В одной из прошлых статей мы разобрали несколько ключевых моментов настройки мультиарендного (далее multitenant) кластера Amazon EKS. Что касается безопасности, то это очень обширная тема. Важно понимать, что безопасность касается не только кластера приложений, но и хранилища данных.
AWS в качестве платформы для SaaS решений обладает большой вариативностью для хранилищ данных. Но, как и везде, грамотная настройка безопасности, проработка multitenant-архитектуры под неё, настройка различных уровней изоляций требуют определенных знаний и понимания специфики работы.
Multitenant хранилища данных
Управлять multitenant данными удобно с помощью бункеров, Silo. Основная особенность разделение арендных данных (далее tenant) в multitenant решениях SaaS. Но перед тем, как поговорить о конкретных кейсах, затронем немного общей теории.
Скрытый текст
Термин бункер еще не окончательно
прижился в русском сленге IT-специалистов, но мы будем использовать
именно его, по аналогии с озером данных.
Доступ должен быть только у одного tenant
Безопасность данных это приоритет для SaaS решений. Нужно защитить данные не только от внешних вторжений, но и от взаимодействия с другими tenant. Даже в случае, когда два арендатора сотрудничают друг с другом, а доступ к общим данным контролируют и настраивают согласно бизнес-логике.
Отраслевые стандарты шифрования и безопасности
Стандарты tenant могут отличаться в зависимости от отрасли. Некоторые требуют шифрования данных с четко определенной частотой смены ключей, в то время как остальным вместо общих ключей нужны tenant ориентированные. Благодаря идентификации массивов данных с конкретными tenant, разные стандарты шифрования и настроек безопасности можно применять к отдельным tenant в качестве исключения.
Настройка производительности на основании подписки tenant
Обычно, провайдеры SaaS рекомендуют общий рабочий процесс для всех tenant. С точки зрения практики, это не всегда может быть удобно по отношению к конкретной бизнес-логике. Поэтому можно сделать по-другом. Каждому tenant присваивают разные наборы свойств и пределы производительности в зависимости от стандарта TIER. Чтобы клиенты получали ту производительность, которая заявлена в соглашении SaaS провайдерам приходиться отслеживать использование индивидуальных tenant. Благодаря этому все клиенты получают равноценный доступ к ресурсам.
Скрытый текст
Естественно, это отразится на счетах
клиента. Тот, кто использует больше ресурсов, заплатит
больше.
Управление данными
С ростом SaaS-сервиса растет и количество tenant. Если клиент меняет провайдера, чаще всего он хочет, чтобы все данные перезалили на другой ресурс, а старые удалили. Если первое желание можно оспорить, то исполнение второго гарантируется Общими правилами Евросоюза по защите данных. Для корректного исполнения правил, SaaS провайдер должен изначально идентифицировать массивы данных отдельных tenant.
Скрытый текст
Почему стоит упомянуть именно регламент
Евросоюза и касается ли он компаний из России?! Да, если жители
Евросоюза будут пользоваться услугами компаний, которые собирают
персональные данные. А это примерно треть крупных компаний из
России. Но подобную тему стоит наверное выделить в отдельную статью
и расписать подробнее.
Как превратить обычное Хранилище данных в multitenant
Сразу хочется отметить, что волшебного кода не существует. Нельзя так просто взять и настроить tenant бункер хранилища данных. Нужно учитывать следующие аспекты:
- Соглашение об обслуживании;
- Шаблоны доступа для чтения и записи;
- Соответствие нормативам;
- Расходы.
Но есть ряд общепринятых практик разделения и изоляции данных. Рассмотрим эти кейсы на примере реляционной БД Amazon Aurora.
Секционирование tenant данных в общих хранилищах и инстансах

Таблица используется всеми tenant. Индивидуальные данные разделены и идентифицированы ключом tenant_id. Авторизация в реляционной БД реализована на уровне строк (row-level security). Доступ к приложению работает на основании политики доступа и учитывает конкретный tenant.
Плюсы:
- Это недорого.
Минусы:
- Авторизация на уровне базы данных. Это подразумевает несколько механизмов авторизации в рамках решения: AWS IAM и политики БД;
- Для идентификации tenant придется разработать логику приложения;
- Без полной изоляции невозможно обеспечить выполнение соглашения TIER об обслуживании;
- Авторизация на уровне БД ограничивает возможности отслеживания доступа с помощью AWS CloudTrail. Это можно компенсировать только добавлением информации извне. А лучше бы заниматься отслеживанием и устранением неполадок.
Изоляция данных на общих instance
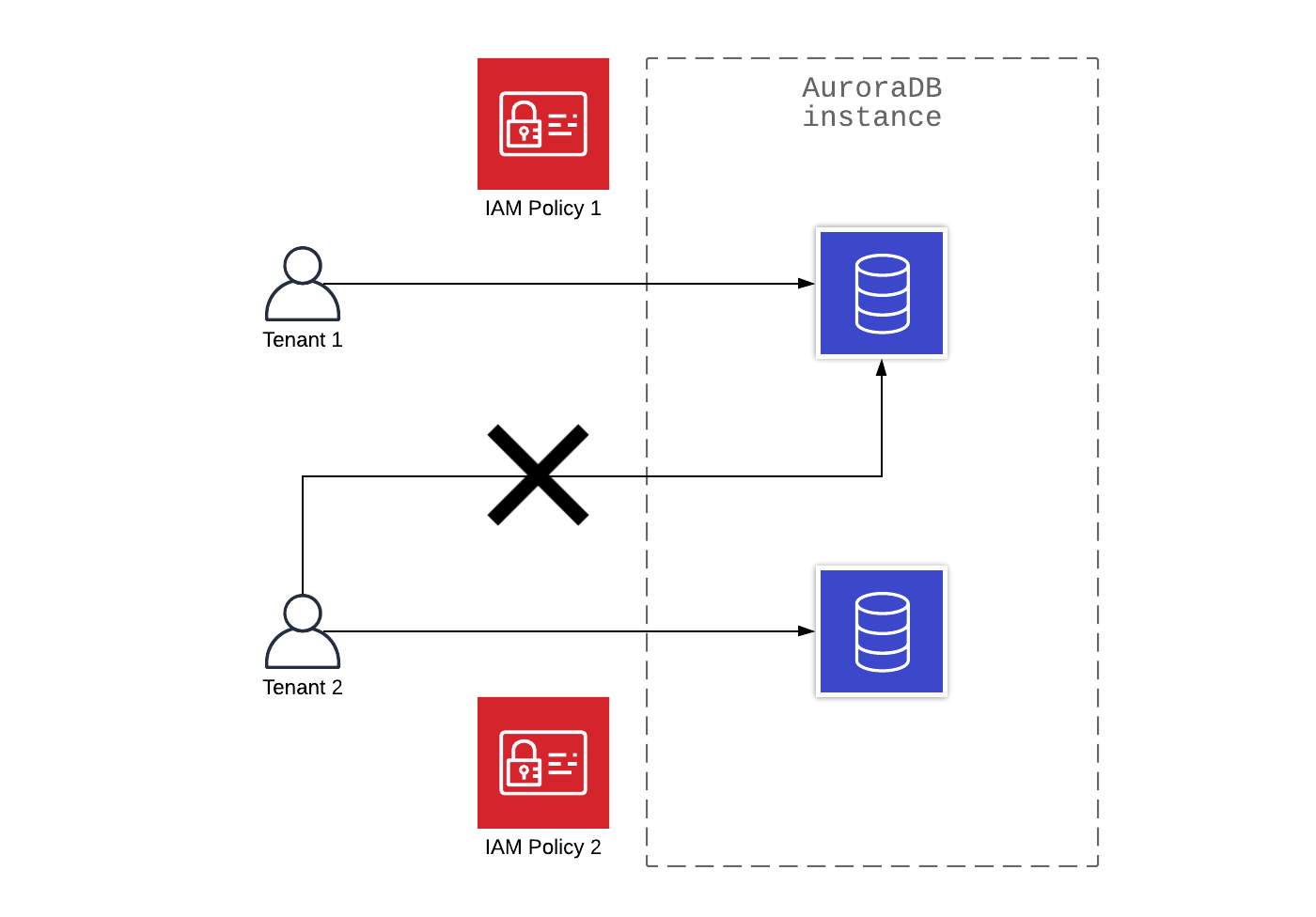
Арендность (tenancy) по-прежнему расшаривается на уровне инстанса. Но при этом бункеризация данных происходит на уровне базы данных. Благодаря этому возможна аутентификация и авторизация AWS IAM.
Плюсы:
- Это недорого;
- За аутентификацию и авторизацию полностью отвечает AWS IAM;
- AWS IAM позволяет вести журнал аудита на AWS CloudTrail без костылей в виде отдельных приложений.
Минусы:
- Базовые инстансы БД шарятся между tenant, в связи с этим возможен отток ресурсов, что не позволяет полностью исполнить соглашение TIER об обслуживании.
Изоляция инстансов базы данных для tenant
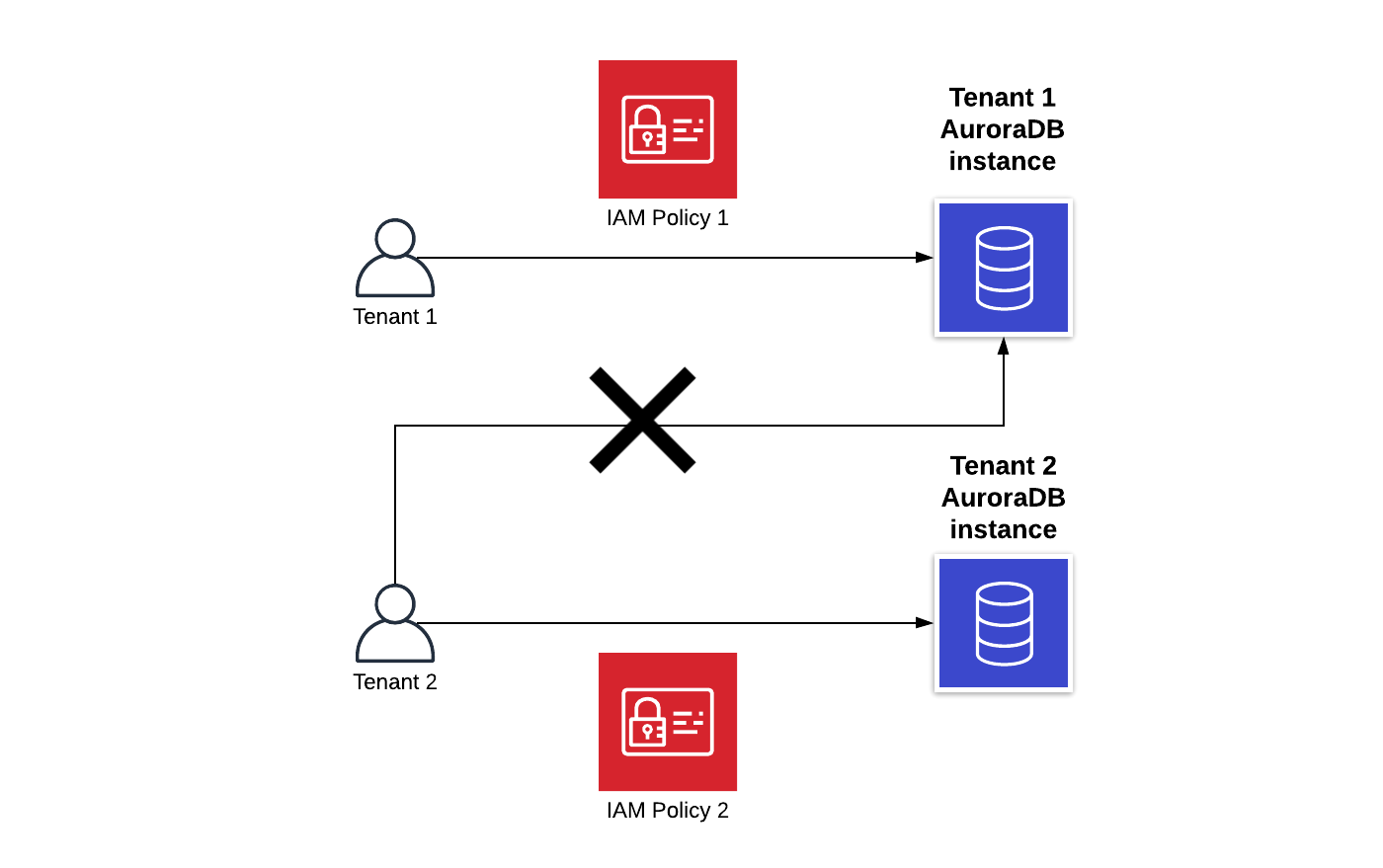
На схеме показана реализация tenant базы данных при изоляции инстансов. На сегодняшний день это, наверное, лучшее решение, сочетающее в себе безопасность и надежность. Здесь есть и AWS IAM, и аудит от AWS CloudTrail, и полная изоляция tenant.
Плюсы:
- AWS IAM обеспечивает как аутентификацию, так и авторизацию;
- Есть полноценный аудит;
- Четкое распределение ресурсов между tenant.
Минусы:
- Изоляция БД и инстансов среди tenant это дорого.
Как реализован доступ приложений к multitenant данным
Обеспечить правильный доступ приложений к данным важнее, чем хранить данные в модели арендной изоляции (tenant), которая соответствует бизнес-требованиям. Это не сложно, если использовать AWS IAM для управления доступом (см. примеры выше). Приложения, которые обеспечивают доступ к данным для tenant также могут использовать AWS IAM. Это можно рассмотреть на примере Amazon EKS.
Чтобы обеспечить доступ к IAM на уровне pod в EKS, прекрасно подойдёт OpenID Connect (OIDC), вместе с аннотациями к учетной записи Kubernetes. В результате произойдет обмен JWT с STS, что создаст временный доступ приложений к необходимым облачным ресурсам. При таком подходе нет необходимости вводить расширенные разрешения для базовых рабочих узлов Amazon EKS. Вместо этого можно настроить только разрешения IAM для учетной записи, связанной с pod. Это делается на основе фактических разрешений приложения, которое работает как часть pod. В итоге получаем полный контроль разрешений приложений и pod.
Скрытый текст
А благодаря тому, что AWS
CloudTrail регистрирует каждое обращение EKS pod
к API, можно вести детальный журнал событий.
Интеграция IAM поддерживает комплексную систему авторизации для доступа tenant к хранилищам данных. В этом случае доступ к БД контролируется только через аутентификацию, а значит, нужно вводить еще один уровень безопасности.
Amazon EKS получает доступ к multitenant БД AWS DynamoDB
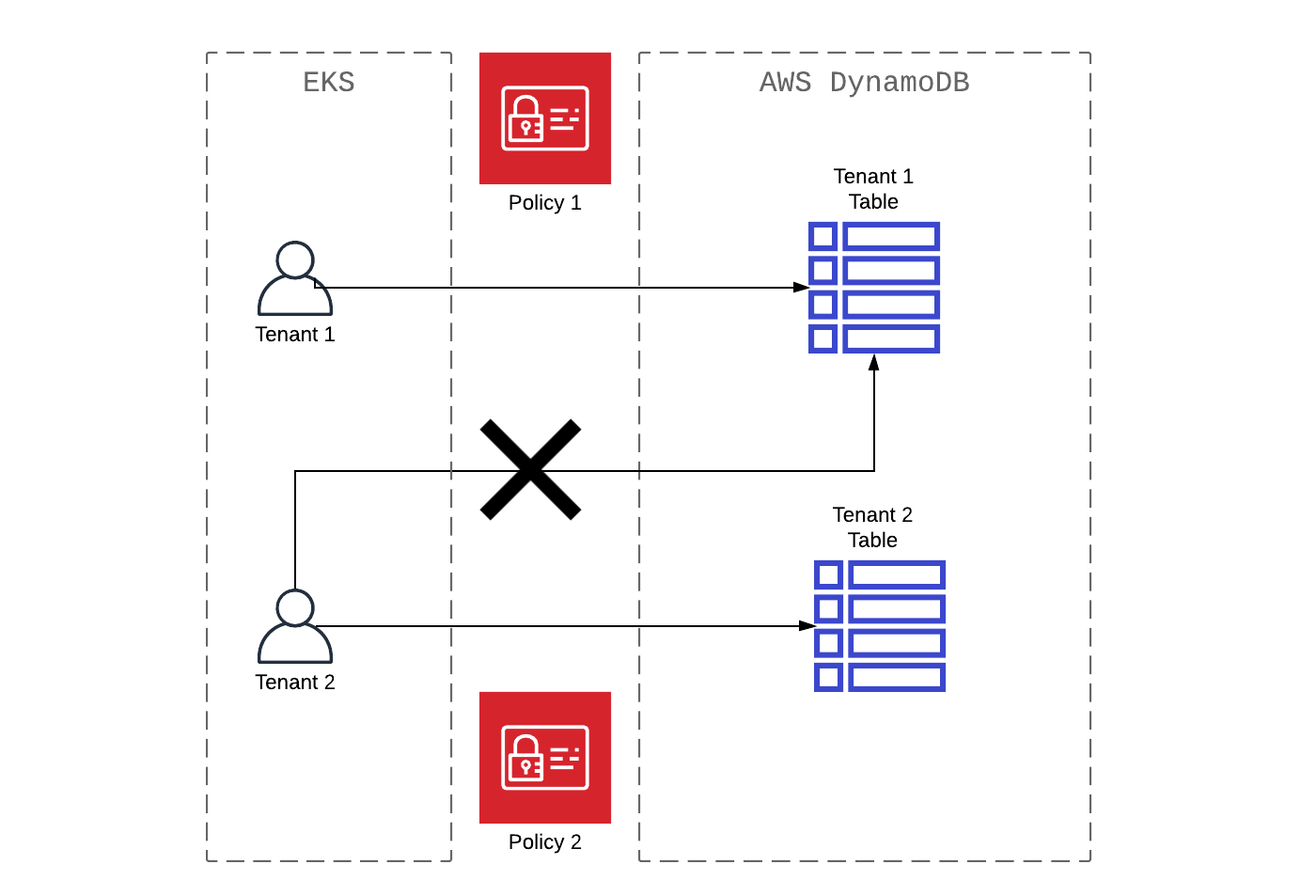
Пристальней посмотрим на multitenant доступ, как приложение, работающее на Amazon EKS, получает доступ к multitenant базе данных Amazon DynamoDB. Во многих случаях multitenant процессы в Amazon DynamoDB реализуют на уровне таблиц (в соотношении таблиц и tenant 1:1). Как пример рассмотрим принцип AWS IAM (aws-dynamodb-tenant1-policy), который отлично иллюстрирует шаблон доступа, где все данные связаны с Tenant1.
{ ... "Statement": [ { "Sid": "Tenant1", "Effect": "Allow", "Action": "dynamodb:*", "Resource": "arn:aws:dynamodb:${region}-${account_id}:table/Tenant1" } ]}
Следующий шаг связать эту роль с учетной записью кластера EKS, которая использует OpenID.
eksctl utils associate-iam-oidc-provider \ --name my-cluster \ --approve \ --region ${region}
eksctl create iamserviceaccount \ --name tenant1-service-account \ --cluster my-cluster \ --attach-policy-arn arn:aws:iam::xxxx:policy/aws-dynamodb-tenant1-policy \ --approve \ --region ${region}
Определение pod, содержащее необходимую спецификацию serviceAccountName, поможет использовать новую учетную запись службы tenant1-service-account.
apiVersion: v1kind: Podmetadata: name: my-podspec:serviceAccountName: tenant1-service-account containers: - name: tenant1
Несмотря на то, что учетная запись и политика IAM tenant ориентированы, статичны и управляются с помощью таких инструментов, как Terraform и Ansible, спецификацию pod можно настроить динамично. Если вы используете генератор шаблонов, например, Helm, serviceAccountName можно установить в качестве переменной в соответствующие учетные записи tenant служб. В итоге у каждого tenant будет свое выделенное развертывание одного и того же приложения. Фактически, у каждого tenant должно быть выделенное пространство имен, где и будут запускаться приложения.
Скрытый текст
Эти же методы можно реализовать с помощью
Amazon Aurora Serverless, Amazon Neptune и контейнеров Amazon
S3.
Заключение
Для SaaS-услуг важно хорошо продумать, как будет осуществляться доступ к данным. Следует учесть требования к хранилищу, шифрованию, производительности и управлению со стороны tenant. В multitenant нет какого-то одного предпочтительного способа разделения данных. Преимуществом выполнения multitenant рабочих нагрузок на AWS является AWS IAM, который можно использовать для того, чтобы упростить контроль доступа к tenant данным. К тому же, AWS IAM поможет настроить доступ приложений к данным в динамическом режиме.
Описанные особенности и приемы, которые могут пригодиться, затронули немного теории. Но частных случаях всегда необходимо самостоятельно анализировать исходную информацию и создавать персонализированные решение.