

В этом материале я расскажу о том, что такое Jenkins и Selenium, и остановлюсь на методах их интеграции. Если у вас уже есть некоторый опыт работы с этими системами, но вы интересуетесь тем, как наладить их совместную работу, вы можете сразу же перейти к соответствующему разделу.
Что такое Jenkins?
Jenkins это опенсорсный DevOps-инструмент, который пользуется популярностью в деле организации процессов непрерывной интеграции и непрерывной доставки программного обеспечения. Это платформонезависимое приложение, написанное на Java. Оно представляет собой систему для сборки проектов. В частности, с его помощью собирают проекты из исходного кода, запускают модульные тесты, рассылают отчёты о сборках соответствующим членам команды разработчиков.
Подробнее о Jenkins можно почитать здесь.
Что такое Selenium?
Selenium это опенсорсный инструмент, который широко используется для автоматизации тестирования веб-приложений. Пользоваться им просто, существуют форумы по Selenium, куда может обратиться тот, кто столкнулся с какими-то проблемами. Благодаря этому Selenium обрёл определённую популярность в кругах тестировщиков ПО. В состав Selenium входят четыре основных компонента: Selenium IDE, Selenium RC, Selenium WebDriver и Selenium Grid. Они созданы в расчёте на решение различных задач. Selenium даёт тому, кто им пользуется, возможности по кросс-браузерному и параллельному тестированию веб-приложений. Это позволяет тестировщикам выполнять испытания приложений в разных операционных системах и браузерах, что, в частности, даёт им возможность проверить совместимость веб-проекта с различными браузерами.
Если вас интересуют подробности о Selenium посмотрите этот материал.
Теперь, после того, как я в двух словах рассказала о Jenkins и Selenium, пришло время серьёзно заняться вопросами интеграции этих инструментов. Но, прежде чем об этом говорить, надо задаться вопросом о том, установлены ли они в системе. Поэтому давайте сначала обсудим их установку и настройку.
Установка, настройка и запуск Jenkins
Шаг 1 Для того чтобы загрузить Jenkins можно воспользоваться соответствующей ссылкой на официальном сайте проекта. Нас, в частности, интересует .war-файл Jenkins.
Шаг 2 Загрузим файл jenkins.war и сохраним его в выбранную директорию.
Шаг 3 Откроем окно командной строки и перейдём в папку, в которой хранится загруженный .war-файл.
Шаг 4 Выполним команду
java -jar Jenkins.war.
Будет запущен сервер Jenkins.Шаг 5 Обычно Jenkins по умолчанию запускается на порте
8080. Если этим портом уже пользуется какой-то другой
сервис, можно указать при запуске Jenkins другой порт,
воспользовавшись командой такого вида:
java -jar jenkins.war --httpPort=8081
В подобной команде можно указать любой свободный порт, а не только
8081. Этот порт и будет использоваться сервером
Jenkins.
При первом запуске Jenkins будет сгенерирован пароль, который выводится в консоли, в выделенной области, показанной ниже. Пароль на изображении скрыт. Он используется при установке Jenkins.

В консоли, после успешного завершения установки, можно будет увидеть сообщение
Jenkins is fully up and running.Шаг 6 Запустим браузер и перейдём к
localhost.
Как уже говорилось, по умолчанию Jenkins запускается на порте
8080. В моём случае порт был изменён на
8081, именно к этому порту localhost мне
и нужно подключиться.После этого откроется страница настроек Jenkins. Она используется для создания административной учётной записи.
Шаг 7 Введём в соответствующее поле пароль, который ранее был показан в консоли, и нажмём на кнопку
Continue для
продолжения настройки системы.
Шаг 8 После ввода пароля система предложит нам установить плагины.

Если вы не знаете точно о том, какие именно плагины вам понадобятся можете выбрать вариант
Install suggested plugins. Это
приведёт к установке набора наиболее часто используемых плагинов.
Но если вы знаете о том, что именно вам нужно, основываясь,
например, на требованиях к проекту, вы можете выбрать вариант
Select plugins to install и самостоятельно выбрать
плагины для установки.После этого плагины будут загружены и установлены.
Шаг 9 После успешной установки плагинов система предложит создать учётную запись администратора, для чего нужно будет ввести имя пользователя, пароль и адрес электронной почты. После того, как эта учётная запись создана, нас перенаправят в панель управления Jenkins.

Существует множество способов интеграции Jenkins с Selenium WebDriver. Некоторые из них мы рассмотрим ниже. Разные способы интеграции этих систем применимы в различных условиях.
Первый метод интеграции Jenkins с Selenium
Шаг 1 В панели управления Jenkins щёлкнем по значку
New Item для создания нового проекта. Укажем имя
проекта и выберем вариант Freestyle Project. После
этого нажмём OK.

Шаг 2 На вкладке свойств проекта
General
введём, в поле Description, описание проекта.
Шаг 3 На вкладке
Source Code Management выберем
None в группе параметров Source Code
Management.
Шаг 4 Jenkins позволяет планировать задания по сборке проектов. Время запуска заданий указывают в таком формате:
MINUTE HOUR DOM MONTH DOW
Смысл этих сокращений раскрыт в следующей таблице
| Сокращённое наименование | Описание |
| MINUTE | Минуты в пределах часа (0 59) |
| HOUR | Часы в пределах дня (0 23) |
| DOM | День месяца (1 31) |
| MONTH | Месяц (1 12) |
| DOW | День недели (0 7), где воскресенье может быть представлено значениями 0 и 7 |
Шаг 5 Создадим проект, который будем применять для запуска тестов с использованием Selenium WebDriver и TestNG.
Вот код на Java:
package Pages;import static org.testng.Assert.assertEquals;import java.util.concurrent.TimeUnit;import org.openqa.selenium.By;import org.openqa.selenium.WebDriver;import org.openqa.selenium.chrome.ChromeDriver;import org.testng.annotations.AfterTest;import org.testng.annotations.BeforeTest;import org.testng.annotations.Test;public class LoginPage {WebDriver driver;@BeforeTestpublic void setUp() {System.setProperty("webdriver.chrome.driver", "C:\\Users\\Shalini\\Downloads\\chrom86_driver\\chromedriver.exe");driver = new ChromeDriver();}public void login() {String login_url = "https://opensource-demo.orangehrmlive.com/";driver.get(login_url);driver.manage().window().maximize();driver.manage().timeouts().pageLoadTimeout(10, TimeUnit.SECONDS);driver.findElement(By.id("txtUsername")).sendKeys("Admin");driver.findElement(By.id("txtPassword")).sendKeys("admin123");System.out.println(driver.getTitle());}@Testpublic void dashboard() {driver.findElement(By.id("menu_dashboard_index")).click();String textPresent = driver.findElement(By.xpath("//*[@id=\"content\"]/div/div[1]/h1")).getText();String textToBePresent = "DashBoard";assertEquals(textPresent, textToBePresent);}@AfterTestpublic void tearDown() {driver.quit();}}
Шаг 6 Создадим файл
TestNG.xml:
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE suite SYSTEM "http://testng.org/testng-1.0.dtd"><suite name="TestSuite"><test name="LoginTest"><groups><run><include name="DemoTest"/></run></groups><classes><class name="Pages.LoginPage"></class></classes></test></suite>
Шаг 7 В папке проекта добавим зависимости. Создадим .bat-файл со следующим содержимым:
ava cp bin;lib/* org.testng.TestNG TestNG.xml
Тут надо указать точное имя файла
TestNG.xml,
созданного ранее.Шаг 8 Выберем в панели управления Jenkins проект, который мы создали в самом начале работы. Щёлкнем по
Configure.
На вкладке General щёлкнем по Advanced и
установим флажок Use custom workplace. Введём в поле
Directory путь к папке проекта.
Шаг 9 На вкладке
Build откроем выпадающий
список Add Build Step и выберем Execute Windows
batch Command. Введём в него имя .bat-файла, созданного на
шаге 7.
Шаг 10 Щёлкнем по кнопке
Apply, потом по кнопке
Save для того чтобы сохранить изменения, внесённые в
настройки Jenkins-проекта. Теперь щёлкнем по кнопке Build
Now, после чего можно будет понаблюдать за процессом
выполнения тестов.
Второй метод интеграции Jenkins с Selenium
Второй подход к автоматизации Selenium-тестов в Jenkins предусматривает использование Maven. Но прежде чем мы это обсудим, предлагаю немного поговорить о Maven, и о том, почему этот фреймворк пользуется популярностью при автоматизации тестов в Jenkins.
Что такое Maven?
Maven это инструмент для автоматизации сборки проектов, который позволяет организовать добавление в проект зависимостей и управление ими с использованием файла
pom.xml. Это
позволяет многократно использовать одни и те же зависимости во
множестве проектов. При добавлении зависимости в файл
pom.xml эта зависимость автоматически загружается и
добавляется в проект, что избавляет разработчика от необходимости
вручную добавлять в проекты зависимости в виде JAR-файлов.Совместное использование Maven, Jenkins и Selenium WebDriver даёт возможность построения DevOps-модели, реализующей механизм непрерывной интеграции программных проектов.
Установка Maven
Шаг 1 Загрузим дистрибутив Maven с официального сайта проекта.
Шаг 2 Добавим в состав системных переменных
MAVEN_HOME переменную, в которой содержится путь к
домашней директории Maven.
Шаг 3 Внесём в переменную
Path путь к
директории bin, содержащейся в домашней директории
Maven.
Настройка переменной Path
Шаг 4 Для того чтобы проверить правильность установки Maven откроем окно командной строки и попробуем выполнить команду
mvn version.
Шаг 5 Создадим Maven-проект и добавим в файл
pom.xml соответствующие зависимости:
<project xmlns="http://personeltest.ru/away/maven.apache.org/POM/4.0.0" xmlns:xsi="http://personeltest.ru/away/www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://personeltest.ru/away/maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>demoProject</groupId><artifactId>demoProject</artifactId><version>0.0.1-SNAPSHOT</version><build><sourceDirectory>src</sourceDirectory><plugins><plugin><artifactId>maven-compiler-plugin</artifactId><version>3.8.0</version><configuration><sоurce>1.8</sоurce><target>1.8</target></configuration></plugin></plugins></build><dependencies><dependency><groupId>org.seleniumhq.selenium</groupId><artifactId>selenium-java</artifactId><version>3.141.59</version></dependency><dependency><groupId>org.testng</groupId><artifactId>testng</artifactId><version>7.3.0</version><scope>test</scope></dependency></dependencies></project>
Вот Java-код:
package WebDriverProject;import org.junit.Assert;import org.openqa.selenium.By;import org.openqa.selenium.WebDriver;import org.openqa.selenium.firefox.FirefoxDriver;public class LoginClass {WebDriver driver;@BeforeTestpublic void setup() {System.setProperty("WebDriver.gecko.driver", "C:\\Users\\shalini\\Downloads\\geckodriver-v0.26.0-win64\\geckodriver.exe");driver = new FirefoxDriver(); //Инициализация WebDriver}@Testpublic void loginTest() {driver.get("https://opensource-demo.orangehrmlive.com/"); //Определение URLString pageTitle = driver.getTitle(); //get the title of the webpageSystem.out.println("The title of this page is ===> " + pageTitle);Assert.assertEquals("OrangeHRM", pageTitle); //Проверка заголовка страницыdriver.findElement(By.id("txtUsername")).clear(); //Очистить поле перед вводом значенийdriver.findElement(By.id("txtUsername")).sendKeys("Admin"); //Ввести имя пользователяdriver.findElement(By.id("txtPassword")).clear();driver.findElement(By.id("txtPassword")).sendKeys("admin123"); //Ввести парольdriver.findElement(By.id("btnLogin")).click(); //Щёлкнуть по кнопке LoginSystem.out.println(Successfully logged in );}@AfterTestpublic void teardown() {driver.quit();}}
Вот XML-файл с настройками тестов:
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE suite SYSTEM "http://testng.org/testng-1.0.dtd"><suite name="TestSuite"><test name="LoginTest"><groups><run><include name="DemoTest"/></run></groups><classes><class name=" WebDriverProject.LoginClass"></class></classes></test></suite>
Интеграция Selenium и Jenkins с помощью Maven
Только что мы говорили об интеграции Jenkins с Selenium WebDriver. То, что получилось, лучше всего использовать для автоматизации Selenium-тестов. Интеграция Jenkins с Selenium WebDriver даёт разработчику надёжную систему кросс-браузерного тестирования проектов. Здесь мы поговорим об интеграции Jenkins и Selenium с помощью Maven.
Шаг 1 Запустим сервер Jenkins.
Шаг 2 Откроем браузер и перейдём на
localhost,
использовав порт, на котором работает Jenkins.
Шаг 3 Щёлкнем по кнопке
New Item в панели
управления
Шаг 4 Введём имя проекта и, в качестве типа проекта, выберем
Maven project.
Шаг 5 Нажмём на кнопку
OK. После этого можно
будет увидеть, как в панели инструментов появилось новое
задание.
Шаг 6 Выберем проект и нажмём на кнопку
Configure.
Шаг 7 На вкладке
Build, в поле Root
POM, введём полный путь к файлу pom.xml. В поле
Goals and options введём clean test.
Шаг 8 Щёлкнем
Apply, а затем
Save.Шаг 9 Нажмём на кнопку
Build Now.
Шаг 10 Будет начата сборка проекта, а после её завершения появится соответствующее сообщение. Для того чтобы посмотреть полный журнал нужно щёлкнуть по кнопке
Console
Output.
Итоги
Мы поговорили о том, почему проект Jenkins пользуется серьёзной популярностью, и о том, как интегрировать его с Selenium WebDriver ради эффективного выполнения тестов и достижения целей непрерывной интеграции программных проектов. Использование Jenkins для автоматизации запуска тестов позволяет разработчикам экономить время, а результаты выполнения тестов можно проанализировать, просмотрев соответствующие лог-файлы. Такой подход позволяет организовать полный цикл разработки ПО разработку, развёртывание, тестирование, мониторинг, выпуск в продакшн. Jenkins поддерживает множество различных плагинов, предназначенных для решения самых разных задач, встающих перед разработчиками. Система, кроме того, умеет сообщать заинтересованным лицам о том, успешно ли прошла сборка проекта.
Надеюсь, теперь вы без труда сможете интегрировать Jenkins с Selenium WebDriver.
Пользуетесь ли вы Jenkins и Selenium WebDriver?
 Изображение от https://unsplash.com/@kellysikkema
Изображение от https://unsplash.com/@kellysikkema
 Инициализация проекта
Инициализация проекта
 Установка Cypress
Установка Cypress
 Открытие Cypress
Открытие Cypress
 Интерфейс Test Runner
Интерфейс Test Runner
 Переход к
cypress/integration
Переход к
cypress/integration
 Создание JavaScript файла
Создание JavaScript файла
 Обновление структуры файлов в реальном времени
Обновление структуры файлов в реальном времени
 Код к файлу basicTest.js
Код к файлу basicTest.js
 Щелчок по basicTest.js в Test Runner
Щелчок по basicTest.js в Test Runner
 Результат запуска теста
Результат запуска теста
 Код
для добавление в basicTest.js
Код
для добавление в basicTest.js
 Результат
нашего второго теста
Результат
нашего второго теста
 Код
для добавления в basicTest.js
Код
для добавления в basicTest.js
 Результат теста: успешно!
Результат теста: успешно!
 Результат
запуска нашего теста
Результат
запуска нашего теста
 Код для
basicCommandsTest.js
Код для
basicCommandsTest.js
 Клик по basicCommandsTest.js вTest Runner
Клик по basicCommandsTest.js вTest Runner

 Получение элемента через id элемента
Получение элемента через id элемента
 Получение элемента через имя класса
Получение элемента через имя класса
 Страница для тестирования
Страница для тестирования
 Скриншот из DeveloperTools
Скриншот из DeveloperTools
 Идентификация элемента
Идентификация элемента
 Вывод результата
Вывод результата
 Скриншот
сайта для тестирования
Скриншот
сайта для тестирования Скриншот из DeveloperTools
Скриншот из DeveloperTools Скриншот из DeveloperTools
Скриншот из DeveloperTools
 Идентификация элемента через его id
Идентификация элемента через его id

 Вывод
результата запуска кода
Вывод
результата запуска кода
 Developer Tools
Developer Tools
 Идентификация наших чекбоксов
Идентификация наших чекбоксов
 Результат запуска теста
Результат запуска теста
 Скриншот
тестируемой страницы
Скриншот
тестируемой страницы Developer Tools
Developer Tools
 Наше утверждение
Наше утверждение
 Получение элемента и за тем утверждение
Получение элемента и за тем утверждение
 Наше утверждение
Наше утверждение
 Получение элемента и затем утверждение
Получение элемента и затем утверждение
 Код для
runningClickCommand.js
Код для
runningClickCommand.js
 Результат запуска
Результат запуска
 Скриншот тестового сайта
Скриншот тестового сайта

 Получение элемента и использование each затем
Получение элемента и использование each затем
 Код для
runningClickCommand.js
Код для
runningClickCommand.js
 Результат выполнения кода
Результат выполнения кода


 Результат выполнения кода
Результат выполнения кода
 Не самая лучшая структура
Не самая лучшая структура
 Отображение тестовой структуры в Test Runner
Отображение тестовой структуры в Test Runner
 Хорошая структура проекта
Хорошая структура проекта

 Пример кода
Пример кода

 Пример кода
Пример кода
 Команды терминала
Команды терминала

 fig:
fig:








 Так выглядит наш локальный StackOverflow
Так выглядит наш локальный StackOverflow







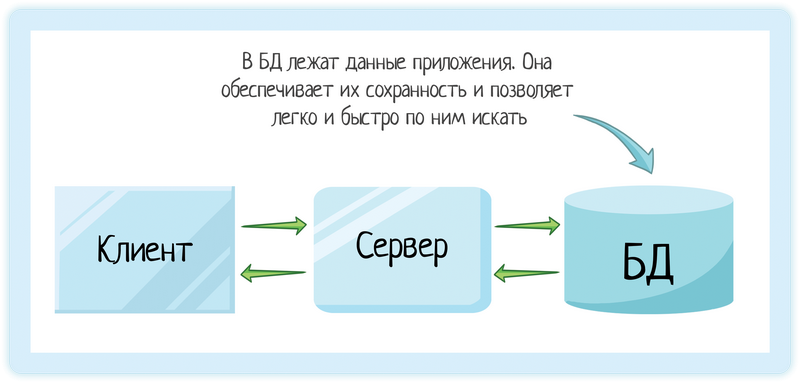






 Пример базы Oracle
Пример базы Oracle







 Здесь ключ id_order
Здесь ключ id_order

























































 "Из коробки" роботы не всё делают одинаково.
"Из коробки" роботы не всё делают одинаково.
 Пример представлений, которые можно
получить в Allure TestOps в пару кликов из базы размеченных тестов.
Пример представлений, которые можно
получить в Allure TestOps в пару кликов из базы размеченных тестов.






 Подмена User-Agent
Подмена User-Agent Пример изменения размера поля элемента
Пример изменения размера поля элемента Отчет о покрытии кода
Отчет о покрытии кода Выбор скорости соединения
Выбор скорости соединения Список возможных столбцов в Network
Список возможных столбцов в Network