
Ну и год же был 2020! Мы счастливы представить релиз 13.7 с
более чем 45 фичами и улучшениями поставки ПО,
вышедший как раз к праздникам.
От имени всех сотрудников GitLab мы хотим поблагодарить
участников нашего сообщества за ваш вклад и за то положительное
влияние, которое вы оказываете на нашу работу. Без вас GitLab не
был бы таким, как сейчас.
Благодарим вас и всех членов команды GitLab, которые помогли
сделать 2020 год невероятным, несмотря на невзгоды и
непредсказуемые обстоятельства. Пожалуйста, оставайтесь в
безопасности, будьте счастливы и здоровы в этот праздничный
период.
Вот что вас ждёт в релизе 13.7:
Улучшенное управление проектами для развития совместной работы
Мерж-реквесты (в русской локализации GitLab запросы на слияние)
имеют решающее значение для развития совместной работы и могут быть
напрямую связаны с соответствующими тикетами, предоставляя
центральное место для общения посредством комментариев, предложений
по изменениям в коде и ревью кода. В этом релизе мы добавили
проверяющих для
мерж-реквестов способ улучшить процесс ревью кода, сделав его
более лёгким и организованным. Теперь вы сможете быстро выяснить,
кто участвовал в мерж-реквесте, или запросить у кого-то ревью,
отправив соответствующее уведомление.
Переключение контекста и выполнение заданий вручную в рабочем
процессе затрудняют эффективное взаимодействие между группами и
проектами. Это означает, что вы проводите меньше времени за
разработкой ценных фич и больше времени тратите на работу с
проектами, поэтому возможность клонировать тикеты с
помощью быстрых действий наверняка вам пригодится, поскольку
поможет оптимизировать управление проектами и гибкое планирование с
agile.
Совместная работа над проектами и частое
итерирование при разработке ваших приложений
подразумевают, что вы должны быть в состоянии быстро определить
степень важности ваших тикетов, выявить любые блокирующие задачи и
использовать эту информацию для расстановки приоритетов при
принятии решений. Теперь вы можете сортировать по
количеству блокируемых тикетов, чтобы быстрее находить те
тикеты, которые блокируют прогресс по другим тикетам.
Улучшена автоматизация релизов и гибкость развёртывания
В управлении организацией, автоматизацией и развёртыванием
приложений на регулярной основе вам необходима гибкость. Надёжное и
частое развёртывание приложений позволяет быстрее поставлять
продукт заказчикам.
Чтобы улучшить автоматизацию релизов в GitLab, мы добавили
автоматический
откат в случае сбоя. Эта фича отменяет неудачное развёртывание,
восстанавливает последнее успешное развёртывание и посылает
автоматическое уведомление об этом. Вам не придётся вносить
изменения вручную, и вы можете быть уверены, что потенциальные
проблемы не приведут к простоям и ситуация не ухудшится, пока вы
работаете над устранением неполадок.
Ещё одно улучшение, которое хорошо сочетается с автоматическим
откатом в случае сбоя, возможность посмотреть
статус развёртывания на странице окружений. Просматривать
статусы развёртываний стало гораздо удобнее, как и определять,
какие действия вам нужно предпринять, например, остановить или
откатить развёртывание.
Мы также выпустили первую официально поддерживаемую бета-версию
контейнера
обработчика заданий GitLab для Red Hat OpenShift, а также нашего
сертифицированного оператора обработчиков заданий, чтобы дать
вам больше свободы в том, как вы выпускаете релизы с GitLab. Мы
работаем над тем, чтобы сделать эту фичу общедоступной, так что
следите за новостями в будущих релизах.
Более надёжное и эффективное управление пакетами и
зависимостями
Ваш рабочий процесс зависит от множества языков
программирования, бинарных файлов, интеграций и артефактов, которые
являются важными входными или выходными данными в вашем процессе
разработки. Чем эффективнее вы управляете своими пакетами и
зависимостями, тем меньше рабочего времени уходит впустую. Чтобы
повысить эффективность работы с реестром пакетов, мы добавили
быстрый поиск и
просмотр общих пакетов.
Мы также внесли улучшения в прокси зависимостей от GitLab;
кстати, эта фича была перенесена в Core в GitLab 13.6.
Теперь вы можете вписаться в
ограничения запросов Docker и ускорить работу конвейеров (в
русской локализации GitLab сборочные линии) благодаря кэшированию
образов контейнеров, размещённых на DockerHub, и быть уверенными в
надёжности и эффективности работы с образами.
Ещё одно улучшение, которого ожидали многие из нашего
сообщества, прокси зависимостей
теперь работает и с приватными проектами, так что теперь этой
фичей смогут воспользоваться и те пользователи, которые
предпочитают работать с приватными проектами.
И, наконец, вы можете использовать
предопределённые переменные с прокси зависимостей взамен того,
чтобы полагаться на свои собственные определённые переменные или
вшитые значения в вашем файле gitlab.ci-yml. Таким
образом, появился более масштабируемый и эффективный способ начать
проксирование и кэширование образов.
И это ещё не всё!
Взгляните на ещё несколько классных новых фич релиза 13.7:
Это всего лишь некоторые из множества новых фич и улучшений
производительности этого релиза. Если вы хотите заранее узнать, что
вас ждёт в следующем месяце, загляните на страницу будущих релизов, а также посмотрите наше
видео по релизу 13.8.
6-7го января у нас прошёл виртуальный хакатон, узнайте больше об
этом и будущих мероприятиях от GitLab здесь.

Rachel активно помогала нашей команде технических писателей
внедрить согласованный стиль в документации для исправления
использования будущего времени в наших
документах. В релизе 13.7 Rachel открыла 33 мерж-реквеста, чем помогла нашей
команде справиться с этой важной и кропотливой задачей. Спасибо,
Rachel!
Основные фичи релиза
GitLab 13.7
Проверяющие для
мерж-реквестов
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Стадия цикла DevOps: Create
Попросить коллегу просмотреть ваш код должно быть обычной частью
рабочего процесса, но иногда это бывает неоправданно сложно. Такая
простая задача, как запрос на ревью, может привести к путанице.
Например, как именно следует запрашивать: через электронное письмо,
комментарий, сообщение в чате? Без формального механизма ревью
мерж-реквестов могут быть непоследовательными, и за их проведением
будет сложно уследить. Раньше уже можно было назначить проверяющего
на мерж-реквест, но и автор, и рецензент отображались в одном и том
же поле Assignee, что не позволяло другим членам команды узнать,
кто за что отвечал в этом мерж-реквесте.
GitLab 13.7 представляет новую фичу теперь авторы мерж-реквеста
могут запросить ревью у конкретных пользователей. В новом поле
Reviewers пользователи могут быть назначены проверяющими для
мерж-реквеста аналогичным образом, как назначаются ответственные
(assignee). Назначенные на ревью пользователи получат уведомление,
предлагающее им просмотреть мерж-реквест. Таким образом, теперь
существует формальный процесс запроса ревью для мерж-реквеста и
уточняются роли каждого пользователя в работе над ним.
Будущие итерации будут включать отображение наиболее подходящих
проверяющих для мерж-реквеста, а также усовершенствованный процесс
подтверждения мерж-реквеста, который будет сфокусирован именно на
проверяющих. Подробнее об этом вы можете узнать в эпике по назначению проверяющих для ревью
мерж-реквестов.

Документация по назначению проверяющих для
мерж-реквеста и оригинальный тикет.
Автоматический откат
в случае сбоя
(ULTIMATE, GOLD) Стадия цикла DevOps: Release
Если у вас возникла критическая проблема с развёртыванием,
ручные действия по её устранению могут занять довольно много
времени и привести к сбоям на продакшене, что негативно скажется на
пользователях. Теперь вы можете использовать автоматический
механизм отката, который возвращает ваше развёртывание обратно к
последнему успешному развёртыванию. Кроме того, когда GitLab
находит проблемы на продакшене, он автоматически уведомляет вас об
этом. Так вы всегда будете своевременно узнавать о проблемах, и
получите драгоценное время для отладки, исследования и исправления
проблем без лишних простоев в работе.
Документация по автоматическому откату при сбое
и оригинальный тикет.
Клонирование
тикета через быстрое действие
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Стадия цикла DevOps: Plan
Чтобы сделать создание похожих тикетов более эффективным, тикеты
теперь поддерживают быстрое действие /clone, которое
создаёт в том же проекте новый тикет с идентичными названием,
описанием и метаданными. Быстрое действие /clone
заменяет более трудоёмкий процесс, который включал в себя несколько
шагов для создания тикета, копирования идентификатора или пути к
исходному тикету и использование быстрого действия
copy_meta.
По умолчанию тикеты клонируются в тот же проект и не включают в
себя системные заметки и комментарии, но вы можете изменить
поведение по умолчанию при клонировании.

Документация по быстрым действиям и оригинальный тикет.
Обработчик заданий GitLab для Red Hat OpenShift
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Стадия цикла DevOps: Verify
Наконец-то стал доступен образ контейнера обработчика заданий
GitLab (GitLab runner) для платформы контейнеров Red Hat OpenShift! Чтобы
установить обработчик заданий на OpenShift, воспользуйтесь новым
оператором обработчиков заданий GitLab. Он
доступен на бета-канале в Red Hat's Operator Hub веб-консоли для
администраторов кластеров OpenShift, уже развёрнутой по умолчанию
на платформе, где они могут найти и выбрать операторы для установки
на своём кластере. На платформе контейнеров OpenShift Operator Hub
уже развёрнут по умолчанию. Мы планируем перенести оператор
обработчика заданий GitLab на стабильный канал, а в начале 2021
года в общий доступ. Наконец, мы также разрабатываем
оператор для GitLab, так что следите за будущими публикациями.

Документация по установке на OpenShift и
оригинальный тикет.
Просмотр статуса развёртываний на странице окружений
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Стадия цикла DevOps: Release
Ранее на странице окружений не было никакого способа узнать о
том, что сейчас выполняется развёртывание. Теперь на этой странице
отображаются статусы развёртываний и предупреждения, благодаря чему
вы можете принять решение о том, какие действия нужно предпринять,
основываясь на статусе развёртывания (успешное, неудачное или
текущее). Например, можно остановить текущее развёртывание или
откатить завершённое.

Документация по работе с окружениями и оригинальный тикет.
Задавайте через пользовательский интерфейс процент трафика для
канареечного развёртывания
(PREMIUM, ULTIMATE, SILVER, GOLD) Стадия цикла DevOps: Release
В GitLab 13.7 вы можете менять процент трафика для канареечного
развёртывания (значение canary-weight) непосредственно с досок
развёртывания в пользовательском интерфейсе. Вы также можете менять
это значение из gitlab-ci.yml и через API, но сделав
это в пользовательском интерфейсе, вы сможете наблюдать за
развёртыванием и при необходимости отмасштабировать поды прямо с
досок развёртывания. Так у вас будет больше контроля над ручными
или инкрементальными развёртываниями по таймеру, а также вы сможете
лучше контролировать и даже снижать риски.

Документация по заданию процента трафика для
канареечного развёртывания и оригинальный тикет.
Просмотр
частоты развёртываний через API
(ULTIMATE, GOLD) Стадия цикла DevOps: Release
В этом релизе в рамках первой итерации встроенной в GitLab
поддержки метрик DORA4 была добавлена возможность узнавать
частоту развёртываний на уровне проекта через API. Это позволяет
отслеживать эффективность развёртывания с течением времени, легко
находить узкие места и при необходимости быстро принимать меры по
корректировке.

Документация по аналитике проектов и оригинальный тикет.
Поддержка
нескольких файлов манифеста в проекте
(PREMIUM, ULTIMATE) Стадия цикла DevOps: Configure
В предыдущих релизах для использования нашего агента для
Kubernetes (GitLab Kubernetes Agent) требовалось, чтобы
пользователи собирали все ресурсы Kubernetes в один файл манифеста.
Теперь же агент может собирать манифесты Kubernetes рекурсивно из
указанных каталогов в вашем проекте. Ваши специалисты по платформе
теперь смогут использовать один репозиторий для управления
различными кластерами из единого места, а также описывать крупные
развёртывания с помощью одного агента.

Документация по настройке репозитория с агентом
Kubernetes и оригинальный тикет.
Импорт
требований из внешних инструментов
(ULTIMATE, GOLD) Стадия цикла DevOps: Plan
Для эффективной совместной работы очень важно, чтобы все ваши
требования хранились в одном месте, поэтому мы рады сообщить, что
теперь вы можете импортировать требования из CSV-файлов!
Благодаря этой фиче вы сможете всей командой работать над
требованиями в GitLab, и в то же время с лёгкостью
взаимодействовать с клиентами, поставщиками и внешними
организациями. Следите за обновлениями о будущих улучшениях
экспорта требований.

Документация по импорту требований из CSV-файла
и оригинальный тикет.
Несколько
конечных точек HTTP для оповещений
(PREMIUM, ULTIMATE, SILVER, GOLD) Стадия цикла DevOps: Monitor
Интеграции оповещений являются критически важной частью ваших
рабочих процессов по управлению инцидентами, поэтому важно иметь
точный контроль над конечными точками и токенами аутентификации.
Меньше всего вам нужно, чтобы все ваши оповещения перестали
работать из-за смены одного токена аутентификации. Настройка
конечной точки HTTP для каждого инструмента мониторинга позволит
вашей команде управлять каждым инструментом в отдельности, не влияя
на оповещения от других инструментов.

Документация по конечным точкам для оповещений и
оригинальный эпик.
(SILVER, GOLD) Стадия цикла DevOps: Manage
В GitLab 13.7 вы можете привязать группу в вашем поставщике
учётных записей к группе на GitLab.com с помощью SAML. Членство в
группе будет обновляться, когда пользователь войдёт в учётную
запись GitLab через своего провайдера SAML. Эта фича снижает
необходимость в ручном назначении групп, что снижает загрузку по
группам для администраторов GitLab. Синхронизация групп также
улучшает адаптацию новых членов групп, избавляя их от необходимости
запрашивать доступ у администраторов групп GitLab.

Документация по синхронизации групп с помощью
SAML и оригинальный эпик.
Другие улучшения в GitLab
13.7
DevOps Adoption
(ULTIMATE) Стадия цикла DevOps: Manage
DevOps Adoption показывает вам, какие команды в вашей
организации используют тикеты, мерж-реквесты, подтверждения,
обработчики заданий, конвейеры, развёртывания и сканирования в
GitLab. Используйте также новую фичу сегменты, чтобы собрать ваши
группы GitLab в логические единицы в рамках вашей организации,
чтобы вы могли сравнивать, как используют GitLab среди нескольких
разных групп.
- Убедитесь, что вы получаете ожидаемую отдачу от использования
GitLab.
- Узнайте, какие группы отстают во внедрении GitLab, и помогайте
им с настройкой DevOps.
- Узнайте, какие группы используют определённые фичи, такие как
конвейеры, и могут поделиться своим опытом с другими группами,
которые хотят начать ими пользоваться.

Документация по DevOps Adoption и оригинальный тикет.
Улучшенный пользовательский интерфейс для создания проектов
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Стадия цикла DevOps: Manage
С улучшенным пользовательским интерфейсом для добавления проекта
вам будет проще выбрать между созданием пустого проекта, проекта из
шаблона, импортом проекта и созданием проекта CI/CD для внешних
репозиториев.
Документация по созданию проектов и оригинальный тикет.
Ограничение создания проектов и групп для внешних аккаунтов
(PREMIUM, ULTIMATE, SILVER, GOLD) Стадия цикла DevOps: Manage
Для снижения риска случайного раскрытия интеллектуальной
собственности администраторы GitLab теперь имеют больший контроль
над аккаунтами, предоставляемыми через интеграцию группы с помощью
SAML или SCIM. В первой итерации этой фичи администраторы могут
запрещать своим пользователям создавать группы или проекты вне
групп, к которым они принадлежат.
Документация по настройкам пользователя через
SAML и оригинальный тикет.
Сортировка по
числу блокируемых тикетов
(STARTER, PREMIUM, ULTIMATE, BRONZE, SILVER, GOLD) Стадия цикла DevOps: Plan
При сортировке списка тикетов в GitLab часто бывает важно
определить, какие из них необходимо выполнить наиболее срочно, и
блокируют ли они другие тикеты.
Ранее в списке тикетов было невозможно посмотреть, какие из
тикетов блокируют другие. Единственный способ это сделать это
открыть каждый из них и просмотреть список блокируемых тикетов под описанием тикета,
что занимает очень много времени.
В версии 13.7 вы можете использовать фильтр Блокирует другие
тикеты для списка тикетов, чтобы отсортировать его по числу
блокируемых тикетов.

Документация по сортировке и оригинальный тикет.
Просмотр
файлов в мерж-реквестах по одному
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Стадия цикла DevOps: Create
Ревью мерж-реквестов это важнейшая задача для обеспечения
качества кода всех участников, так как именно здесь происходит
большая часть обсуждений между автором и ревьюером. Однако, по мере
того, как мерж-реквесты становятся крупнее и число файлов в них
увеличивается, навигация и производительность диффов могут
ухудшаться.
В GitLab 13.7 мы добавили возможность просматривать файлы по
одному при просмотре мерж-реквеста. При переходе на вкладку
мерж-реквеста Изменения кликните на иконку с
шестерёнками и поставьте галочку Показывать файлы по
одному. После выбора этого параметра вы сможете
просматривать файлы по одному, переключаясь между ними при помощи
кнопок Предыдущий и
Следующий.
В этом режиме ваше рабочее пространство выглядит менее
перегруженным, и вам проще сосредоточиться на одном файле. Кроме
того, при этом повышается производительность и улучшается навигация
по диффу мерж-реквеста.

Документация по ревью и управлению
мерж-реквестами и оригинальный тикет.
Просмотр
изменений мерж-реквеста в VS Code
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Стадия цикла DevOps: Create
При ревью мерж-реквестов в VS Code для обращения к изменениям
зачастую приходится делать checkout ветки и затем пытаться
разобраться в диффе между этой веткой и целевой веткой мержа.
С релизом 3.7.0 расширения GitLab Workflow изменения мерж-реквеста стали
доступны напрямую в VS Code. Это позволяет быстро просматривать
изменения в мерж-реквестах ваших проектов.
В рамках работы над добавлением полноценного ревью кода в VS Code следующим шагом мы
собираемся добавить комментарии к диффам.

Документация по расширению для VS Code и
оригинальный тикет.
Улучшенное скачивание артефактов для вложенных конвейеров
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Стадия цикла DevOps: Verify
Ранее при скачивании артефактов из родительского конвейера во
вложенный не всегда можно было получить нужные артефакты. Если два
вышестоящих конвейера были запущены примерно в одно время, то
вложенный конвейер мог скачать артефакты и из более нового
конвейера.
Теперь вы можете использовать новый синтаксис
needs:pipeline, чтобы указать вложенному конвейеру, из
какого конвейера ему нужно скачивать артефакты. Вы можете
использовать его, чтобы скачивать артефакты из родительского
конвейера или из другого вложенного конвейера в рамках той же
иерархии.

Документация по скачиванию артефактов для вложенных
конвейеров и оригинальный тикет.
Обход
ограничений Docker и ускорение конвейеров
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Стадия цикла DevOps: Package
Для более быстрых и надёжных сборок вы можете использовать нашу
фичу, прокси зависимостей, для кэширования образов контейнеров из
Docker Hub. Однако, когда Docker начал применять ограничения по количеству запросов docker
pull, вы могли заметить, что даже когда ваш образ
скачивался из кэша, Docker всё равно засчитывал его в лимит. Это
происходило потому, что прокси зависимостей кэшировал только слои
(или блоб-объекты) образа, но не манифест, который содержит
информацию о том, как собрать данный образ. Так как манифест был
необходим для сборки, всё равно приходилось выполнять pull. А если
Docker Hub был недоступен, вы не могли скачать нужный образ.
Начиная с этого релиза прокси зависимостей будет кэшировать и слои,
и манифест образа. Так что при первом скачивании с использованием
alpine:latest образ будет добавлен в кэш прокси
зависимостей, и это будет считаться за один pull. В следующий раз,
когда вы будете скачивать alpine:latest, всё будет
скачиваться из кэша, даже если Docker Hub недоступен, и это
скачивание не будет учитываться в лимите Docker.
Напоминаем вам, что начиная с 13.6 прокси зависимостей стал
доступен в плане Core. Поэтому попробуйте эту фичу сейчас и
скажите нам, что вы о ней думаете. Или даже лучше, помогите нам с
открытыми тикетами.
Документация по прокси зависимостей и оригинальный тикет.
Быстрый поиск и
просмотр общих пакетов
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Стадия цикла DevOps: Package
Вы можете с лёгкостью публиковать общие файлы, такие как
бинарные файлы релиза, через реестр пакетов GitLab. Однако, если вы
используете пользовательский интерфейс пакетов или другой формат
менеджера пакетов, то возможно вы заметили, что не можете выбрать
вкладку для быстрого просмотра только ваших общих пакетов.
Недавно мы добавили в пользовательский интерфейс пакетов вкладку
Общие пакеты, чтобы вы могли отфильтровать список
пакетов для просмотра только общих пакетов. Мы надеемся, что это
поможет вам находить и проверять ваши пакеты более быстро и
эффективно.
Документация по просмотру пакетов и оригинальный тикет.
Прокси
зависимостей для приватных проектов
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Стадия цикла DevOps: Package
Вы можете использовать прокси зависимостей GitLab для
проксирования и кэширования образов контейнеров из Docker Hub. До
последнего времени эта фича была доступна только для публичных
групп, что не позволяло многим пользователям её использовать.
Теперь вы можете использовать прокси зависимостей и для
приватных проектов. Вы можете снизить свои скачивания с Docker Hub
путём кэширования ваших образов контейнера для использования их в
будущем. Так как прокси зависимостей хранит образы Docker в
пространстве, связанном с вашей группой, вы должны авторизоваться с
вашим логином и паролем GitLab или с личным токеном доступа, для
которого есть разрешение как минимум на чтение
(read_registry).
Документация по прокси зависимостей и оригинальный тикет.
Улучшенная поддержка анализаторов SAST для нескольких проектов
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Стадия цикла DevOps: Secure
В GitLab сканирования безопасности автоматически
определяют язык кода и запускают подходящие анализаторы. В случае
монорепозиториев, микросервисов и репозиториев для нескольких
проектов в одном репозитории GitLab может существовать больше
одного проекта. Ранее наши инструменты безопасности могли
определять язык кода только в одиночных проектах в репозиториях.
Начиная с этого релиза наши анализаторы SAST могут определять языки кода в репозиториях с несколькими
проектами, запускать подходящие сканирования для каждого
проекта и составлять отчёт о уязвимостях. Это делает
управление инструментами безопасности проще и удобнее для
пользователей с одним репозиторием для нескольких проектов. В
следующих релизах мы продолжим улучшать панель
безопасности и отчёты для этих типов проектов.
Документация по поддержке репозиториев для
нескольких проектов и оригинальный эпик.
Описание релиза во
внешнем файле
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Стадия цикла DevOps: Release
Если вы создаёте релизы в конвейерах через файл
.gitlab-ci.yml вашего проекта, вам, возможно, было
сложно поддерживать в актуальном состоянии описание каждого релиза.
В релизе GitLab 13.7 вы можете задавать описание вашего релиза в
файле с контролем версий или в автоматически генерируемом файле и
вызывать его из .gitlab-ci.yml. При этом содержимое
файла загружается в описание релиза в формате Markdown. Это
упрощает создание, поддержку и использование контроля версий для
релизов, а также будет особенно полезно при автогенерации лога
изменений. Огромное спасибо Nejc Habjan и Siemens за этот невероятный вклад!
Документация по описаниям релизов и оригинальный тикет.
Поддержка
для версий Kubernetes 1.17, 1.18 и 1.19
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Стадия цикла DevOps: Configure
Поддержка GitLab для последних версий Kubernetes позволяет вам
пользоваться преимуществами интеграций GitLab с Kubernetes, такими
как GitLab Kubernetes Agent, Auto DevOps и на более поздних
кластерах GitLab Managed Apps. В этом релизе GitLab добавил
официальную поддержку для версий Kubernetes 1.17, 1.18 и 1.19.
Документация по кластерам и оригинальный тикет.
Geo поддерживает
репликацию сниппетов
(PREMIUM, ULTIMATE) Доступность
Geo теперь поддерживает репликацию сниппетов под контролем версий на вторичные
ноды, что позволит распределённым командам получать доступ к ним с
ближайшей ноды Geo, что снижает задержку и делает весь процесс
удобнее. Кроме того, эти данные могут быть восстановлены со
вторичной ноды при переключении на неё в случае сбоя.
В данный момент мы не поддерживаем верификацию для этого типа
данных, но мы планируем добавить её в будущем.
Документация по репликации Geo и оригинальный эпик.
Поддержка
зашифрованных учётных данных LDAP
(CORE, STARTER, PREMIUM, ULTIMATE) Доступность
GitLab использует единый файл конфигурации, например
gitlab.rb в Omnibus GitLab, что упрощает настройку
всех связанных сервисов. В этот файл конфигурации включены
некоторые секретные ключи, например учётные данные для
аутентификации на сервере LDAP. Хотя для доступа к этому файлу
требуются специальные права, хорошей практикой считается отделять
секретные ключи от конфигурации.
Установки Omnibus GitLab и Source теперь поддерживают зашифрованные учётные данные, причём первыми
поддерживаемыми учётными данными стали LDAP. Это снижает уязвимость
конфигурационного файла GitLab, а также помогает достичь
соответствия требованиям заказчика.
Документация по настройке зашифрованных учётных
данных LDAP и оригинальный тикет.
Веб-хуки
при добавлении новых участников группы
(STARTER, PREMIUM, ULTIMATE, BRONZE, SILVER, GOLD) Стадия цикла DevOps: Manage
Теперь в GitLab стало проще автоматизировать управление
пользователями: это можно сделать с помощью веб-хука, который
запускается при добавлении нового участника в группу. Раньше вам
приходилось выполнять запросы REST для идентификации новых членов
группы, что ухудшало производительность вашего инстанса GitLab.
Документация по веб-хукам и оригинальный тикет.
Улучшенная фильтрация и сортировка списков участников группы
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Стадия цикла DevOps: Manage
Мы продолжили улучшать наш список участников группы и добавили
для него новые возможности фильтрации и сортировки. Это поможет
администраторам группы быстро находить нужную им информацию.
Например, сортировку по последнему времени входа (Last sign-in)
можно использовать для поиска пользователей, которые в последнее
время не заходили на GitLab, и для помощи в управлении
лицензиями.

Документация по фильтрации и сортировке участников
группы и оригинальный тикет.
Автоматическая подготовка профиля пользователя с SAML
(SILVER, GOLD) Стадия цикла DevOps: Manage
Раньше в качестве одной из частей включения в группу с SAML
пользователям нужно было заполнять форму регистрации. В GitLab 13.7
мы представляем синхронизацию пользователей для групп с
использованием SAML. Когда пользователь в первый раз входит в
группу с SAML, учётная запись пользователя создаётся для него
автоматически, если нет существующего пользователя с таким же
адресом электронной почты. Автоматическая подготовка с SAML
улучшает процесс адаптации новых пользователей и гарантирует, что
вновь созданные учётные записи содержат правильную информацию.
Документация по настройке групп с SAML и
оригинальный тикет.
Настраиваемый адрес электронной почты для службы поддержки
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Стадия цикла DevOps: Plan
Раньше вашим пользователям было трудно запомнить (а
следовательно, и использовать) адрес электронной почты службы
поддержки GitLab. С введением настраиваемого адреса электронной
почты теперь можно выбрать суффикс адреса, который имеет смысл для
вашей компании и который будет легче запомнить вашим пользователям.
Это ещё один шаг, который нужен для того, чтобы вы могли
предоставлять своим пользователям качественную поддержку.
Документация по настройке адреса электронной почты
для службы поддержки и оригинальный тикет.
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Стадия цикла DevOps: Create
Редактор статических сайтов предлагает интуитивно понятный и
знакомый всем режим редактирования WYSIWYG для контента Markdown.
Чтобы обеспечить единообразный формат вывода Markdown, редактор
WYSIWYG автоматически переформатирует содержимое страницы в
соответствии с соглашениями о стилях, определёнными в парсере
Markdown. Это происходит полностью в фоновом режиме ещё до того,
как вы начнёте редактировать. Однако эти изменения форматирования
коммитятся вместе с вашими изменениями содержимого. Если страница,
которую вы редактируете, не следовала тем же соглашениям о стилях,
для проверяющих итогового мерж-реквеста может быть сложно отличить
ваши изменения от автоматического форматирования.
Начиная с GitLab 13.7 редактор статических сайтов автоматически
исправляет несоответствия в синтаксисе Markdown и коммитит все
необходимые изменения форматирования в новой ветке. По завершении
редактирования кнопка Опубликовать создаёт отдельный коммит,
содержащий только ваши изменения. Это может сэкономить время
проверяющим изменения, которые вместо того, чтобы продираться через
изменения синтаксиса, смогут сосредоточиться на вашем контенте.
В будущем мы планируем сделать параметры форматирования
настраиваемыми, так что следите за новостями в соответствующем тикете.
Документация по редактору статических сайтов и
оригинальный тикет.
Предзаполненные переменные при ручном запуске конвейеров
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Стадия цикла DevOps: Verify
Раньше, когда вы хотели запустить конвейер вручную, вам нужно
было узнать нужные переменные, а затем ввести их на странице Запуск
конвейера (Run Pipeline). Это может быть утомительно и чревато
ошибками, если нужно ввести множество пар ключ-значение. Теперь
форма для запуска конвейера будет сгенерирована для вашего
конвейера с переменными, предварительно заполненными на основе
определений переменных в вашем файле .gitlab-ci.yml,
что сделает этот процесс более эффективным.

Документация по ручному запуску конвейера и
оригинальный тикет.
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Стадия цикла DevOps: Package
Если вы публиковали пакеты в реестре пакетов, то могли заметить,
что пакеты, созданные с помощью GitLab CI/CD, не всегда отображали
коммит и конвейер, ответственные за создание или обновление вашего
пакета. Это могло происходить по нескольким причинам.
Во-первых, возможно, мы ещё не поддерживали эту функцию, как в
случае с Composer и Conan. Во-вторых, проблема возникала у тех из
вас, кто обновлял одну и ту же версию пакета из разных веток или
коммитов. Однако до недавнего времени пользовательский интерфейс
отображал только первое развёртывание без каких-либо обновлений.
Кроме того, на странице подробных сведений отображается ветка, в
которой был создан пакет, а не самый последний коммит. В результате
вам приходилось искать эту информацию, просматривая историю
коммитов, что было не очень эффективно.
В дальнейшем любой пакет, собранный или обновлённый с помощью
GitLab CI/CD, будет отображать информацию о коммите и конвейере в
пользовательском интерфейсе пакетов. Чтобы избежать проблем с
производительностью или пользовательским интерфейсом, будут
отображаться только пять обновлений пакета. В майлстоуне 13.8 мы
создадим дизайн, который поможет вам легко просматривать все
данные, включая историю. А пока вы можете использовать API пакетов, чтобы смотреть всю историю сборки
данного пакета.

Документация по реестру пакетов и сборке пакетов с
помощью GitLab CI/CD и оригинальный тикет.
Используйте предопределённые переменные с прокси зависимостей
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Стадия цикла DevOps: Package
С помощью проксирования и кэширования образов контейнеров из
Docker Hub прокси зависимостей помогает вам повысить
производительность ваших конвейеров. Несмотря на то, что
прокси-сервер предназначен для интенсивного использования с CI/CD,
для использования этой фичи вам нужно было определить свои
собственные переменные или прописать значения в вашем файле
gitlab.ci-yml. Это затрудняло начало работы для тех,
кто работает один, и не позволяло использовать его в качестве
масштабируемого решения, особенно для организаций с множеством
различных групп и проектов.
В дальнейшем вы можете использовать предопределённые переменные окружения в качестве
интуитивно понятного способа для прокси зависимостей.
Поддерживаются следующие переменные:
CI_DEPENDENCY_PROXY_USER: пользователь CI для
входа в прокси зависимостей,CI_DEPENDENCY_PROXY_PASSWORD: пароль для входа в
прокси зависимостей,CI_DEPENDENCY_PROXY_SERVER: сервер для входа в
прокси зависимостей,CI_DEPENDENCY_PROXY_GROUP_IMAGE_PREFIX: префикс
образа для извлечения образов через прокси зависимостей.
Попробуйте и дайте нам знать, что вы думаете!
Документация по аутентификации в прокси зависимостей
с помощью CI/CD и оригинальный тикет.
Результаты сканирований безопасности в виджете мерж-реквеста стали
удобнее
(CORE, STARTER, PREMIUM, FREE, BRONZE, SILVER) Стадия цикла DevOps: Secure
С помощью SAST и поиска секретных ключей, которые теперь
доступны для всех пользователей, мы упростили жизнь всем
пользователям GitLab, взаимодействующим с результатами сканирования
безопасности в мерж-реквесте, за счёт облегчения доступа к
результатам сканирования безопасности. Ранее
результаты сканирования безопасности были доступны только на
странице Обзор конвейера, и вы должны были знать, где
искать, чтобы найти их там. Теперь все мерж-реквесты будут
показывать, были ли для них запущены проверки безопасности, и
помогут вам найти артефакты задания. Это изменение не затрагивает работу с мерж-реквестами для
пользователей плана Ultimate.

Документация по просмотру результатов сканирования
безопасности в мерж-реквесте и оригинальный эпик.
Специальные ссылки на
уязвимости
(ULTIMATE, GOLD) Стадия цикла DevOps: Secure
Мы ввели уязвимости как полноценные объекты в 12.10. Будучи
объектом, каждая из них имеет уникальный URL-адрес, позволяющий
напрямую перейти к деталям любой уязвимости. Несмотря на
значительное улучшение видимости и согласованности, ссылки на
уязвимости в тикетах и эпиках (в русской локализации GitLab цели)
всё равно нужно копировать вручную в виде ссылок Markdown. Это
делает неэффективным совместное использование, а ссылки на
уязвимости в других областях GitLab более громоздкими, чем для
других объектов, например тикетов.
Теперь на уязвимости можно ссылаться с помощью специальных
ссылок. На них впервые будет опробован новый синтаксис
[object_type:ID], который в конечном итоге
распространится на другие существующие ссылки. Теперь вы можете
быстро вставить ссылку на уязвимость из любого места, где обычно
используется специальная ссылка, например из описания тикета или
мерж-реквеста. Просто введите [vulnerability:123] в
описании тикета, чтобы вставить ссылку на уязвимость с
идентификатором 123 в том же проекте. Вы также можете добавить к
идентификатору префикс пространства имён или проекта, чтобы
ссылаться на уязвимости вне контекста текущего проекта.
Документация по специальным ссылкам и оригинальный тикет.
Смотрите, какие коммиты и конвейеры выполняются в форке, а какие в
родительском проекте
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Стадия цикла DevOps: Release
После того, как мы решили проблему, описанную в тикете 217451 в GitLab 13.3, вы получили
возможность разрешать разработчикам родительского проекта создавать
конвейеры для мерж-реквестов в форках. Однако не было никакого
способа узнать контекст, в котором был запущен конвейер.
В этом релизе вы сможете увидеть, какие коммиты и конвейеры
выполнялись в проекте-форке, а какие в родительском проекте.
Коммиты в форках отмечены уникальным значком и тултипом, что
позволяет вам узнать, что они выполнялись из мерж-реквеста в форке.
Это упрощает понимание контекста, в котором работал ваш конвейер, и
устраняет необходимость более детально изучать источник.

Документация по запуску конвейеров в родительском
проекте для мерж-реквестов из проекта-форка и оригинальный тикет.
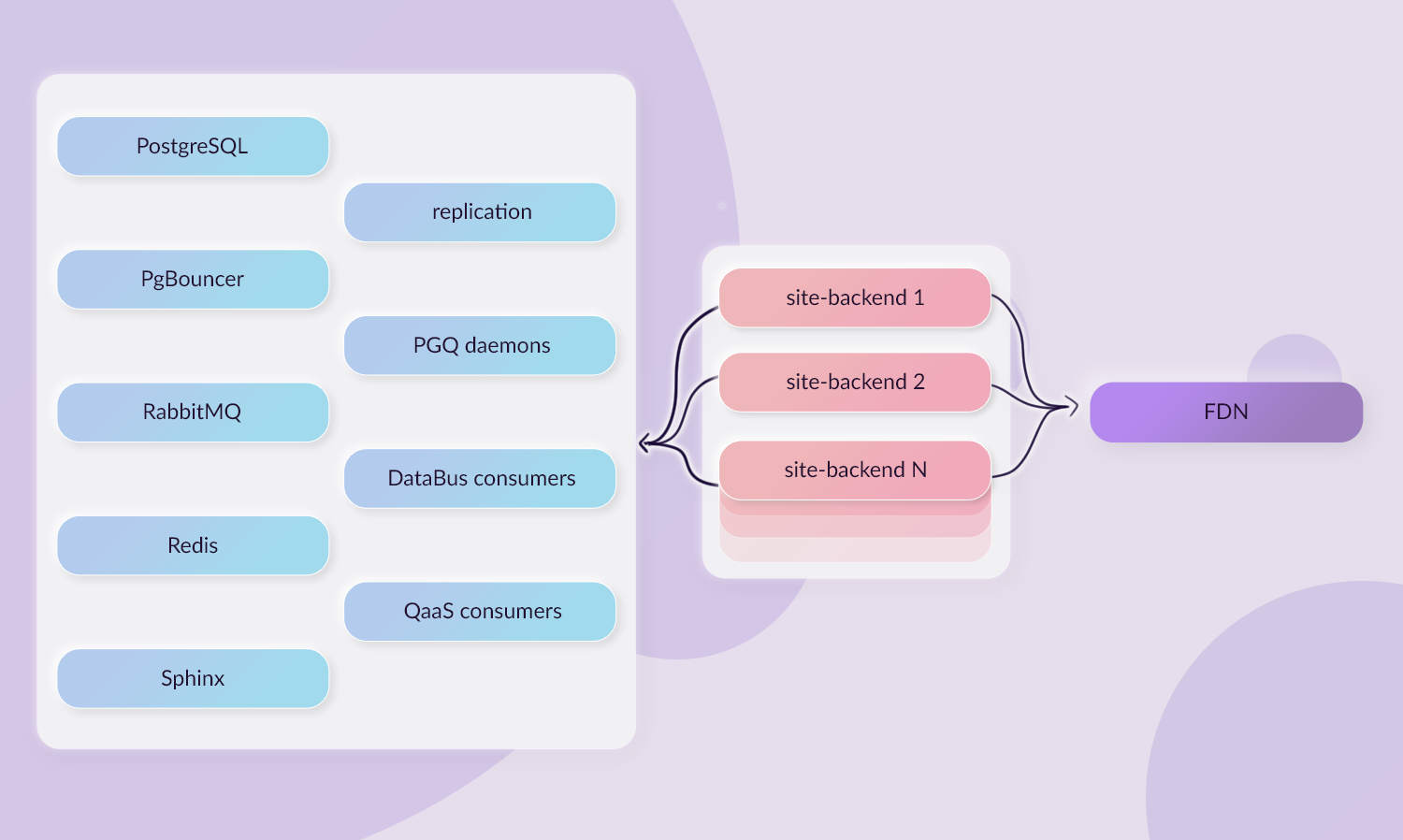
Запросы к базе данных выполняются быстрее при использовании
балансировщика нагрузки
(CORE, STARTER, PREMIUM, ULTIMATE, FREE, BRONZE, SILVER, GOLD)
Доступность
Многие запросы к базе данных повторяются несколько раз, так что
их можно кэшировать для повышения общей производительности. Для
GitLab можно кэшировать примерно 10% всех запросов. В GitLab 13.7 мы
включили кэширование запросов к базе данных, когда используется
балансировка нагрузки базы данных. На GitLab.com
это приводит к кэшированию ~700 000 запросов каждую минуту и
сокращает среднее время выполнения запросов вплоть до 10%.
Для запросов, которые выполняются более 100 раз, мы уменьшили
продолжительность запроса на 11-31% и кэшировали ~30% всех операторов
SELECT, которые бы в противном случае выполнялись на реплике
базы данных.
Документация по балансировке нагрузки на базу
данных и оригинальный тикет.
Для новых установок по умолчанию используется PostgreSQL 12
(CORE, STARTER, PREMIUM, ULTIMATE) Доступность
Начиная с GitLab 13.3 PostgreSQL 12 был доступен в
качестве опции как для пакетов Omnibus, так и для нашего Helm
chart. PostgreSQL 12 улучшает производительность, а также
предлагает значительные преимущества при индексировании и
секционировании.
Начиная с GitLab 13.7 новые установки GitLab будут по умолчанию
использовать PostgreSQL 12. Чтобы выполнить обновление вручную,
запустите gitlab-ctl pg-upgrade.
Многонодовые инстансы базы данных должны будут переключиться с
repmgr на Patroni до обновления с помощью Patroni. Затем можно
обновить и повторно синхронизировать вторичные
ноды Geo.
Документация по настройкам баз данных в GitLab 13.3
и более поздних версиях и оригинальный тикет.
Полный текст релиза и инструкции по обновлению/установке вы
можете найти в оригинальном англоязычном посте: GitLab 13.7 released with merge request reviewers
and automatic rollback upon failure.
Над переводом с английского работали cattidourden, maryartkey,
ainoneko и rishavant.


 Рыночная капитализация криптовалюты
подскочила со 190 млрд до 2 трлн за один год.
Рыночная капитализация криптовалюты
подскочила со 190 млрд до 2 трлн за один год.





















































































































 Даже не зовите меня, если ваш pipeline
не похож на это.
Даже не зовите меня, если ваш pipeline
не похож на это.
 Мне нужны твои уязвимости, сапоги и мотоцикл
Мне нужны твои уязвимости, сапоги и мотоцикл
 Да-да, прямо как Испанская Инквизиция!
Да-да, прямо как Испанская Инквизиция!
 Деплоим контейнер в прод, как можем.
Деплоим контейнер в прод, как можем.














































