
В этой статье, переводом которой мы решили поделиться специально к старту курса о Data Science, автор представляет новый пакет Python для генерации кластерограмм из решений кластеризации. Библиотека была разработана в рамках исследовательского проекта Urban Grammar и совместима со scikit-learn и библиотеками с поддержкой GPU, такими как cuML или cuDF в рамках RAPIDS.AI.
Когда мы хотим провести кластерный анализ для выявления групп в наших данных, мы часто используем алгоритмы типа метода k-средних, которые требуют задания количества кластеров. Но проблема в том, что мы обычно не знаем, сколько кластеров существует.
Существует множество методов определения правильного числа, например силуэты или локтевой сгиб. Но они обычно не дают представления о том, что происходит между различными вариантами, поэтому цифры немного абстрактны.
Маттиас Шонлау предложил другой подход кластерограмму. Кластерограмма это двухмерный график, отражающий потоки наблюдений между классами по мере добавления кластеров. Это говорит вам о том, как перетасовываются ваши данные и насколько хороши ваши сплиты. Тал Галили позже реализовал кластерограмму для k-средних в R. Я использовал реализацию Таля, перенёс ее на Python и создал clustergram пакет Python для создания кластерограмм.
clustergram в настоящее время поддерживает метод k-средних, использование scikit-learn (включая реализацию Mini-Batch) и RAPIDS.AI cuML (если у вас есть GPU с поддержкой CUDA), Gaussian Mixture Model (только scikit-learn) и иерархическую кластеризацию на основе scipy.hierarchy. В качестве альтернативы мы можем создать кластерограмму на основе меток и данных, полученных с помощью альтернативных пользовательских алгоритмов кластеризации. Пакет предоставляет API, подобный sklearn, и строит кластерные диаграммы с помощью matplotlib, что даёт ему широкий выбор вариантов оформления в соответствии со стилем вашей публикации.
Установка
Установить clustergram можно при помощи conda или pip:
conda install clustergram -c conda-forge
или
pip install clustergram
В любом случае вам нужно установить выбранный бэкенд (scikit-learn и scipy или cuML).
from clustergram import Clustergramimport urbangrammar_graphics as uggimport seaborn as snsimport matplotlib.pyplot as pltfrom sklearn.preprocessing import scalesns.set(style='whitegrid')
Давайте рассмотрим несколько примеров, чтобы понять, как выглядит кластерограмма и что с ней делать.
Набор данных о цветке ириса
Первый пример, который мы пытаемся проанализировать с помощью кластерограммы, это знаменитый набор данных о цветке ириса. Он содержит данные по трём видам цветков ириса с измерением ширины и длины чашелистиков, а также и ширины и длины лепестков. Мы можем начать с разведки:
iris = sns.load_dataset("iris")g = sns.pairplot(iris, hue="species", palette=ugg.COLORS[1:4])g.fig.suptitle("Iris flowers", y=1.01)

Похоже, что setosa относительно чётко определённая группа, тогда как разница между versicolor и virginica меньше, поскольку они частично перекрываются (или, в случае ширины чашелистика, полностью).
Итак, мы знаем, как выглядят данные. Теперь мы можем увидеть кластерограмму. Помните, мы знаем, что существует три кластера, и в идеале мы должны быть в состоянии распознать это по кластерограмме. Я говорю в идеале, потому что, даже если есть известные метки, это не значит, что наши данные или метод кластеризации способны различать эти классы.
Давайте начнём с кластеризации методом k-средних. Чтобы получить стабильный результат, мы можем запустить кластерную программу с 1000 инициализаций.
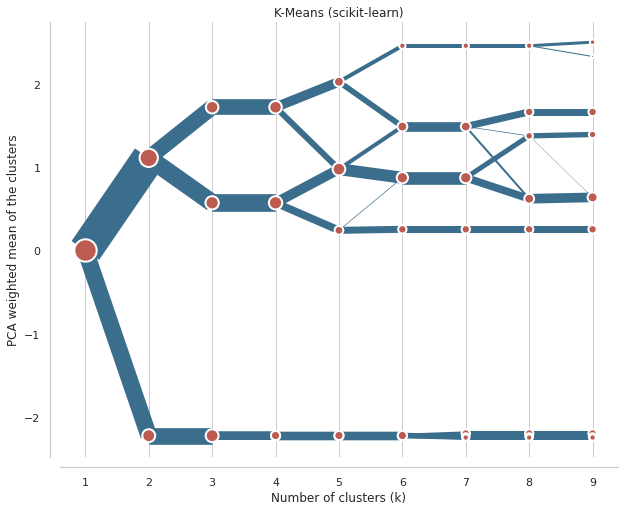
data = scale(iris.drop(columns=['species']))cgram = Clustergram(range(1, 10), n_init=1000)cgram.fit(data)ax = cgram.plot( figsize=(10, 8), line_style=dict(color=ugg.COLORS[1]), cluster_style={"color": ugg.COLORS[2]},)ax.yaxis.grid(False)sns.despine(offset=10)ax.set_title('K-Means (scikit-learn)')

На оси x мы видим количество кластеров. Точки представляют собой центр каждого кластера (по умолчанию), взвешенный по первой главной компоненте (это помогает сделать диаграмму более читабельной). Линии, соединяющие точки, и их толщина представляют наблюдения, перемещающиеся между кластерами. Поэтому мы можем прочитать, когда новые кластеры образуются как расщепление одного существующего класса и когда они образуются на основе наблюдений из двух кластеров.
Мы ищем разделение, т. е. отвечаем на вопрос, принёс ли дополнительный кластер какое-либо значимое разделение? Шаг от одного кластера к двум большой хорошее и чёткое разделение. От двух до трёх свидетельство довольно хорошего раскола в верхней ветви. Но с 3 по 4 видимой разницы нет, потому что новый четвёртый кластер почти не отличается от существующей нижней ветви. Хотя сейчас она разделена на две части, это разделение не даёт нам много информации. Таким образом, можно сделать вывод, что идеальное количество кластеров для данных Iris три.
Мы также можем проверить некоторую дополнительную информацию, например оценку силуэта или оценку Калинского Харабазса.
fig, axs = plt.subplots(2, figsize=(10, 10), sharex=True)cgram.silhouette_score().plot( xlabel="Number of clusters (k)", ylabel="Silhouette score", color=ugg.COLORS[1], ax=axs[0],)cgram.calinski_harabasz_score().plot( xlabel="Number of clusters (k)", ylabel="Calinski-Harabasz score", color=ugg.COLORS[1], ax=axs[1],)sns.despine(offset=10)

По этим графикам можно предположить наличие 34 кластеров по аналогии с кластерограммой, но они не очень убедительны.
Набор данных о пингвинах со станции Палмера
Теперь попробуем другие данные, где кластеры оценить немного сложнее. Пингвины Палмера содержат данные, подобные тем, что в примере Iris, но в нём измеряются несколько признаков трёх видов пингвинов.
penguins = sns.load_dataset("penguins")g = sns.pairplot(penguins, hue="species", palette=ugg.COLORS[3:])g.fig.suptitle("Palmer penguins", y=1.01)

Глядя на ситуацию, мы видим, что перекрытие между видами гораздо выше, чем раньше. Скорее всего, идентифицировать их будет гораздо сложнее. Кроме того, мы знаем, что существует три кластера, но это не означает, что данные способны их различать. В этом случае может быть особенно сложно отличить пингвинов Адели от антарктических пингвинов.
data = scale(penguins.drop(columns=['species', 'island', 'sex']).dropna())cgram = Clustergram(range(1, 10), n_init=1000)cgram.fit(data)ax = cgram.plot( figsize=(10, 8), line_style=dict(color=ugg.COLORS[1]), cluster_style={"color": ugg.COLORS[2]},)ax.yaxis.grid(False)sns.despine(offset=10)ax.set_title("K-Means (scikit-learn)")

Мы ищем разделения, и эта кластерограмма показывает достаточное их количество. На самом деле определить оптимальное количество кластеров довольно сложно. Однако, поскольку мы знаем, что происходит между различными вариантами, мы можем поиграть с этим. Если у нас есть причина быть консервативными, мы можем обойтись 4 кластерами (я знаю, это уже больше, чем первоначальный вид). Но и дальнейшее разделение также разумно, а это указывает на то, что даже более высокая детализация может дать полезную информацию, что могут существовать значимые группы.
Можно ли сказать, что их три? Поскольку мы знаем, что их должно быть три... Ну, не совсем. Разница между разделениями 23 и 34 незначительна. Однако здесь виновником является метод K ближайших соседей, а не кластерограмма. Он просто не может правильно кластеризовать эти данные из-за наложений и общей структуры. Давайте посмотрим, как работает смешанная Гауссова модель (Gaussian Mixture).
cgram = Clustergram(range(1, 10), n_init=100, method="gmm")cgram.fit(data)ax = cgram.plot( figsize=(10, 8), line_style=dict(color=ugg.COLORS[1]), cluster_style={"color": ugg.COLORS[2]},)ax.yaxis.grid(False)sns.despine(offset=10)ax.set_title("Gaussian Mixture Model (scikit-learn)")

Результат очень похож, хотя разница между третьим и четвёртым разделениями более выражена. Даже здесь я бы, вероятно, выбрал решение с четырьмя кластерами.
Подобная ситуация случается очень часто. Идеального случая не существует. В конечном счёте нам необходимо принять решение об оптимальном количестве кластеров. Clustergam даёт нам дополнительные сведения о том, что происходит между различными вариантами, как они расходятся. Можно сказать, что вариант с четырьмя кластерами в данных Iris не помогает. Также можно сказать, что пингвины Палмера могут быть сложными для кластеризации с помощью k-средних, что нет решающего правильного решения. Кластерограмма не даёт простого ответа, но она даёт нам лучшее понимание, и только от нас зависит, как мы её [кластерограмму] интерпретируем.
Установить clustergram можно с помощью conda install clustergram -c conda-forge или pip install clustergram. В любом случае вам всё равно придётся установить бэкенд кластеризации: либо scikit-learn, либо cuML. Документация доступна здесь, а исходный код здесь, он выпущен под лицензией MIT.
Если вы хотите поиграть с примерами из этой статьи, блокнот Jupyter находится на GitHub. Вы также можете запустить его в среде interactive binder в браузере. Более подробную информацию можно найти в блоге Тала Галили и оригинальных статьях Матиаса Шонлау.
Вполне понятно, что идеальной кластеризации не существует. И даже сегодня, с учётом всего прогресса искусственного интеллекта, для принятия сложных решений о данных по-прежнему нужен человек. Если вам интересна наука о данных область, в которой такие решения принимаются постоянно вы можете обратить внимание на наш курс о Data Science, где через подкреплённую теорией практику студенты учатся ориентироваться в данных, делать обоснованные выводы и действовать с открытыми глазами.

Узнайте, как прокачаться и в других специальностях или освоить их с нуля:
Другие профессии и курсыПРОФЕССИИ
КУРС