
Активность использования термина
"transistor" c 1800 года и до наших дней
Для принятия правильных решений в различных жизненных ситуациях
очень полезно иметь адекватную модель мира. В частности, бывает
полезна возможность сопоставить популярность различных предметов и
оценить динамику этой популярности. Например, вы издатель, и вам
предлагают перевести и издать книгу по языку программирования
Fortran. Его ведь всё ещё используют, издаётся англоязычная
литература, а у нас давно ничего не выходило. Или, скажем, по языку
Julia. Книжек по актуальной версии языка на русском ещё нет. Можно
взять какую-нибудь самую популярную английскую, перевести, издать и
сорвать куш. В подобных ситуациях полезно иметь возможность
подглядеть, какова популярность этих языков относительно других и
какова динамика этой популярности. Пример с языками
программирования приведён просто для наглядности, подобные задачи
возникают и при анализе популярности различных программ,
технологий, научных концепций.
Пример с языками программирования удобен ещё и потому, что для
них имеются различные официальные рейтинги. Этих рейтингов много,
они используют разные способы оценки популярности и естественно
дают различающиеся результаты. Эти результаты к тому же подвержены
достаточно сильному случайному дрейфу. Если посмотреть результаты
разных рейтингов на какую-то конкретную дату, то создаётся
впечатление, что мы ничего толком не знаем, и мир непостижим. Но
ситуация немного меняется, если рассмотреть всё в динамике. В
динамике становится видно, где дрейф, а где проглядывают какие-то
реальные закономерности.
Одним из способов составления рейтингов популярности является
анализ частоты поисковых запросов. Такой способ при всей его
кажущейся наивности, при разумном использовании позволяет получать
довольно устойчивые оценки. На этом, например, построен рейтинг
языков программирования PYPL. Рейтинг строится на основе
анализа запросов для поиска мануалов по тем или иным языкам. Но
никакой общепит не сравнится с авторской кухней. Иногда хочется
чего-то особенного, чего в существующих рейтингах может не быть.
Например, рейтинг PYPL не включает в себя Fortran. Да, этот язык
явно не лидер, хотя из других рейтингов известно, что он стабильно
входит в верхние 50 строчек по популярности. Не проблема.
Аналогичную картинку можно получить самостоятельно, не прибегая к
помощи сторонних агентств, используя инструмент Google Trends. Вот,
например, если посмотреть в динамике, можно увидеть хвост
популярности Fortran (синий) и для масштаба относительно
стабильный, хотя и немного снижающийся спрос на Matlab (красный). У
Matlab, кстати, отчётливо видны сезонные пики два раза в год. По
всей видимости перед зимней и весенней сессиями:

Глядя на такие картинки, невольно обращаешь внимание на левую
границу, глубже которой невозможно копнуть, а именно на 2004 год.
Поскольку анализируются запросы в Google, заглянуть в более древние
периоды истории с помощью этого инструмента не получится. А ведь
так любопытно взглянуть на период, когда Fortran был ещё на пике
популярности. Но увы, наша машина времени туда попасть не может.
Она была запущена на полную мощность только в 2004 году и все более
ранние периоды для неё закрыты.
Из-за отсутствия информации по каким-либо другим инструментам
ретроспективного поиска, я всегда думал, что возможность заглянуть
в более ранние периоды отсутствует. Но, как оказалось, такая
возможность имеется, причём инструмент предлагает всё та же
компания Google. Называется он Google Books Ngram Viewer. Это
инструмент статистического анализа информации, содержащейся в
массиве книг из Google Books. В некотором смысле это гениальное
решение, ведь печатные книги существуют уже несколько столетий, и
имея их полные оцифрованные тексты, вполне можно использовать их
как источник статистической информации о прошлых исторических
периодах. Теперь хотя бы понятно, зачем Google создал и
поддерживает проект Google Books. Общая цель здесь та же, что и
поиска, и у сервисов: владение информацией. Но, к счастью, с нами
готовы поделиться какой-то её частью.
Что предлагается:
Предлагается поисковая строка, куда нужно вводить запрос. Вводим
запрос получаем график популярности данного слова в книгах. Начиная
с 1800 (!!) года и до нашего времени. Поисковые запросы можно
вводить через запятую тогда мы получим несколько линий на графике,
соответствующих данным понятиям, и сможем оценить их динамику. Вот,
например, тот же Fortran:

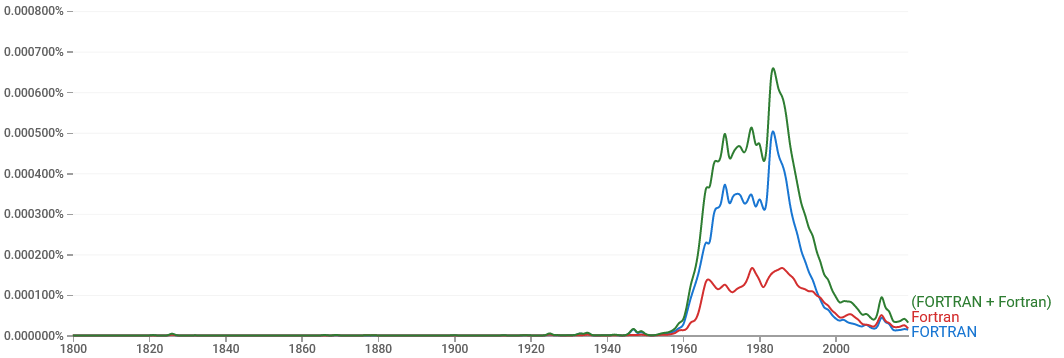
По умолчанию поиск чувствителен к регистру, то есть Fortran
(написание названия для современных версий языка) и FORTRAN
(написания названия для старых версий) это будут два разных слова.
Можно выключить чувствительность к регистру, либо использовать
арифметические выражения над введёнными поисковыми запросами, то
есть написать FORTRAN+Fortran:
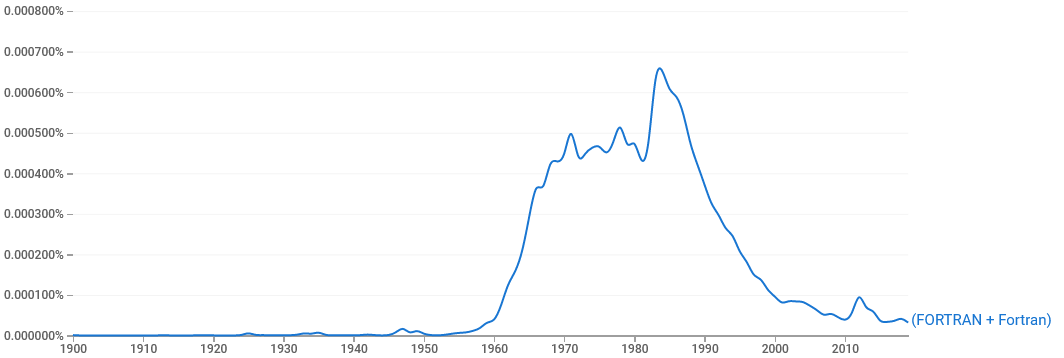
Инструмент статистический, не абсолютно точный, про это не стоит
забывать. Например, для того же Фортрана мы увидим какие-то
микровсплески ещё до публикации первой версии языка:
Также, как и упоминание о транзисторах ещё до их официального
появления:

Любопытно было бы иметь возможность увидеть эти аномальные
публикации, они могут представлять интерес. Но пока что такой
возможности не предусмотрено.
Если не придираться к деталям, а смотреть какие-то общие
тенденции, то в целом всё выглядит довольно реалистично. Например,
можно увидеть, как упоминание Fortran в литературе сменяется на
MATLAB:

Поскольку поиск по умолчанию выдаёт все вхождения заданного
слова, забота о корректном учёте синонимов лежит на пользователе. В
некоторых случаях провести такое разделение невозможно. Так,
например, поиск просто по слову chip очевидно выдаёт слишком много
случаев, когда слово употреблялось в других значениях, а поиск по
слову microchip, хотя и явно точнее, не учитывает всех вариаций
наименования предмета и не может использоваться для корректного
количественного сопоставления с другими сущностями:

Например, если мы решим таким образом сопоставить популярность в
литературе таких слов как Fortran+FORTRAN, MATLAB и Julia, то для
первых двух это явно будет название языка программирования, а в
последнем случае в первую очередь что-то совсем другое, включая
различные имена собственные:

В этой смеси выделить именно язык программирования Julia
проблематично. Введя дополнительное слово, мы сильно урежем
допустимые вариации его использования, а не вводя получим
неразделимую смесь. На данном этапе это неустранимое ограничение
данного сервиса. В будущем конечно хотелось бы иметь возможность
поиска понятий с учётом их смысла, примерно как в Google Trends.
Искренне надеюсь, что прямо сейчас ведётся работа в этом
направлении, просто результат ещё недостаточно хорош для
показа.
Но всё-таки, даже с учётом различающейся вариативности
контекстов сравниваемых слов, какую-то картину всё же можно
получить. Например, сравнивая выдачу по таким понятиям, как
electric, software и experiment мы увидим чёткую картину по
использованию понятия software, которое не применялось до середины
XX века, немного размытую картину по понятию electric поскольку оно
могло использоваться в различных смыслах и контекстах, вплоть до
художественной литературы, и примерно одинаковый уровень для
experiment. Видимо, эксперименты производили и обсуждали на
страницах книг с 1800 года и до наших дней с примерно одинаковой
частотой. В последние десятилетия даже чуть реже, чем раньше:

Гораздо более чёткую картину даёт использование уникальных
слов-маркеров, для которых известно, в связи с чем и в какое время
их могли употреблять, а в какое ещё не могли. Таким образом,
кстати, можно ещё и проверить адекватность выдачи. Вот пример для
Stalingrad, Sputnik и perestroyka:

Ну что же, все пики вроде бы на своих местах. Интереса к
перестройке в мировой литературе было явно меньше, чем к первым
запускам спутников Земли. Похоже на правду.
Если взять какие-то более размытые понятия, например, genetic и
neural, то даже несмотря на какой-то шум от возможного
использования этих слов в других смыслах, виден явный подъём с
середины XX века:

Интересно также оценить отражение вклада отдельных личностей в
совокупность мировых печатных материалов. Но получится это далеко
не со всеми деятелями, а только с имеющими какие-то необычные
фамилии и не имеющими других известных однофамильцев. Вот,
например, вклад Циолковского (одного из основоположников
космонавтики и выдающегося философа-космиста) и Вистелиуса
(основоположника математической геологии). Циолковский явно имеет
большую известность и цитируемость в западной литературе:

Но даже если взять какую-то уникальную персоналию, то выдача
будет зашумлена всем, что потом назвали в её честь. Вот пример по
ключевому слову Lomonosov:
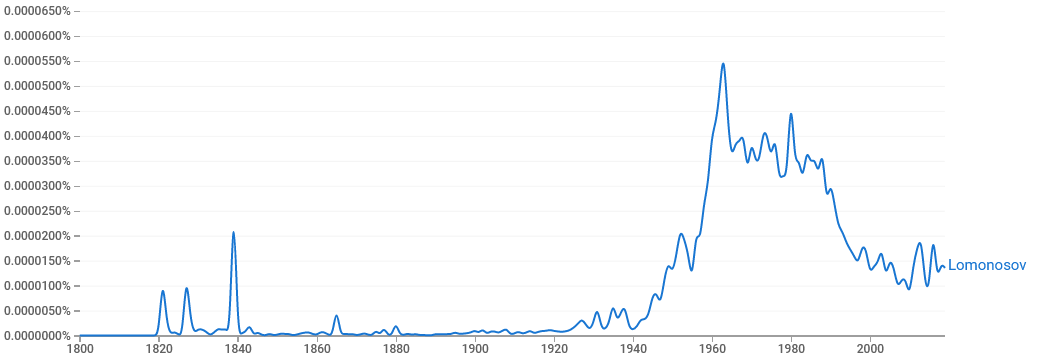
Явно в начале здесь вклад самого Михаила Васильевича (наверное,
какие-то ссылки на его работы), потом названного в честь него
университета, а потом ещё города и суперкомпьютера.
Для кириллических понятий можно осуществлять поиск по массиву
русскоязычной литературы, но поскольку в Google Books пока что не
очень большой её охват, а также есть риск, что распознавание текста
выполнено не настолько качественно, как и для англоязычной, данную
возможность пока скорее стоит рассматривать как демо-версию будущих
возможностей сервиса.
По настройкам:
Можно сужать период охвата, можно менять набор текстов, по
которым ведётся поиск, включать-выключать чувствительность
регистра, менять степень сглаживания графиков. Есть некоторые
выражения для поисковой строки, позволяющие реализовать некоторые
специальные приёмы при поиске, наподобие арифметических действий
над запросами. Есть и другие, они описаны на специальной странице.
Можно задавать только часть слова или искать по корням, учитывая
его различные формы, можно указывать, какой частью речи должно
являться искомое слово, осуществлять логические операции, чтобы
отфильтровывать что-то лишнее. В принципе, возможности сервиса
достаточны даже для каких-то лингвистических исследований,
например, для анализа изменений норм языка.
Какие на данный момент есть проблемы:
1) Не учитывается контекст запроса. С одной стороны это хорошо,
заставляет исследователя самого строить модель возможного
использования слова. Поиск идёт более осознанно. С другой стороны,
некоторые сущности без контекста разделить просто нельзя, то есть
сейчас некоторые операции анализа просто нельзя выполнить, так как
поиск по слову выдаёт неразделимую смесь нескольких понятий.
2) Нельзя перейти к конкретным текстам. И просто ради
любопытства, и для проверки качества распознавания и поиска было бы
интересно увидеть аномальные встречи заданного слова, когда его по
идее ещё не должно было возникнуть. Возвращаясь к тому же Фортрану
увидеть его упоминания до выхода первой версии.
3) Есть риск смещённости оценок из-за возможной неоднородности
охвата оцифрованной литературы. Например, если имеется
неоднородность по охвату различных областей знания, языков,
исторических периодов. Было бы интересно увидеть какое-то
процентное соотношение базы поиска к общей информации, хранимой в
данный момент всеми библиотеками.
4) В принципе невозможно искать неразделимые термины и
персоналии. Например, если будем искать по фамилии Толстой, то
очевидно встретим след как от Льва Толстого, так и от Алексея
Толстого, а также других выдающихся носителей этой фамилии. И
начиная с какой-то даты их уже невозможно будет разделить. Для
идеальной поисковой системы будущего, поисковая машина должна не
просто учитывать контекст, а понимать запрос.
Какие промежуточные выводы можно сделать:
1) Объекты с уникальными и неизменными именами гораздо проще
найти и оценить. Создавая новый язык программирования, программу
или какое-то другое произведение давайте ему уникальное имя и
старайтесь потом не менять.
2) Носители уникальных фамилий находятся в более выигрышном
положении в плане обнаружения их заслуг (и в проигрышном в плане
маскировки среди однофамильцев). Если у вас неоднозначно
записываемая фамилия, то чем раньше вы определитесь с её эталонным
написанием, тем проще будет потом найти ваши работы.
3) Практика наименования одного объекта в честь другого в
долгосрочной перспективе может приводить к сложности оценки вклада
как первого, так и второго. По крайней мере, при использовании
поисковых машин, не умеющих понимать контекст вопроса
На этом всё. Надеюсь, данная заметка была полезна. Инструмент
работает, и при осознанном использовании позволяет лучше понимать
мир и его динамику. При не очень осознанном использовании может
просто использоваться как игрушка. Но игрушка всё-таки развивающая.
Почему бы и нет.
В ходе работы пришла пара интересных мыслей:
1) Наверное, примерно так и должна быть устроена мировая
библиотека будущего. Фактически, это уже её прототип.
2) Сервис позволяет оценивать вклад отдельных понятий в общую
совокупность всех записанных человеческих текстов, то есть
фактически когда-либо высказанных мыслей представителей нашей
цивилизации. Но как назвать эту совокупность?























 Python не просто останется в топе еще
много лет, но и поднимется по позициям. Если мы говорим о России,
то это во многом обусловлено экономическими факторами. Люди поняли,
что их профессии уже не такие нужные, да и денег приносят не так
много. Поэтому многие начинают штурмовать IT-сферу и изучать
программирование. А Python имеет очень низкий порог входа из-за
простоты синтаксиса и, конечно же, сахара.
Python не просто останется в топе еще
много лет, но и поднимется по позициям. Если мы говорим о России,
то это во многом обусловлено экономическими факторами. Люди поняли,
что их профессии уже не такие нужные, да и денег приносят не так
много. Поэтому многие начинают штурмовать IT-сферу и изучать
программирование. А Python имеет очень низкий порог входа из-за
простоты синтаксиса и, конечно же, сахара.





