50 лет истории видеокарт (1970-2020): Полная история видеокарт
и их прародителей
Часть 1
Компьютерная графика. Услышав эти слова, мы представляем поражающие
воображение спецэффекты из крупных блокбастеров, красивейшие модели
персонажей из ААА-игр, и всё, что связано с визуальной красотой
современных технологий. Но компьютерная графика, как и любой
технологический аспект, развивалась не одно десятилетие, преодолев
путь от отображения нескольких символов на монохромном дисплее до
поражающих воображение пейзажей и героев, с каждым годом всё
сложнее отличимых от реальности. Сегодня мы начнем рассказ о том,
как начиналась история компьютерной графики, вспомним, как появился
термин видеокарта и сокращение GPU, и какие технические рубежи год
за годом преодолевали лидеры рынка, в стремлении покорения новой
аудитории.

Предисловие эпохи. Зарождение компьютеров (1940-е/1950-е)
Эпоха компьютерных технологий у многих вызывает ассоциации с
началом эпохи персональных компьютеров в начале 80-х, но на самом
деле первые компьютеры появились гораздо раньше. Первые разработки
таких машин начались еще до Второй Мировой войны, а прототипы,
отдаленно напоминающие будущие ПК, увидели свет уже в 1947 году.
Первым таким устройством стал IBM 610 экспериментальный компьютер,
разработанный Джоном Ленцем из Уотсоновской лаборатории при
Колумбийском университете. Он первым в истории получил гордое
название Персонального автоматического компьютера (Personal
Automatic Computer, PAC), хотя оно и было слегка преувеличенным
машина стоила $55 тысяч, и было изготовлено всего 150
экземпляров.
Первые впечатляющие визуальные
системы появлялись в те же годы. Уже в 1951 году IBM при участии
General Electric и ряда военных подрядчиков разработала летный
симулятор для нужд армии. В нем использовалась технология
трехмерной виртуализации пилот, находившийся за тренажером, видел
проекцию кабины и мог действовать так, как это происходило бы за
штурвалом настоящего самолета. Позже графический прототип
использовала компания Evans & Sutherland, создавшая полноценный
тренажер для пилотов CT5, работающий на базе массива компьютеров
DEC PDP-11. Только задумайтесь на дворе всё еще 50-е, а у нас уже
тогда была трехмерная графика!
1971-1972. Magnavox Odyssey и PONG
Бум полупроводниковых технологий и производства микросхем полностью
поменял расклад сил на рынке, прежде принадлежавшем громоздким
аналоговым компьютерам, занимавшим целые залы. Отказавшись от
вакуумных ламп и перфокарт, индустрия шагнула в эпоху развлечений
для всей семьи, познакомив западный мир с домашними игровыми
видеосистемами, прабабушками современных консолей.
Первопроходцем видеоигровых развлечений стало устройство под
названием Odyssey Magnavox, первая официально выпущенная игровая
система. У Одиссеи были диковинные по современным стандартам
контроллеры, а вся графическая система выводила на экран телевизора
только линию и две точки, которыми управляли игроки. Создатели
устройства подошли к делу с фантазией, и в комплекте с консолью шли
специальные цветные накладки на экран, способные раскрасить игровые
миры нескольких проектов, идущих в комплекте с Odyssey. Всего для
устройства было выпущено 28 игр, среди которых был простой на
первый взгляд пинг-понг, вдохновивший энтузиастов из молодой
компании Atari на выпуск игрового автомата Pong с идентичной игрой.
Именно Pong стал началом магии игровых автоматов, которая, к слову,
полностью захватила и Японию и западный мир к началу 80-х.
Несмотря на очевидную простоту, Magnavox Odyssey использовал
настоящие картриджи правда, во многом лишь для эффекта. Никаких
чипов памяти в них не было картриджи служили набором перемычек,
волшебными образом превращающих одно расположение линии с точками в
другое, тем самым меняя игру. До полноценного видеочипа примитивной
приставке было далеко, но популярность Magnavox Odyssey показала
однозначный интерес публики, и многие компании взялись за
разработку своих собственных устройств, чувствуя потенциальную
прибыль.
1976-1977. Fairchild Channel F и Atari 2600
Ждать первой серьезной схватки за новорожденный игровой рынок
пришлось недолго. В 1975 году стремительно устаревающая Magnavox
Odyssey исчезла с прилавков, а на её место за титул лучшей консоли
нового поколения бились сразу два устройства Channel F от компании
Fairchild и Atari VCS от той самой компании, что подарила миру
Pong.

Несмотря на то, что разработка консолей шла практически
одновременно, Atari не успевала и Fairchild первой выпустила своё
устройство под названием Fairchild Video Entertainment System
(VES).
Консоль от Fairchild появилась на полках магазинов в ноябре 1976
года, и стала настоящей кладезю технических преимуществ. Вместо
невнятных контроллеров Odyssey появились удобные, бутафорские
картриджи сменились на настоящие (внутри которых стояли ROM-чипы с
данными игр), а внутри консоли был установлен динамик,
воспроизводящий звуки и музыку из запущенной игры. Приставка умела
отрисовывать изображение с использованием 8-цветовой палитры (в
режиме черно-белой строки либо цветной) в разрешении 102х54
пикселя. Отдельно стоит заметить, что процессор Fairchild F8,
установленный в системе VES, был разработан Робертом Нойсом,
который в 1968 году основал небольшую, но перспективную фирму
Intel.
Atari была на грани отчаяния проект Stella, основа будущей консоли,
сильно отставал по темпам разработки, а рынок, как известно, ждать
не будет. Множество вещей, казавшихся инновационными с выходом
Fairchild VES, вот-вот должны были стать неотъемлемой чертой всех
будущих консолей. Понимая, что на кон нужно ставить всё, основатель
компании Atari Нолан Бушнелл подписывает соглашение с Warner
Communications, продавая своё детище за $28 миллионов с условием,
что консоль Atari выйдет на рынок в кратчайшие сроки.
Warner не подвели, и работа над приставкой закипела с новой силой.
Для упрощения логики и удешевления производства к разработке
привлекли знаменитого инженера Джея Майнера, который переработал
чипы видеовывода и обработки звука TIA (Television Interface
Adaptor) в единый элемент, что и стало последним штрихом перед
готовностью консоли. Чтобы позлить Fairchild, маркетологи Atari
назвали консоль VCS (Video Computer System), вынудив конкурента
переименоваться в Channel F.
Но это не слишком помогло Channel F успешно конкурировать с
новинкой хотя на этапе релиза консоли в 1977 году было готово всего
9 игр, разработчики достаточно быстро осознали наступление новой
технологической эры, и принялись использовать мощности приставки на
полную. Atari VSC (позже ставшая Atari 2600), была первой
приставкой, в основе которой лежал комплексный чип, не только
обрабатывающий видео и звуковую дорожку, но и команды, получаемые с
джойстика. Скромные продажи, поначалу смутившие Warner, сменились
феноменальным успехом после решения лицензировать аркаду Space
Invaders авторства японской компании Taito. Картриджи, поначалу
ограниченные 4 Кб памяти, со временем доросли до 32 Кб, а число игр
исчислялось сотнями.
Секрет успеха Atari крылся в максимально упрощенной логике
устройства, возможности разработчиков гибко программировать игры с
использованием ресурсов 2600 (например, иметь возможности менять
цвет спрайта во время отрисовки), а также внешняя притягательность
и удобные контроллеры, названные джойстиками (от буквального
joystick палка счастья). Поэтому, если вы не знали, откуда
пришел этот термин, можете поблагодарить за него разработчиков
Atari. Как и за главный образ всего ретро-гейминга забавного
пришельца из Space Invaders.
После того, как успех Atari 2600 вышел за рамки всех прогнозируемых
величин, Fairchild покинула рынок видеоигр, решив, что направление
скоро сойдет на нет. О подобном решении, скорее всего, в компании
жалеют до сих пор.
1981-1986. Эпоха IBM PC.
Несмотря на то, что уже в 1979 году компания Apple представила
Apple II, навсегда изменивший образ доступного компьютера, понятие
персональный компьютер появилось немногим позже, и принадлежало
совсем иной компании. Монументальная IBM, за плечами которой были
десятилетия работы с громоздкими мейнфреймами (с шумом бобин и
мерцающими лампочками), неожиданно сделала шаг в сторону и создала
рынок, которого прежде не существовало.
В 1981 году в продаже появился легендарный IBM PC, появление
которого предваряла одна из лучших рекламных кампаний в истории
маркетинга. Никого еще не увольняли за покупку IBM гласил тот самый
слоган, навсегда вошедший в историю рекламы.
Однако не только слоганы и яркие рекламные вклейки сделали имя
персональному компьютеру IBM. Именно для него впервые в истории
была разработана сложная графическая система из двух видеоадаптеров
Монохромного адаптера дисплея (MDA, Monochrome Display Adapter) и
Цветного графического адаптера (CGA, Color Graphics Adapter).
MDA предназначался для набора текста с поддержкой 80 колонок и 25
строк на экране для набора ASCII символов при разрешении 80х20
пикселей. Адаптер использовал 4 Кб видеопамяти, и отображал зеленый
текст на черном экране. В таком режиме было легко и удобно работать
с командами, документами и другими повседневными задачами
бизнес-сектора.
CGA, напротив, можно было назвать прорывным с точки зрения
графических возможностей. Адаптер поддерживал 4-битную палитру в
разрешении в разрешении 640х200 пикселей, располагал 16 Кб памяти,
и лег в основу стандарта компьютерной графики для активно
расширяющейся линейки компьютеров IBM PC.
Впрочем, у использования двух разных адаптеров видеовывода были
серьезные недостатки. Масса возможных технических проблем,
дороговизна устройств и ряд других ограничений подтолкнули
энтузиастов к работе над универсальным решением графическим
адаптером, способным работать в двух режимах одновременно. Первым
таким продуктом на рынке стала Hercules Graphics Card (HGC),
разработанная одноименной компанией Hercules в 1984 году.
 Hercules Graphics Card (HGC)
Hercules Graphics Card (HGC)
По легенде основатель компании Hercules Ван Сиваннукул (Van
Suwannukul) разработал систему специально для работы над своей
докторской диссертацией на родном тайском языке. Стандартный
MDA-адаптер IBM не отображал тайский шрифт корректно, что и
побудило разработчика приступить к созданию HGC в 1982 году.
Поддержка разрешения 720х348 точек как для текста, так и для
графики, а также возможность работы в режимах MDA и CGA, обеспечило
адаптеру Hercules долгую жизнь. Наследие компании в виде
универсальных стандартов видеовывода HGC и HGC+ использовалось
разработчиками IBM-совместимых компьютеров, а позже и ряда других
систем вплоть до конца 90-х. Однако мир не стоял на месте, и бурное
развитие компьютерной отрасли (как и её графической части)
привлекло множество других энтузиастов среди них были четверо
мигрантов из Гонконга Хво Юн Хо (Kwak Yuan Ho), Ли Лау (Lee Lau),
Френсис Лау (Francis Lau) и Бенни Лау (Benny Lau), основавшие Array
Technology Inc, компанию, которую весь мир узнает как ATI
Technologies Inc.
1986-1991. Первый бум рынка графических карт. Ранние успехи
ATI
После выпуска IBM PC компания IBM недолго оставалась в авангарде
развития компьютерных технологий. Уже в 1984 году Стив Джобс
представил первый Macintosh с впечатляющим графическим интерфейсом,
и для многих стало очевидно, что графические технологии вот-вот
сделают настоящий скачок вперед. Но, несмотря на потерю лидерства в
отрасли, IBM выгодно отличалась от Apple и других
компаний-конкурентов своим видением направления. Философия открытых
стандартов, которой придерживалась IBM, открыла двери производству
любых совместимых устройств, что и привлекло в сферу многочисленные
стартапы своего времени.
В их числе была и молодая компания ATI Technologies. В 1986 году
гонконгские специалисты представили свой первый коммерческий
продукт OEM Color Emulation Card.
 Color Emulation Card
Color Emulation Card
Расширив возможности стандартных монохромных контроллеров, инженеры
ATI обеспечили вывод трех цветов шрифта на черном экране зеленого,
янтарного и белого. Адаптер располагал 16 Кб памяти и
зарекомендовал себя в составе компьютеров Commodore. За первый год
продаж изделие принесло ATI более $10 миллионов.
Конечно же, это стало лишь первым шагом для ATI следом за
расширенным графическим решением с 64 Кб видеопамяти и возможностью
работы в трех режимах (MDA, CGA, EGA) на рынок вышла линейка ATI
Wonder, с появлением которой прежние стандарты можно было
записывать в архаизмы.
Звучит слишком смело? Судите сами адаптеры серии Wonder получили
буфер в 256 Кб видеопамяти (в 4 раза больше!), а вместо
четырехцветной палитры на экран выводилось 16 цветов при разрешении
640х350. При этом никаких ограничений при работе с различными
форматами вывода не было ATI Wonder успешно эмулировала любой из
ранних режимов (MDA, CGA, EGA), а, начиная со 2-ой серии, получила
поддержку новейшего стандарта Extend EGA.
 ATi Wonder
ATi Wonder
Кульминацией развития линейки в 1987 году стала знаменитая ATI EGA
Wonder 800, выводившая 16-цветовую палитру уже VGA-формата в
невероятно высоком разрешении 800х600. Адаптер продавался в формате
более доступной VGA Improved Performance Card (VIP) с ограниченной
поддержкой VGA-вывода.
Первый расцвет рынка видеокарт. Инновации ATI, начало конкурентной
борьбы
Значительные успехи ATI в развитии коммерческих графических
адаптеров привлекли внимание множества других компаний в период с
1986 по 1987 год были основаны и представили первые продукты на
рынке адаптеров такие бренды, как Trident, SiS, Tamarack, Realtek,
Oak Technology, LSI (G-2 Inc), Hualon, Cornerstone Imaging и
Windbond. Помимо новых лиц в выходе на графический рынок
заинтересовались и действующие представители Кремниевой долины
такие компании, как AMD, Western Digital/Paradise Systems,
Intergraph, Cirrus Logic, Texas Instruments, Gemini и Genoa каждая
из них так или иначе представила первый графический продукт в том
же промежутке времени.
В 1987 году ATI выходит на OEM-рынок уже в качестве
компании-поставщика, выпуская серию продуктов Graphics Solution
Plus. Эта линейка была рассчитана на работу с 8-битной шиной
компьютеров IBM PC/XT на базе платформы Intel 8086/8088. Адаптеры
GSP тоже поддерживали форматы вывода MDA, CGA и EGA, но с
оригинальным переключением между ними на самой плате. Устройство
прекрасно приняли на рынке, и даже схожая модель от Paradise
Systems с 256 Кб видеопамяти (у GSP было всего 64 Кб) не помешала
Ati пополнить портфолио новым успешным продуктом.
Все следующие годы канадская компания ATI Technologies Inc.
оставалась на пике графических инноваций, постоянно опережая
конкурентов. Хорошо известная тогда линейка адаптеров Wonder первой
на рынке перешла на 16-битный цвет; получила поддержку EVGA (в
адаптерах Wonder 480 и Wonder 800+) и SVGA (в Wonder 16). В 1989
году ATI снизила цены на линейку Wonder 16 и добавила разъем VESA
для возможности соединять друг с другом два адаптера можно сказать
это были первые фантазии на тему связок из нескольких устройств,
которые появятся на рынке гораздо позже.
Из-за разрастания рынка с бесчисленным числом форматов и
производителей требовалась специальная организация, способная
урегулировать их и разработать ключевые стандарты для игроков
рынка. В 1988 году усилиями шести ключевых производителей была
основана VESA (Video Electronics Standard Association, Ассоциация
стандартов видеоэлектроники), взявшая на себя централизацию
стандартов и форматов разрешений, а также цветовой палитры
графических адаптеров. Первым форматом стал SVGA (800х600 точек),
который уже использовался в картах Ati Wonder 800. В дальнейшем их
становилось больше, а некоторые (включая HGC и HGC+) использовались
на протяжении десятилетий.

Технологическое лидерство ATi укрепляла и на заре 90-х. В 1991 году
в продажу вышла Wonder XL первый графический адаптер с поддержкой
32 тысяч цветов и поддержкой разрешения 800х600 при частоте
обновления в 60 Гц. Подобного удалось добиться благодаря
использованию конвертера Sierra RAMDAC. Помимо этого, Wonder XL
стала первым адаптером с 1 Мб видеопамяти на борту.
В мае того же года ATI представила Mach8 первый продукт из новой
линейки Mach для работы с обработкой простых 2D-операций например,
отрисовки линий, заполнения цветом и битмаппинга. Mach8 был
доступен для приобретения как в виде чипа (для последующей
интеграции например, в бизнес-системы OEM-формата), так и в виде
полноценной платы. Сейчас многим покажется странным выпуск
отдельного адаптера для таких вещей, но 30 лет назад многие
специальные вычисления всё еще лежали на плечах центрального
процессора, тогда как графические адаптеры предназначалась для
узкого круга задач.
Впрочем, такой уклад вещей сохранялся недолго следом за интересной
VGA Stereo F/X, симбиозом графического адаптера и платы Sound
Blaster для эмуляции кодека в формате моно налету, лидер индустрии
представил продукт для работы как с двухмерной, так и с трехмерной
графикой VGA Wonder GT. Объединив возможности Mach8 и Wonder Ati
смогли первыми решить проблему необходимости дополнительного
адаптера для работы с разными типами задач. Значительному успеху
новинок поспособствовал выход популярной ОС Windows 3.0, в которой
впервые ставили акценты на широкий круг задач в работе с
2D-графикой. Wonder GT пользовалась спросом и у системных
интеграторов, что благотворно сказалось на прибылях компании в 1991
году оборот ATI превысил $100 млн. Будущее обещало быть светлым, но
конкуренция на рынке никогда не ослабевала лидеров ожидали новые
испытания.
1992-1995. Разработка OpenGL. Второй бум рынка графических карт.
Новые рубежи в 2D и 3D
В январе 1992 года, компания Silicon Graphics Inc представила
первый мультиплатформенный программный интерфейс OpenGL 1.0,
поддерживающий работу как с 2D, так и с 3D-графикой.

В основу будущего открытого стандарта легла проприетарная
библиотека IRIS GL (Integrated Raster Imaging System Graphical
Library, Интегрированная системная библиотека обработки растровой
графики). Понимая, что в скором времени множество компаний
представят на рынке свои библиотеки подобного рода, в SGI приняли
решение сделать OpenGL открытым стандартом, совместимым с любыми
платформами на рынке. Популярность такого подхода было трудно
переоценить на OpenGL обратил внимание весь рынок.
Изначально Silicon Graphics нацеливалась на профессиональный рынок
UNIX-систем, планируя определённые задачи для будущей открытой
библиотеки, но благодаря доступности для разработчиков и
энтузиастов OpenGL быстро занял место на развивающемся рынке
трехмерных игр.
Однако не все крупные игроки рынка приветствовали такой подход SGI.
Примерно в то же время компания Microsoft разрабатывала собственную
программную библиотеку Direct3D, и совсем не спешила интегрировать
поддержку OpenGL в операционную систему Windows.

Direct3D открыто раскритиковал и знаменитый автор Doom Джон Кармак,
собственноручно портировавший Quake на OpenGL для Windows,
подчеркнув преимущества простого и понятного кода открытой
библиотеки на фоне сложного и мусорного варианта Microsoft.
 Джон Кармак
Джон Кармак
Но позиция Microsoft осталась неизменной, и после выхода Windows 95
компания отказалась лицензировать MCD-драйвер OpenGL, благодаря
которому пользователь мог самостоятельно решить, через какую
библиотеку запускать приложение или новую игру. В SGI нашли
лазейку, выпустив драйвер в формате установщика (ICD, Installable
Client Driver), который помимо растеризации OpenGL получил
поддержку обработки эффектов освещения.
Ударный рост популярности OpenGL привел к тому, что решение SGI
стало популярным и в сегменте рабочих станций, что вынудило
Microsoft выделить все возможные ресурсы на создание своей
проприетарной библиотеки в кратчайшие сроки. Основу для будущего
API предоставила купленная в феврале 1995 года студия
RenderMorphics, чья программная библиотека Reality Lab и
сформировала основные принципы работы Direct3D.
Второе рождение рынка видеокарт. Волна слияний и
поглощений
Но вернемся немного в прошлое. В 1993 году рынок видеокарт
переживал второе рождение, и в поле зрения публики попало множество
новых перспективных компаний. Одной из них стала NVidia, основанная
Дженсеном Хуангом, Кёртисом Прэмом и Крисом Малаховски в январе
1993 года. Хуанг, успевший поработать программным инженером в LSI,
давно вынашивал идею создания компании по производству графических
адаптеров, а его коллеги из Sun Microsystems как раз успели
поработать над графической архитектурой GX. Объединив усилия и
собрав 40 тысяч долларов, трое энтузиастов дали начало компании,
которой было суждено сыграть ключевую роль в индустрии.
 Дженсен Хуанг
Дженсен Хуанг
Впрочем, в те годы заглядывать в будущее никто не решался рынок
стремительно менялся, новые проприетарные API и технологии
появлялись чуть ли не каждый месяц, и было очевидно, что в бурном
круговороте конкуренции выживут далеко не все. Многие из компаний,
вступивших в гонку графических вооружений к концу 80-х, были
вынуждены объявить о банкростве среди них оказались Tamerack,
Gemini Technology, Genoa Systems и Hualon, тогда как Headland
Technology была выкуплена SPEA, а Acer, Motorola и Acumos стали
собственностью Cirrus Logic.
Как вы уже могли догадаться, особняком в этом скоплении слияний и
приобретений стояла ATI. Канадцы продолжали усердно трудиться и
выпускать инновационные продукты, несмотря ни на что пусть это и
стало значительно сложнее.
В ноябре 1993 года ATI представила карту видеозахвата VideoIt! в
основе которой лежал чип-декодер 68890, способный записывать
видеосигнал в разрешении 320х240 при 15 кадрах в секунду или
160х120 при 30 кадрах в секунду. Благодаря интеграции чипа Intel
i750Pd VCP владелец новинки мог проводить компрессию-декомпрессию
видеосигнала в реальном времени, что было особенно полезно при
работе с большими объемами данных. VideoIt! первую на рынке научили
использовать центральную шину для общения с графическим
ускорителем, и никаких кабелей и коннекторов, как прежде, уже не
требовалось.
Проблемы ATI и успехи S3 Graphics
Для ATI 1994 год стал настоящим испытанием из-за серьезной
конкуренции компания понесла убытки в размере $4,7 миллиона.
Главной причиной неприятностей канадских разработчиков стали успехи
компании S3 Graphics. Графический ускоритель S3 Vision 968 и
адаптер Trio64 обеспечили американской компании-разработчику дюжину
крупных ОЕМ-контрактов с такими лидерами рынка, как Dell, HP и
Compaq. В чем была причина такой популярности? Невиданный ранее
уровень унификации графический чип Trio64 собрал под одной крышкой
цифро-аналоговый преобразователь (DAC), синтезатор частот и
графический контроллер. Новинка от S3 использовала объединенный
кадровый буфер и поддерживала аппаратное наложение видео
(реализованное путем выделения части видеопамяти в процессе
рендеринга). Масса достоинств и отсутствие явных недостатков чипа
Trio64 и его 32-битного собрата Trio32 привели к появлению
множества вариантов партнерских исполнений плат на их основе. Свои
решения предлагали Diamond, ELSA, Sparkle, STB, Orchid, Hercules и
Number Nine. Вариации разнились от базовых адаптеров на базе VirGe
за $169, до сверхмощной Diamond Stealth64 с 4 Мб видеопамяти за
$569.
В марте 1995 года ATI вернулась в большую игру с набором инноваций,
представив Mach64 первый на рынке 64-битный графический ускоритель,
а также первый, способный работать в системах на базе PC и Mac.
Наряду с популярной Trio 958 Mach64 обеспечивал возможность
аппаратного ускорения видео. Mach64 открыл для ATI выход на
профессиональный рынок первыми решениями канадцев в данном секторе
стали ускорители 3D Pro Turbo и 3DProTurbo+PC2TV. Новинки
предлагались по цене в $899 за целых 4 Мб видеопамяти.
Еще одним важным новичком на рынке графических ускорителей стал
технологический стартап 3Dlabs. Приоритетным направлением для
молодой компании был выпуск высококлассных графических ускорителей
для профессионального рынка Fujitsu Sapphire2SX с 4 Мб видеопамяти
предлагалась по цене от $1600, а ELSA Gloria 8 с 8 Мб памяти на
борту стоила немыслимые для тех лет $2600. Пытались 3Dlabs выйти и
на рынок массовой игровой графики с Gaming Glint 300SX, но высокая
цена и всего 1 Мб видеопамяти не принес популярности адаптеру.
Свои продукты на потребительском рынке представляли и другие
компании. Trident, ОEM-поставщик графических решений для 2D-задач,
представил чип 9280, обладавший всеми преимуществами Trio64 по
доступной цене от $170 до $200. Тогда же в продажу вышли Weiteks
Power Player 9130 и Alliance Semiconductors ProMotion 6410
обеспечившие прекрасную плавность при воспроизведении видео.
NV1 Дебют NVidia и проблемные полигоны
В мае 1995 года к новичкам присоединилась и NVIDIA, представив свой
первый графический ускоритель с символическим названием NV1.
Продукт первым на коммерческом рынке объединил возможности
3D-рендеринга, аппаратного ускорения видео и графического
интерфейса. Сдержанный коммерческий успех никак не смутил молодую
компанию Дженсен Хуанг с коллегами прекрасно понимали, что на
рынке, где новые решения представляют каждый месяц, выстрелить
будет очень непросто. Но прибыли с продажи NV1 оказалось
достаточно, чтобы удержать компанию на плаву и дать стимул
продолжать работу.
 Diamond EDGE 3D 2120 (NV1)
Diamond EDGE 3D 2120 (NV1)
Производством чипов на базе 500 нм техпроцесса заведовала компания
ST Microelectronics, но к несчастью для Nvidia всего через
несколько месяцев после появления на рынке партнерских решений на
основе NV1 (например, Diamond Edge 3D) Microsoft представила первую
версию долгожданного графического API DirectX 1.0. Наконец-то!
воскликнули геймеры со всего мира, но производители графических
ускорителей такого энтузиазма не разделяли.
Главной особенностью работы DirectX стали полигоны треугольной
формы. Многие ошибочно полагают, что пресловутые треугольники были
всегда, но на самом деле это заблуждение. Инженеры Nvidia
закладывали в свой первый продукт квадратичный маппинг текстур
(вместо треугольников-полигонов были квадраты), из-за чего
приложения и первые игры с поддержкой DirectX вызвали массу проблем
совместимости у владельцев NV1. Для решения проблемы Nvidia
включили в драйвер обработчик для перевода квадратной разметки
текстур в треугольную, но производительность в таком формате
оставляла желать лучшего.
Большинство игр c поддержкой квадратичного маппинга текстур были
портированы с приставки Sega Saturn. В Nvidia сочли эти проекты
настолько важными, что разместили на 4 Мб модели NV1 два порта
новой консоли, подключенные к карте через ленточные разъемы. На
момент выхода в продажу (в сентябре 1995 года) первый продукт
Nvidia обошелся покупателям в $450.
Большинство производителей графических ускорителей к моменту
запуска API от Microsoft сильно зависели от проприентарных решений
других компаний когда разработчики компании Билла Гейтса только
начинали работу над собственной графической библиотекой, на рынке
уже присутствовало множество API, таких как S3d (S3), Matrox Simple
Interface, Creative Graphics Library, C Interface (ATI) и SGL
(PowerVR), а позже в их число вошли NVLIB (Nvidia), RRedline
(Rendition) и знаменитый Glide. Такое разнообразие сильно усложняло
жизнь разработчикам нового железа, так как API были несовместимы
друг с другом, а разные игры поддерживали разные библиотеки. Выход
DirectX поставил крест на всех сторонних решениях, ведь
использование других проприентарных API в играх для Windows
попросту не имело смысла.
Но нельзя сказать, что новинка от Microsoft была лишена серьезных
недостатков. После представленного DirectX SDK у многих
производителей графических ускорителей исчезла возможность
аппаратно управлять ресурсами видеокарт при воспроизведении
цифрового видео. Многочисленные проблемы с драйверами на недавно
вышедшей Windows 95 возмущали пользователей, привыкших к стабильной
работе ОС Windows 3.1. Со временем все проблемы были решены, но
главная битва за рынок ожидала впереди взявшая паузу ATI готовилась
покорять вселенную трехмерных игр с новой линейкой 3D Rage.
ATI Rage Трехмерная ярость
Демонстрация нового графического ускорителя прошла в рамках
лос-анджелесской выставки E3 1995 года. Инженеры ATI объединили
преимущества чипа Mach 64 (и его выдающихся возможностей работы с
2D-графикой) с новым чипом для обработки 3D, взяв максимум от
предыдущих разработок. Первый 3D-ускоритель ATI 3D Rage (известный
также как Mach 64 GT) вышел на рынок в ноябре 1995 года.
 ATI 3D Rage
ATI 3D Rage
Как и в случае с Nvidia, инженерам пришлось столкнуться с массой
проблем поздние ревизии DirectX 1.0 вызывали многочисленные
проблемы, связанные с отсутствием глубокого буфера. Карта
располагала всего 2 Мб видеопамяти EDO RAM, поэтому 3D-приложения и
игры запускались в разрешении не более 640х480 при 16-битном цвете
или 400х300 при 32-битном, тогда как в 2D-режиме разрешение экрана
было значительно выше до 1280х1024. Попытки запустить игру в режиме
32-битного цвета с разрешением 640х480 обычно заканчивались
цветовыми артефактами на экране, да и игровую производительность 3D
Rage нельзя было назвать выдающейся. Единственным бесспорным
преимуществом новинки была возможность воспроизводить видеофайлы в
формате MPEG в полноэкранном режиме.
В ATI провели работу над ошибками и переработали чип, выпустив Rage
II в сентябре 1996 года. Исправив аппаратные недочеты и добавив
поддержку кодека MPEG2, инженеры по какой-то причине не подумали о
необходимости увеличить объем памяти первые модели всё еще имели на
борту смешные 2 Мб видеопамяти, что неизбежно било по
производительности при обработке геометрии и перспективы. Недочет
был исправлен в более поздних ревизиях адаптера например, в Rage
II+DVD и 3D Xpression+ буфер памяти вырос до 8 Мб.
Но война за 3D-рынок только начиналась, ведь целых три новых
компании готовили свои продукты для новейших игр Rendition,
VideoLogic и 3dfx Interactive. Именно последней удалось в
кратчайшие сроки представить графический чип, значительно
опередивший всех конкурентов и начавший новую эру в 3D-графике
3Dfx Voodoo Graphics.
1996-1999. Эпоха 3Dfx. Величайший графический стартап в
истории. Последний этап большой конкуренции за рынок
Невероятная история 3Dfx стала хрестоматийным воплощением стартапа,
символизирующего как невероятный успех и головокружительные
прибыли, так и некомпетентность самоуверенного руководства, и как
итог крах и забвение. Но печальный финал и горький опыт не в силах
отрицать очевидного 3Dfx в одиночку сотворила графическую
революцию, застав врасплох многочисленных конкурентов, и задав
новую, феноменально высокую планку производительности. Ни до, ни
после этого невероятного периода в истории развития видеокарт мы не
видели ничего, даже отдаленно похожего на сумасшедший взлет 3Dfx во
второй половине девяностых.

3Dfx Voodoo Graphics была графическим адаптером, нацеленным
исключительно на работу с 3D-графикой. Предполагалось, что
покупатель новинки будет использовать для работы с двухмерными
нагрузками другую плату, подключая её к Voodoo через второй
VGA-разъем.
Такой подход не смутил многочисленных энтузиастов, и инновационное
решение сразу же привлекло многих производителей-партнеров,
выпустивших собственные варианты Voodoo.
Одной из интересных карт на базе первого чипа 3Dfx была Orchid
Righteous 3D от Orchid Technologies. Фирменным отличием адаптера за
$299 было наличие механических реле, издающих характерные щелчки
при запуске 3D-приложений или игр.
 Orchid Righteous 3D
Orchid Righteous 3D
В поздних ревизиях эти реле заменили на твердотельные компоненты, и
прежний шарм был утрачен. Вместе с Orchid свои варианты новейшего
ускорителя представили и Diamond Multimedia (Monster 3D),
Colormaster (Voodoo Mania), Canopus (Pure3D и Quantum3D), Miro
(Hiscore), Skywell (Magic3D), и самая пафосная в ряду названий
2theMAX Fantasy FX Power 3D. Раньше видеокарты называть не
стеснялись!
Причины подобного ажиотажа вокруг новинки были очевидны при всех
возможных недостатках Voodoo Graphics обладала невероятной
производительностью, и её появление сразу же перевело в разряд
устаревших множество других моделей особенно тех, что могли
работать только с 2D-графикой. Несмотря на то, что в 1996 году
более половины рынка 3D-ускорителей принадлежало компании S3, 3Dfx
ударными темпами завоевывала миллионы фанатов и уже к концу 1997
года компании принадлежало 85% рынка. Это был феноменальный
успех.
Конкуренты 3Dfx. Rendition и VideoLogic
Громкие успехи вчерашнего новичка не вычеркнули из игры
конкурентов, о которых мы упоминали ранее VideoLogic и Rendition.
VideoLogic создала технологию отложенного мозаичного рендеринга
(TBRD), благодаря которой пропадала необходимость предварительной
Z-буферизации кадра. На финальной стадии рендеринга вычищались
скрытые пиксели, а обработка геометрии началась только после того,
как будут наложены текстуры, тени и освещение. Технология TBRD
работала по принципу разбития кадра на прямоугольные ячейки,
рендеринг полигонов в которых происходил независимо друг от друга.
При этом полигоны, расположенные за пределами видимой области
кадра, отсеивались, а рендеринг остальных начинался только после
обсчета общего числа пикселей. Такой подход позволял сэкономить
массу вычислительных ресурсов на этапе отрисовки кадра, существенно
повышая общую производительность.
Компания вывела на рынок три поколения графических чипов
производства NEC и ST Micro. Первое поколение было эксклюзивным
продуктом в составе компьютеров Compaq Presario под названием Midas
3 (Модели Midas 1 и 2 были прототипами, и использовались в аркадных
автоматах). Вышедшие позже PSX1 и PSX2 были ориентированы на
ОЕМ-рынок.
Чипы второго поколения легли в основу приставки Sega Dreamcast
японской платформы, сыгравшей свою роль в печальной судьбе 3Dfx.
При этом VideoLogic не успели выйти на потребительский рынок
графических карт к моменту премьеры их модель Neon 250 морально
устарела, проиграв всем бюджетным решениям, и это неудивительно,
ведь до прилавков новинка добралась лишь в 1999 году.
Компания Rendition тоже успела отличиться инновациями в графике, и
создала первый графический чип Vrit 1000 с возможностью работы не
только с двухмерной, но и с 3D-графикой одновременно благодаря
процессорному ядру на архитектуре RISC, а также использованию
пиксельных конвейеров. Процессор отвечал за обработку полигонов и
механизма работы конвейеров рендеринга.
Подобный подход к построению и обработке изображения заинтересовал
Microsoft в компании использовали Vrit 1000 во время разработки
DirectX, но у ускорителя были свои архитектурные недостатки.
Например, он работал только на материнских платах с поддержкой
технологии прямого доступа к памяти (Direct memory access, DMA) по
ней передавались данные через шину PCI. Благодаря дешевизне и массе
программных преимуществ, включающих сглаживание и аппаратное
ускорение в Quake от id Software, карта пользовалась популярностью
вплоть до выхода Voodoo Graphics. Новинка от 3Dfx оказалась более
чем в 2 раза производительнее, а технология DMA быстро потеряла
популярность у разработчиков игр, отправив некогда перспективную
V1000 на свалку истории.
ATI Гонка за Voodoo c Rage II и Rage Pro
Тем временем ATI не прекращала работу над новыми ревизиями Rage.
Следом за Rage II в марте 1997 года была представлена Rage Pro
первая AGP-видеокарта от сформированного накануне подразделения ATI
3D Engineering Group.
Rage Pro с 4 Мб видеопамяти на борту практически сравнялась с
легендарной Voodoo по производительности, а вариант на AGP-шине с 8
Мб видеопамяти даже превосходил знаменитого конкурента в ряде игр.
В Pro-версии карты инженеры ATI доработали коррекцию перспективы и
обработку текстур, а также добавили поддержку аппаратного
сглаживания и трилинейной фильтрации благодаря увеличенному кэшу в
4 Кб. Чтобы снизить зависимость производительности адаптера от
центрального процессора в компьютере, на плате был распаян
отдельный чип для обработки операций с плавающей запятой. Любители
современных мультимедиа оценили поддержку аппаратного ускорения при
воспроизведении видео с DVD-носителя.
Выход на рынок Rage Pro позволил ATI поправить дела с финансами и
увеличить чистую прибыль до $47.7 миллионов при общем обороте более
$600 млн. По большей части финансовый успех продукту принесли
OEM-контракты, реализация графического чипа на материнских платах и
выпуск мобильного варианта. Карта, часто фигурировавшая в продаже в
вариантах Xpert@Work и Xpert@Play, имела массу конфигураций от 2 до
16 Мб видеопамяти для различных нужд и сегментов рынка.
Важным стратегическим плюсом для штата ATI стало приобретение за $3
миллиона компании Tseng Labs, в которой работали над технологиями
интеграции чипов RAMDAC на борт графических карт. Компания
разрабатывала собственный графический адаптер, но столкнулась с
техническими проблемами, что и привело к встречному предложению от
канадских лидеров рынка. Вместе с интеллектуальной собственностью в
штат ATI перешло 40 инженеров высшего класса, сразу же приступивших
к работе.
Новые конкуренты. Permedia и RIVA 128
Профессионалы из 3DLabs не оставляли надежды захватить интересы
геймеров. Для этого была выпущена серия продуктов Permedia,
произведенная по 350 нм техпроцессу Texas Instruments. Оригинальная
Permedia обладала относительно низкой производительностью, что было
исправлено в Permedia NT. Новая карта обладала отдельным чипом
Delta для обработки полигонов и алгоритма сглаживания, но при этом
стоила дорого целых $600. Когда к концу 1997 года была готова
обновленная линейка Permedia 2, конкурировать с игровыми продуктами
она уже не могла 3DLabs сменили маркетинг, и представили новинки
как профессиональные карты для работы с 2D-приложениями и
ограниченной поддержкой 3D.
Всего через месяц после последних премьер 3DLabs и ATI на рынок
вернулась Nvidia, представив свою RIVA 128, готовую к жесткой
конкуренции кошельки геймеров. Доступная цена и отличная
производительность в Direct3D обеспечили новинке всеобщее признание
и коммерческий успех, позволив компании заключить контракт с TSMC
на производство чипов обновленной RIVA 128ZX. К концу 1997 года две
успешные видеокарты принесли Дженсену Хуангу 24% рынка практически
всё, что не успела подмять под себя всемогущая 3Dfx.
Забавно, что пути Nvidia и лидера рынка начали пересекаться уже
тогда, когда Sega, готовясь к разработке новой консоли Dreamcast,
заключила несколько предварительных контрактов с производителями
графических решений. Среди них была и Nvidia (с проектом чипа NV2),
и 3Dfx (с прототипом Blackbelt). Руководство 3Dfx было полностью
уверено в получении контракта, но, к своему удивлению, получило
отказ японцы предпочли не рисковать, и обратились за разработкой в
NEC, ранее зарекомендовавшей себя сотрудничеством с Nintendo.
Представители 3Dfx подали на Sega в суд, обвиняя компанию в
намерениях присвоить себе проприетарные разработки в ходе работы
над прототипом долгие судебные тяжбы закончились в 1998 году
выплатой компенсации в размере $10.5 миллиона в пользу американской
компании.
Quantum3D и первое применение SLI
А пока они продолжались, 3Dfx успела обзавестись дочерней
компанией. Ей стала Quantum3D, получившая сразу несколько выгодных
контрактов на разработку профессиональных графических решений
самого высокого уровня от SGI и Gemini Technology. В основе будущих
продуктов лежала инновационная разработка 3Dfx технология SLI
(Scan-Line Interleave).
Технология предполагала возможность использования двух графических
чипов (каждый из которых имеет собственный контроллер памяти и
буфер) в рамках одной платы или соединение двух отдельных плат с
помощью специального ленточного кабеля. Соединенные подобным
образом карты (в формате двухчиповой платы или двух отдельных)
делили обработку изображения напополам. Технология SLI обеспечивала
возможность увеличения разрешения экрана с 800х600 до 1024х768
точек, но подобная роскошь обходилась недешево: Obsidian Pro
100DB-4440 (две спаренные карты с чипами Amethyst) предлагалась по
цене в $2500, тогда как двухчиповая плата 100SB-4440/4440V обошлась
бы покупателю в $1895.
 Obsidian Pro 100DB-4440
Obsidian Pro 100DB-4440
Специализированные решения, впрочем, никак не отвлекали лидеров
рынка от разработки новых карт серии Voodoo.
3Dfx Voodoo Rush. Спешка, бюджет и разочарование
Летом 1997 года 3Dfx вышла на биржу, и попыталась закрепить
ошеломительный успех Voodoo, выпустив Voodoo Rush карту, работающую
с 2D и 3D-графикой одновременно, и уже не требующей второго
адаптера. Изначально в её основе должен был лежать новый чип
Rampage, но из-за технических проблем его релиз был отложен, и в
основе Rush использовался урезанный вариант оригинальной Voodoo.
Чтобы помирить два вида графических нагрузок, на плате
располагалось два чипа SST-1 отвечал за обработку 3D-игр,
использующих API Glide, тогда как более посредственный чип
производства Alliance или Macronix отвечал за другие 2D и
3D-приложения и игры. Из-за рассинхронизации чипы работали на
разных частотах (50 и 72 МГц), вызывая случайные артефакты на
экране и недоумение владельцев.
 Voodoo Rush
Voodoo Rush
Помимо этого, Voodoo Rush имела общий буфер видеопамяти, который
одновременно использовали оба чипа. От этого пострадало
максимальное разрешение экрана оно составляло лишь половину от
1024х768 (512х384 точки), а низкие частоты RAMDAC не позволили
обеспечить желанные 60 Гц в обновлении экрана.
Rendition V2100 и V2200. Уход с рынка
На фоне больших проблем 3Dfx компания Rendition предприняла новую
попытку приятно удивить массовый рынок Rendition V2100 и V2200.
Новинки вышли на рынок незадолго после премьеры Voodoo Rush, но, к
разочарованию энтузиастов, не смогли потягаться даже с урезанной
Voodoo. Невостребованные видеокарты вынудили Rendition первой из
многих покинуть рынок графических карт.
В результате многие проекты компании остались на стадии прототипов
одним из них была доработанная версия V2100/V2200 с геометрическим
процессором Fujitsu FXG-1 (в формате двухчипового исполнения).
Впрочем, существовал и одночиповый вариант с FXG-1, вошедший в
историю как продукт с самым изысканным названием в истории Hercules
Thrilled Conspiracy. Вместе с другими разработками (например,
чипами V3300 и 4400E) компания была продана Micron за $93 млн в
сентябре 1998 года.
Агрессивная экономия. Битва за бюджетный сегмент
Постоянный рост производительности и появление новых технических
преимуществ привели к тому, что производителям второго эшелона
стало крайне сложно конкурировать с решениями от ATI, Nvidia и
3Dfx, занявших не только нишу энтузиастов и профессионалов, но и
народный сегмент рынка адаптеров ценой до $200.
Matrox представила свою графическую карту Mistique по вкусной цене
от $120 до $150, но из-за отсутствия поддержки OpenGL новинка сразу
же попала в категорию аутсайдеров. S3 начала продажи новой линейки
ViRGE, с присутствием максимально широкого модельного ряда свет
увидела и мобильная версия адаптера с динамическим управлением
питанием (ViGRE/MX), и специальная версия основного ViRGE с
поддержкой ТВ-выхода, разъема S-Video и воспроизведением DVD
(ViRGE/GX2). Два основных адаптера, призванных сразиться за
бюджетный рынок (модели ViRGE, VIRGE DX и ViRGE GX) стоили на
момент выхода от $120 за младшую до $200 за старшую.
Трудно представить, но категория ультра-бюджетных решений тоже была
местом жесточайшей конкуренции. За кошельки пользователей, готовых
заплатить за графический ускоритель не более $99, тягались Laguna3D
от CirrusLogic, модели 9750/9850 от Trident, а также SiS 6326. Все
эти карты были компромиссными решениями с минимумом
возможностей.
После выхода Laguna3D компания CirrusLogic покинула рынок низкое
качество 3D-графики, посредственная (и непостоянная)
производительность, а также куда более интересные конкуренты (та же
ViRGE, стоившая чуть дороже) не оставляли ветеранам индустрии шанса
на выживание. Единственными источниками дохода для CirrusLogic
оставались продажи допотопных 16-битных графических адаптеров за
$50, интересных лишь самым экономным клиентам.
Trident тоже видела потенциал в сегменте рынка ниже среднего в мае
1997 года была выпущена 3D Image 9750, а немногим позже вышла 9850
с поддержкой двухканальной AGP-шины. Исправив многие недочеты 9750
с PCI-шиной, 9850 страдала от посредственной обработки текстур, и
не получила лестных отзывов.
Среди карт, продаваемых за бесценок, наиболее успешной была SiS
6326, представленная в июне 1997 года по цене до $50. Обладая
хорошим качеством изображения и относительно высокой
производительностью, 6326 разошлась тиражом в 8 миллионов устройств
в 1998 году. Но на исходе 90-х мир энтузиастов всколыхнул стартап,
полный серьезных обещаний им была компания BitBoys.
BitBoys Дерзкие ребята в мире сказочного 3D
BitBoys заявила о себе в июне 1997 года анонсом интригующего
проекта Pyramid3D. Революционный графический чип разрабатывался
совместными усилиями самого стартапа с компаниями Silicon VLSI
Solutions Oy и TriTech. К сожалению для энтузиастов, кроме громких
слов на презентациях Pyramid3D так нигде и не появился, а компания
TriTech была осуждена за присвоение чужого патента на аудиочип,
из-за чего позже обанкротилась и закрылась.
Но BitBoys не прекращали работу, и анонсировали второй проект под
названием Glaze3D. Невероятный реализм, лучшая производительность в
своем классе и масса новейших технологий были показаны публике на
SIGGRAPH99. Рабочий прототип графического адаптера использовал шину
RAMBUS и 9 Мб видеопамяти DRAM производства Infineon.
Увы, как и в первый раз, аппаратные проблемы и переносы привели к
тому, что ожидаемой революции вновь не наступило.
 Рекламный скриншот, призванный подчеркнуть реализм, которого
должны были достичь карты Glaze3D
Рекламный скриншот, призванный подчеркнуть реализм, которого
должны были достичь карты Glaze3D
Намного позже проект был вновь переименован Axe, а полем для
конкуренции выбрали игры с поддержкой DirectX 8.1 прототип даже
успел получить официальное название Avalanche3D и обещал взорвать
рынок в 2001, но не случилось. На последнем этапе разработки Axe
сменился на Hammer, которому прочили поддержку DirectX 9.0. История
самого пафосного долгостроя в истории графики закончилась
банкротством Infineon, после которого BitBoys отказались от проекта
мечты и перешли в сегмент мобильной графики. А теперь вновь
вернемся в уютный 1998.
Intel i740 Большая неудача больших профессионалов
Intel выпустила свою первую (и пока что последнюю) графическую
карту для 3D-игр под названием Intel i740 в январе 1998 года. У
проекта была интересная история, ведь корнями он уходил в проект
программы симуляции космических полетов, которую NASA совместно с
General Electric создавала для знаменитой серии лунных миссий
Аполлон. Позже наработки были проданы Martin Marietta компании,
позже вошедшей в состав оборонного гиганта Lockheed (так и появился
тот самый Lockheed-Martin). Lockheed-Martin на базе проекта создал
линейку профессиональных устройств Read3D, состоящую из двух
моделей графических адаптеров Real3D/100 и Real3D/Pro-1000.
Иронично, но несмотря на военное происхождение устройств одним из
применений выдающихся технологий стал аркадный автомат Sega,
использующий две платы Pro-1000.

Немного позднее Lockheed-Martin объявил о начале Project Aurora
коллаборации с Intel и Chips and Technologies. За месяц до выхода
i740 Intel приобрела 20% проекта Real3D, а к июлю 1997 года
полностью выкупила Chips and Technologies.
Ключевой особенностью проекта Real3D было использование двух
отдельных чипов для обработки текстур и графики Intel объединила их
при создании i740. Адаптер использовал оригинальный подход к
буферизации данных через шину AGP содержимое кадрового буфера и
текстуры загружалось прямо в оперативную память компьютера. В
партнерских вариантах i740 обращение к оперативной памяти
происходило лишь в том случае, если собственный буфер адаптера
полностью заполнялся или был сильно сегментирован. Такой же подход
часто используется и сегодня при исчерпании памяти на борту
видеокарты система увеличивает буфер, используя свободную RAM.

Но во времена, когда буферы исчислялись мегабайтами, а текстуры еще
не раздулись до неприличных размеров, такой подход мог показаться
по меньшей мере странным.
Чтобы уменьшить возможные задержки при работе с шиной, Intel
использовали одну из её особенностей прямой доступ к буферу памяти
(Direct Memory Execute или DiME). Такой метод еще назывался
AGP-текстуризацией, и позволял использовать оперативную память
компьютера для маппинга текстур, обрабатывая их селективно. Средняя
производительность вкупе с посредственным качеством изображения
позволили i740 добиться уровня прошлогодних карт своего ценового
сегмента.

За модель с 4 Мб видеопамяти просили $119, а вариант с 8 Мб стоил
$149. При этом помимо базовой версии Intel свет увидели всего два
партнёрских варианта Real3D StarFighter и Diamond Stealth II
G450.
Рассчитывая на успех, Intel начала разработку следующего чипа i752,
но ни ОЕМ-производители, ни энтузиасты не проявили интереса к
бюджетному адаптеру, серьезно отстающему от актуальных решений. И
это неудивительно, ведь в то же время продавалась ViRGE от S3,
покупка которой куда больше порадовала бы пользователя.
Производство адаптеров было свернуто, а вышедшие на рынок чипы i752
перепрофилировали для использования в качестве решений
интегрированной графики.
В октябре 1999 года Lockheed-Martin ликвидировала Real3D, а богатый
штат специалистов разошелся в Intel и ATI.
ATI Возвращение в игру с Rage Pro и Rage 128
ATI вновь заявила о себе с Rage Pro Turbo в феврале 1998 года, но
эта карта оказалась всего лишь ребрендингом Rage Turbo с доработкой
драйверов для выдающихся результатов в синтетических текстах.
Обзорщики некоторых изданий были приятно удивлены, но цену в $449
оправдать было очень сложно. Тем не менее, именно с Rage Pro Turbo
впервые появился феномен Finewine драйвера постепенно улучшали
производительность адаптера с каждой новой ревизией.
Куда более серьезную попытку повлиять на расстановку сил ATI
предприняла с выходом Rage 128 GL и Rage 128 VR в августе того же
года. Из-за проблем с поставками ATI не смогла обеспечить наличие
моделей в магазинах почти до зимних каникул, что сильно сказалось
на продвижении новинок. В отличие от OEM-контрактов, стабильно
приносящих канадцам серьезную прибыль, простые энтузиасты не смогли
оценить новинку из-за отсутствия адаптеров на рынке. Но была и
другая причина, по которой продажи Rage 128 оказались ниже
ожидаемого.
ATI подготовила Rage 128 к светлому графическому будущему, оснастив
новинку 32 Мб видеопамяти (варианты с 16 Мб выпускались под брендом
All-In-Wonder 128), которая работала на быстрой и эффективной
подсистеме в 32-битном цвете прямой конкурент NVidia Riva TNT не
имел никаких шансов. Увы, во времена выхода новинки большинство игр
и приложений всё еще работали в 16-битном режиме, где Rage 128
ничем не выделялась на фоне NVidia и S3 (а по качеству изображения
даже уступала моделям от Matrox). Массовая публика не оценила
подхода ATI, но именно тогда канадцы впервые опередили своё время
вот только по достоинству их подход оценили гораздо позже.
1998 год стал для ATI рекордным при обороте в $1.15 млрд чистая
прибыль компании составила неплохие $168.4 миллиона. Канадская
компания завершила год, располагая 27% рынка графических
ускорителей.
В октябре 1998 года ATI приобрела Chromatic Research за $67
миллионов. Компания, знаменитая своими медиапроцессорами MPACT,
была поставщиком решений для PC TV от Compaq и Gateway, и
предлагала великолепную производительность при работе с MPEG2,
высокое качество аудио и отличные показатели в режиме 2D. По иронии
судьбы именно единственный недостаток MPACT в виде слабой
производительности в 3D-режиме поставил Chromatic Research на грань
банкротства всего через 4 года после основания. Всё ближе
подступало время универсальных решений.
3Dfx Voodoo 2 и Voodoo Banshee Успешный провал лидера
рынка
Пока Intel пыталась выйти на рынок графических адаптеров, его лидер
в лице 3Dfx представил Voodoo 2, ставшую технологическим прорывом в
нескольких сферах одновременно. Новый графический адаптер от 3Dfx
имел уникальный дизайн помимо центрального чипа на плате были два
спаренных текстурных обработчика, благодаря чему карта была не
только трехчиповой, но и обеспечивала возможность мультитекстурной
обработки в OpenGL (когда на пиксель накладывались две текстуры
одновременно, ускоряя общую прорисовку сцены), чего прежде никогда
не использовалось. Как и оригинальная Voodoo, карта работала
исключительно в режиме 3D, но в отличие от конкурентов, совмещавших
в одном чипе 2D и 3D-обработку, 3Dfx не шла ни на какие
компромиссы, преследуя главную цель отстоять позиции лидера
рынка.
Профессиональные версии нового адаптера не заставили себя долго
ждать дочерняя компания 3Dfx Quantum3D выпустила три примечательных
акселератора на базе новинки двухчиповой Obsidian2 X-24, которую
можно было использовать в паре с 2D-платой, SB200/200Sbi с 24 Мб
памяти EDO на борту, а также Mercury Heavy Metal экзотический
бутерброд, в котором спаренные 200Sbi соединялись между собой
контактной платой Aalchemy, в будущем ставшей прототипом
знаменитого SLI-мостика NVidia.
 Mercury Heavy Metal
Mercury Heavy Metal
Последний вариант предназначался для проведения сложных графических
симуляций, и был доступен по космической цене в
$9999. Для
полноценной работы монстр MHM требовал серверной материнской платы
серии Intel BX или GX с четырьмя слотами PCI.
Понимая важность контроля над бюджетным рынком уже в июне 1998 года
3Dfx представила Voodoo Banshee первый графический ускоритель с
поддержкой 2D и 3D режимов работы. Вопреки ожиданиям и надеждам
ставший легендарным чип Rampage так и не был готов, а на борту
карта имела всего один блок обработки текстур, практически
уничтоживший производительность новинки в мультиполигональном
рендеринге Voodoo 2 была в разы быстрее. Но даже если экономичное
производство с узнаваемым брендом и обеспечили Banshee хорошие
продажи, то разочарование фанатов никуда не исчезло от создателей
той самой Voodoo, в одночасье перевернувшей графический рынок,
ожидали куда большего.
К тому же, несмотря на лидерство Voodoo 2, отрыв от конкурентов
стремительно сокращался. Навязав ATI и NVidia серьезную
конкуренцию, 3Dfx сталкивалась всё и новыми и новыми передовыми
решениями, и лишь благодаря эффективному менеджменту (3Dfx
производила и продавала карты сама, без участия партнеров) компания
получала значительную прибыль с продаж. Но руководство 3Dfx видело
массу возможностей в приобретении собственных фабрик по
производству кремниевых пластин, поэтому компания выкупила STB
Technologies за $131 миллион с расчётом на радикальное сокращение
стоимости производства и навязывание конкуренции поставщикам Nvidia
(TSMC) и ATI (UMC). Эта сделка стала роковой в истории 3Dfx
мексиканские фабрики STB безнадежно отставали по качеству продукции
от азиатских конкурентов, и никак не могли конкурировать в гонке за
техпроцесс.
После того, как стало известно о приобретении STB Technologies,
большинство партнеров 3Dfx не поддержали сомнительное решение, и
перешли на продукты NVidia.
Nvidia TNT Заявка на техническое лидерство
И причиной для этого стала представленная Nvidia 23 марта 1998 года
Riva TNT. Добавив параллельный пиксельный конвейер в архитектуру
Riva, инженеры удвоили скорость отрисовки и рендеринга, что вкупе с
16 Мб памяти формата SDR значительно увеличило производительность.
Voodoo 2 использовала куда более медленную память EDO и это давало
новинке от Nvidia серьезное преимущество. Увы, техническая
сложность чипа имела свои плоды из-за аппаратных ошибок при
производстве 350-нм чип TSMC не работал на задуманных инженерами
125 МГц частота часто падала до 90 МГц, из-за чего Voodoo 2 смогла
сохранить звание формального лидера по производительности.
Но даже при всех недостатках TNT была впечатляющей новинкой.
Благодаря использованию двухканальной AGP-шины карта обеспечивала
поддержку игровых разрешений до 1600х1200 при 32-битном цвете (и
24-битном Z-буфере для обеспечения глубины изображения). На фоне
16-битной Voodoo 2 новинка от nVidia выглядела настоящей революцией
в графике. И хотя TNT не была лидером в бенчмарках, она оставалась
опасно близкой к Voodoo 2 и Voodoo Banshee, предлагая больше новых
технологий, лучшее скалирование с частотой процессора и более
высокое качество обработки 2D и текстур благодаря прогрессивной
AGP-шине. Единственным минусом, как и в случае с Rage 128, были
задержки в поставках большое количество адаптеров появилось в
продаже только осенью, в сентябре 1998 года.
Другим пятном на репутации Nvidia в 1998 году стал иск компании
SGI, согласно которому NVidia нарушила права на патент внутренней
технологии текстур-маппинга. По итогу судебных разбирательств,
продлившихся целый год, было заключено новое соглашение, согласно
которому NVidia получала доступ к технологиям SGI, а SGI получала
возможность использовать наработки Nvidia. При этом графической
подразделение самой SGI было расформировано, что только пошло на
пользу будущему графическому лидеру.
Number Nine Шаг в сторону
Тем временем 16 июня 1998 года ОЕМ-производитель графических
решений Number Nine решил попытать счастья на рынке графических
адаптеров, выпустив карту Revolution IV под собственным
брендом.
Сильно отставая по производительности от флагманских решений ATI и
Nvidia, Number Nine сделала акцент на бизнес-сектор, предложив
крупным компаниям то, в чем были слабы классические карты для игр и
3D-графики поддержку высоких разрешений в 32-битном цвете.
Чтобы завоевать интерес крупных компаний, Number Nine интегрировала
проприентарный 36-пиновый разъем OpenLDI в свою Revolution IV-FP, и
продавала плату в комплекте с 17.3 дюймовым монитором SGI 1600SW (с
поддержкой разрешения 1600х1024). Набор стоил $2795.
Особого успеха предложение не снискало, и Number Nine вернулась к
выпуску партнерских карт S3 и Nvidia, пока не была куплена S3 в
декабре 1999, а затем продана бывшим инженерам компании,
сформировавшим Silicon Spectrum в 2002 году.
S3 Savage3D Бюджетная альтернатива Voodoo и TNT за $100
Бюджетный чемпион в лице S3 Savage дебютировал в рамках E3 1998, и
в отличие от многострадальных доминаторов сегментом выше (Voodoo
Banshee и Nvidia TNT) попал на полки магазинов уже через месяц
после анонса. К сожалению, спешка не могла пройти незаметно
драйвера были сырыми, а поддержка OpenGL была реализована только в
Quake, ведь проигнорировать одну из самых популярных игр года S3
себе позволить не могла.
С частотами S3 Savage также было не всё гладко. Из-за
производственных недочетов и высокого энергопотребления референсные
модели адаптера сильно грелись, и не обеспечивали задуманного
порога частоты в 125 МГц частота обычно плавала между значениями в
90 и 110 МГц. При этом обозреватели из лидирующих изданий получили
на руки инженерные образцы, исправно работавшие на 125 МГц, что
обеспечило красивые цифры во всевозможных бенчмарках вместе с
похвалами профильной прессы. Позже, в партнерских моделях ранние
проблемы были решены Savage3D Supercharged стабильно работала на
120 МГц, а Terminator BEAST (Hercules) и Nitro 3200 (STB) покорили
заветную планку в 125 МГц. Несмотря сырые драйвера и посредственную
производительность на фоне лидеров большой тройки демократичная
цена в пределах $100 и возможность качественного воспроизведения
видео позволили S3 получить неплохие продажи.
1997 и 1998 годы стали очередным периодом поглощений и банкротств
многие компании не выдержали конкуренции в гонке за
производительностью, и были вынуждены уйти из отрасли. Так за
бортом остались Cirrus Logic, Macronix, и Alliance Semiconductor,
тогда как Dynamic Pictures была продана 3DLabs, Tseng Labs и
Chromatic Research оказались выкуплены ATI, Rendition ушла Micron,
AccelGraphics приобрели Evans & Sutherland, а Chips and
Technologies стали частью Intel.
Trident, S3 и SiS Последняя битва тысячелетия за бюджетную
графику
ОЕМ-рынок всегда был последней соломинкой для производителей,
безнадежно отставших от конкурентов в работе с 3D-графикой и чистой
производительностью. Таким он был и для компании SiS, выпустившей
бюджетную SiS 300 для нужд бизнес-сектора. Несмотря на плачевную
производительность в 3D (ограниченную единственным пиксельным
конвейером) и безнадежное отставание в 2D от всех конкурентов
мейнстрим-рынка, SiS 300 покорила OEM-производителей определенными
преимуществами 128-битной шиной памяти (64-битной в случае более
упрощенной SiS 305), поддержкой 32-битного цвета, DirectX 6.0 (и
даже 7.0 в случае с 305), поддержкой мультитекстурного рендера и
аппаратного декордирования MPEG2. Был у графической карты и
ТВ-выход.
В декабре 2000 года свет увидела модернизированная SiS 315, где
появился второй пиксельный конвейер и 256 битная шина, а также
полная поддержка DirectX 8.0 и полноэкранного сглаживания. Карта
получила новый движок обработки освещения и текстур, компенсацию
задержек при проигрывании видео с DVD-носителей и поддержку разъема
DVI. Уровень производительности находился в районе GeForce 2 MX
200, но это ничуть не смущало компанию.
Попала SiS 315 и на ОЕМ-рынок, но уже в составе чипсета SiS 650 для
материнских плат на сокете 478 (Pentium IV) в сентябре 2001, а
также как часть SoC-системы SiS552 в 2003.
Но SiS была далеко не единственным производителем, предлагавшим
интересные решения в бюджетном сегменте. Trident также боролась за
внимание покупателей с Blade 3D, общая производительность которой
была на уровне провальной Intel i740, но цена в $75 с лихвой
перекрывала многие недостатки. Позже на рынок вышла Blade 3D Turbo,
в которой частоты поднялись со 110 до 135 МГц, а общая
производительность вышла на уровень i752. К сожалению, Trident
разрабатывала свои решения слишком долго для рынка, где новинки
презентовали каждые пару месяцев, поэтому уже в апреле 2000 года
это нанесло первый удар по компании VIA, для которой Trident
разрабатывали встроенную графику, приобрела компанию S3, и
прекратила сотрудничество с прежним партнером.
Впрочем, Trident использовала свою бизнес-модель в максимально
выгодном ключе, сочетая массовые поставки и низкую стоимость
производства своих бюджетных решений. Мобильный сектор рынка
оставался относительно свободным, и специально для него в Trident
разработали несколько моделей Blade3D Turbo T16 и T64 (работающих
на частоте 143 МГц) и XP (работавшей на частоте 165 МГц). А вот
приглянувшийся многим компаниям OEM-рынок уже не был благосклонен к
простоте Trident вышедшая чуть позже SiS 315 поставила шах и мат
всей линейке продуктов Trident. Не имея возможности быстро
разработать достойную альтернативу, в Trident приняли решение
продать графическое подразделение дочке SiS компании XGI в 2003
году.
Особняком среди прочих решений в бюджетном секторе стояла S3
Savage4. Анонсированная в феврале и поступившая в продажу в мае
1999 года, новинка предлагала 16 и 32 Мб памяти на борту, 64-битную
четырехканальную шину AGP и собственную технологию сжатия текстур,
благодаря которой адаптер мог обрабатывать блоки разрешением вплоть
до 2048х2048 без особых затруднений (хотя это и было реализовано
ранее в Savage3D). Умела карта проводить и мультитекстурный
рендеринг, но даже отлаженные драйвера и впечатляющие технические
характеристики не могли скрыть того факта, что прошлогодние
предложения от 3Dfx, Nvidia и ATI были значительно
производительнее. И такое положение вещей повторилось год спустя,
когда на рынок вышла Savage 2000. В низких разрешениях (1024х768 и
менее) новинка могла потягаться с Nvidia TNT и Matrox G400, но при
выборе более высокого разрешения расстановка сил радикально
менялась.
3Dfx Voodoo3 Пафос, шум и пустые оправдания
3Dfx не могла допустить, чтобы их новинка затерялась на фоне
прогрессирующих конкурентов, поэтому премьера Voodoo3 в марте 1999
года сопровождалась обширной рекламной кампанией карту ярко
продвигали в прессе и по телевидению, а смелое оформление коробки
притягивало взгляды потенциальных покупателей, мечтавших о новой
графической революции.

Увы, ставший притчей во языцех чипсет Rampage всё еще не был готов,
и архитектурно новинка представляла собой родственника Voodoo2 на
основе чипа Avenger. Архаичные технологии вроде поддержки
исключительно 16-битного цвета и разрешения текстур всего в 256х256
не порадовали поклонников бренда как и полное отсутствие поддержки
аппаратной обработки освещения и геометрии. Многие производители
уже ввели моду на текстуры высокого разрешения, мультиполигональный
рендеринг и 32-битный цвет, поэтому 3dfx впервые оказалась в числе
отстающих по всем параметрам.
Инвесторам убытки в $16 миллионов пришлось объяснять недавним
землетрясением в Тайване, которое, однако, почти не отразилось на
финансовых успехах ATI и Nvidia. Понимая очевидные преимущества
свободного распространения библиотек DirectX и OpenGL, компания еще
в декабре 1998 года объявила о том, что их API Glide будет доступен
как open-source. Правда, на тот момент желающих едва ли было
слишком много.
Riva TNT2 и G400 Конкуренты впереди
Одновременно с пафосной премьерой Voodoo3 от 3Dfx Nvidia скромно
представила свою RIVA TNT 2 (с первыми в своей истории картами
серии Ultra, где геймеры получали более высокие частоты ядра и
памяти), а Matrox презентовала не менее впечатляющую G400.
Riva TNT2 производилась по 250 нм технологии на фабриках TSMC, и
смогла обеспечить Nvidia беспрецедентный уровень
производительности. Новинка разгромила Voodoo3 практически везде
исключением стали лишь несколько игр, в которых использовалась
технология AMD 3DNow! В сочетании с OpenGL. Не отстала Nvidia и в
плане технологий на картах серии TNT2 присутствовал DVI-разъем для
поддержки новейших мониторов с плоским экраном.
Настоящей неожиданностью для всех стала Matrox G400, которая
оказалась еще более производительной, чем TNT2 и Voodoo3, отставая
лишь в играх и приложениях с использованием OpenGL. За свою
демократичную цену в $229 новинка от Matrox предлагала отличное
качество изображения, завидную производительность и возможность
подключения двух мониторов через спаренный разъем DualHead. Второй
монитор был ограничен разрешением в 1280х1024, но сама идея многим
пришлась по душе.
Для G400 также была реализована технология рельефного
текстурирования (Environment Mapped Bump Mapping, EMBM) для
повышения общего качества прорисовки текстур. Для тех, кто всегда
предпочитал приобретать лучшее, существовала G400 MAX, носившая
титул самой производительной карты на рынке вплоть до выхода
GeForce 256 с DDR-памятью в начале 2000 года.
Matrox Parhelia и 3DLabs Permedia Последние
посредственности
Большой успех на рынке игровых графических ускорителей не слишком
вдохновил Matrox, которая вернулась на профессиональный рынок, лишь
однажды соблазнившись повторить успех G400 с Parhelia, но в 2002
году конкуренты уже вовсю осваивали DirectX 9.0, а поддержка трех
мониторов одновременно меркла на фоне плачевной игровой
производительности.
Когда публика уже успела переварить громкие релизы трех компаний,
3DLabs представила давно заготовленную Permedia 3 Create! Главной
особенностью новинки было нишевое позиционирование 3DLabs
рассчитывали привлечь внимание профессионалов, предпочитающих
коротать свободное время в играх. Компания сделала акцент на
высокую производительность в 2D, и привлекла к проекту специалистов
из приобретенной в 1998 году Dynamic Pictures, авторов
профессиональной линейки адаптеров Oxygen.
К несчастью для 3DLabs, в профессиональных картах приоритетом было
сложнополигональное моделирование, и зачастую высокая
производительность в этом направлении обеспечивалась серьезным
снижением скорости обработки текстур. Игровые адаптеры с
приоритетом в 3D работали с точностью до наоборот вместо сложных
вычислений во главу угла ставилась скорость рендеринга и обработки
текстур с высоким качеством изображения.
Значительно отставая от Voodoo3 и TNT 2 в играх, и не слишком
опережая конкурентов в рабочих приложениях и задачах, Permedia
оказалась последней попыткой 3DLabs выпустить продукт на рынок
игровых адаптеров. Далее знаменитые графические инженеры продолжали
расширение и поддержку своих специализированных линеек GLINT R3 и
R4 на архитектуре Oxygen, где изобилие моделей варьировалось от
бюджетных VX-1 за $299 до премиальных GVX 420 за $1499.
Была в репертуаре компании и линейка адаптеров Wildcat, основанная
на разработках Intense3D, купленной у Integraph в июле 2000 года. В
2002 году когда 3DLabs активно заканчивала разработку передовых
графических чипов для новых адаптеров Wildcat, компанию выкупила
Creative Technology со своими планами на линейки P9 и P10.
В 2006 году компания покинула рынок настольных компьютеров,
сосредоточившись на решениях для медиа-рынка, а позже вошла в
состав Creative SoC, и стала известна как ZiiLab. История 3DLabs
окончательно закончилась в 2012 году, когда компанию купила
Intel.
ATI Rage MAXX Двухчиповое безумие в роли отстающего
С момента выхода успешной Rage 128 ATI испытывала ряд трудностей с
дальнейшим развитием линейки. В конце 1998 года инженерам удалось
успешно реализовать поддержку шины AGP 4x в обновленной версии
адаптера Rage 128 Pro, дополнив число разъемов ТВ-выходом. В целом
графический чип показывал себя примерно на уровне TNT 2 в плане
игровой производительности, однако после выпуска TNT 2 Ultra
первенство вновь перешло к Nvidia, с чем канадцы мириться не
хотели, началась работа над Project Aurora.
Когда стало очевидно, что гонка за производительностью проиграна,
инженеры прибегли к трюку, который в будущем станет одной из
особенностей многих поколений красных карт они выпустили Rage Fury
MAXX, двухчиповую графическую карту, на плате которой трудились две
Rage 128 Pro.
 Rage Fury MAXX
Rage Fury MAXX
Внушительные спецификации и возможность параллельной работы двух
чипов сделали карту с одиозным названием достаточно продуктивным
решением, и вывели ATI вперед, долго лидерство удерживать не
удалось. За титул лучших боролась даже S3 Savage 2000, а
представленная позже GeForce 256 с DDR-памятью не оставила флагману
ATI никаких шансов несмотря на угрожающие цифры и прогрессивные
технологии. Nvidia понравилось быть первой, и уступать место лидера
рынка юный Дженсен Хуанг совсем не торопился.
GeForce 256 первая настоящая видеокарта. Рождение термина
GPU
Не прошло и двух месяцев с момента, как ATI наслаждалась пирровой
победой в бенчмарках с анонсом Rage Fury MAXX, когда Nvidia
представила ответ, закрепивший за компанией статус лидера рынка
GeForce 256. Новинка первой в истории выходила с разными типами
видеопамяти 1 октября 1999 года свет увидела версия с чипами SDR, а
уже 1 февраля 2000 года начались продажи обновленной версии с
памятью типа DDR.
 GeForce 256 DDR
GeForce 256 DDR
Графический чип из 23 миллионов транзисторов изготавливался на
фабриках TSMC по 220 нм техпроцессу, но, что куда более важно,
именно GeForce 256 стала первым графическим адаптером, получивший
название видеокарта. Заметили, как тщательно мы избегали этого
термина на протяжении всего повествования? Смысл неловких замен был
именно в этом. Термин GPU (Graphics Processing Unit, чип обработки
графики) появился благодаря интеграции отдельных прежде конвейеров
обработки текстур и освещения в качестве составной части чипа.
Широкие возможности архитектуры позволяли графическому чипу
видеокарты проводить тяжелые вычисления в операциях с плавающей
запятой, преобразовывая сложные массивы 3D-объектов и составных
сцен в красивую 2D-презентацию для впечатленного игрока. Прежде все
подобные сложные вычисления проводил центральный процессор
компьютера, что служило серьезным ограничением детализации в
играх.
Статус GeForce 256 как пионера в использовании программных шейдеров
с поддержкой технологии трансформации и освещения (T&L) часто
подвергался сомнению. Другие производители графических ускорителей
уже внедряли поддержку T&L в прототипах (Rendition V4400,
BitBoys Pyramid3D и 3dfx Rampage), или на стадии сырых, но
работоспособных алгоритмов (3DLabs GLINT, Matrox G400), или в
качестве функции, реализованной дополнительным чипом на плате
(геометрический процессор Fujitsu на борту Hercules Thriller
Conspiracy).
Тем не менее, ни один из вышеперечисленных примеров не вывел
технологию на этап коммерческой реализации. Nvidia первой
реализовала трансформацию и освещение в качестве архитектурных
преимуществ чипа, подарив GeForce 256 то самое конкурентное
преимущество и открыв для компании прежде скептически настроенный
профессиональный рынок.
И интерес профессионалов был вознагражден всего через месяц после
выхода геймерских видеокарт NVidia презентовала первые видеокарты
линейки Quadro модели SGI VPro V3 и VR3. Как можно догадаться из
названия, карты были разработаны с применением проприетарных
технологий компании SGI, договор с которой Nvidia заключила летом
1999 года. Иронично, что немного позже SGI пыталась отсудить у
Nvidia свои разработки, но потерпела неудачу, оказавшись на грани
банкротства.
Nvidia завершила последний финансовый год уходящего тысячелетия
ярко прибыль в размере $41.3 миллиона при общем обороте в $374.5
миллиона порадовала инвесторов. По сравнению с 1998 годом прибыль
выросла на порядок, а общие обороты более чем вдвое. Вишенкой на
торте для Дженсена Хуанга стал контракт с Microsoft на сумму $200
млн, в рамках которого NVidia разработала чип NV2 (графическое ядро
для будущей консоли Xbox), увеличив общие активы компании до $400
млн при выходе на биржу в апреле 2000 года.
Конечно, в сравнение с $1.2 миллиардами оборота и $156 миллионами
чистой прибыли ATI цифры набирающего обороты конкурента казались
скромными, но канадский производитель видеокарт не почивал на
лаврах, ведь щедрые контракты ОЕМ-рынка оказались под угрозой из-за
выхода прогрессивной интегрированной графики от Intel чипсета
815.
А впереди было падение великих. И начало новой эры в гонке за
производительностью.
Автор текста Александр Лис.
Продолжение следует...
Плейлист Графические войны на YouTube:








































































 Пример: ярлык игры Wolfenstein - Blade of Agony
Пример: ярлык игры Wolfenstein - Blade of Agony
 __NV_PRIME_RENDER_OFFLOAD=1
__GLX_VENDOR_LIBRARY_NAME=nvidia minecraft-launcher
__NV_PRIME_RENDER_OFFLOAD=1
__GLX_VENDOR_LIBRARY_NAME=nvidia minecraft-launcher











































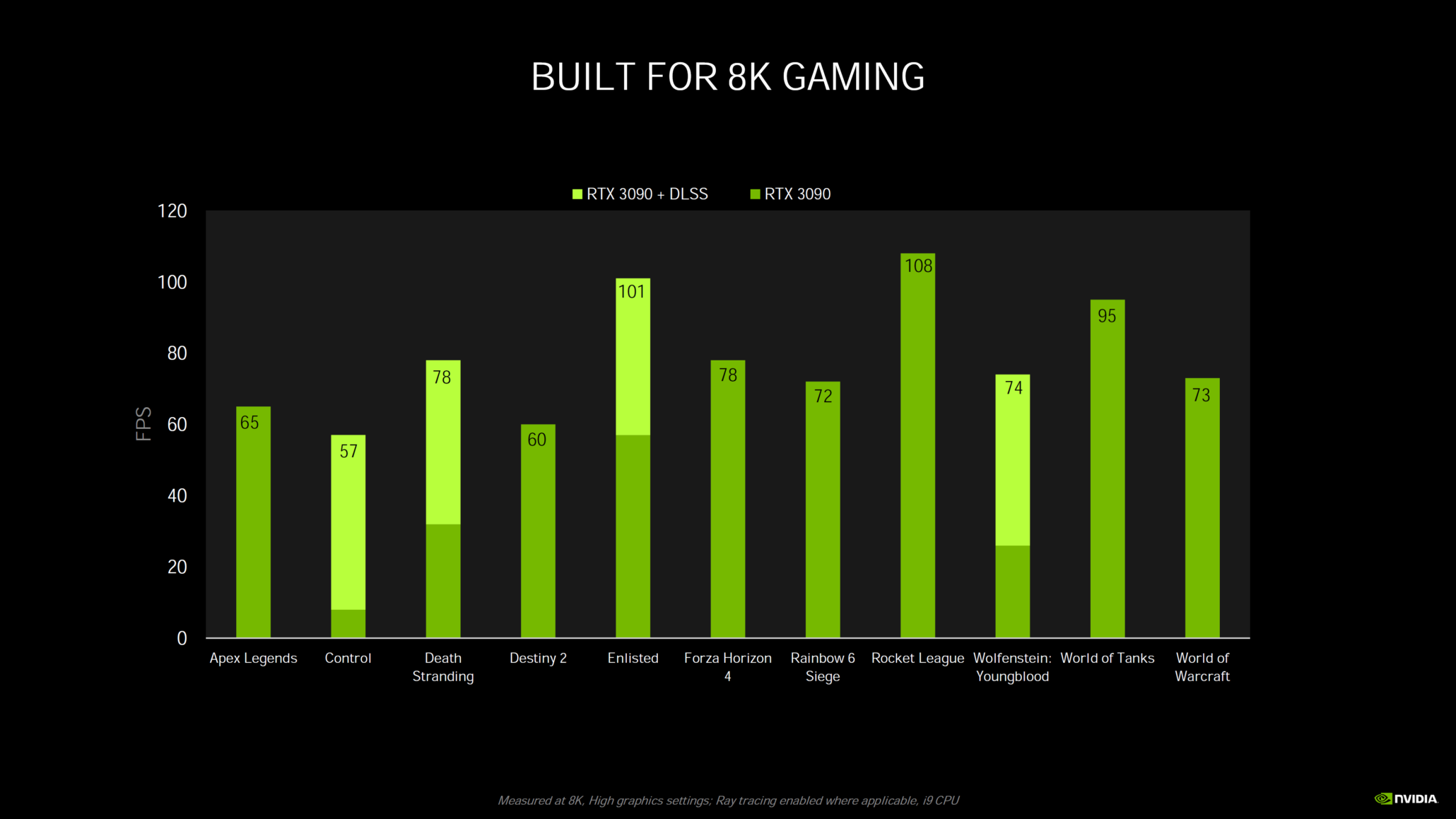


















 классификация изображения моделью на Jetson Nano 2GB
классификация изображения моделью на Jetson Nano 2GB














 Собранная на коленках видеостена на 8
мониторов средствами NVidia Quadro P620
Собранная на коленках видеостена на 8
мониторов средствами NVidia Quadro P620
 Установка 8 мониторов встроенными
средствами Windows 10
Установка 8 мониторов встроенными
средствами Windows 10
 Поворот верхних мониторов на 180 градусов
Поворот верхних мониторов на 180 градусов
 Поворот дисплея
Поворот дисплея
 Технология AMD Eyefinity
Технология AMD Eyefinity
 1 шаг - выбор топологии
1 шаг - выбор топологии
 2 шаг - выбираем дисплеи
2 шаг - выбираем дисплеи
 3 шаг -
расположение дисплеев
3 шаг -
расположение дисплеев



{kind=link}
{kind=link}