

В предыдущей статье, мы вспомнили, что такое WebRTC CDN, как эта технология помогает обеспечивать минимальную задержку в WebRTC трансляциях и почему для CDN не лишним будет использовать балансировку нагрузки и автоматическое масштабирование.
Кратко напомним основные тезисы:
-
В CDN низкая задержка в трансляциях обеспечивается использованием технологии WebRTC для передачи видеопотока от Origin сервера к Edge серверам, которые, в свою очередь, позволяют подключить большое количество зрителей.

-
Если постоянно держать включенными некоторое количество серверов в расчете на большой наплыв зрителей, то, в то время, когда наплыва нет, деньги на аренду серверов расходуются зря. Оптимальным вариантом было бы запускать дополнительные Edge при увеличении потока зрителей и гасить их при уменьшении.

Google Cloud Platform - это стек облачных сервисов, которые выполняются на той же самой инфраструктуре, которую Google использует для своих продуктов. То есть, получается, что пользовательские приложения запущенные в среде Google Cloud Platform, крутятся на тех же серверных мощностях, что и сам "великий и ужасный" Google. Поэтому, можно, с большой вероятностью, ожидать бесперебойной работы серверной инфраструктуры.
Инфраструктура Google Cloud Platform, как и в случае с AWS, поддерживает автоматическое масштабирование и балансировку распределения нагрузки, поэтому не приходится беспокоиться о лишних расходах на оплату виртуальных серверов вы платите только за то, что используете.
На момент написания статьи образа для быстрого развертывания WCS в GCP Marketplace не было. Но есть возможность автоматического развертывания WCS из образа виртуальной машины, который был подготовлен вручную. В этом случае, для WCS используется стандартная ежемесячная лицензия.
Теперь рассмотрим, как развернуть WCS CDN с балансировщиком и автоматическим масштабированием и процесс тестирования развернутой системы.
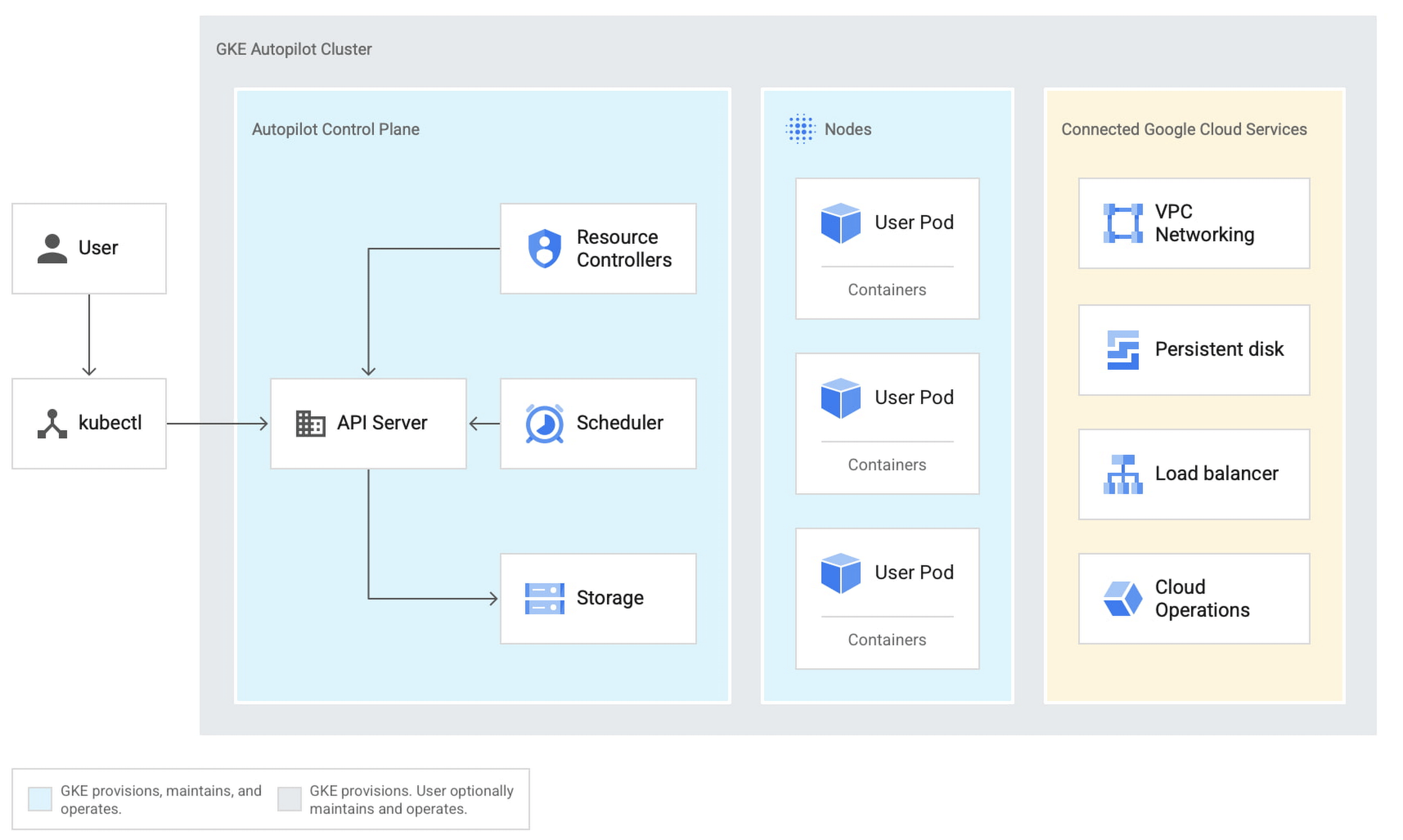
Разворачиваем WebRTC CDN с балансировщиком и автоматическим масштабированием на Google Cloud Platform
Конфигурация CDN будет следующей:
-
один Origin сервер;
-
один Edge в составе балансировщика нагрузки, который позволяет во время пиковой нагрузки увеличить число Edge серверов до трех.
Для развертывания потребуется настроить следующие компоненты в консоли Google Cloud Platform:
-
глобальный файрволл на уровне проекта Google Cloud;
-
виртуальные машины WCS CDN Origin и WCS CDN Edge;
-
шаблон развертывания на основе образа диска WCS CDN Edge;
-
группу масштабирования;
-
балансировщик нагрузки.
Итак, приступим.
Настраиваем глобальный файрволл на уровне проекта Google Cloud для прохождения WebRTC трафика
Настройка межсетевого экрана действует на все запущенные в вашем проекте сервера, поэтому начнем развертывание с нее.
В основном меню консоли Google Cloud откройте раздел "VPC networks" и выберите пункт "Firewall":

На открывшейся странице нажмите кнопку "Create Firewall Rule" :

В открывшемся мастере задайте имя правила:

Ниже на странице разрешите входящий трафик с любых компьютеров:

Еще ниже в секции "Protocols and ports" укажите порты для работы WCS и нажмите кнопку "Create":

Настройка глобального файрволла на этом закончена. Теперь перейдем к развертыванию виртуальных машин, настройке балансировщика и настройке автоматического масштабирования.
Разворачиваем WCS сервер с ролью Origin для WebRTC CDN
В консоли Google Cloud откройте раздел "Compute Engine" и выберите из меню в левой части пункт "VM instances". Нажмите кнопку "Create" в диалоге создания нового экземпляра сервера:

В открывшемся мастере укажите имя сервера, выберите регион и зону расположения датацентра, а также конфигурацию сервера. Выбор конфигурации сервера зависит от планируемых целей использования WCS, бюджета, региона и зоны расположения датацентра GCP. Для тестирования в рамках этой статьи мы используем минимальные технические характеристики виртуальных машин:

Ниже на странице в секции "Boot disk" нажмите кнопку "Change" и выберите образ "CentOS 7":

Разверните секцию "Management, security, disks, networking, sole tenancy":

На вкладке "Security" добавьте публичный ключ для доступа к серверу по SSH:

На вкладке "Networking" в секции "Network interfaces" настройте внешний и внутренний IP адреса для сервера. Для работы в составе CDN серверу нужно назначить статический внутренний IP адрес:

После всех настроек нажмите кнопку "Create" для создания нового экземпляра WCS сервера с ролью CDN Origin:

Спустя пару минут сервер будет создан и запущен. Подключаемся к нему по ssh и устанавливаем WCS. Все действия - установка, изменение настроек, запуск или перезапуск WCS - должны выполняться с root правами, либо через sudo.
1.Установите Wget, Midnight Commander и дополнительные инструменты и библиотеки
sudo yum -y install wget mc tcpdump iperf3 fontconfig
2.Установите JDK. Для работы в условиях больших нагрузок рекомендуется JDK 12 или 14. Удобнее провести установку при помощи скрипта на bash. Текст скрипта:
#!/bin/bashsudo rm -rf jdk*curl -s https://download.java.net/java/GA/jdk12.0.2/e482c34c86bd4bf8b56c0b35558996b9/10/GPL/openjdk-12.0.2_linux-x64_bin.tar.gz | tar -zx[ ! -d jdk-12.0.2/bin ] && exit 1sudo mkdir -p /usr/java[ -d /usr/java/jdk-12.0.2 ] && sudo rm -rf /usr/java/jdk-12.0.2sudo mv -f jdk-12.0.2 /usr/java[ ! -d /usr/java/jdk-12.0.2/bin ] && exit 1sudo rm -f /usr/java/defaultsudo ln -sf /usr/java/jdk-12.0.2 /usr/java/defaultsudo update-alternatives --install "/usr/bin/java" "java" "/usr/java/jdk-12.0.2/bin/java" 1sudo update-alternatives --install "/usr/bin/jstack" "jstack" "/usr/java/jdk-12.0.2/bin/jstack" 1sudo update-alternatives --install "/usr/bin/jcmd" "jcmd" "/usr/java/jdk-12.0.2/bin/jcmd" 1sudo update-alternatives --install "/usr/bin/jmap" "jmap" "/usr/java/jdk-12.0.2/bin/jmap" 1sudo update-alternatives --set "java" "/usr/java/jdk-12.0.2/bin/java"sudo update-alternatives --set "jstack" "/usr/java/jdk-12.0.2/bin/jstack"sudo update-alternatives --set "jcmd" "/usr/java/jdk-12.0.2/bin/jcmd"sudo update-alternatives --set "jmap" "/usr/java/jdk-12.0.2/bin/jmap"
3.Загрузите архив для установки самой свежей стабильной версии WebCallServer:
sudo wget https://flashphoner.com/download-wcs5.2-server.tar.gz
4.Распакуйте архив и запустите скрипт установки WCS и следуйте указаниям мастера установки. Для запуска WCS вам потребуется действительная лицензия. Для правильной работы команды, укажите номер сборки скачанного вами архива:
sudo tar -xvzf FlashphonerWebCallServer-5.2.714.tar.gz && cd FlashphonerWebCallServer-5.2.714 && ./install.sh
5.Для активации лицензии запустите скрипт "./activation.sh" из каталога установки WCS. Этот шаг, при желании, можно пропустить и активировать лицензию позже через веб-интерфейс:
sudo cd /usr/local/FlashphonerWebCallServer/bin && sudo ./activation.sh
6.Отключите firewalld и SELinux. Сетевой экран мы ранее настроили на уровне Google Cloud Platform, поэтому нет необходимости закрывать порты в операционной системе:
sudo systemctl stop firewalld && systemctl disable firewalld && setenforce 0
7.Откройте любым удобным редактором файл flashphoner.properties, который можно найти по пути:
/usr/local/FlashphonerWebCallServer/conf/flashphoner.properties
и внесите в него настройки для запуска CDN. В параметре "cdn_ip" укажите внутренний IP адрес вашей виртуальной машины с ролью CDN Origin:
cdn_enabled=truecdn_ip=10.128.0.3 # Local IP address CDN Origincdn_nodes_resolve_ip=falsecdn_role=origin
На скриншоте ниже примерный вид файла flashphoner.properties для WCS с ролью CDN Origin:

После изменения настроек запустите (или перезапустите) Web Call Server:
systemctl start webcallserver
На этом запуск и настройка Origin закончены. Перейдем к настройке балансировщика нагрузки и автоматического масштабирования.
Запускаем балансировщик нагрузки и автоматическое масштабирование в Google Cloud для WebRTC CDN
Для запуска балансировщика и автоматического масштабирования нужны следующие компоненты:
-
образ диска, который будет использоваться в шаблоне при создании нового экземпляра WCS;
-
шаблон, на основе которого будут создаваться новые экземпляры сервера при масштабировании;
-
группа масштабирования;
-
балансировщик нагрузки;
-
настройки контроля активности сервера.
Создаем образ диска WCS сервера с ролью Edge для WebRTC CDN
Начнем настройку с развертывания WCS сервера с ролью CDN Edge, для того, что бы создать на его основе образ диска для шаблона создания новых экземпляров WCS в балансировщике.
Повторите инструкцию по подготовке сервера Origin до пункта о внесении настроек в файл flashphoner.properties. Для роли Edge внесите в этот файл следующие настройки:
cdn_enabled=truecdn_ip=10.128.0.4cdn_nodes_resolve_ip=falsecdn_point_of_entry=10.128.0.3cdn_role=edgehttp_enable_root_redirect=false

После внесения и сохранения настроек, остановите в консоли Google Cloud виртуальную машину WCS CDN Edge, выберите из меню в левой части пункт "Images" и нажмите кнопку "Create Image":

В открывшемся мастере укажите имя нового образа, выберите в качестве источника диск виртуальной машины WCS CDN Edge и нажмите кнопку "Create":

После того, как образ диска создан переходим к созданию шаблона развертывания Edge сервера на основе созданного образа.
Создаем шаблон развертывания Edge сервера
Выберите из меню в левой части окна консоли Google Cloud пункт "Instance templates" и нажмите кнопку "Create Instance template":

В открывшемся мастере создания шаблона развертывания укажите имя шаблона и выберите конфигурацию виртуальной машины:

Ниже на странице в секции "Boot disk" нажмите кнопку "Change". в Открывшемся окне перейдите на вкладку "Custom Images" и выберите образ диска WCS CDN Edge, который мы создали ранее. Нажмите кнопку "Select":

Разверните секцию "Management, security, disks, networking, sole tenancy". На вкладке "Security" добавьте публичный ключ для доступа к серверу по SSH и нажмите кнопку "Create":

Шаблон развертывания для WCS с ролью CDN Edge создан. Теперь перейдем к созданию группы масштабирования.
Создаем группы масштабирования для Edge серверов
Из меню в левой части окна консоли Google Cloud выберите пункт "Instance groups" и нажмите кнопку "Create Instance group":

На открывшейся странице выберите регион и зону расположения группы и укажите шаблон развертывания WCS Edge, который мы создали ранее:

В секции "Autoscaling" на этой же странице настройте триггер запуска дополнительных серверов Edge. В качестве триггера будем использовать загрузку процессора более 80% . В поле "Maximum number of instances" укажите максимальное количество виртуальных машин, которые будут запущены при срабатывании триггера:

Затем включите проверку состояния виртуальной машины в секции "Autohealing". Для того, что бы создать настройку проверки сервера выберите из списка в поле "Health check" пункт "Сreate a health check":

В открывшемся мастере создания проверки состояния сервера укажите имя проверки, протокол TCP, порт 8081 и запрос /health-check. Настройте критерии проверки и нажмите кнопку "Save and continue":

Разверните секцию "Advanced creation options" и активируйте чекбокс "Do not retry machine creation". После чего нажмите "Create":

Будет создана группа масштабирования и запущен один WCS с ролью CDN Edge. Последним этапом настройки нашей CDN с балансировщиком нагрузки и автоматическим масштабированием будет настройка балансировщика.
Создаем балансировщик нагрузки
Сначала зарезервируем для балансировщика внешний IP адрес. В главном меню Google Cloud Platform в секции "VPC network" выберите пункт "External IP addresses" и нажмите кнопку "Reserve static address":

На открывшейся странице в поле "Name" задаем имя для зарезервированного IP адреса. Выбираем уровень качества сетевых услуг для адреса и тип распространения. После завершения всех настроек нажимаем кнопку "Reserve":

Затем переходим к настройке балансировщика.
Выбираем пункт "Load balancing" в разделе "Network services" секции "Networking" основного меню Google Cloud Platform:

Нажимаем кнопку "Create load balancer":

Затем выберите тип балансировщика "TCP Load Balancing" и нажмите кнопку "Start configuration":

На открывшейся странице укажите внешний балансировщик "From Internet to my VMs" и регион размещения серверов балансировщика. После выбора настроек нажмите кнопку "Continue":

На следующей странице задайте имя балансировщика, Затем перейдите в раздел настроек "Backend configuration" и укажите в каком регионе будут созданы сервера входящие в состав балансировщика. На вкладке "Select existing instance groups" выберите группу масштабирования Edge серверов, которую мы создали ранее. Затем в поле "Health check"выберите из выпадающего списка пункт "Сreate a health check":

На открывшейся странице укажите параметры для проверки состояния работы балансировщика порт 8081 и запрос /, после чего нажмите кнопку "Save and continue":

Затем перейдите к настройкам раздела "Frontend configuration". В этом разделе нужно создать привязку портов к внешнему IP адресу. Укажите внешний IP адрес для балансировщика, который мы зарезервировали выше и создайте конфигурации для TCP портов 8081, 8080, 8443, 8444 для HTTP(S) и WS(S). После создания необходимых портов нажмите кнопку "Create":

Балансировщик будет запущен. На этом развертывание CDN с балансировщиком и масштабированием можно считать завершенным. Переходим к тестированию.
Тестирование WebRTC CDN с балансировщиком и масштабированием на базе Google Cloud Platform
Методика тестирования
Для проведения нагрузочного тестирования, при создании группы масштабирования мы выставили порог загрузки процессора для срабатывания триггера на 20%. Тестирование будем проводить с использованием браузера Google Chrome и виртуальной вебкамеры для организации трансляции видеопотока. Что бы сымитировать повышение нагрузки на процессор запустим воспроизведение потока с транскодированием с помощью примера "Media Devices".
В результате тестирования мы должны убедиться, что повышение нагрузки на процессор виртуальной машины приводит к запуску дополнительных ВМ и балансировщик распределяет соединения между ними.
Тестирование
В браузере Google Chrome открываем web интерфейс WCS с ролью CDN Origin Авторизуемся, открываем пример "Two-way Streaming", устанавливаем соединение с сервером по WebSocket и публикуем видеопоток.

Затем, запускаем web интерфейс WCS CDN Edge сервера по IP адресу, который был зарезервирован при создании балансировщика.
Авторизуемся, открываем пример "Media Devices" и устанавливаем соединение с балансировщиком по WebSocket. В правом столбце настроек снимаем чек бокс "default" для параметра "Size" и задаем значения для транскодирования видеопотока. Например, если поток на Origin сервере опубликован с размерами 320х240 задаем значение 640х480. Повторите действия в нескольких вкладках браузера, для имитации большого количества зрителей.

В консоли Google Cloud видим, что были запущены две дополнительные виртуальные машины:

Для того, что бы проверить, что балансировщик распределяет соединения между активными ВМ можно использовать страницу статистики, которая доступна по адресу:
http://<WCS instance IP address>:8081/?action=stat
Откройте страницу статистики для каждой виртуальной машины, запущенной балансировщиком. Значение "connection_websocket" показывает количество активных WebSocket сессий на каждой виртуальной машине.

Как видите на скриншотах наша задача успешно решена. CDN работает, дополнительные Edge сервера запускаются и WebSocket соединения распределяются между ними. В итоге, мы создали CDN в которой при увеличении нагрузки на сервер Edge, автоматически разворачиваются дополнительные виртуальных сервера для распределения нагрузки и сохранения низкой задержки в видеотрансляции.
Хорошего стриминга!
Ссылки
CDN для стриминга WebRTC с низкой задержкой - CDN на базе WCS
Документация по быстрому развертыванию и тестированию WCS сервера
Документация по развертыванию WCS в Google Cloud Platform
Документация по настройке балансировки нагрузки с масштабированием в GCP



 (источник фото
-https://unsplash.com/photos/XWNbUhUINB8
(источник фото
-https://unsplash.com/photos/XWNbUhUINB8

 Код с конфигурацией - как мясное с молочным?
Код с конфигурацией - как мясное с молочным?






![таблица 1. Среднее и стандартное квадратичное отклонение тестовой области под кривой (AUC) на 6 синтетических наборах данных из [6], для TabNet и других моделей ГНС на основе выбора признаков: Нет выбора: использование всех функций без какого-либо выбора функций, Глобальный: использование только глобально значимых функций, Дерево: Ансамбли деревьев [16], LASSO: регуляризованная модель, L2X [6] и INVASE [61].](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/f7a/9a4/1cc/f7a9a41cc0e58228f9bc8b75a66b7b6b.PNG "таблица 1. Среднее и стандартное квадратичное отклонение тестовой области под кривой (AUC) на 6 синтетических наборах данных из [6], для TabNet и других моделей ГНС на основе выбора признаков: Нет выбора: использование всех функций без какого-либо выбора функций, Глобальный: использование только глобально значимых функций, Дерево: Ансамбли деревьев [16], LASSO: регуляризованная модель, L2X [6] и INVASE [61].") таблица 1. Среднее и стандартное
квадратичное отклонение тестовой области под кривой (AUC) на 6
синтетических наборах данных из [6], для TabNet и других моделей
ГНС на основе выбора признаков: Нет выбора: использование всех
функций без какого-либо выбора функций, Глобальный: использование
только глобально значимых функций, Дерево: Ансамбли деревьев [16],
LASSO: регуляризованная модель, L2X [6] и INVASE [61].
таблица 1. Среднее и стандартное
квадратичное отклонение тестовой области под кривой (AUC) на 6
синтетических наборах данных из [6], для TabNet и других моделей
ГНС на основе выбора признаков: Нет выбора: использование всех
функций без какого-либо выбора функций, Глобальный: использование
только глобально значимых функций, Дерево: Ансамбли деревьев [16],
LASSO: регуляризованная модель, L2X [6] и INVASE [61].
 таблица 2. Производительность для набора
данных типа лесного покрова.
таблица 2. Производительность для набора
данных типа лесного покрова.
 таблица 3. Производительность для набора
данных, симулирующих раздачу карт в покере.
таблица 3. Производительность для набора
данных, симулирующих раздачу карт в покере.
.") таблица 4. Производительность для набора
данных обратной динамики Sarcos Robotics Arm. расчет дерева моделей
TabNet разных размеров (обозначается -S, -M и -L).
таблица 4. Производительность для набора
данных обратной динамики Sarcos Robotics Arm. расчет дерева моделей
TabNet разных размеров (обозначается -S, -M и -L).
") таблица 5. Производительность на наборе
данных Бозона Хиггса. Расчет двух моделей TABNet (обозначены как -S
и -M)
таблица 5. Производительность на наборе
данных Бозона Хиггса. Расчет двух моделей TABNet (обозначены как -S
и -M)
 таблица 6. Производительность на наборе
данных магазина Россмана.
таблица 6. Производительность на наборе
данных магазина Россмана.
 таблица 7. Производительность на наборе данных KDD.
таблица 7. Производительность на наборе данных KDD.
![\eta_{b}[i] = \sum_{c=1}^{N_d}ReLU(d_{b,c}[i])](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/48e/68b/2c3/48e68b2c3a602ef893349cffcc20d930.svg)
![M_{agg-b,j} = \sum_{i=1}^{N_{steps}} \eta_b[i]M_{b,j}[i] / \sum_{j=1}^{D} \sum_{i=1}^{N_{steps}} \eta_b[i] M_{b,j}[i].](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/7b3/3af/3f6/7b33af3f622f2d1cba74ac73e6cbe538.svg)

 таблица 8. Рейтинг важности характеристик
Дохода взрослого населения в переписи. TabNet составляет рейтинг
важности функций в соответствии с хорошо известными методами.
таблица 8. Рейтинг важности характеристик
Дохода взрослого населения в переписи. TabNet составляет рейтинг
важности функций в соответствии с хорошо известными методами.
![Рисунок 5. Маски важности признаков M [i] (которые указывают, какие объекты выбираются на i-м шаге) и совокупная маска важности признаков Magg, показывающая глобальный выбор объекта по экземплярам для наборов данных Syn2 и Syn6 из [6]. Более яркие цвета показывают более высокую ценность. Например, для набора данных Syn2 используются только четыре функции (X3-X6).](http://personeltest.ru/aways/habrastorage.org/getpro/habr/upload_files/053/815/b34/053815b34816dc06138a0a64bf71f1f7.PNG "Рисунок 5. Маски важности признаков M [i] (которые указывают, какие объекты выбираются на i-м шаге) и совокупная маска важности признаков Magg, показывающая глобальный выбор объекта по экземплярам для наборов данных Syn2 и Syn6 из [6]. Более яркие цвета показывают более высокую ценность. Например, для набора данных Syn2 используются только четыре функции (X3-X6).") Рисунок 5. Маски важности признаков M [i]
(которые указывают, какие объекты выбираются на i-м шаге) и
совокупная маска важности признаков Magg, показывающая глобальный
выбор объекта по экземплярам для наборов данных Syn2 и Syn6 из [6].
Более яркие цвета показывают более высокую ценность. Например, для
набора данных Syn2 используются только четыре функции (X3-X6).
Рисунок 5. Маски важности признаков M [i]
(которые указывают, какие объекты выбираются на i-м шаге) и
совокупная маска важности признаков Magg, показывающая глобальный
выбор объекта по экземплярам для наборов данных Syn2 и Syn6 из [6].
Более яркие цвета показывают более высокую ценность. Например, для
набора данных Syn2 используются только четыре функции (X3-X6).
.") Рисунок 6. T-SNE многообразия решений для
тестовых выборок переписи дохода взрослого населения и влияние
главного признака Age (Возраст).
Рисунок 6. T-SNE многообразия решений для
тестовых выборок переписи дохода взрослого населения и влияние
главного признака Age (Возраст).
 Рисунок 7. Сходимость с предварительным
обучением без учителя происходит намного быстрее, что показано для
набора данных Хиггса с выборкой в 10 тыс..
Рисунок 7. Сходимость с предварительным
обучением без учителя происходит намного быстрее, что показано для
набора данных Хиггса с выборкой в 10 тыс.. по Хиггсу с TabNet-М модель, варьируя размером обучающего набора данных для контролируемой тонкой настройки.") таблица 9. Табличные результаты обучения с
самостоятельным контролем. Среднее и стандартное отклонение
точности (более 15 прогонов) по Хиггсу с TabNet-М модель, варьируя
размером обучающего набора данных для контролируемой тонкой
настройки.
таблица 9. Табличные результаты обучения с
самостоятельным контролем. Среднее и стандартное отклонение
точности (более 15 прогонов) по Хиггсу с TabNet-М модель, варьируя
размером обучающего набора данных для контролируемой тонкой
настройки. для типа леса, с варьированием размера обучающего набора данных и контролируемой точной настройки") таблица 10. Табличные результаты обучения
с самоконтролем. Среднее и стандартное отклонение точности (более
15 прогонов) для типа леса, с варьированием размера обучающего
набора данных и контролируемой точной настройки
таблица 10. Табличные результаты обучения
с самоконтролем. Среднее и стандартное отклонение точности (более
15 прогонов) для типа леса, с варьированием размера обучающего
набора данных и контролируемой точной настройки














 Конфигурации ВМ A2 доступные в сервисе Compute
Engine
Конфигурации ВМ A2 доступные в сервисе Compute
Engine
 Новая ВМ A2-MegaGPU: 16 графических
процессоров A100 со скоростью передачи данных 9,6 ТБ/с по
интерфейсу NVIDIA NVLink
Новая ВМ A2-MegaGPU: 16 графических
процессоров A100 со скоростью передачи данных 9,6 ТБ/с по
интерфейсу NVIDIA NVLink


















 Изначально архитектура Web Portal в нашем
проекте выглядела так
Изначально архитектура Web Portal в нашем
проекте выглядела так
 Архитектура нашей системы после миграции в GCP
Архитектура нашей системы после миграции в GCP






























 Листы в
документе "Grade Book"
Листы в
документе "Grade Book"
 Лист
"T1"
Лист
"T1"

 Лист "Grade Book"
Лист "Grade Book"