trip Detail.pdf.vbs. Онуже мог сойти
залегитимный PDF, потому что поумолчанию Windows скрывает
расширение файлов. Правда, вэтом случае подозрение все еще могла
вызвать его иконка, соответствовавшая VBS-скрипту.Наэтом этапе жертва могла распознать обман: достаточно насекунду присмотреться кскачиваемым файлам. Однако втаких фишинговых кампаниях злоумышленники зачастую рассчитывают именно наневнимательного или спешащего пользователя.
Этап2. Работа VBS-скрипта
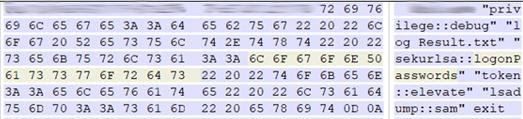
VBS-скрипт, который пользователь мог открыть понеосторожности, прописывал DLL-библиотеку вреестр Windows. Скрипт был обфусцирован: строки внем записаны ввиде байтов, разделенных произвольным символом.
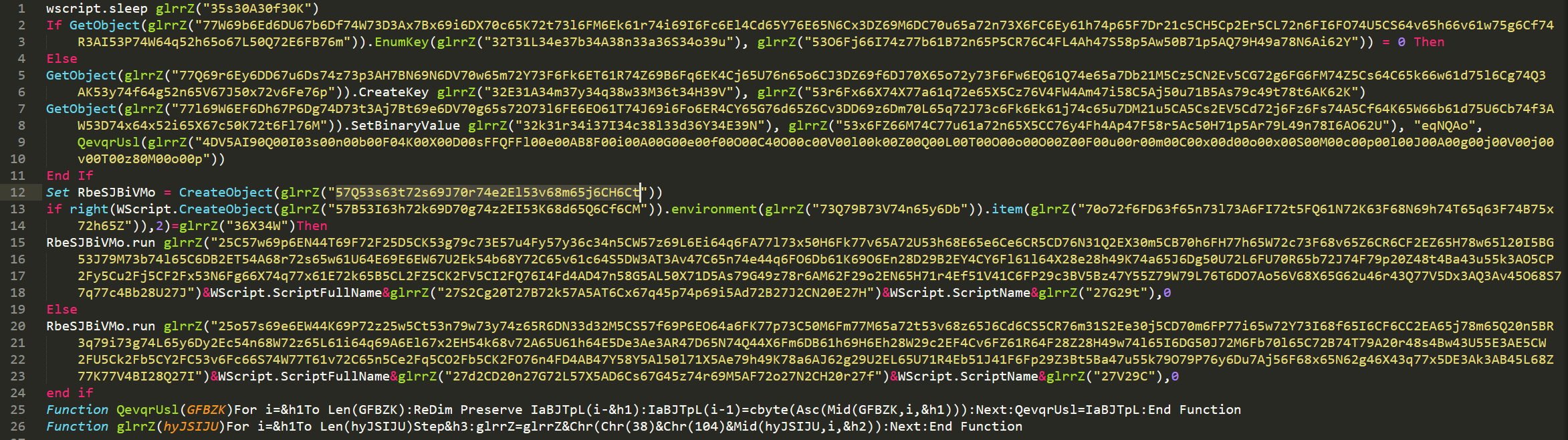
Пример обфусцированного скрипта
Алгоритм деобфускации достаточно прост: изобфусцированной строки исключался каждый третий символ, после чего результат декодировался изbase16в исходную строку. Например, иззначения
57Q53s63t72s69J70r74e2El53v68m65j6CH6Ct (выделено
наскриншоте выше) получалась строка WScript.Shell.Для деобфускации строк мыиспользовали функцию наPython:
def decode_str(data_enc): return binascii.unhexlify(''.join([data_enc[i:i+2] for i in range(0, len(data_enc), 3)]))
Ниже настроках 910 выделено значение, при деобфускации которого получался DLL-файл. Именно онзапускался наследующем этапе спомощью PowerShell.

Строка собфусцированным DLL
Каждая функция вVBS-скрипте выполнялась помере деобфускации строк.
После запуска скрипта вызывалась функция
wscript.sleep
сеепомощью выполнялось отложенное исполнение.Далее скрипт работал среестром Windows. Ониспользовал для этого технологию WMI. Сеепомощью создавался уникальный ключ, ивего параметр записывалось тело исполняемого файла. Обращение креестру через WMI выполнялось спомощью следующей команды:
GetObject(winmgmts {impersonationLevel=impersonate}!\\.\root\default:StdRegProv)

Запись, сделанная вреестре VBS-скриптом
Этап3. Работа DLL-библиотеки
Натретьем этапе вредоносная DLL-библиотека загружала конечный пейлоад, внедряла его всистемный процесс иобеспечивала автозапуск VBS-скрипта при входе пользователя всистему.
Запуск через PowerShell
DLL-библиотека исполнялась спомощью следующей команды вPowerShell:
[System.Threading.Thread]::GetDomain().Load((ItemProperty HKCU:\/\/\/Software\/\/\/<rnd_sub_key_name> ).<rnd_value_name>);[GUyyvmzVhebFCw]::EhwwK('WScript.ScriptFullName', 'rWZlgEtiZr', 'WScript.ScriptName'),0
Эта команда делала следующее:
- получала данные значения реестра сименем
rnd_value_nameэти данные представляли собой DLL-файл, написанный наплатформе .Net; - загружала полученный .Net-модуль впамять процесса
powershell.exeспомощью функции[System.Threading.Thread]::GetDomain().Load()(подробное описание функции Load() доступно насайте Microsoft); - исполняла функцию
GUyyvmzVhebFCw]::EhwwK()снее начиналось исполнение DLLбиблиотеки спараметрамиvbsScriptPath,xorKey,vbsScriptName. ПараметрxorKeyхранил ключ для расшифровки конечного пейлоада, апараметрыvbsScriptPathиvbsScriptNameпередавались для того, чтобы прописать VBS-скрипт вавтозапуск.
Описание DLL-библиотеки
Вдекомпилированном виде загрузчик выглядел так:
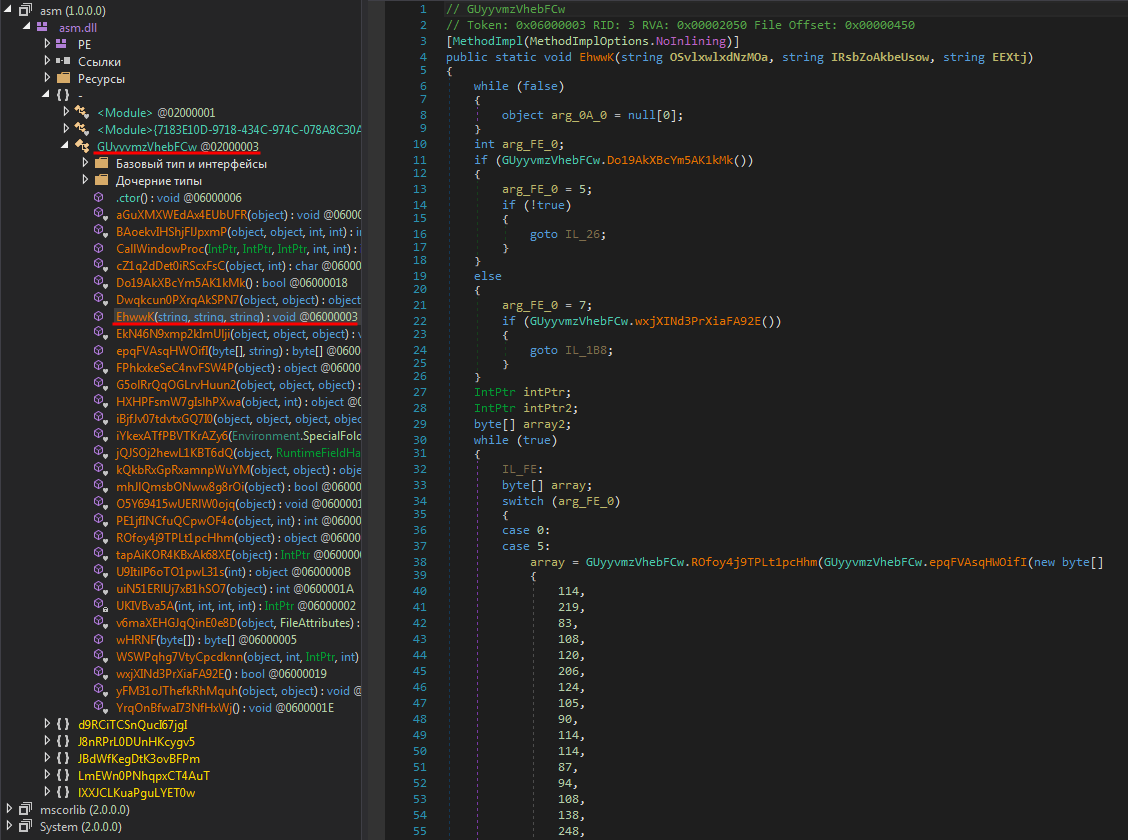
Загрузчик вдекомпилированном виде (красным подчеркнута функция, скоторой начиналось исполнение DLL-библиотеки)
Загрузчик защищен протектором .Net Reactor. Соснятием данного протектора отлично справляется утилита de4dot.
Данный загрузчик:
- осуществлял инжект пейлоада всистемный процесс (вданном примере
это
svchost.exe); - прописывал VBS-скрипт вавтозапуск.
Инжект пейлоада
Рассмотрим функцию, которую вызывал PowerShell-скрипт.

Функция, вызываемая PowerShell-скриптом
Данная функция осуществляла следующие действия:
- расшифровывала два массива данных (
arrayиarray2наскриншоте). Первоначально они были сжаты спомощью gzip изашифрованы алгоритмом XOR сключомxorKey; - копировала данные ввыделенные области памяти. Данные
из
arrayвобласть памяти, накоторую указывалintPtr(payload pointerнаскриншоте); данные изarray2вобласть памяти, накоторую указывалintPtr2(shellcode pointerнаскриншоте); - вызывала функцию
CallWindowProcA(описание этой функции есть насайте Microsoft) соследующими параметрами (ниже перечислены имена параметров, наскриншоте они идут втомже порядке, носрабочими значениями):
lpPrevWndFuncуказатель наданные изarray2;hWndуказатель настроку, содержащую путь кисполняемому файлуsvchost.exe;Msgуказатель наданные изarray;wParam,lParamпараметры сообщения (вданном случае эти параметры неиспользовались иимели значения 0);
- создавала файл
%AppData%\Microsoft\Windows\Start Menu\Programs\Startup\<name>.url, где<name>это первые 4символа параметраvbsScriptName(наскриншоте фрагмент кода сэтим действием начинается скомандыFile.Copy). Таким образом вредонос добавлял URL-файл всписок файлов для автозапуска при входе пользователя всистему итем самым закреплялся назараженном компьютере. URL-файл содержал ссылку наскрипт:
[InternetShortcut]URL = file : ///<vbsScriptPath>
Для понимания того, как осуществлялся инжект, мырасшифровали массивы данных
array и array2. Для этого
мыиспользовали следующую функцию наPython:
def decrypt(data, key): return gzip.decompress( bytearray([data[i] ^ key[i % len(key)] for i in range(len(data))])[4:])
Врезультате мывыяснили, что:
arrayпредставлял собой PE-файл это иесть конечный пейлоад;array2представлял собой шелл-код, необходимый для осуществления инжекта.
Шелл-код измассива
array2 передавался вкачестве
значения функции lpPrevWndFunc вфункцию
CallWindowProcA. lpPrevWndFunc функция
обратного вызова, еепрототип выглядит так:
LRESULT WndFunc( HWND hWnd, UINT Msg, WPARAM wParam, LPARAM lParam);
Таким образом, при запуске функции
CallWindowProcA
спараметрами hWnd, Msg,
wParam, lParamисполняется шелл-код
измассива array2 саргументами hWnd и
Msg. hWnd это указатель настроку,
содержащую путь кисполняемому файлу svchost.exe, а
Msg указатель наконечный пейлоад.Шелл-код получал адреса функций из
kernel32.dllиntdll32.dllпозначениям
хешей отихимен ивыполнял инжект конечного пейлоада впамять процесса
svchost.exe, используя технику Process Hollowing
(подробно оней можно прочитать вэтой статье). При инжекте
шелл-код:- создавал процесс
svchost.exeвприостановленном состоянии при помощи функцииCreateProcessW; - затем скрывал отображение секции вадресном пространстве
процесса
svchost.exeпри помощи функцииNtUnmapViewOfSection. Таким образом программа освобождала память оригинального процессаsvchost.exe, чтобы затем поэтому адресу выделить память для пейлоада; - выделял память для пейлоада вадресном пространстве процесса
svchost.exeпри помощи функцииVirtualAllocEx;

Начало процесса инжекта
- записывал содержимое пейлоада вадресное пространство процесса
svchost.exeпри помощи функцииWriteProcessMemory(как наскриншоте ниже); - возобновлял процесс
svchost.exeпри помощи функцииResumeThread.

Завершение процесса инжекта
Загружаемое ВПО
Врезультате описанных действий взараженной системе устанавливалась одна изнескольких вредоносных программ класса RAT. Втаблице ниже перечислены использованные ватаке вредоносы, которые мысуверенностью можем приписать одной группе злоумышленников, поскольку семплы обращались кодному итомуже серверу управления.
| Название ВПО |
Впервые замечено |
SHA-256 |
C&C |
Процесс, вкоторый осуществляется инжект |
|---|---|---|---|---|
| Darktrack |
16-04-2020 |
ea64fe672c953adc19553ea3b9118ce4ee88a14d92fc7e75aa04972848472702 |
kimjoy007.dyndns[.]org:2017 |
svchost |
| Parallax |
24-04-2020 |
b4ecd8dbbceaadd482f1b23b712bcddc5464bccaac11fe78ea5fd0ba932a4043 |
kimjoy007.dyndns[.]org:2019 |
svchost |
| WARZONE |
18-05-2020 |
3786324ce3f8c1ea3784e5389f84234f81828658b22b8a502b7d48866f5aa3d3 |
kimjoy007.dyndns[.]org:9933 |
svchost |
| Netwire |
20-05-2020 |
6dac218f741b022f5cad3b5ee01dbda80693f7045b42a0c70335d8a729002f2d |
kimjoy007.dyndns[.]org:2000 |
svchost |
Примеры распространяемого ВПО содним итемже сервером управления
Здесь примечательны две вещи.
Во-первых, сам факт, что злоумышленники использовали сразу несколько различных семейств RAT. Такое поведение нехарактерно для известных кибергруппировок, которые зачастую используют приблизительно одинаковый набор привычных для них инструментов.
Во-вторых, RATKing использовали вредоносы, которые либо продаются наспециализированных форумах занебольшую цену, либо ивовсе являются проектами соткрытым исходным кодом.
Более полный перечень использованного вкампании ВПО содной важной оговоркой приведен вконце статьи.
Огруппировке
Мынеможем отнести описанную вредоносную кампанию ккаким-либо известным злоумышленникам. Пока мысчитаем, что эти атаки совершила принципиально новая группировка. Как мыуже писали вначале, мыназвали ееRATKing.
Для создания VBS-скрипта группировка, вероятно, использовала инструмент, похожий наутилиту VBS-Crypter отразработчика NYAN-x-CAT. Наэто указывает схожесть скрипта, который создает эта программа, соскриптом злоумышленников. Вчастности, они оба:
- осуществляют отложенное исполнение спомощью функции
Sleep; - используют WMI;
- прописывают тело исполняемого файла вкачестве параметра ключа реестра;
- исполняют этот файл при помощи PowerShell вегоже адресном пространстве.
Для наглядности сравните команду PowerShell для запуска файла изреестра, которую использует скрипт, созданный спомощью VBS-Crypter:
((Get-ItemPropertyHKCU:\Software\NYANxCAT\).NYANxCAT);$text=-join$text[-1..-$text.Length];[AppDomain]::CurrentDomain.Load([Convert]::FromBase64String($text)).EntryPoint.Invoke($Null,$Null);
саналогичной командой, которую использовал скрипт злоумышленников:
[System.Threading.Thread]::GetDomain().Load((ItemProperty HKCU:\/\/\/Software\/\/\/<rnd_sub_key_name> ).<rnd_value_name>);[GUyyvmzVhebFCw]::EhwwK('WScript.ScriptFullName', 'rWZlgEtiZr', 'WScript.ScriptName'),0
Заметим, что вкачестве одного изпейлоадов злоумышленники использовали другую утилиту отNYAN-x-CAT LimeRAT.
Адреса C&C-серверов указывают наеще одну отличительную черту RATKing: группировка предпочитает сервисы динамического DNS (см. перечень C&Cв таблице сIoC).
IoC
Втаблице ниже приведен полный перечень VBS-скриптов, которые сбольшой вероятностью можно отнести кописанной кампании. Все эти скрипты похожи иосуществляют примерно одинаковую последовательность действий. Все они инжектят ВПО класса RAT вдоверенный процесс Windows. Увсех них адреса C&C зарегистрированы сиспользованием Dynamic DNS-сервисов.
Тем неменее, мынеможем утверждать, что все эти скрипты распространялись одними итемиже злоумышленниками, заисключением семплов содинаковыми адресами C&C (например, kimjoy007.dyndns.org).
| Название ВПО |
SHA-256 |
C&C |
Процесс, вкоторый осуществляется инжект |
|---|---|---|---|
| Parallax |
b4ecd8dbbceaadd482f1b23b712bcddc5464bccaac11fe78ea5fd0ba932a4043 |
kimjoy007.dyndns.org |
svchost |
00edb8200dfeee3bdd0086c5e8e07c6056d322df913679a9f22a2b00b836fd72 |
hope.doomdns.org |
svchost |
|
504cbae901c4b3987aa9ba458a230944cb8bd96bbf778ceb54c773b781346146 |
kimjoy007.dyndns.org |
svchost |
|
1487017e087b75ad930baa8b017e8388d1e99c75d26b5d1deec8b80e9333f189 |
kimjoy007.dyndns.org |
svchost |
|
c4160ec3c8ad01539f1c16fb35ed9c8c5a53a8fda8877f0d5e044241ea805891 |
franco20.dvrdns.org |
svchost |
|
515249d6813bb2dde1723d35ee8eb6eeb8775014ca629ede017c3d83a77634ce |
kimjoy007.dyndns.org |
svchost |
|
1b70f6fee760bcfe0c457f0a85ca451ed66e61f0e340d830f382c5d2f7ab803f |
franco20.dvrdns.org |
svchost |
|
b2bdffa5853f29c881d7d9bff91b640bc1c90e996f85406be3b36b2500f61aa1 |
hope.doomdns.org |
svchost |
|
c9745a8f33b3841fe7bfafd21ad4678d46fe6ea6125a8fedfcd2d5aee13f1601 |
kimjoy007.dyndns.org |
svchost |
|
1dfc66968527fbd4c0df2ea34c577a7ce7a2ba9b54ba00be62120cc88035fa65 |
franco20.dvrdns.org |
svchost |
|
c6c05f21e16e488eed3001d0d9dd9c49366779559ad77fcd233de15b1773c981 |
kimjoy007.dyndns.org |
cmd |
|
3b785cdcd69a96902ee62499c25138a70e81f14b6b989a2f81d82239a19a3aed |
hope.doomdns.org |
svchost |
|
4d71ceb9d6c53ac356c0f5bdfd1a5b28981061be87e38e077ee3a419e4c476f9 |
2004para.ddns.net |
svchost |
|
00185cc085f284ece264e3263c7771073a65783c250c5fd9afc7a85ed94acc77 |
hope.doomdns.org |
svchost |
|
0342107c0d2a069100e87ef5415e90fd86b1b1b1c975d0eb04ab1489e198fc78 |
franco20.dvrdns.org |
svchost |
|
de33b7a7b059599dc62337f92ceba644ac7b09f60d06324ecf6177fff06b8d10 |
kimjoy007.dyndns.org |
svchost |
|
80a8114d63606e225e620c64ad8e28c9996caaa9a9e87dd602c8f920c2197007 |
kimjoy007.dyndns.org |
svchost |
|
acb157ba5a48631e1f9f269e6282f042666098614b66129224d213e27c1149bb |
hope.doomdns.org |
cmd |
|
bf608318018dc10016b438f851aab719ea0abe6afc166c8aea6b04f2320896d3 |
franco20.dvrdns.org |
svchost |
|
4d0c9b8ad097d35b447d715a815c67ff3d78638b305776cde4d90bfdcb368e38 |
hope.doomdns.org |
svchost |
|
e7c676f5be41d49296454cd6e4280d89e37f506d84d57b22f0be0d87625568ba |
kimjoy007.dyndns.org |
svchost |
|
9375d54fcda9c7d65f861dfda698e25710fda75b5ebfc7a238599f4b0d34205f |
franco20.dvrdns.org |
svchost |
|
128367797fdf3c952831c2472f7a308f345ca04aa67b3f82b945cfea2ae11ce5 |
kimjoy007.dyndns.org |
svchost |
|
09bd720880461cb6e996046c7d6a1c937aa1c99bd19582a562053782600da79d |
hope.doomdns.org |
svchost |
|
0a176164d2e1d5e2288881cc2e2d88800801001d03caedd524db365513e11276 |
paradickhead.homeip.net |
svchost |
|
0af5194950187fd7cbd75b1b39aab6e1e78dae7c216d08512755849c6a0d1cbe |
hope.doomdns.org |
svchost |
|
| Warzone |
3786324ce3f8c1ea3784e5389f84234f81828658b22b8a502b7d48866f5aa3d3 |
kimjoy007.dyndns.org |
svchost |
db0d5a67a0ced6b2de3ee7d7fc845a34b9d6ca608e5fead7f16c9a640fa659eb |
kimjoy007.dyndns.org |
svchost |
|
| Netwire |
6dac218f741b022f5cad3b5ee01dbda80693f7045b42a0c70335d8a729002f2d |
kimjoy007.dyndns.org |
svchost |
| Darktrack |
ea64fe672c953adc19553ea3b9118ce4ee88a14d92fc7e75aa04972848472702 |
kimjoy007.dyndns.org |
svchost |
| WSH RAT |
d410ced15c848825dcf75d30808cde7784e5b208f9a57b0896e828f890faea0e |
anekesolution.linkpc.net |
RegAsm |
|
Lime |
896604d27d88c75a475b28e88e54104e66f480bcab89cc75b6cdc6b29f8e438b |
softmy.duckdns.org |
RegAsm |
| QuasarRAT |
bd1e29e9d17edbab41c3634649da5c5d20375f055ccf968c022811cd9624be57 |
darkhate-23030.portmap.io |
RegAsm |
12044aa527742282ad5154a4de24e55c9e1fae42ef844ed6f2f890296122153b |
darkhate-23030.portmap.io |
RegAsm |
|
be93cc77d864dafd7d8c21317722879b65cfbb3297416bde6ca6edbfd8166572 |
darkhate-23030.portmap.io |
RegAsm |
|
933a136f8969707a84a61f711018cd21ee891d5793216e063ac961b5d165f6c0 |
darkhate-23030.portmap.io |
RegAsm |
|
71dea554d93728cce8074dbdb4f63ceb072d4bb644f0718420f780398dafd943 |
chrom1.myq-see.com |
RegAsm |
|
0d344e8d72d752c06dc6a7f3abf2ff7678925fde872756bf78713027e1e332d5 |
darkhate-23030.portmap.io |
RegAsm |
|
0ed7f282fd242c3f2de949650c9253373265e9152c034c7df3f5f91769c6a4eb |
darkhate-23030.portmap.io |
RegAsm |
|
aabb6759ce408ebfa2cc57702b14adaec933d8e4821abceaef0c1af3263b1bfa |
darkhate-23030.portmap.io |
RegAsm |
|
1699a37ddcf4769111daf33b7d313cf376f47e92f6b92b2119bd0c860539f745 |
darkhate-23030.portmap.io |
RegAsm |
|
3472597945f3bbf84e735a778fd75c57855bb86aca9b0a4d0e4049817b508c8c |
darkhate-23030.portmap.io |
RegAsm |
|
809010d8823da84cdbb2c8e6b70be725a6023c381041ebda8b125d1a6a71e9b1 |
darkhate-23030.portmap.io |
RegAsm |
|
4217a2da69f663f1ab42ebac61978014ec4f562501efb2e040db7ebb223a7dff |
darkhate-23030.portmap.io |
RegAsm |
|
08f34b3088af792a95c49bcb9aa016d4660609409663bf1b51f4c331b87bae00 |
darkhate-23030.portmap.io |
RegAsm |
|
79b4efcce84e9e7a2e85df7b0327406bee0b359ad1445b4f08e390309ea0c90d |
darkhate-23030.portmap.io |
RegAsm |
|
12ea7ce04e0177a71a551e6d61e4a7916b1709729b2d3e9daf7b1bdd0785f63a |
darkhate-23030.portmap.io |
RegAsm |
|
d7b8eb42ae35e9cc46744f1285557423f24666db1bde92bf7679f0ce7b389af9 |
darkhate-23030.portmap.io |
RegAsm |
|
def09b0fed3360c457257266cb851fffd8c844bc04a623c210a2efafdf000d5c |
darkhate-23030.portmap.io |
RegAsm |
|
50119497c5f919a7e816a37178d28906fb3171b07fc869961ef92601ceca4c1c |
darkhate-23030.portmap.io |
RegAsm |
|
ade5a2f25f603bf4502efa800d3cf5d19d1f0d69499b0f2e9ec7c85c6dd49621 |
darkhate-23030.portmap.io |
RegAsm |
|
189d5813c931889190881ee34749d390e3baa80b2c67b426b10b3666c3cc64b7 |
darkhate-23030.portmap.io |
RegAsm |
|
c3193dd67650723753289a4aebf97d4c72a1afe73c7135bee91c77bdf1517f21 |
darkhate-23030.portmap.io |
RegAsm |
|
a6f814f14698141753fc6fb7850ead9af2ebcb0e32ab99236a733ddb03b9eec2 |
darkhate-23030.portmap.io |
RegAsm |
|
a55116253624641544175a30c956dbd0638b714ff97b9de0e24145720dcfdf74 |
darkhate-23030.portmap.io |
RegAsm |
|
d6e0f0fb460d9108397850169112bd90a372f66d87b028e522184682a825d213 |
darkhate-23030.portmap.io |
RegAsm |
|
522ba6a242c35e2bf8303e99f03a85d867496bbb0572226e226af48cc1461a86 |
darkhate-23030.portmap.io |
RegAsm |
|
fabfdc209b02fe522f81356680db89f8861583da89984c20273904e0cf9f4a02 |
darkhate-23030.portmap.io |
RegAsm |
|
08ec13b7da6e0d645e4508b19ba616e4cf4e0421aa8e26ac7f69e13dc8796691 |
darkhate-23030.portmap.io |
RegAsm |
|
8433c75730578f963556ec99fbc8d97fa63a522cef71933f260f385c76a8ee8d |
darkhate-23030.portmap.io |
RegAsm |
|
99f6bfd9edb9bf108b11c149dd59346484c7418fc4c455401c15c8ac74b70c74 |
darkhate-23030.portmap.io |
RegAsm |
|
d13520e48f0ff745e31a1dfd6f15ab56c9faecb51f3d5d3d87f6f2e1abe6b5cf |
darkhate-23030.portmap.io |
RegAsm |
|
9e6978b16bd52fcd9c331839545c943adc87e0fbd7b3f947bab22ffdd309f747 |
darkhate-23030.portmap.io |
RegAsm |