
Компания EPAM давно работает с данными, первые крупные заказчики с проектами поBigDataпоявилисьв далёком 2001 году.В то время известные аналитические компанииGartnerиForrester, а также крупные поставщикиOracle,Microsoftи IBM отмечали, что компании должны двигаться в сторонуBigData, поскольку эти технологии незаменимы во всех областях, связанных с обработкой больших объёмов данных.С того времени команда экспертовEPAMпостепенно росла, работая над всё более сложными проектами и предлагая проверенные решения и качественные продукты для работы с большими данными. Сегодня только в российскомEPAMболее 500 человек работают вData-практике. О том, как всё начиналось, какие проекты встречались, какие провалы случались,к чему должны готовитьсяData-специалисты и о том, какие вообще бываютData-специалисты,я поговорила с руководителемData-практики EPAM в России Ильей Герасимовым.
Карьера

Расскажи, как ты пришёл в направление Data
ВEPAMя пришёл в 2006 годукакjunior-разработчикна .NETиMSSQLServer, до этого работал в продуктовойкомпаниии занимал должность тимлида, разрабатывал ПО для автоматизациигостиници ресторанов.Но вEPAMяначалкарьерус нуля.К 2013 году я дорос дотимлидаиискал новыевозможностисвоегоразвитиявEPAM,и именно в это времяявстретилсянаSECeв Минскес руководителем центра компетенцийBigData, и мы договорились о том, что в России надо развивать это направление.
Тогданас былодва илитричеловека.Нам помогали коллеги из других стран, читали нам курсы, вовлекали нас в различные активности, связанные с этим направлением. Очень много приходилось учиться,а потомраспространять полученныезнания.

Почему так долго работаешь в компании?
Ещё до Data я подумывал пару раз уйти, но что-то не отпускало меня. Сейчас я могу сказать точно, что здесь меня держат люди, с которыми пройдено много всего. И здесь всегда появляется что-то новое новые проекты, заказчики.
Почему именно Data?
Потому чтовесь мир этоData, и мы в нейData.:)
Что сейчас представляет собой Data-практика?
ПостепеннопоявлялисьновыеData-компетенции:Data Science,Machine Learning,Business Intelligence, Enterprise Search, DevOps in Data, Data Quality, Business Data Analysis.Сегодняв нашей практике более 500 человек это оченьбольшое подразделение сглубокойэкспертизойв разных областях.
Постепенно трансформировалось пониманиеподходовк реализации проектовв этой области. Если раньшемы отвечалина вопрос Каки концентрировались в основном на технологиях, то теперь фокусируемся на вопросеЗачеми методологии работы с данными.
Для любого крупного предприятия рано или поздно встает вопросData-менеджмента иData governance,т.е.понимания какие данные у предприятия есть в активе, какие данные они могут получить, как объединить эти данные, источниками которых являются разные подразделенияивнешние источники.Понять кто несёт за эти данные ответственность, кто имеет к ним доступ,как быстро данные устаревают, насколько они достоверны ит.д.
Более глубокое понимание качества данныхэто способ лучше понять бизнес клиента.
Ценность сотрудника в практике определяется не только глубиной его знаний и навыков, но также широтой охвата компетенций, связанных с данными. Сотрудники могут приобретать различные компетенции, переходямежду подразделениями практикиразработка программного обеспечения, моделирование данных, аналитикаданных,DataScienceи др.
Проекты
Вспомни необычный или сложный проект, где пришлось буквально с нуля выстраивать все процессы, применять технологии и методы, которые раньше не использовали
Когда в 2013-2014 году мы начинали, у нас было буквально два-три проекта, мы работали с иностранной нефтегазовой компанией, с российским банком, потом появился проект с расшифровкой генома, а затем и первый проект с Data Science.
Самым сложным и масштабным на тот момент был проект с расшифровкой генома, к тому же это был абсолютно новый для меня язык программирования Scala и первое знакомство с облачными технологиями, серьёзное погружение в DevOps, погружение без скафандра, как говорится. Мы до ночи сидели, пытаясь собрать проект, мы построили много различных акселераторов, это было действительно интересно.
А самый большой провал и как справились с этим?
Первое время провалов было много. В основном они были связаны с нехваткой людей, потому что мы не могли найти готовых людей с улицы со знанием технологий. Мы набираем разработчиков со знанием Java, Python, DevOps-инжиниринг и потом доучиваем.
Все специалисты проходят курсы молодого бойца, чтобы освоить наши технологии и процессы, которые в своё время прошел и я. Внешние курсы не соответствовали нашим запросам, поэтому в 2012 году было принято решение создать свой собственный курс ёмкий, а главное имеющий практическое применение. Писали его сами, своими руками, основываясь на собственном опыте, ошибках. Понятно, что курс требует адаптации и должен меняться в соответствии с технологических ландшафтом и приобретенным опытом. Для поддержания курса в актуальном состоянии требуется много ресурсов, и нам приходится идти на это, чтобы оставаться на передовой, потому что без этого никак, внешние курсы сильно запаздывают от бизнес-реалий, в которых находится EPAM.
Помимо общего курса нашими специалистами разработано много внутренних курсов по разным направлениям Data Analytics, облачные решения, Data Engineering, Data Science и другие, доступных всем сотрудникам EPAM.
Пока это курсы для текущих сотрудников, но сейчас мы пытаемся масштабировать вовне, чтобы к нам приходили специалисты уже подготовленными. В Нижнем Новгороде первый пилотный проект мы открыли доступ к курсу, который могут пройти все желающие освоить эти технологии.
Про технологии
За чем сейчас будущее? На какие технологии появляется и сохраняется спрос?
Если я начну перечислять все технологии, то какие-то пропущу, какие-то не вспомню, на какие-то обращу больше внимания, чем они этого заслуживают. Технологий очень много, они быстро стареют и так же быстро появляются новые. Гнаться за суперсовременными технологиями не всегда получается, да и не всегда нужно. Зачастую новые решения появляются на рынке в довольно сыром состоянии. Однажды на одном проекте мы погнались за технологией Cadence, которая показалась заказчику приемлемой, но в итоге с ней постоянно возникало много проблем с производительностью, она не справлялась с тем объёмом данных, который был на проекте, и мы с трудом находили людей, которые могли бы быстро в ней разобраться.
Был ещё один кейс, на этот раз с технологией Reinforcement Learning. Один из наших заказчиков хотел внедрить систему с использованием этой технологии. Этому фреймворку на тот момент было около 2-х месяцев, он был довольно сырой. В целом было очень мало систем промышленного масштаба, где эта технология используется. В итоге ничего не получилось, и нам пришлось быстро откатить систему и создать решение, которое справлялось с задачей заказчика уже без использования Reinforcement Learning. Хотя технология очень перспективна, мы следим за её развитием и, возможно, даже уже в этом году мы сможем использовать её в проектах.
Но всё же существует некоторый золотой стандарт, который должны знать Data-специалисты. Причём этот стандарт тоже постоянно обновляется. На самом деле, в инкубаторе много проектов, которые завтра взлетят. Многие проекты, которые вошли в золотой стандарт это вчерашний инкубатор. Были, конечно, технологии, которые не взлетели. Так случилось, например, с технологией Theano, она появилась примерно в одно время с TensorFlow, но Theano куда-то исчезла.
-
УApacheесть целый набор инструментов, технологий, которые нужно знать среди нихSpark,Cassandra,Elasticsearchи другие.
-
Yarn, HDFS,MapReduce,Hive,Kafka,ZooKeeper этобазовые технологии, с которых всё начиналось.БазоваятехнологияHadoopникуда не делась,хотя онавыглядит немногоустаревшей, новсе принципы,которые в ней заложены,используются в современных технологиях.
-
Вразличных облачныхтехнологиях вAmazon,MicrosoftAzure,JCPесть свои аналогиHadoop, с которыми мы работаем.
-
Также актуальными являются инструменты защиты данных, такие какKerberos,Knox,Ranger.
-
Понятно, что различныеNoSQLиNewSQLбазы данных Cassandra, например(ужене новая),Snowflake,AmazonRedshift,HBase,MongoDB,Teradata.
-
DevOpsтехнологии Kubernetes, Docker, Jenkins.
-
Технологии визуализации данных:PowerBI,Tableau,QlikView.
-
ВDataScienceтоже множество различных фреймворков,напримерTensorFlowиGoogleBERT (который тоже ужевчерашний день, сегодняесть реализации лучше),PyTorch,Keras.
-
Отдельно стоит перечислить технологииStreaming.Streamingэто новый вызовмираData, поэтомуинструментыстоит знать Spark Streaming, KafkaStreams, ApacheFlink, Apache Storm.
Во многом набор знаний зависит от направления специалиста.
Для всех обязательно знание SQL (стандартного и аналитического), теории DWH (какие типы организации хранилищ данных бывают звезда, снежинка,DataVault, как организовать историчность хранения справочников ит.д.), нормализации данных (чем отличаются первая, втораяи третья нормальные формы, что это такое вообще, в каких случаях полезна денормализация), и понимать, чем отличается DWH,DataMart,DataLake.
Для всех обязательно понимание процесса промышленной разработки, знание систем контроля версий. В последние годы обязательным становиться опыт работы с облаками, хотя бы с одним из наиболее популярных AWS,Azure, GCP.
Для тех, кто занимается ETL (загрузка и преобразование данных перед их использованием) обязательно понимание разницы ETL и ELT, стадий загрузки, способов проверки и очистки данных, понятияslowlychangeddimension. Также обязательно знание как минимум одного языка программирования для написания ETL вручную (PL/SQL, T-SQL,pgSQL,Python,Spark), оркестраторов для запуска процессов (например,Airflow), специализированных программ, каккомерческих, так и бесплатных (Talend,InformaticaPowerCenter,Pentaho,etc.).
Для репортеров (DataAnalyticsandVisualization), помимо знания хотя бы 2-х репортинговых программ (PowerBI,Tableau, TIBCOSpotfire,MicroStrategy,Pentaho, ит.д.) необходимо знание различных подходов в создании отчётов идашбордов(например,Storytelling).
А вы сами участвуете в разработке каких-то технологий?
Наши сотрудникиконтрибьютятвApache Spark, NiFi, Elasticsearch и многие другие. Любой сотрудник может принять участие в проекте. Даже врамках нашего обучающего курса, о котором ярассказывал,одно из заданий доработать какую-то фичу или исправить решение в Open Source проекте.
Кроме того,мы разрабатываемисвоиOpenSourceпродукты, например, Open Data Analytics Hub (ODAHU) проект, предоставляющий компоненты для создания систем автоматизации полного жизненного цикла ML моделей.
Какие технологии используются у вас на проектах?
Мы немного по-другому смотрим на то, как долженстроитьсяподход к управлению проектами в Data он основанненавыборетехнологий,ана методологиях. У нас есть несколько шаблонов (blueprint) для решения тех или иных задач. Это решения задач,с которыми мы часто сталкивались на наших проектах, ужепроверенныевременем.Грубо говоря, у нас естьшаблон,который мынаполняемтехнологиямив зависимостиот задач заказчика, от его приоритетов, инфраструктуры.
Сготовымblueprintмыможем прийти к заказчику и просто как по чек-листусобрать информацию, например,естьлиунегов архитектуре хранилище сырых данных, витрина данных,эксплуатируемое окружение дляDataScientists, процесс миграции данных, вычисления дельтит.д.
Отличаются ли подходы к проектам в разных отраслях?
Мыработаемснефтегазовой отраслью, с банками, сфармацевтическими компаниями,e-commerce,с медиа,со страховым бизнесом, в областиLifeScienceмногопроектоводним словом, в различных бизнес-направлениях.Может показаться, что всё это абсолютно разные направления задач,ноblueprintsпозволяют нам мыслить в одних шаблонах, решать разные задачи с помощью одних и тех же подходов.
Конечно,вкаждойотраслиесть специфические задачи и подходы, и если мы видим растущий бизнес, то мы делаем специализированное решение для той или иной отрасли.Мы разрабатывали специализированныерешения для нефтегазовой, фармацевтической,банковской сферы идругих.
Что изменил 2020 год?
Четкое осознание, что данные нужно уже не только копить, но и заставлять их работать на бизнесу компанийпоявилосьвXXIвеке.И2020 год подтолкнул компании, так называемое позднее большинство (latemajority), которые до этого сомневались вценности использования данных,к изменениямвзглядов и походов.
") The diffusion of innovations according to
Rogers. (From Wikipedia)
The diffusion of innovations according to
Rogers. (From Wikipedia)
Про обучение
Как его лучше организовывать тем, кто интересуется датой: с чего начать, на что делать упор?
Существует много курсов как платных, так и бесплатных,где даютмного информации о технологиях, подходах. И, возможно, придётсяпрослушать десятки курсов,прежде чемизучить тему.
Чтобы начать учиться, необходимоиметьжелание,уверенность в будущемData, и умение программировать хотя бы на одном из языковJava,ScalaилиPython.
В тренинг-центре EPAM есть бесплатные курсы для начинающих специалистов, в том числе по направлениям Data Engineering, Data Science, BI, а также Python и другим языкам, которые помогут стартовать в профессии.

Что должен знать идеальный инженер, претендующий на место в команде Data в EPAM?
Выше подробно описан стек технологий. Если кратко, идеальныйDataгерой должен уметь программировать наJava,ScalaилиPython(вообще, большинство ребят полиглоты в терминах языков программирования),знатьSQL, понимать различные подходы к хранению и обработке данных, их плюсы и минусы, знать различные архитектуры построения гетерогенных систем, обязательно знатьDevOps-инструменты и методологии ведения проектов,умениеработать с облачными технологиямиипониманиеMachineLearningтакже приветствуются.





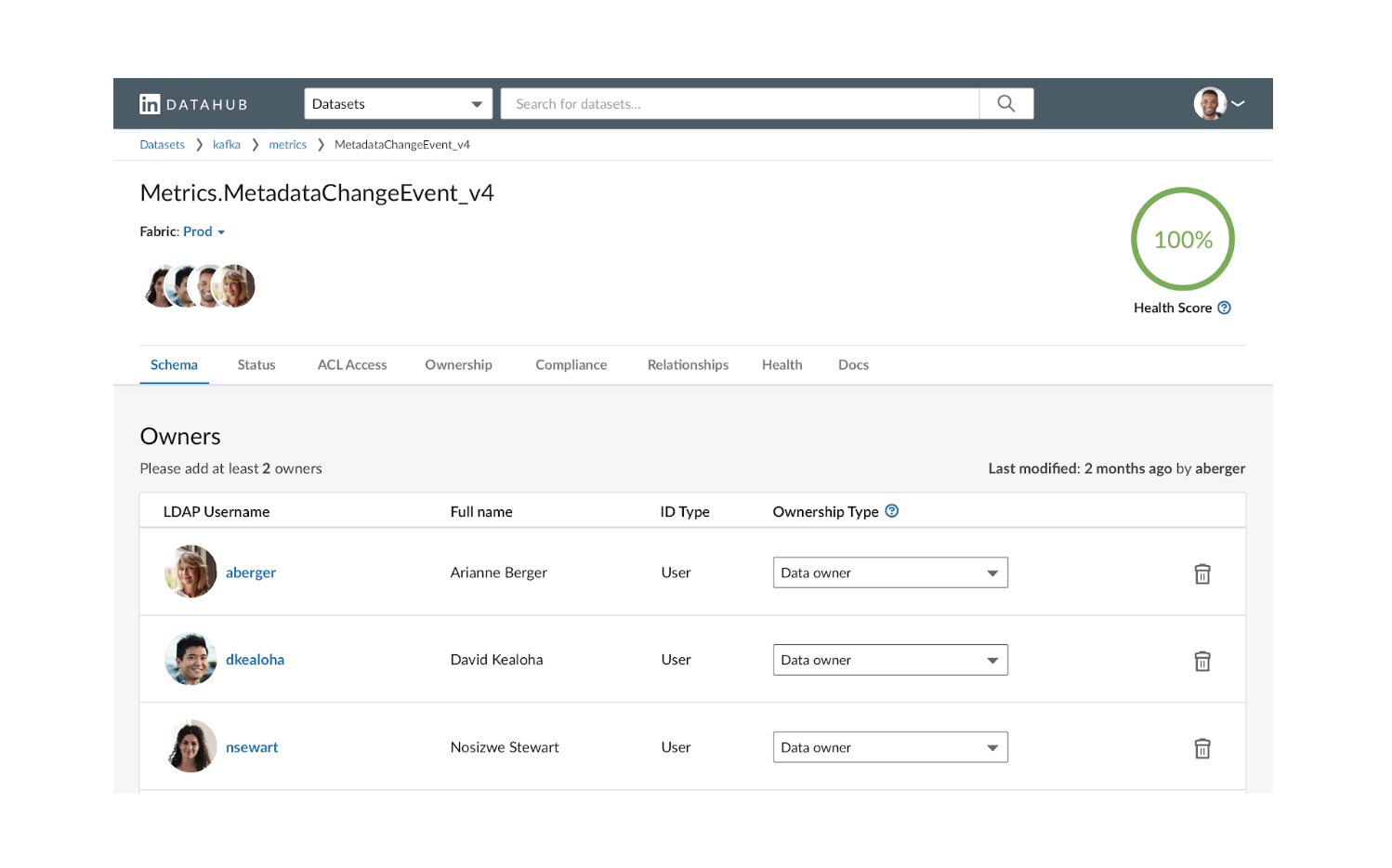


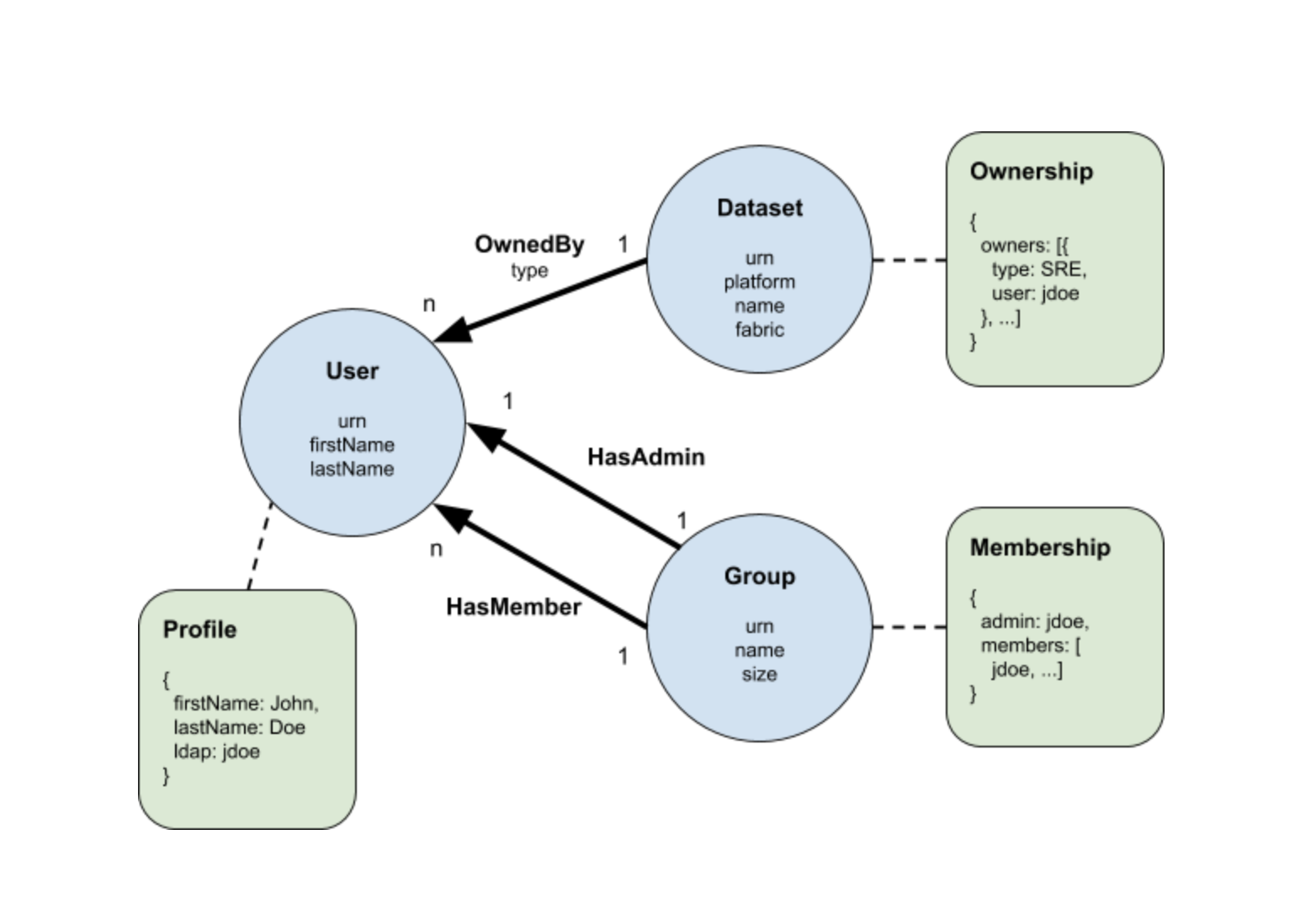

.") Рис. 1 SLA Report предоставляет
высокоуровневый обзор производительности SLA по спискам наборов.
Каждая строка содержит индикатор состояния последнего раздела
данных, а также гистограммы, отражающие данные о времени выгрузки
(красные столбцы показывают дни, когда время выгрузки не
соответствует SLA).
Рис. 1 SLA Report предоставляет
высокоуровневый обзор производительности SLA по спискам наборов.
Каждая строка содержит индикатор состояния последнего раздела
данных, а также гистограммы, отражающие данные о времени выгрузки
(красные столбцы показывают дни, когда время выгрузки не
соответствует SLA).
 Рис. 2 Пример происхождения данных набора
"A". "A" зависит от "B", который зависит от "C" и "D", и так далее.
Рис. 2 Пример происхождения данных набора
"A". "A" зависит от "B", который зависит от "C" и "D", и так далее.
 Рис. 3 Ранняя разведка с акцентом на
происхождение набора. В каждой графе указано историческое время
выгрузки каждого набора данных в более крупном конвейере.
Рис. 3 Ранняя разведка с акцентом на
происхождение набора. В каждой графе указано историческое время
выгрузки каждого набора данных в более крупном конвейере.
 Рис. 4 Timeline даёт чёткое представление
о последовательности и продолжительности преобразований данных,
сохраняя при этом важные иерархические зависимости, которые дают
последовательности контекста. Исторические данные о времени
выгрузки отображаются для каждой строки набора слева от промежутка.
Рис. 4 Timeline даёт чёткое представление
о последовательности и продолжительности преобразований данных,
сохраняя при этом важные иерархические зависимости, которые дают
последовательности контекста. Исторические данные о времени
выгрузки отображаются для каждой строки набора слева от промежутка.
 и отфильтрованного пути к \"узкому\" месту (справа, n=8). Пути узких мест значительно улучшают соотношение сигнал шум и облегчают поиск проблемных этапов больших конвейерах.") Рис. 5 Сравнение всей линии происхождения
(слева, n=82) и отфильтрованного пути к "узкому" месту (справа,
n=8). Пути узких мест значительно улучшают соотношение сигнал шум и
облегчают поиск проблемных этапов больших конвейерах.
Рис. 5 Сравнение всей линии происхождения
(слева, n=82) и отфильтрованного пути к "узкому" месту (справа,
n=8). Пути узких мест значительно улучшают соотношение сигнал шум и
облегчают поиск проблемных этапов больших конвейерах.
 из-за позднего начала вверху и сравнить с длительным выполнением внизу. Объединив эти взаимодополняющие представления в SLA Tracker, мы получаем полную перспективу своевременности данных (рис. 7).") Рис. 6 Исторические распределения времени
выполнения и задержек помогают быстро отличить SLA (красным цветом)
из-за позднего начала вверху и сравнить с длительным выполнением
внизу. Объединив эти взаимодополняющие представления в SLA Tracker,
мы получаем полную перспективу своевременности данных (рис.
7).
Рис. 6 Исторические распределения времени
выполнения и задержек помогают быстро отличить SLA (красным цветом)
из-за позднего начала вверху и сравнить с длительным выполнением
внизу. Объединив эти взаимодополняющие представления в SLA Tracker,
мы получаем полную перспективу своевременности данных (рис.
7). Рис. 7 Трекер SLA состоит из нескольких
представлений. Представление Report даёт обзор состояния набора
данных, Lineage позволяет провести анализ первопричин времени
выгрузки, а Historical фиксирует исторические тенденции в
подробностях.
Рис. 7 Трекер SLA состоит из нескольких
представлений. Представление Report даёт обзор состояния набора
данных, Lineage позволяет провести анализ первопричин времени
выгрузки, а Historical фиксирует исторические тенденции в
подробностях.
 Рис. 8 Эволюция визуального отображения
времени выгрузки; отображены текущее и типичное время.
Рис. 8 Эволюция визуального отображения
времени выгрузки; отображены текущее и типичное время.
: первые ящики с усами, множество промежутков; простые промежутки с дугами зависимостей; упрощение поиска узких мест.") Рис. 9 Эволюция диаграммы Ганта Lineage
(слева направо): первые ящики с усами, множество промежутков;
простые промежутки с дугами зависимостей; упрощение поиска узких
мест.
Рис. 9 Эволюция диаграммы Ганта Lineage
(слева направо): первые ящики с усами, множество промежутков;
простые промежутки с дугами зависимостей; упрощение поиска узких
мест.
 во всех представлениях SLA Tracker (справа) помогла сбалансировать плотность информации, сделав элементы более понятными.") Рис. 10 Разработка простого, но
согласованного языка дизайна (слева) во всех представлениях SLA
Tracker (справа) помогла сбалансировать плотность информации,
сделав элементы более понятными.
Рис. 10 Разработка простого, но
согласованного языка дизайна (слева) во всех представлениях SLA
Tracker (справа) помогла сбалансировать плотность информации,
сделав элементы более понятными.















































 Образец
таблицы с информацией
Образец
таблицы с информацией
 Связь между
двумя столбцами
Связь между
двумя столбцами
 База данных NoSQL реального времени в Google Firebase
База данных NoSQL реального времени в Google Firebase
 pgAdmin4 на Mac
pgAdmin4 на Mac
 Создание новой базы данных для проекта
Создание новой базы данных для проекта
 Создание
таблицы пользователей
Создание
таблицы пользователей
 в pgAdmin") Инструмент запросов (Query Tool) в pgAdmin
Инструмент запросов (Query Tool) в pgAdmin


 Обновление записей
Обновление записей
 Удаление
записей из таблицы
Удаление
записей из таблицы





 Рис. 1
Рис. 1
 Рис. 2
Рис. 2
 Рис.
3
Рис.
3 Рис.
4
Рис.
4 Рис.
5
Рис.
5 Рис.6
Рис.6
 Рис.7. Пример фотографий первого класса
Рис.7. Пример фотографий первого класса Рис. 8. Пример фотографий второго класса
Рис. 8. Пример фотографий второго класса
 Рис.9
Рис.9
 Рис..10
Рис..10 Рис.11
Рис.11
 Рис.12. Архитектура, используемая для
реализации задач
Рис.12. Архитектура, используемая для
реализации задач Рис .13. Пайплайн в Data intelligence
Рис .13. Пайплайн в Data intelligence




























































{kind=link}