Зачем нам p3express в наших IT-проектах
Нас всего 6 человек и по сути мы проектный офис. Мы стремимся
меньше делать своими руками, но больше проектировать и
организовывать работы. А это проекты, проекты и еще раз проекты,
которые у нас завязаны на IT-разработку разработка web и мобильных
приложений, промо и контент проекты, автоматизация бизнес-процессов
и сопровождение стартапов.

При всей нашей маленькости мы много, долго (и часто болезненно)
работаем с крупными компаниями, у которых очень высокие требования
и к качеству, и к управлению проектом. Нам встречаются очень разные
проектные процессы: от слишком забюрократизированных до сплошной
вольницы. Бывало даже одновременно оба процесса на разных проектах
в одной компании. И нам приходится со всем этим справляться,
выруливая в переговорах и работая с клиентами любой сложности,
причем мы стараемся дружить долго.

Конечно, у кого-то из заказчиков есть свои стандарты управления
проектами, но заточены они под их основную деятельность (например,
для строительства домов), и пытаться с их помощью руководить
IT-проектом такое себе приключение. Поэтому методологию ведения их
ИТ-проектов обычно выбираем мы. Выбор у нас всегда был большой есть
прекрасные классические инструменты, которые охватывают всё, что
только можно охватить, плюс подходят к этому с разных сторон и
классно документированы:

Но есть нюанс все они требуют очень высокого уровня владения
стандартом со стороны клиента, чтобы мы сработались при
использовании разных с ним подходов. А это будет сложно, если
клиент исповедует PRINCE2, а мы, например, топим за ISO 21500.
Другая сложность в том, что подходить к реализации проекта можно
с трех сторон:
Всё жестко зафиксировано с самого начала и ничего менять
нельзя. То есть мы говорим: У нас есть сроки, деньги и то,
что должно в итоге получиться. Шаг влево/вправо расстрел. А проект
мы считаем успешным, только если достигли вот такой цели. Это
классно и замечательно, но часто даже сам клиент не готов к тому,
чтобы все его требования были жестко зафиксированы в самом начале и
чтобы потом их нельзя было менять. Всё равно в процессе зайдет речь
о каких-то изменениях и корректировках. А если при этом вы не
договорились, что это повлечет за собой изменение бюджетов, сроков
или объема работ будет больно.
Другой подход говорит, что мы будем удовлетворять
клиента и это Agile. Что бы клиент ни захотел, какие бы
идеи у него ни рождались, мы будем работать, работать, и конца
этому видно не будет пока все не станут счастливы. Agile был
первым, о чем мы подумали, когда выбирали подход, потому что он
действительно прекрасен, а Agile-манифест это вообще сказка и
прелесть: важнее люди и взаимодействие, работающий продукт важнее
документации, и самое главное сотрудничество и готовность к
изменениям:

Но, оказывается, на моменте готовности к изменениям большая
часть клиентов Agile-манифест не поддерживает. Как не поддерживает
ни одна компания, которая работает в B2B секторе и занимается
заказной разработкой, потому что у них есть своя бюрократия и
прочие факторы. Так что Agile мы оставили только для своих
стартап-проектов.
А для клиентов у нас прижился ценностный
(сбалансированный) подход это когда в конце проекта мы с
заказчиком соглашаемся, что игра стоила свеч. Даже если результат
может быть получен не совсем тогда, использоваться могут не совсем
те деньги, и может быть, получилось не совсем то. Но если мы смогли
договориться, что это стоило затраченных усилий и нашли баланс это
он и есть:

Используя этот подход, мы постепенно пришли и к тому, что для
взаимодействия на одном языке с клиентами нужна общая проектная
методология. Обязательно с низким порогом входа чтобы даже никогда
не управляя проектами или используя другую методологию, вы могли бы
быстро прочитать описание и сказать: Да, классно, я всё понял,
поехали! Но под эти требования ни Agile, ни другие взрослые
методологии не подходили. Зато подошел фреймворк p3express.
В p3express мы пришли с огромным накопленным багажом проектных
инструментов. От некоторых он помог нам избавиться. Но большая
часть осталась с нами, так как никаких противоречий с новым
фреймворком не выявилось. И в принципе, я сейчас буду рассказывать
не столько про p3express в его первозданном виде, сколько уже про
то, как мы поженили свои практики с тем скелетом (фундаментом),
которые он дает.

У p3express есть бешеное преимущество: он простой. Это 37 шагов,
разрисованных на картинке и быстро читаемых, при этом есть примеры
и шаблоны. Прочитать их за 10 минут вполне реально. Хотя, конечно,
без опыта не получится начать управлять проектом прямо сразу, здесь
и сейчас. Но получится понять, допустим, меня, когда я буду
описывать, чем мы завтра будем заниматься, и вообще куда и как мы
двигаемся. То есть если мы договорились, что работаем по p3express,
то всем в любой момент времени будет понятно, как мы будем жить и
куда пойдем.
Второе его преимущество p3express сбалансирован по
цене/срокам/скоупу.
И еще один кайф (впрочем, как у многих других стандартов) это
фреймворк. Он не описывает жестко всё, что мы должны делать (то
есть не ограничивает и не сковывает), а говорит: примерно такие
вопросы и такие задачи нужно решить примерно таким способом.
Дальше я поэтапно рассмотрю шаги p3express и прокомментирую, как
мы с этим живем.
Подготовка проекта
Начало в p3express вполне классическое:
-
Шаг 01. Определить спонсора;
-
Шаг 02. Подготовить резюме проекта;
-
Шаг 03. Определить руководителя проекта;
-
Шаг 04. Развернуть рабочее пространство;
-
Шаг 05. Определить команду;
-
Шаг 06. Планирование проекта;
-
Шаг 07. Определить внешних исполнителей (если в проекте они
есть) ;
-
Шаг 08. Провести аудит подготовки;
-
Шаг 09. Да/нет;
-
Шаг 10. Провести стартовую встречу;
-
Шаг 11. Фокусированная коммуникация.
У нас же получилось всё сильно сложнее, чем 11 шагов.
Шаг 01. Определить спонсора продукта
p3express не дает четкого определения: спонсор продукта это его
владелец или нет? но в его контексте это синонимы. В других
методологиях это слово тоже по-разному трактуется: это может быть
тот, кто принимает решение или получатель или менеджер проекта. В
каждом фреймворке есть своя терминология, и что даже важнее у
каждого из нас в компании есть своя терминология, которую мы
считаем той самой общепринятой. А у ребят в соседнем офисе она
будет совершенно другая.
По моему мнению, владельцем является тот, кто за него платит и
кто получает от него основную выгоду. На практике же это часто
разные люди. Почему владелец продукта нам, как менеджерам, важен с
практической точки зрения? Потому что это тот этап, когда мы
спрашиваем: Кто будет определять, мы сделали всё хорошо и
правильно, или нет? Кто будет принимать проект? И часто бывает, что
деньги платят одни, а решение о том, заплатить эти деньги или нет,
принимают другие люди. Это абсолютно нормальная история
(делегирование и пр.), но нам нужно понимать, кто выставляет
основные требования.
Конечно, основные требования должны бы выставлять
пользователи-выгодополучатели. Но чаще их выставляют те, кто
подписывает бумаги в конце. И нам желательно на этом этапе этот
момент как-то свести к одной точке.
Шаг 02. Подготовить резюме проекта
Для нас это самое сложное перед запуском проекта. Взрослые
методологии, тот же самый ISO 21500, предполагают, что на вход в
проект придет бизнес-план или ТЭО, которые полностью описывают, что
мы делаем и зачем, как на этом планируем зарабатывать и т.д., чтобы
можно было прочитать и сказать: А, понятно!, и по нему уже
запускать проект. Но у нас так не получается.
Поэтому перед стартом проекта мы обычно делаем очень много
консалтинга. Эти работы мы даже выносим в отдельный контракт с
фиксированной стоимостью. Обычно это относительно небольшое время
от 2 до 6 недель при том, что проекты бывают от 2 до 12-24
месяцев.
И у нас есть два разных подхода для наших основных типов
клиентов стартапов и уже сформировавшегося бизнеса.

Со стартапами мы обычно используем Lean Canvas. Это большая
таблица, в которой грубо раскидано что, зачем, кому мы делаем, как
нам за это будут платить и почему нам это выгодно. Это больше
маркетинговая история, но на самом деле именно она определяет, что
мы будем делать. Это некая канва бизнес-модели, и именно с ней мы
сверяемся, когда хотим что-то в проекте поменять или выбрать
альтернативный путь. Мы смотрим нашему продукту это ценности
прибавит или, наоборот, убавит?
Из Lean Canvas вырастает MVP: мы видим, каким должен быть
минимальный продукт, чтобы проверить, а правильно ли мы вообще
напридумывали скетчи и прототипы, концепт дизайна, техническое
задание? Это как раз тот пакет документов, который в больших
методологиях называется бизнес-план, ТЭО или еще как-то.
И в таком виде на входе у нас появляется резюме проекта, о
котором и говорит p3express для того, чтобы понимать что и зачем мы
делаем. И часто мы делаем сильно не то, что было описано в
первоначальном брифе.

С устоявшимся бизнесом происходит чуть по-другому, но часто
встречается одна проблема. Людям понятно, что автоматизация нужна,
что она должна решить какие-то проблемы но какие? Чаще всего это
некий очень неопределенный круг проблем, который клиент надеется
решить с помощью автоматизации. Возможно, наш айтишный маркетинг
как-то слишком обожествляет весь процесс автоматизации и волосы
станут мягкими и шелковистыми, и котики, и единороги, и радуга и
прочее, и прочее...
И когда мы приходим автоматизировать, то заказчику кажется, что
нужно автоматизировать буквально всё. И чтобы разделить реальность
и единорогов, мы всегда проводим стратегическую
сессию. Она помогает понять, куда компания вообще идет,
почему вдруг на этом пути появилась потребность что-то
автоматизировать (то есть как-то улучшить процессы) и что это даст
на уровне глобальных показателей. Обычно это почти не больно 3-4
часа общения с топами. Они почти никогда не кусаются, но нам всё
равно страшно, и мы приходим всей командой.
После этого мы идем на проблемную сессию для
общения с менеджерами, которые нам рассказывают, почему то, что
хотят топы, не удалось реализовать без автоматизации и оптимизации.
Поднимаем циферки (сбор и анализ данных) и
смотрим, насколько действительно те проблемы, которые есть
присутствуют, а также насколько их решение действительно даст то,
что от нас ждут. В итоге составляем концепт
изменений, который нужен, чтобы с клиентом еще на берегу
договориться, что можно решить (и в какой степени) а что нельзя.
Иначе мы под конец будем друг на друга обижаться, а это всегда
неприятно. Чаще всего потом деньги сложно получить. Бывает, кстати,
что после анализа статистики текущих процессов и формирования
прогноза по выгодам от изменений мы клиента отговариваем от
проекта.
Параметры проекта
В итоге для любого вида бизнеса мы создаем описание проекта по
таким параметрам:

Это есть во всех стандартах управления проектами, которые я
знаю. Но мы используем очень простую методику
Scope-Pak. Придумали ее не мы по ссылке в QR коде
можно посмотреть первоисточник:

Scope-Pak это 8 шагов по 5-7 вопросов каждый. На них лучше всего
отвечать всем вместе то есть собираем нужных людей, задаем им
вопросы и фиксируем ответы. На этом этапе желательно, чтобы команда
заказчика еще не была сформирована, так как именно в процессе
встречи с теми людьми, которые могут вам помочь, вы поймете, кого
из них брать в команду.
Вопросы своеобразные, но проговорить их надо все иногда
всплывают очень интересные и важные детали. Из собранного материала
формируем документ или доску в Trello смотря какой уровень
бюрократии необходим в проекте. Это отлично помогает сформировать
общее понимание и выявить риски, а на руках вы будете уже иметь
почти готовый план проекта.
Рассмотрим кратко эти 8 шагов:
Шаг 1. Заинтересованные стороны:
-
Чьи деньги участвуют в реализации проекта?
-
Этот человек является спонсором проекта?
-
Кто еще будет участвовать в проекте?
Шаг 2. Компоненты:
-
Что предстоит сделать?
-
Нужны какие-то вспомогательные работы?
-
Нужны подготовительные работы?
-
Завершающие работы?
-
Если мы сделаем все это, мы завершим весь проект?
Когда мы читали оригинал, мы очень смеялись над советом:
ОГРАНИЧЬТЕ СПИСОК 30 ПУНКТАМИ то есть не расписывайте подробнее,
чем на 30 пунктов, что надо сделать. А на практике мы столкнулись с
тем, что только первые 6 рождаются просто в бешеных муках, а потом
сложно остановиться.
Шаг 3. Цели и результаты:
-
Зачем мы все это делаем и как правильно это назвать?
-
Что мы получим на выходе и как это измерить?
-
Когда мы хотим это получить?
-
То, что мы запланировали сделать даст нам эти результаты?
Наверное, этим меня и зацепил Scope-Pak. Обычно делается все
наоборот: сначала говорят о целях, а потом что мы будем делать ради
этого. А когда мы сначала спрашиваем: Что мы делаем?, а потом:
Зачем? появляется ступор, ведь у клиента в голове был только один
план надо сделать это, это и это. Ответ помогает нам с заказчиком и
командой выйти из ступора и перейти к пункту: А может, можно пойти
другим путем?
Шаг 4. Альтернативы
-
Есть ли более эффективный способ достичь своих целей?
-
То, что мы запланировали сделать единственный способ получить
нужный нам результат?
-
Как еще можно получить тот же результат?
-
Что можно сделать лучше?
Здесь важно разбить стену, когда все уже решили раз взялись, то
надо делать, и попытаться выудить из клиентов предысторию проекта.
Это важно, потому что для клиента какие-то вещи кажутся
малозначимой внутренней кухней, про которую другим якобы слушать
неинтересно. А на самом деле из предысторий вы понимаете какие-то
важные вещи, которые помогают правильно понять боль клиента.
Шаг 5. Ресурсы и сложности
-
Какова стратегия финансирования проекта?
-
Насколько он важен в сравнении с другими проектами?
-
Какие ресурсы вам потребуются?
-
С какими препятствиями вы столкнетесь?
-
Кто спонсирует этот проект?
-
Какие разрешения вы должны получить?
-
Кто будет выполнять задания проекта?
-
Каковы временные рамки?
-
Каковы критические даты?
-
Что может быть еще включено в проект?
-
Что можно исключить из проекта?
Забавно то, что когда-то дубль вопроса Кто спонсирует? попал
сюда по ошибке из первого шага, но на практике получилось, что он
здесь к месту. Потому что часто выясняется, когда мы наконец
расписали, с кем что согласовывается спонсоры не совсем те. Поэтому
мы оставили этот вопрос здесь, он классно помогает.
Шаг 6. План наступления
Тут просто укрупненно накидываем взаимосвязи шагов, что от чего
зависит:

Шаг 7. Риски:
-
Какие предположения вы сделали?
-
Какие предположения вы должны сделать?
-
Какие трудности могут встретиться при выполнении каждой
задачи?
-
Как можно сократить риски или найти обходные пути?
Для некоторых проектов может быть необходима отдельная большая
риск-сессия, но в большинстве случаев достаточно зафиксировать то,
что витает в воздухе и двигаться дальше.
Шаг 8. Ключевые индикаторы достижения цели:
-
Кто 3-4 самые главные заинтересованные участники проекта?
-
Какой результат их скорее всего удовлетворит?
-
Как измерить каждый из них по завершении проекта?
Это тот самый момент истины, ради чего я вообще показал эти 8
шагов. На старте обязательно надо понимать, как нас вообще будут
измерять. Это вещь, которая нас очень нехило спасает от
нереалистичных ожиданий клиента.
Например, заказчик хочет оптимизировать логистику. Мы выясняем,
что сейчас эффективность использования его автотранспорта 20%, а
клиент хочет достигнуть 70%. Мы считаем на коленке и понимаем, что
весь его процесс так устроен, что больше 30% просто не получится.
Потому что хоть клиент и ожидает, что машина будет 70% в пути, ей
на самом деле нужно больше времени для приезда, разгрузки,
погрузки, отъезда и прочих факторов. И если мы соглашаемся на 70%,
не оговаривая всё это сразу, то под конец приходим к тому, что
проделали отличную работу, всё здорово, всё классно, все довольны,
а клиент говорит: Ребята, ну не 70 же! Как минимум, это неприятно,
а может закончиться и контрактными проблемами.
Шаг 9. Да / Нет
Этот шаг описан и в p3express, во многих других методологиях.
Для нас он о честности. Потому что когда предварительные работы
проведены, мы даем заказчику полный и честный расклад по
предстоящему проекту. Бывает иногда соблазн нарисовать более
радужную картинку, но это нечестно и обязательно выйдет нам боком
плохие новости всё равно всплывут. Честно это не украшать картинку
и не обещать, что всё будет обалденно, шикарно и классно. Может и
будет, но надо понимать, сколько это будет стоить это тот самый
сбалансированный подход.
Конечно, нам иногда кажется, если получилась такая цена (или
такой геморрой), то, наверное, вообще не стоит этот проект делать.
Но по опыту мы уже знаем: в обсуждении с клиентом может выясниться,
что выгод у него будет все равно больше и проект случается. Но если
не сказать обо всем этом сразу, потом всегда будет больно придется
краснеть, потеть и плакать.
Поэтому я согласен с тем, что этап Да/Нет должен происходить как
раз на этом шаге. Этим мне тоже очень понравился p3express, потому
что это мало где применяется. По некоторым методологиям, люди
посидели, подумали и ТЭО составили, а потом принесли на старт
проект и сразу начали проектировать. А в жизни как раз получается
наоборот. Когда назначен менеджер и решили да, наверное, будем
делать проект, очень многое еще непонятно. И вот именно на этом
этапе есть смысл сесть и подумать а вы уверены, что в это
ввязываетесь? Да? Тогда поскакали, всё классно, и все друг друга
хорошо понимают.
Планирование этапа
Тут у P3express всё по канонам:
-
Шаг 12. Обновить планы;
-
Шаг 13. Определить внешних исполнителей (если в проекте они
есть);
-
Шаг 14. Да/нет;
-
Шаг 15. Провести стартовую встречу цикла;
-
Шаг 16. Фокусированная коммуникация.
Важный момент внешние исполнители. Есть соблазн собрать в
команду всех, кто может понадобиться в процессе, но такой командой
будет очень сложно управлять. Поэтому мы стараемся максимально
сокращать количество участников проекта оставлять только
ответственных за работы, а исполнителей выносить за рамки.
Например, за команду разработки отвечает наш проектный менеджер, а
за подготовку всех материалов, согласование документов, оплату и
прочее один представитель клиента с соответствующими
полномочиями.
Свою команду я тоже выношу во внешние исполнители, а сам являюсь
ее представителем, отвечая за них. При этом моя команда работает
так, как обычно у нее операционка, она не играет в p3express. Это
же относится к командам на подряде они по умолчанию внешние. Мы им
ставим задачу, заказчик для них проект, а внутри они работают
по-своему. Я же, как человек, который находится внутри проекта,
могу выставить какие-то контрольные точки и требования для них.
В проектной же команде должны быть те (и в p3express они должны
играть), для кого выполняется наша операционная деятельность и кого
касаются абсолютно все работы по проекту. Идеально, когда в проекте
2 человека, много внешних исполнителей и список заинтересованных
лиц, которых надо держать в курсе хода проекта.
Дополнительно на этапе планирования мы делаем Lean-приоритезацию
она поможет в случае наступления рисков остаться в ценностных
рамках. Лучше всего это делать вместе с будущим владельцем проекта
и/или с лицами, принимающими решение. Схема очень простая: по двум
шкалам (ценность/сложность) оцениваем по 10-балльной шкале все
компоненты (фичи и прочее, что решили делать):
-
какую ценность нам это принесет?
-
что будет стоить по трудозатратам, по ресурсам, по времени,
etc.?

Получаем табличку. Иногда бывает, что ценно всё то есть все наши
компоненты получают десятки. Это нехорошо, и мы тогда пытаемся их
оценить по 100-балльной шкале и тут уже все компоненты обычно
делятся на 4 категории (очень редко бывает, что какой-то из
квадратиков остается пустым).
Здесь я опять возвращаюсь к тому подходу, что обычно наша задача
не попасть день в день, доллар в доллар и строчка в строчку, а
определить и создать основную ценность. А для этого нам в процессе
надо понимать, какие задачи и какие требования мы (в случае чего)
можем выкинуть, но ценность сохранить. Lean-приоритезация нам дает
для этого те самые приоритеты. Если мы знаем, что это стоит больше,
а то меньше, то ради второго можно пожертвовать первым, но не
наоборот.
Реализация этапа
На данном этапе всё скучно и по началу очень легко новый проект,
все вдохновленные, всё здорово, сроков впереди много, и вообще
любовь и ромашки! Но чтобы в конце не было сильно больно, на этом
этапе надо заставлять всех регулярно общаться, при этом желательно
как-то отчитываться перед заказчиком и подводить промежуточные
итоги.
Еженедельные действия p3express определяет так:
-
Шаг 17. Оценить прогресс;
-
Шаг 18. Работать с отклонениями;
-
Шаг 19. Еженедельная встреча;
-
Шаг 20. Провести еженедельный аудит;
-
Шаг 21. Фокусированная коммуникация.
То есть каждую неделю нужно готовить отчет по статусу. Для этого
мы используем отчет из очень немолодой книжки Управление проектом
на одной странице К. А. Кэмбэлла она маленькая, но в ней ценные
вещи написаны, а формат отчетов вообще шикарный. Мы показываем
клиенту вот такой отчет на одной странице, классный и вкусный, и в
нем видно практически всё:

Поначалу он может немного пугать. Но если до этого мы всю работу
провели нормально, то нам будет что вписывать: цели, основные
задачи, риски и прочее. При желании можно уйти глубоко (показателей
много), но чаще этого не нужно.
Два показателя особенно классные: плановый объем (PV) и
освоенный объем (EV). Они помогают нам наглядно увидеть: отстаем ли
мы, идем с опережением или что-то другое происходит.
Как это работает? Ресурсы редко тратятся линейно, поэтому обычно
мы не можем утверждать, что за половину сроков мы потратим половину
денег. На самом деле это почти всегда не так. Например, есть
задачи, где в начале идет что-то очень емкое (необязательно это
айтишная история) какая-то концепция, дизайн-исследование что
угодно. Мы это делаем в первую неделю, а потом три недели тестируем
и согласовываем то есть в это время ценности уже не добавляется, а
время это занимает. Или наоборот сначала долго, но дешево копим
данные, а потом быстро и дорого их анализируем. В этом случае
первые 3 недели мы ничего не тратим, никакой ценности не приносим,
а в конце тратим много ресурсов (денег), но получаем много
ценности.
Из-за этой неровности невозможно сопоставить сроки и объем.
Вроде бы прошла половина срока, и мы должны получить половину
планируемого результата но мы получили 63% или 48%. Возникает
вопрос: Это хорошо или плохо?. А по методике соответствия
планового/освоенного мы заранее расписываем: мы будем тратить
ресурсы именно так, и именно так получать ценность. А потом легко
сравнить, получились ли наши запланированные 63% и 48%.
Ежедневные действия
На этом этапе p3express в основном предлагает работать с
рисками:
-
Шаг 22. Зафиксировать RICs;
-
Шаг 23. Реагировать на RICs;
-
Шаг 24. Принять готовые продукты.
Мы их дополнили частью из SCRUMа, введя ежедневные митинги для
обсуждения:
-
Что сделал вчера;
-
Что планируешь сегодня;
-
Что может помешать.
Правда, эти ежедневные митинги мы проводим только 2 раза в
неделю, так как если чаще, то друг от друга очень быстро устаешь.
Но нам этого хватает и для подведения итогов с клиентом, и для
введения друг друга в курс дела.
Закрытие этапа
Вот так это в p3express:
-
Шаг 25. Оценить удовлетворённость заказчика и команды;
-
Шаг 26. Запланировать улучшения;
-
Шаг 27. Фокусированная коммуникация.
Если у нас проект в один этап мы это пропускаем и переходим к
закрытию проекта. Если этапов несколько, то вопрос в том, как
именно оценивать удовлетворенность этапом. Мы пробовали
использовать анкету для оценки из шага 25, но не зашло. Потому что
когда мы получаем заполненную анкету, на нее всегда надо
реагировать, хорошая она или плохая надо разбираться, выяснять или
просто дать ответ. Не всегда это нужно, если мы сделали всю
предыдущую работу нормально. К тому же дополнительные вопросы часто
людей раздражают: Мы и так все проблемы знаем! Но, может быть, я
еще не умею это готовить. Знаю ребят, у которых анкета шикарно
заходит, и они очень довольны.
Вместо анкеты мы проводим проблемную сессию Квадратные колеса
для составления дерева проблем. Это консалтинговый инструмент, он
помогает обезличить проблемы и структурировать их:

Мы прямо ставим эту забавную картинку на заставку и обсуждаем:
может, у нас есть какие-то вещи, которые мы делаем глупо, а их
можно сделать по-другому и что-то улучшить? То есть мы идем не
туда, где мы делаем плохо, а туда, где можем сделать лучше.
Выписываем то, что можно улучшить, проставляем иерархию и получаем
дерево проблем, которое прорабатываем и фиксируем новые
договоренности.
Закрытие проекта
По p3express закрытие включает такие шаги:
-
Шаг 28. Получить одобрение и передать продукт
-
Шаг 29. Передать проект
-
Шаг 30. Оценить удовлетворенность заказчика и команды
-
Шаг 31. Провести аудит закрытия
-
Шаг 32. Извлечь уроки и заархивировать проект
-
Шаг 33. Объявить и отметить окончание проекта
-
Шаг 34. Фокусированная коммуникация
Наши проекты редко имеют совсем конец обычно вместо этого мы
запускаем их в промышленную эксплуатацию. Поэтому ближе к
завершению, параллельно с проектом по реализации, мы обсуждаем и
составляем с заказчиком этапы следующего проекта и запускаем еще
один проект по созданию бизнес-процесса сопровождения. В рамки
основного проекта его не включаем это уже операционка, часто там
уже другие участники.

Сессия Скажи спасибо
После того как все закончилось, всем участникам нужно этот
гештальт закрыть команде важно почувствовать, что силы были
потрачены не зря. И мы для этого проводим сессию Скажи спасибо. Это
просто, тупо, мило, но всегда приятно сначала люди друг с другом
взаимодействовали, а теперь они друг друга благодарят. Это можно
сделать текстом, устно и как-то еще как хотите, так и сделайте.
У нас была девочка, которая очень переживала за свой первый
проект что она то здесь, то там накосячила. А ее просто засыпали
благодарностями за то, что она считала косяками. Оказалось, что она
реально влезала во все проблемы, находила причины и закрывала их,
но принимала косяки на свой счет. А проект во многом сложился из-за
того, что она очень переживала, расстраивалась и очень
старалась.
Поэтому закрывать совместную деятельность нормальной обратной
связью искренними благодарностями и воспоминаниями о том, что было
хорошо сделано, а не просто обменом комплиментами это очень
классно. Реально очень рекомендую. Можете все остальное выкинуть, а
это обязательно попробуйте.
После проекта
Для нас важно, чтобы переход от запуска к развитию проходил
бесшовно, иначе могут растеряться результаты проекта. Мне очень
нравится, как про это говорит p3express:
-
Шаг 35. Оценить полученные выгоды
-
Шаг 36. Спланировать дополнительные действия
-
Шаг 37. Фокусированная коммуникация
Мы называем это стратегической сессией. Для стартапов она будет
впервые за время проекта, а для бизнеса уже второй. На ней мы
корректируем KPI, обновляем ожидания от проекта, составляем план
развития и едем дальше. В идеале запускаем новый проект.
Такие регулярные сессии особенно важны, если проект длится
годами. У нас был проект, который начался с лендинга, длился три с
половиной года и в итоге перерос в огромную онлайн-академию с кучей
народу, всякими бонусами, баллами и прочими фишками. За это время в
проекте поменялось всё. И если бы мы не дробили его на маленькие
кусочки и не проводили регулярные стратегические и проблемные
сессии, то нам было бы сложно оставаться в рамках стратегии, планов
и нормальных человеческих отношений.
Я надеюсь, что у вас не возникло ощущение, что p3express нужно
еще допиливать. Потому что это абсолютно не так. Кайф в том, что в
этот фреймворк весь наш огромный багаж не только органично
вписался, но и получил структуру. Если у вас такого багажа нет вам
в p3express будет вполне достаточно его самого, чтобы не сойти с
ума и довести до конца любой проект.







 Василий
Суворов, CEO FitBase
Василий
Суворов, CEO FitBase
 Команда FitBase
Команда FitBase




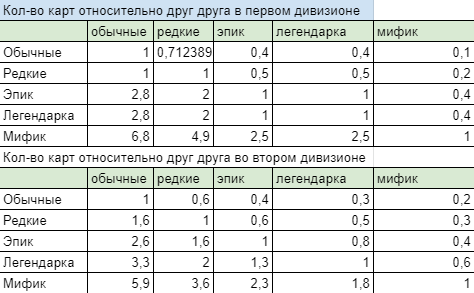


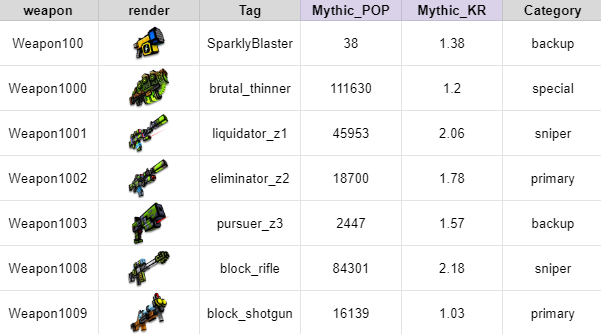


 График популярности оружия
График популярности оружия



 Архитектура Bonita BPM
Архитектура Bonita BPM
 Это приложение, которое устанавливается
на компьютер аналитика или разработчика. Здесь можно редактировать
BPMN-схемы, создавать модели данных, писать скрипты на Groovy,
загружать справочники пользователей, рисовать формы в общем, полный
стартерпак для создания бизнес-процессов.
Это приложение, которое устанавливается
на компьютер аналитика или разработчика. Здесь можно редактировать
BPMN-схемы, создавать модели данных, писать скрипты на Groovy,
загружать справочники пользователей, рисовать формы в общем, полный
стартерпак для создания бизнес-процессов.
 Вот так выглядит BPMN-схема для процесса
"Выдача прав доступа" в Bonita
Вот так выглядит BPMN-схема для процесса
"Выдача прав доступа" в Bonita
 Это пространство, в котором пользователи
управляют задачами, а администраторы процессом. Разворачивается
вместе с сервером, и хорошо работает из коробки.
Это пространство, в котором пользователи
управляют задачами, а администраторы процессом. Разворачивается
вместе с сервером, и хорошо работает из коробки.

 XML-схема, которую генерит Bonita на
основе business data model. Далее в соответствии с этой схемой
будут созданы таблицы в БД
XML-схема, которую генерит Bonita на
основе business data model. Далее в соответствии с этой схемой
будут созданы таблицы в БД

 Пласт коннекторов, позволяющий Bonita
взаимодействовать с внешними системами.Этот механизм облегчает
жизнь разработчику можно подключиться к БД, SOAP, REST, отправлять
письма.
Пласт коннекторов, позволяющий Bonita
взаимодействовать с внешними системами.Этот механизм облегчает
жизнь разработчику можно подключиться к БД, SOAP, REST, отправлять
письма.





 Task-модуль CROC BPM Portal на тесте
Task-модуль CROC BPM Portal на тесте


 живьём.") Немножко труб - тепловой пункт (БТП) живьём.
Немножко труб - тепловой пункт (БТП) живьём.
 И БТП в SCADA системе.
И БТП в SCADA системе.
 Управление всем набором запроектированных
дизайнером светильников в гостиной
Управление всем набором запроектированных
дизайнером светильников в гостиной
 Подключаем
сигнальные линии
Подключаем
сигнальные линии
 Силовой
шкаф до расключения
Силовой
шкаф до расключения
 Основное окно секции освещения
Основное окно секции освещения
 Окно с настройками
Окно с настройками
 Временные тренды
Временные тренды
 Отчет за выбранное время
Отчет за выбранное время
 Отчет за выбранное время
Отчет за выбранное время

 fig:
fig:






 Танюшка - автор канала IT DIVA и данной
статьи, кофеголик и любитель автоматизировать рутину
Танюшка - автор канала IT DIVA и данной
статьи, кофеголик и любитель автоматизировать рутину
 Пример возможной иерархии для расширений движка
Пример возможной иерархии для расширений движка
 Новый элемент меню, через который мы
будем использовать наш инструмент
Новый элемент меню, через который мы
будем использовать наш инструмент
 Пример возможной иерархии для расширений
стандартных классов
Пример возможной иерархии для расширений
стандартных классов
 Результат работы AddPersistentListener
Результат работы AddPersistentListener

 Волшебная кнопка
Волшебная кнопка




 Наглядный профит от использования аналитики
Наглядный профит от использования аналитики
 Простая формула идеального аналитика
Простая формула идеального аналитика

























 Программируемые реле серий EASY800, EASY500 и
EASY700
Программируемые реле серий EASY800, EASY500 и
EASY700
 Новая серия easyE4 и EASY512,
подключенные к питающему напряжению
Новая серия easyE4 и EASY512,
подключенные к питающему напряжению
 easyE4
easyE4
 Web-сервер easyE4 с отображением текущего
состояния входов
Web-сервер easyE4 с отображением текущего
состояния входов
 Модули расширения с комплектными соединителями
Модули расширения с комплектными соединителями
 Артикулы
197211+197222+197223
Артикулы
197211+197222+197223
 EASY800 и EASY700 с кабелями программирования
EASY800 и EASY700 с кабелями программирования
 EasySoft 7
EasySoft 7
 Конвертация "старого" проекта *.e60
Конвертация "старого" проекта *.e60
 Стартовый набор 197227
Стартовый набор 197227
 Электрическая схема подключения
Электрическая схема подключения
 Настройки астрономического таймера
Настройки астрономического таймера