Введение. О чем эта статья.
Не так давно на Хабре я увидел статью с многообещающим названием
"Что из себя представляет класс Startup и Program.cs в ASP.NET
Core" (http://personeltest.ru/aways/habr.com/ru/company/otus/blog/542494/).
Меня всегда нтересовало и интересует, что именно происходит под
капотом той или иной библиотеки или фреймворка, с которыми мне
доводится работать. И к веб-приложениям на ASP.NET Core это
относится в полной мере. И я надеялся получить из этой статьи новую
информацию о том, как работают упомянутые классы при запуске такого
приложения. Та статья, к сожалению, меня разочаровала: в ней всего
лишь в очередной раз был пересказан кусок руководства, никакой
новой информации я оттуда не получил. И при чтении ее я подумал,
что, наверное, есть и другие люди, которым, как и мне, интересно не
просто знать, как применять тот или иной фреймворк (ASP.NET Core в
данном случае), но и как он работает. А так как я по разным
причинам последнее время довольно сильно углубился во внутреннее
устройство ASP.NET Core, то я подумал, что теперь мне есть много
что рассказать о нем из того, что выходит за рамки руководств. И
вот потому я решил для начала написать статью про то, что
действительно представляют из себя классы Startup и Program - так,
чтобы рассказать не столько о том, как ими пользоваться (это есть в
многочисленных руководствах, которые, как мне кажется, нет смысла
дублировать), а, в основном, о том, как работают эти классы, причем
- в контексте работы всего веб-приложения на ASP.NET Core. Однако
поскольку необъятное объять нельзя, то предмет этот статьи
ограничен. Прежде всего, она ограничивается рассказом только про
веб-приложения, созданные с использованием нового типа шаблона
приложения - Generic Host. Во-вторых, статья будет посвящена только
тому, как происходит инициализация веб-приложения, потому что
основная роль рассматриваемых классов именно такова - инициализация
и запуск размещенного приложения. Итак, кому рассматриваемая тема,
даже в столь ограниченном объеме, интересна - добро пожаловать под
кат.
Введение. Продолжение.
Для начала немного расширю вводную часть статьи - потому что до
ката поместилось не все, про что хотелось там написать. Но, прежде
всего - краткое содержание статьи (под спойлером):
TL;DR
(сразу предупреждаю: тут - далеко не всё).
Инициализация приложения, сделанного по шаблону Generic Host
выглядит следующим образом.
-
Создается объект построителя размещения (Host), реализующий
интерфейс IHostBuilder
-
Затем выполняется стадия конфигурирования, на которой
производится конфигурирование компонентов приложения - либо путем
вызовов методов интерфейса IHostBuilder напрямую, либо путем вызова
методов расширения для этого интерфейса - статических методов,
определенных в других классах. Эти методы расширения, как правило,
производят конфигурирование вызовами все тех же методов интерфейса
IHostBuilder.
-
Конфигурирование производится путем передачи в методы интерфейса
IHostBuilder процедур-делегатов. Эти делегаты помещаются в очередь
соответсвующего этапа, для которого они переданы (этап определяется
именем вызываемого для этого метода IHostBuilder). Они будут
выполнены впоследствии на соответствующих этапах построения объекта
приложения Generic Host (иначе - размещения, Host).
-
После стадии конфигурирования производится создание объекта
размещения (приложения), реализующего интерфейс IHost, оно
производится вызовом метода Build интерфейса IHostBuilder
построителя.
-
Создание объекта размещения в реализации по умолчанию
производится построителям в несколько этапов. Эти этапы : создание
конфигурации построителя, создание объектов окружения, создание
конфигурации приложения, создание контейнера сервисов, включая
сервисы параметров (options). После создания контейнера сервисов
построитель извлекает из него реализацию интерфейса IHost и
возвращает как результат вызова метода Build.
-
На ряде этапов происходит вызов на выполнение делегатов,
переданных построителю на этапе конфигурирования и хранящихся в
очередях. Список этих этапов: этап создания конфигурации
построителя; этап создания конфигурации приложения; подэтап
конфигурирования списка регистрации сервисов этапа создания
контейнера сервисов; подэтап конфигурирования
контейнера-построителя этапа создания контейнера сервисов.
-
После создания объекта приложения он запускается, что в конечно
итоге приводит к запуску метода StartAsync реализации интерфейса
IHost. В реализации по умолчанию этот метод выбирает из контейнера
сервисов все зарегистрированные компоненты приложения - реализации
интерфейса IHostedService - и асинхронно запускает их методы
StartAsync. Эти методы могут выполнять инициализацию, зависящую от
конкретного компонента приложения.
На этом предмет рассмотрения данной статьи заканчивается.
Далее, поскольку статья получилось многословной, решено было
часть материала убрать с видного места, под спойлеры. Основных
видов спойлеров в статье два, вот их описания:
Лирическое отступление: о лирических отступлениях вообще
Когда я читал код ASP.NET Core - написанный в весьма непривычном
для меня стиле - я много думал, много разного. Но в этой статье я
постарался оставить все эти мысли о коде при себе, и описать в
основной части статьи все максимально кратко и по существу того,
что происходит в коде, что и как в нем делается - а не что я думаю
при прочтении соответствующего фрагмента кода. В конце концов,
именно информация о работе программы - это то основное, что, как я
полагаю, хотят увидеть читатели этой статьи. А все свои мысли по
поводу виденного, которые мне сдержать не удалось, я убрал под
спойлер с пометкой "Лирическое отступление", отдельно от описания
работы кода. Так что те читатели, кому мое личное мнение не кажется
интересным, могут вообще не открывать соответствующие куски: там
действительно нет никакой информации о работе фреймворка ASP.NET. И
ещё: я прошу не обсуждать это мое личное мнение в комментариях к
этой статье - я не считаю его настолько ценным, чтобы тратить на
это время тех, кому нужна, прежде всего, информация по
рассматриваемой теме (включая мое время, кстати). А обсуждать в
комментариях прошу только тему самой статьи: прояснять и уточнять,
как происходит инициализация веб-приложения, созданного по шаблону
Generic Host, насколько удачна и понята терминология и т.д. Если же
мое личное мнение о современно программировании вдруг окажется
интересным более-менее заметной доле читателей - я готов изложить
его для них в отдельной статье: там можно будет сделать это более
систематично и подробно, и там можно обсудить его в комментариях,
не отвлекая тех, кто пришел за информацией о продукте, а не за моим
мнением.
детали реализации: описание убрано под спойлер
Разбираясь с работой кода, мне неизбежно приходилось вникать в
самые детали: какой метод и откуда вызывается, где хранится
используемое значение и откуда оно в это место попало, конкретный
способ реализации в целом понятной возможности - как и почему он
работает... Такие детали вряд ли стоило сохранять в основной канве
изложения - с ними из-за деревьев не будет видно леса - но терять
информацию о них тоже не хотелось: знание имен конкретных
переменных и методов может помочь при отладке, способы реализации
могут быть весьма нетривиальны и т.д. В качестве компромиса я вынес
всю такую информацию в спойлер с пометкой "детали реализации". И
при первом (или единственном) прочтении статьи эти детали можно
смело (я надеюсь) опускать как несущественные для понимания общей
картины.
Вернемся однако к содержанию статьи. Для начала хочется сказать
о коде ASP.NET Core в целом. Не знаю как для других, а для меня
стиль написания этого кода оказался весьма непривычен. Уже при
первом взгляде на файлы исходного текста, которые нам любезно
генерирует мастер создания нового проекта в Visual Studio видно,
что программы на ASP.NET Core принято писать в "современном,
модном, молодежном" стиле. И более глубокое рассмотрение самих
исходных текстов ASP.NET Core это подтверждает.
Лирическое отступление: О современных приемах написания кода
Однако, продолжу: мое внимание не могло не пройти мимо того
факта, что в ASP.NET Core широко используются такие новаторские
современные (и не очень) приемы написания кода, как объединение
вызовов методов в цепочку через точку, методы расширения
классов/интерфейсов, определенные в других классах, новые
модификации синтаксиса, позволяющие писать код сокращенно
("синтаксический сахар"), вложенные функции, стрелочные (они же -
лямбда-)функции (в том числе - и для написания обычных методов, и с
фигурными скобками, и с вызовом других лямбда-функций внутри
лямбда-функций), передача переменных в эти вложенные методы и
лямбда-функции через автоматически генерируемые компилятором
замыкания, в том числе - и при создании делегатов, запоминаемых в
свойствах других объектов, широкое применение ключевого слова var,
позволяющего компилятору (и читающему код - тоже) самому
догадываться о типах определенных таким образом переменных, не
менее широкое применение делегатов для задания значений
полей/свойств объектов вместо простого присвоения этим
полям/свойствам - короче целый арсенал приемов, ранее не
используемых в C#. Да, я понимаю, что все эти приемы очень ценны, и
особенно - в плане повышения продуктивности программиста при
написании кода путем экономии количества знаков, необходимых для
первоначальной записи программы ;-). Но конкретно мне (почему-то)
читать такой код оказалось не всегда просто.
А ещё, разбираясь с исходным кодом ASP.NET, я узнал много новых
приемов для написания кода в духе настоящих программистов - приемов
ничуть не менее эффективных ;-) , чем освященные временем операторы
GOTO и циклы DO на 5 страницах из арсенала настоящих программистов
древности. И, вообще-то, я надеюсь опубликовать статью, как можно
пользоваться этими приемами для написания действительно сложной для
понимания программы, не навлекая на себя при этом обвинений в
нарушении принципов чистоты кода и других современных верований о
том, как надлежит писать программы, из которой многие, надеюсь,
подчерпнут для себя знания этих приемов ;-) (как, надеюсь, все
поняли из вышенаписанного, статья планируется несерьезной - ну, или
наполовину серьезной). Но вернемся к рассматриваемому вопросу.
Важная особенность кода ASP.NET Core, в целом, и шаблона Generic
Host, в частности - широкое использование модного современного
подхода (да, я специально его не называю тут по имени, почему - см.
лирическое отступление), в котором написанный программистом код
работает с некими интерфейсами, получаемые тем или иным методом из
специального объекта фреймворка - контейнера сервисов.
Лирическое отступление: что тебе в имени моем
Тем, кого учили теории, придут по поводу этого подхода в голову
какие-нибудь умные слова, которым их научили - типа "принцип
инверсии зависимостей". И вспомнится буква D в слове "SOLID". А то
и другие умные слова вспомнятся: "инверсия управления", "внедрение
зависимостей". Но по моему личному мнению без упоминания этих слов
вполне можно обойтись - они не дают ничего для понимания работы
конкретной программы. И вообще, говорят, что настоящим
программистам не требуются абстрактные концепции, чтобы делать
конкретную работу:в те древние времена, про которые была написана
статья о настоящих программистах, откуда взяты эти слова, им для
этого, якобы, требовался компилятор с Фортрана и пиво, а что
требуется для этого настоящим программистам сейчас - об этом я не в
курсе: я программист ненастоящий. Но про все эти умные слова и про
все, якобы, предоставляемые ими преимущества я тут писать не буду -
я просто буду описывать все ровно так, как оно есть в коде, без
приплетания сюда абстрактных понятий. Надеюсь, настоящим
программистам это понравится. Так что вернемся к нашим баранам.
Эти интерфейсы суть наборы методов с известными сигнатурами
(параметрами вызова и типом возвращаемого значения) и свойств
известного типа. Информация же о классах, которые реально
обеспечивают работу этих интерфейсов, может быть запрятана при этом
весьма далеко.
А эта информация на практике может оказаться весьма полезной.
Лирическое отступление: попробуй найди
Да, я слышал, что у этого подхода с сокрытием реализации
интерфейсов есть многочисленные достоинства. Но и неудобства такой
подход тоже создает: потому что зачастую сложно понять, какой код
здесь выполняется, а ведь именно код является самой точной
спецификацией программы - спецификации из документации не всегда
полны/точны/бывают правильно поняты - а потому возоможность
посмотреть конкретный код - она IMHO не лишняя. И IDE, которая
помогает справляться со многими неясностями, в этом случае мало
может подсказать, что стоит за этими интерфейсами: потому что путем
статического анализа невозможно определить, какой именно код, в
каком именно классе, в каком именно файле исходного текста
находящийся, будет реализовывать эти интерфейсы, их методы и
свойства. Это в немалой степени затрудняет, на мой взгляд,
использование исходного текста фреймворка для выяснения точного
поведения этого кода (что иногда бывает реально надо, особенно -
при отладке).
И потому одной из задач данной статьи я считаю как раз
прояснение вопроса, какие именно классы стоят за теми или иными
интерфейсами в процессе выполнения приложения ASP.NET, и как именно
они эти интерфейсы реализуют.
Конечно, реальная жизнь есть реальная жизнь, и разработчикам
ASP.NET в некоторых местах пришлось-таки написать код так, чтобы он
учитывал, какой каким именно классом реализуется интерфейс, который
используется данным кодом, и менять на основе этого знания путь
выполнения программы Но сделано это было весьма изящно и тоже в
рамках того же подхода "используй интерфейсы вместо классов": код в
таких местах проверяет, реализует ли объект, который стоит за
используемым интерфейсом, некий другой интерфейс, и в зависимости
от этого использует разные пути выполнения. Конкретно про это будет
рассказано при рассмотрении соответствующих частей кода во второй
части статьи.
Далее стоит упомянуть, что исторически для ASP.NET, кроме
Generic Host существует другой, более старый тип шаблона
веб-приложения: Web Host. Хотя производителем (Microsoft) он в
рассматриваемой в статье версии ASP.NET Core (статья писалась
изначально по версии 3.1.8) объявлен нежелательным для
использования в новых проектах, но он все ещё поддерживается. Эти
шаблоны приложения внешне весьма сходны, но в их реализации, тем не
менее, есть весьма существенные отличия, рассмотрение которых
заметно бы увеличило объем и так неслабо разросшейся статьи.
Поэтому решено было рассмотреть в статье только реализацию шаблона
Generic Host. Далее, ни работа веб-приложения, ни компоненты
(Middleware), которые могут использоваться в его работе, в этой
статье рассматриваться не будут по той же самой причине: необъятное
объять нельзя.
Также очень кратко, только в объеме, необходимом для понимания
процесса инициализации размещения (объекта, реализующего интерфейс
IHost), будут рассмотрены инициализация и работа общесистемных
компонентов .NET Core, таких как упомянутый выше контейнер сервисов
(он же - контейнер внедрения зависимостей, DI Container),
конфигурация (Configuration), параметры (Options).
И последнее, что нужно сказать во введении - про терминологию.
Везде, где возможно, в статье использована русскоязычная
терминология. Причем, по возможности - сделанная без помощи
транслитерации, потому как шедевры транслитерации такие, как
"континуация таски" (выкопано в одной прошлогодней статье на Хабре)
весьма неприятно царапают мое эстетическое чувство. Однако,
поскольку для немалого числа понятий в рассматриваемой области
русскоязычная терминология, как минимум, не устоялась (а то и вовсе
отсутствует), я, во-первых, допускаю, что использованный мной
вариант может быть неудачным (или не самым удачным), а потому готов
прислушиваться к комментариям об удачности терминов и о возможных
альтернативах, а во-вторых, по той же причине отсутствия
общепринятой русскоязычной терминологии, и чтобы в любом случае
сохранить однозначность понимания, русскоязычные термины в этой
статье будут дополняться их англоязычными эквивалентами - или
терминами, или названиями классов - везде, где это уместно, по
крайней мере - при первом их использовании. Ну, и некоторые
понятия, вроде Middleware, для которых мне не удалось найти
адекватный (в контексте их использования в ASP.NET) перевод, так и
оставлены на языке оригинала.
На первый взгляд...
Итак, начнем с начала - с начала выполнения программы. Как
известно, наверное, уже всем, выполнение программы ASP.NET
начинается с определенного в файле program.cs класса Program, с его
метода Main. И самый первый взгляд на этот файл, сгенерированный
мастером создания нового проекта в Visual Studio, подсказывает нам,
что приложение выполняется в две стадии. Сначала следует стадия
настройки, производимая в шаблоне автоматически генерируемым
отдельным методом CreateHostBuilder: создается вызовом статического
метода CreateDefaultBuilder класса Microsoft.Extension.Hosting.Host
экземпляр класса, реализующего интерфейс IHostBuilder (с
добавленными к нему настройками по умолчанию), а затем с помощью
методов IHostBuilder и многочисленных методов расширения
IHostBuilder (специфических для различных компонентов приложения),
указывается, какие компоненты, и с какими настройками будут
использоваться. Отдельный метод CreateHostBuilder с этим именем
нужен, как сказано в документации, чтобы средства разработки для
ORM Entity Framework Core могли найти контекст подключения к БД
(DbContext), с которым должно работать разрабатываемое приложение
(в данной статье про это ничего не будет). Затем, уже в методе
Main, вызовом метода IHostBuilder.Build создается объект,
реализующий интерфейс IHost. И, наконец, приложение запускается на
выполнение одним из методов интерфейса IHost или методов его
расширения: в сгенерированном мастером файле используется метод
расширения Run, запускающий приложение на выполнение и ожидающий
его завершения, но есть и другие, альтернативные методы. Так все
выглядит на первый взгляд - легко и просто.
Лирическое отступление: а как же теория?
Знатоки теории могут попытаться натянуть на описанную
архитектуру какой-нибудь шаблон проектирования. Я, например,
встречал мнения, что ASP.NET Core реализует шаблон "Построитель"
(Builder pattern). Но, IMHO лучше забыть теорию, а рассматривать
все так, как оно реализовано в натуре (именно об этом будет
рассказано дальше, и в подробностях). А в теоретические рассуждения
- типа, что Builder pattern плохо совместим с Dependency Injection
(тот самй упомянутый выше модный современный подход), которое очень
глубоко внедрено в код ASP.NET Core - я вдаваться не собираюсь. Но
вернемся к нашим баранам.
Однако при более пристальном расмотрении все оказывается не так
просто. Дело в том, что для конфигурирования веб-приложения в
данном фреймворке нельзя просто взять и указать список использумых
компонентов и их параметров и задать их настройки любым
декларативным способом (константами/переменными/параметрами
конфигурации),
а в приложение добавитьтолько тот код, который будет делать нечто
специфичное именно для приложения. То тут, то там мы видим
использование для конфигурирования компонентов фреймворка каких-то
дополнительных блоков кода , передаваемых в виде делегатов (обычно
- оформленных в виде лямбда-выражений) в вызовы каких-то
методов.
Первый такой делегат встречает нас сразу же в сгенерированном
мастером шаблоне простейшего веб-приложения: он используется в
методе конфигурирования ConfigureWebHostDefaults для указания типа
нашего класса инициализации веб-приложения, условно называемого
Startup (этот класс, вообще-то, может иметь произвольное имя,
поэтому дальше, чтобы не забывать этот факт, я буду называть его
Startup-классом).
Т.е. в метод конфигурирования в качестве аргумента передается
почему-то не просто тип Startup-класса, а некий блок кода, делегат,
указывающий тип Startup-класса с помощью какого-то неочевидного
соглашения: в виде лямбда-выражения, вызывающего для передаваемого
в него параметра некий его обобщенный метод, специализированный
типом нашего Startup-класса. А как это соглашение работает, и
почему нельзя было передать в метод конфигурирования просто тип
Startup-класса в качестве аргумента - это остается загадкой.
Лирическое отступление: о типах параметров лямбда-выражений.
Параметр ConfigureWebHost, при этом, как и положено правильно
написанного в целях повышения сложности кода параметру
лямбда-выражения, имеет неведомый нам тип. Впрочем, IDE(сразу) или
документация (если ее все же прочесть) тут слегка помогут: они
покажут, что тип этого параметра (он является интерфейсом)
называется IWebHostBuilder. Но вот какой класс за этим интерфейсом
прячется - все равно не покажут. Но я про то, что это за класс,
дальше, во второй части статьи, обязательно расскажу - это очень
интересный и нетривиальный класс.
Если же начать добавлять ещё компоненты, то трудно будет
обойтись уже и без вложенных лямбда-выражений - выражений, внутри
которых вызывается какой-нибудь метод, которому в качестве
аргумента тоже передается делегат в виде лямбда-выражения.
В документации причины использование именно такого способа
передачи конфигурационной информации не объяснены никак. То, что
этот делегат где-то в процессе построения приложения вызывается и
выполняется - это очевидно
На самом деле, нет
С появлением (ещё в незапамятные времена - в .NET Framework 3.5)
поддержки деревьев выражений (Expression Trees) делегат может быть
преобразован в такое дерево и использован внутри приложения
каким-нибудь другим образом, кроме выполнения его кода. Но в коде
конфигурирования и построения веб-приложений, который тут
рассматривается, это, насколько я заметил, нигде не используется.
Так что в этой статье можно смело писать "очевидно" ;-) .
Но где, в какой момент, и в каких условиях это происходит -
документация нам про это не рассказывает. В основном, документация
по этапу конфигурирования и построения приложения ASP.NET Core
является сборником рецептов "как сделать", а не описанием "как это
работает".
Лирическое отступление: заклинательное программирование
В результате типичное описание инициализации фреймворка
превращается в некую форму декларативного программирования: для
получения нужного приложения записывается набор пожеланий о том,
что программист хочет получить на выходе. Правда, назвать это чисто
декларативным программированием сложно: описание желаемого
результата записывается на весьма необычном языке, включающем в
себя вполне императивные конструкции внутри лямбда-выражений и даже
полноценные методы (в Startup-классе, например). Но, в целом,
описание по своей сути вполне декларативно: все эти императивно
выглядящие конструкции типовой программист обычно тщательно
переписывает из документации (или со StackOverflow и т.п.), изменяя
в них, разве что, имена переменных. Получаются своего рода такие
усложненные декларации. Я такой подход называю "заклинательным
программированием": подобно магу, программист создает
программу-заклинание, используя таинственные слова, точный смысл
которых ему неведом, лишь вплетая в заклинание небольшие свои
кусочки, чтобы добиться желаемого. И, подобно магу, программист не
знает, как и почему заклинание будет выполнено - но уверен, что
если не допущено ошибок, то оно обязательно сработает - и оно
действительно ведь срабатывает! Подход этот древний (но, конечно,
менее древний, чем магия): я видел людей, его использующих, ещё
студентом, работая ещё на электронно-вычислительной машине (ЭВМ), а
не на компьютере. У одного из таких людей (кстати, вполне неплохого
прикладного программиста) была по этому поводу любимая присказка:
"что бы такого ей (то есть ЭВМ) сказать". Причем, это явно были не
первые люди, кто такой подход использовал. Лично я такой подход не
люблю: мне всегда хочется не то, чтобы докопаться до первооснов,
но, по крайней мере, иметь в голове модель того, что происходит. И
это, кстати, послужило одной из причин, почему я стал разбираться в
том материале, который вошел в эту статью.
Раскрываем тайны: этапы большого пути
Но хватит, наверное, нагнетать таинственность, а пора переходить
непосредственно к рассмотрению того, как происходит процесс
инициализации в шаблоне Generic Host, и почему процедура
конфигурирования устроена так, как она устроена.
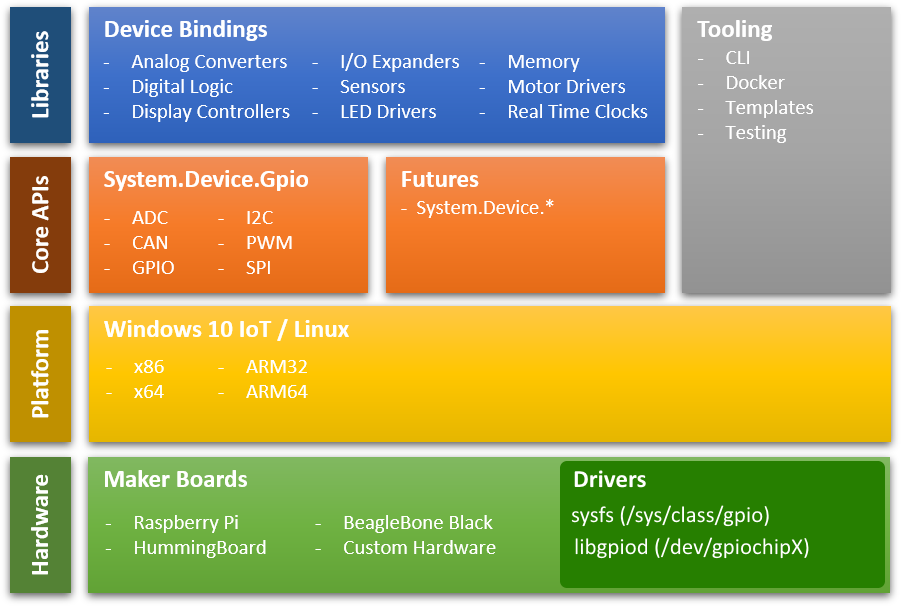
Общая схема процесса инициализации схематически изображена на
рисунке ниже:

Рис. 1. Схема процесса инициализации Generic
HostУсловные обозначения на рисунках
Рисунки-cхемы - эта, единственная в первой части, и ещё
несколько во второй части - не являются формализованными
диаграммами, а служат только для иллюстрации. Поэтому объекты на
них изображены с некоторой степнью вольности, без строгой
формализации. Но, тем не менее, специфичческий смысл у разных форм
графических элементов присутствует. Прямоугольные элементы со
сплошниыми границами обозначают блоки кода - как реализации методов
классов, так и делегаты. Прямоугольныики со скругленными границами
обозначают объекты. Элементы с штриховыми границами - элементы
данных: свойства объектов и данные, передаваемые методам. Маленькие
кружки на выносных линиях обозначают методы и свойства интерфейсов
и классов. Сплошные линии со стрелками - направления, в которых
идет выполнение кода. Штриховые линии со стрелками - передача
данных в методы/свойства (а делегаты, передаваемые в методы в
качестве данных, обозначены прямоугольниками в штриховых кругах).
Штрих-пунктирные линии с пустотелыми стрелками на конце обозначают
создание экземпляров объектов.
В изображенном на рисунке типичном процессе инициализации
статический метод Host.CreateHostBuilder сначала создает объект
построителя, реализующий интерфейс IHostBuilder. Затем для этого
интерфейса в процессе конфигурирования вызываются (условные)
присоединенные методы этого интерфейса для конфигурирования
компонетов AddFeature1..AddFeatureN. В процессе конфигурирования
присоединенные методы вызывают методы интерфейса IHostBuilder для
регистрации делегатов, которые будут фактически выполнять
конфигурирование при вызове метода Build. После окончания
конфигурирования программа вызывает метод Build созданного объекта
построителя, который выполняет конфигурирование. В результате этого
вызова программа получает ссылку на интерфейс IHost объекта
приложения (оно же - размещение, Host) и вызывает метод StartAsync
этого интерфейса для запуска приложения.
Реализацией интерфейса IHostBuilder, которую создает метод
CreateDefaultBuilder (статический, определен в классе
Microsoft.Extensions.Hosting.Host), является класс
Microsoft.Extensions.Hosting.HostBuilder(далее я буду называть его
построителем, а чтобы избегать путаницы с переводом - параллельно
использовать английское название интерфейса IHostBuilder). После
создания построителя метод CreateDefaultBuilder добавляет в него
ряд делегатов, создающих настройки по умолчанию (подробности см. в
документации). Если же вам по какой-то причине эти настройки по
умолчанию не нужны - вы имеете полное право создать объект
построителя самостоятельно, с помощью оператора new, и
конфигурировать его как угодно, что называется, "с чистого
листа".
О значениях по умолчанию, фиксированных константах и т.п.
Все такие вещи довольно подробно описаны и в документации, и в
многочисленных руководствах, копирующих куски из документации с
небольшими изменениями. И, так как объем статьи ограничен, я не
вижу смысла тратить его ещё и на эти, многократно описанные вещи,
которые часто вполне можно опустить без ущерба для связности
изложения. Поэтому по их поводу везде далее будет написано кратко:
"см. документацию". Потому что моя цель - сообщить оригинальную
информацию. Но вот там, где без этих сведений из документации
обойтись нельзя - страдает либо понимание, либо связность изложения
- там я, конечно, могу и сдублировать такие сведения.
Теперь рассмотрим метод Build. Просмотр исходного кода класса
построителя показывает, что создание объекта класса, реализующего
интерфейс IHost (далее я буду называть его словом "размещение")
происходит в этом методе в несколько четко определенных этапов.
Отступление - о терминологии
В англоязычной документации этот объект называется Host, но это
слово сложно адекватно перевести на русский язык. Используемый
самой Microsoft перевод "узел" и смысл не раскрывает, и к путанице
может привести - слово "node" тоже переводится как "узел", и его
смысл такой перевод передает куда точнее. По-русски точнее всего по
смыслу было бы перевести Host в контексте этой статьи примерно как
"разместитель", но это слово явно "не звучит". Другой более-менее
точный перевод - "размещение" - не передает тот факт, что этот
объект играет активную роль, а не просто является вместилищем
чего-то. Но за неимением лучшего буду использовать его.
Для использования на некоторых из этапов конфигурирования
действий, задаваемых пользователем фреймворка - тех самых
"загадочных" лямбда-выражений - в этом классе определены (и
создаются в конструкторе) поля, содержащие списки действий,
специфичных для этапа. Эти поля представляют собой экземпляры
обобщенного класса List<>, специализированные нужным типом
делегата,
детали реализации: списки делегатов
или (для одного из этапов) - интерфейса, реализованного
вспомогательным классом, создаваемым на базе делегата (причина,
почему так сделано, будет объяснена при описании этапа).
Далее я буду называть эти списки очередями, поскольку они
используются именно как очереди: элементы добавляются в них
последовательно, в конец списка, а на соответствующих этапах
конфигурирования действия с содержащимися в них элементами также
производятся последовательно, от первого элемента к последнему. На
рис.1 очереди изображены в виде штриховых трапеций ("корзин"), и
внутри них условно нарисованы находящиеся в них делегаты: стопки
сплошных прямоугольников. Для добавления делегатов в каждую из
очередей существует собственный метод, определенный в интерфейсе
IHostBuilder и реализованный в классе построителя. На рис.1 он
помечен линией с кружком вначале и стрелкой на конце, указывающей
на соответствующую очередь. Конкретно о каждом поле-очереди и о
соответствующем методе для добавления в него делегатов будет
рассказано при описании того этапа построения, на которых они
используются.
детали реализации: другие методы IHostBuilder
Для полноты описания методов IHostBuilder, но забегая немного
вперед. Еще один метод интерфейса IHostBuilder,
UseServiceProviderFactory (имеющий две перегруженных формы)
используется для указания объекта-фабрики, создающего один из
ключевых компонентов - контейнер сервисов приложения, реализующий
интерфейс IServiceProvider. Об использовании объекта фабрики для
его создания будет рассказано ниже при описании стадии создания
этого компонента. Ну и, кроме того, в интерфейсе IHostBuilder
определено (а в классе построителя, соответственно, реализовано)
свойство-словарь Properties(типа IDictionary<object,object>),
которое можно использовать для передачи произвольных значений между
несколькими делегатами, конфигурирующими один и тот же компонент (в
том числе - и делегатами, выполняющимися на разных этапах). Более
того, содержимое этого свойства будет доступно и на этапе
выполнения, где интерфейс IHostBuilder уже недоступен. А доступно
оно будет через контейнер сервисов (например, путем внедрения
зависимостей): ссылка на этот словарь будет помещена в объект
HostBuilderContext, который будет зарегистрирован в контейнере
сервисов как реализация сервиса для своего собственного типа -
естественно (иначе не получится), с постоянным (Singleton) временем
жизни.
Конфигурирование конкретных компонентов приложения производится
обычно методами-расширениями интерфейса IHostBuilder. Эти методы
обычно содержат вызовы нескольких разных методов интерфейса
IHostBuilder для согласованного конфигурирования всех частей
компонента. Поскольку эти компоненты в этой статье сколь-нибудь
подробно рассматриваться не будут, то и большинство таких
методов-расширений тоже останутся без рассмотрения.
Ключевые компоненты Generic Host
Теперь, прежде чем двигаться дальше, нужно вкратце рассмотреть
те ключевые компоненты, которые создаются в процессе построения
приложения на базе шаблона Generic Host
Первый рассматриваемый ключевой компонент ASP.NET Core (и .NET
Core в целом) - это конфигурация, представляемая интерфейсом
IConfiguration Конфигурация в .NET Core делает для приложения
доступным набор строк-ключей, которым сопоставлены строки-значения,
получаемых от различных поставщиков.
детали реализации: перечисление того, что умеет конфигурация
В качестве поставщиков конфигурации (все они представлены
объектами, реализующими интерфейс IConfigurationProvider) .NET Core
может использовать довольно разнообразные объекты: переменные среды
(environment), параметры командной строки, файлы различных
форматов... Имеется возможность использовать дополнительные
поставщики конфигурации, создавая собственные реализации интерфейса
IConfigurationProvider. Можно изменять значения ключей и добавлять
новые ключи - однако эти изменения остаются только в пределах
выполняющейся программы: существующие поставщики конфигурации на
основе постоянных объектов (таких, как файлы) эти изменения в
представляемых ими постоянных объектах не фиксируют. Конфигурация
поддерживают возможность получения оповещений об изменениях в
объектах, доступных через поставщики конфигурации (например, после
редактирования файла конфигурации), повторной загрузки изменившейся
части конфигурации и оповещения об изменении объектов, которые
используют эту конфигурацию. Ключи конфигурации образуют
иерархическое пространство имен - т.е. могут быть составными:
состоять из нескольких компонентов разделенных знаком
двоеточия-имен разделов, после которых находится имя значения. Есть
возможность выделять ключи, принадлежащие одному разделу, в
отдельные объекты разделов конфигурации, реализующие свою,
ограниченную разделом, IConfiguration. Из объекта конфигурации
(обычно - из одного из разделов) можно получать значения для
экземпляров объектов: свойства объектов при этом заполняются на
основе одноименных значений из конфигурации, преобразованных к
нужному типу: это называется привязкой (Bind) конфигурации.
Предметом же данной статьи является процесс создания
конфигурации. Он происходит следующим образом: сначала в
специальный объект-построитель с интерфейсом IConfigurationBuilder
добавляются его методами источники конфигурации - объекты с
интерфейсом IConfigurationSource. А после указания всех нужных
объектов-источников конфигурации методом Build построителя
конфигурации производится создание конфигурации - объекта с
интерфейсом IConfiguration. Процессы добавления источников
конфигурации в объект-построитель конфигурации и создания из него
конфигурации детально описаны ниже, при описании соответствующих
этапов инициализации приложения.
Следующий по порядку создания, но, наверное, первый по важности
ключевой компонент ASP.NET Core и .NET Core - это контейнер
сервисов: объект реализующий интерфейс IServiceProvider. Именно
этот объект в большинстве случаев предоставляет реализации тех
самых интерфейсов, который обычно используются и в коде фреймворка,
и в модулях, реализующих функциональность конкретного приложения.
Сервисы, которые должен предоставлять контейнер сервисов -
определяются типами интерфейсов или, реже, классов, которые
требуются коду. Контейнер сервисов при обращении к нему за
определенным сервисом (типом интерфейса или класса) путем вызова
обобщенного метода GetService с указанием нужного параметра-типа,
возвращает ссылку на объект запрошенного типа - реализующий этот
интерфейс или являющийся объектом этого класса.
Исходным для создания контейнера сервисов является список
регистраций сервисов с интерфейсом IServiceCollection, в который
методами этого интерфейса добавляются объекты - описатели сервисов.
Описатели сервисов содержат такую информацию, как тип сервиса
(возвращаемого класса или интерфейса), способ реализации и время
жизни сервиса. Процессы добавления описателей в список регистраций
сервисов и создания из него контейнера сервисов детально описаны
ниже, при описании соответствующих этапов инициализации
приложения.
детали реализации: дополнительные полезные сведения о контейнере
сервисов
-
Список регистрации сервисов хранит описатели сервисов в объектах
типа ServiceDescriptor. Возможно добавление в список регистраций
сервисов заранее созданных объектов описателей сервисов, иногда это
может быть полезным.
-
Контейнер сервисов позволяет регистрировать в нем несколько
вариантов одного и того же сервиса - с одним и тем же типом, но с
разными способами реализации. Как именно в таких случаях будет
вести себя контейнер сервисов - зависит от типа обращения к нему.
Если запрашивается одиночный объект какого-либо сервиса, то
контейнер сервисов создает и возвращает объект, реализующий сервис,
только для последней регистрации в нем сервиса этого типа. Если
запрашивается список сервисов некоторого типа - сервис типа
IEnumerable с этим параметром-типом, то контейнер сервисов создает
объекты для всех зарегистрированных реализаций сервиса того типа,
который был указан в качестве параметра-типа IEnumerable и
возвращает ссылку на IEnumerable, который перечисляет все эти
объекты в том порядке, в котором эти реализации были
зарегистрированы. Порядок регистрации сервисов в контейнере
сервисов совпадает с тем порядком, в котором они были добавлены в
список регистраций сервисов IServiceCollection
-
При регистрации сервиса указывается его время жизни. По времени
жизни сервисы разделяются на постоянные, реализации которых
создаются в одном экземпляре (Singleton) и существующие в течение
всего времени жизни приложения (пока существует контейнер
сервисов), временные - реализации которых создаются каждый раз в
момент обращения и существуют пока объект, реализующий сервис,
используется в запросившем его коде (Transient), и сервисы со
временем жизни ограниченной области (Scoped), которые должны
запрашиваться не из основного (корневого) контейнера сервисов, а из
производного от него контейнера сервисов ограниченной области,
доступного через свойство ServiceProvider интерфейса IServiceScope
создаваемого с помощью метода расширения CreateScope для интерфейса
контейнера сервисов IServiceProvider. Объекты, реализующие сервисы
со временем жизни ограниченной области существуют, пока существует
соответствующая ограниченная область, а в рамках этой области
существуют в единственном экземпляре.
-
В качестве реализации сервиса может быть указан:
а) класс: в этом случае контейнер сервисов для создания
реализующего сервис объекта находит конструктор указанного класса,
создает реализации для всех параметров этого конструктора, вызывает
конструктор и возвращает ссылку на созданный таким образом
объект;
б) делегат-фабрика: в этом случае в этом случае контейнер
сервисов для создания реализующего сервис объекта вызывает этот
делегат, передавая в него в качестве аргумента ссылку на свой
интерфейс IServiceProvider; делегат сам отвечает за создание
нужного объекта и всех необходимых для этого объектов (для этого
может использоваться переданная в качестве параметра ссылка на
контейнер сервисов); контейнер сервисов возвращает ссылку на
созданный делегатом-фабрикой объект;
в) экземпляр класса нужного типа (только для сервисов с
постоянным временем жизни): в этом случае контейнер сервисов
возвращает ссылку на этот объект.
Третий ключевой компонент ASP.NET Core и .NET Core
инициализуемый в процессе создания приложения (а также -
используемый внутри самого процесса инициализации) - это механизм
параметров (Options). Параметры, передаваемые данным механизмом,
представляют собой сервисы, позволяющие получать в приложении
значения заранее определенного типа, причем на стадии инициализации
(конфигурирования) приложения задается не само значение, а способ
его получения, его источник. То есть, во-первых, параметры
передаются в программу на стадии выполнения не как объекты данных,
а как сервисы, реализованные в виде интерфейсов .NET, и реализация
механизма параметров опирается на использование контейнера
сервисов: сервисы для работы с параметрами, так же как и любые
другие сервисы, регистрируются в списке регистраций сервисов, а
затем, после создания контейнера сервисов на основе этого списка
регистраций, становятся доступными в приложении. Для получения
самих же передаваемых значений необходимо вызвать соответствующие
свойства или методы этих сервисов (для доступа к параметрам есть
три разных типа сервисов, отличающихся способами их использования -
IOptions<>, IOptionsSnapshot<>, и
IOptionsMonitor<>, их описание я здесь приводить не буду).
Во-вторых, значения параметров являются строго статически
типизированными, их типы задаются на стадии написания программы, и
указываются как параметры-типы для обобщенных типов сервисов
получения значений параметров(options). В-третьих, на стадии
конфигурирования задаются не сами значения параметров, а способы
получения их значений. Эти способы задаются путем добавления в
контейнер сервисов специальных сервисов конфигурирования значений.
Регистрация сервисов, реализующих механизм параметров (options), в
принципе, может быть произведена обычными методами регистрации
сервисов. Но для удобства конфигурирования этого механизма созданы
специальные методы расширения для интерфейса списка регистрации
сервисов IServiceCollection, и чаще всего используются именно они.
Этими методами можно указать, что либо источником значения сервиса
служит объект конфигурации, реализующий IConfiguration (обычно -
раздел конфигурации), либо произвольный код, записываемый в виде
одной или нескольких процедур-делегатов, устанавливающих это
значение. Более подробное рассмотрение механизма параметров
заслуживает отдельной статьи, поэтому здесь его не будет.
Рассмотрим теперь в подробностях процесс создания приложения,
точнее - его объекта размещения (или хоста), реализующего интерфейс
IHost Как уже было сказано, это производится методом Build
интерфейса IHostBuilder. А поскольку статья рассматривает работу
стандартной реализации шаблона приложения Generic Host построителя
Microsoft.Extensions.Hosting.HostBuilder (или просто HostBuilder)
здесь рассматривается работа метода Build этого конкретного
класса.
Создание конфигурации приложения
Вот теперь можно вернуться к дальнешему изучению метода Build.
Сначала в методе Build создается конфигурация приложения.
детали реализации: метод Build
Но в самом что ни на есть начале метод HostBuilder.Build
проверяет, что он не был запущен повторно. В объекте класса
HostBuilder для этого есть специальное булево поле _hostBuilt,
которое после создания объекта имеет значение по умолчанию false.
Код в начале метода проверяет, установлено ли это поле в true, и
если так - выбрасывает исключение InvalidOperationException. А
сразу после этой проверки поле _hostBuilt устанавливается в
true.
Для создания конфигурации приложения используются два отдельных
этапа, с некоторым количеством промежуточных этапов между ними, на
которых создаются другие структуры данных. Это связано с тем, что
для нахождения части источников конфигурации приложения - таких,
как файлы конфигурации - нужно знать некую дополнительную
информацию - такую, как местонахождение корневого каталога
приложения - которая обычно задается по умолчанию, но может, вообще
говоря, и переопределяться в конфигурации, только в другой ее
части. Поэтому сначала выполняется стадия, на которой создается
конфигурация размещения (Host Configuration, чаще я буду назвать ее
конфигурации построителя - по месту ее использования). Это - та
часть конфигурации, которая не зависит от контекста построения (о
нем немного ниже), в который входит, в частности, упомянутый путь к
корневому каталогу приложения. Что именно входит в конфигурацию
построителя по умолчанию - см. документацию. Очередь делегатов,
выполняемых на этой стадии, создается методом
ConfigureHostConfiguration интерфейса IHostBuilder и хранится во
внутреннем поле _configureHostConfigActions. На рис.1 она
обозначена "корзиной" под номером 1.
детали реализации: конфигурация построителя
Метод ConfigureHostConfiguration принимает единственный
параметр-делегат, который тоже имеет единственный параметр - ссылку
на объект построителя конфигурации IConfigurationBuilder.
Создание конфигурации построителя производится внутренним
методом BuildHostConfiguration().
детали реализации: создание конфигурации построителя
Этот метод создает объект-построитель конфигурации класса
ConfigurationBuider(реализующий IConfigurationBuilder) - локальную
переменную configBuilder(на рис.1 она представлена штриховым
прямоугольником) - и добавляет в него источник конфигурации,
создающий провайдер хранилища конфигурации в памяти (изначально
пустого) - чтобы делать возможным установку параметров конфигурации
(через свойство по умолчанию интерфейса IConfiguration) даже в
случае, если для конфигурации не будет больше определен никакой
другой источник. После этого вызываются все делегаты из очереди
построения конфигурации размещения, которые добавляют в созданный
объект с интерфейсом IConfigurationBuilder свои источники
конфигурации (но могут, конечно, делать и другие действия). И,
наконец, из этих источников создается (методом
IConfigurationBuilder.Build()) конфигурация размещения (она же -
конфигурация построителя).
Созданная конфигурация построителя запоминается в поле
_hostConfiguration построителя.
После этого наступают этапы создания структур данных - объектов,
содержащих информацию о контексте, в котором производится
построение приложения. Первый такой объект - это объект окружения
размещения (хоста), реализующий интерфейс IHostEnvironment. Его
создание производится внутренним методом
CreateHostingEnvironment(). Данный метод создает объект внутреннего
для сборки типа HostingEnvironment, реализующий интерфейсы
IHostEnvironment и IHostingEnvironment (устаревший аналог
IHostEnvironment). При этом при создании объекта его свойства
устанавливаются на основе значений ключей конфигурации размещения с
фиксированными названиями (подробности - см. документацию). В число
этих свойств входят имя приложения (ApplicationName), название
среды выполнения(Environment) и путь к корневому каталогу
приложения (ContentRootPath).
Если нужных ключей в конфигурации размещения нет - эти свойства
устанавливаются в значения по умолчанию (опять-таки, см.
документацию). И, наконец, в свойство ContentRootFileProvider
созданного объекта окружения записывается вновь созданный экземпляр
класса PhysicalFileProvider для пути ContentRootPath - то есть, в
качестве средства доступа к файлам приложения используется
(изначально и по умолчанию) обычная файловая система. Созданный
объект окружения размещения запоминается в поле _hostingEnvironment
объекта построителя.
Другой объект, содержащий информацию о контексте - это объект
контекста построения (экземпляр класса HostBuilderContext) Он
создается на следующем этапе внутренним методом
CreateHostBuilderContext. В его свойствах запоминаются ссылки на
другие объекты, связанные с построителем: в Properties - ссылка на
одноименное свойство построителя - словарь построителя (его
описание см. выше под спойлером "детали реализации: другие методы
IHostBuilder"), в Environment - на только что созданный объект
окружения размещения (IHostEnvironment), в Configuration -
(временно) конфигурация размещения (потом она будет заменена на
конфигурацию приложения). Ссылка на объект контекста построения
запоминается в поле _hostBuilderContext. И вот теперь все готово
для окончательного создания полной конфигурации приложения,
включающей в себя все источники, и это становится следующей
стадией.
Стадия окончательного создания конфигурации приложения
производится внутренним методом BuildAppConfiguration. Очередь
делегатов, выполняемых на этой стадии, создается методом
ConfigureAppConfiguration интерфейса IHostBuilder и хранится во
внутреннем поле _configureAppConfigActions. На рис.1 она обозначена
"корзиной" под номером 2.
детали реализации: конфигурация приложения
Метод ConfigureAppConfiguration принимает единственный
параметр-делегат, который имеет уже два параметра - ссылку на
контекст построения HostBuilderContext и ссылку на объект
построителя конфигурации IHostBuilder. Данный метод сначала создает
построитель конфигурации - объект класса
ConfigurationBuider(реализующий IConfigurationBuilder) и
устанавливает для него базовым каталогом корневой каталог
приложения IHostEnvironment.ContentRootPath . установка базового
каталога построителя конфигурации IConfigurationBuilder
производится его методом расширения SetBasePath. Этот метод
записывает в словарь построителя конфигурации под ключом
"FileProvider" ссылку на свежесозданный объект PhysicalPathProvider
с указанным базовым каталогом. Этот провайдер затем будет
использоваться в качестве файлового провайдера IFileProvider по
умолчанию во всех классах-источниках конфигурации файловых
провайдеров (классов-наследников FileConfigurationSource)
Непонятно, однако, зачем нужно было создавать два одинаковых по
смыслу объекта провайдера - здесь и для окружения размещения -
работающих с одним и тем же каталогом, причем - создавать их
немного разным образом.
Следующим шагом в построитель конфигурации IConfigurationBuilder
добавляется как источник конфигурации созданная ранее конфигурация
построителя. Тем самым ранее созданная конфигурация построителя
становится частью конфигурации приложения.
детали реализации: добавление конфигурации построителя к
конфигурации приложения
Делается это добавлением в список источников класса
ChainedConfigurationSource, содержащий ссылку на объект
конфигурации построителя, причем в конструкторе
ChainedConfigurationSource указывается флаг, что за освобождение
(вызов метода Dispose) этого объекта конфигурации должен будет
отвечать созданный из этого источника экземпляр класс провайдера
ChainedConfigurationProvider, который также будет содержать ссылку
на этот объект конфигурации.
Затем построение конфигурации приложения завершается аналогично
построению конфигурации построителя.
детали реализации: завершение построения конфигурации приложения
Затем к построителю конфигурации IConfigurationBuilder
последовательно применяются делегаты из очереди конфигурации
приложения _configureAppConfigActions, получающие в качестве
аргументов ссылку на ранее созданный контекст построителя и на
построитель конфигурации. Что именно входит в конфигурацию
приложения по умолчанию - также см. документацию. После применения
всех делегатов производится создание объекта конфигурации
приложения методом IConfigurationBuilder.Build.
Полученная конфигурация (интерфейс IConfiguration) сохраняется в
поле _appConfiguration объекта построителя.
Последнее действие, которое производит метод IHostBuilder.Build
построителя - это создание контейнера сервисов. Выполняет его
внутренний метод CreateServiceProvider. Это действие достаточно
сложное, оно включает в себя несколько стадий, на двух из которых
применяются две разных очереди делегатов конфигурирования.
Создание контейнера сервисов
Для начала - немного о том, как выглядит процесс создания
контейнера сервисов. Выполняется этот вызовами двумя
последовательными вызовами методов интерфейса фабрики контейнера
сервисов IServiceProviderFactory. Этот интерфейс, как мы видим,
является обобщенным, с параметром-типом, который является типом
промежуточного объекта, создаваемого первым методом, и принимаемого
вторым. Точный смысл этого параметра-типа я, честно говоря, так до
конца и не понял, т.к. ни в документации, ни в изученных мной
исходных текстах примеров его нетривиального использования не
встречается: фабрика контейнера сервисов по умолчанию (о ней см.
ниже) использует тривиальный вариант, в котором этот тип совпадает
с типом списка регистраций сервисов IServiceCollection и никакого
дополнительного конфигурирования с использованием этого типа не
производится. В документации и в коде его в разных местах называют
по-разному - то ContainerBuilder(как вышеприведенный параметр-тип,
только без префикса T), то просто Container. В тексте я буду
называть его "контейнер-построитель". Судя по всему, он
используется где-то для конфигурирования процесса подключения
контейнера сервисов стороннего типа: в .NET Core есть возможность
использовать другие контейнеры сервисов, кроме реализации по
умолчанию, и несколько из них официально поддерживаются, однако я
со сторонними контейнерами дела не имел, а потому достоверно
утверждать об этом не могу. В самой же ASP.NET Core используется
только упомянутый уже тривиальный вариант по умолчанию.
Вернемся, однако, к интерфейсу фабрики контейнера сервисов
IServiceProviderFactory. Первый метод, CreateBuilder, принимает в
качестве аргумента список регистраций сервисов IServiceCollection
services) и возвращает объект контейнера-построителя, который (я
тут забегаю вперед) может быть подвергнут дополнительному
конфигурированию. После этого второй метод интерфейса фабрики
CreateServiceProvider принимает аргумент - контейнер-построитель и
возвращает созданный на его основе контейнер сервисов (интерфейс
IServiceProvider).
Для установки используемой при построения контейнера сервисов
фабрики в процессе построения размещения (IHost) в интерфейсе
построителя IHostBuilder существует метод UseServiceProviderFactory
(его параметр тип - это тип контейнера-построителя), имеющий две
перегруженных формы: первая принимает в качестве параметра ссылку
на интерфейс фабрики заранее созданного объекта, вторая - делегат,
принимающий в качестве параметра объект контекста построения
HostBuilderContext и возвращающий ссылку на интерфейс фабрики
контейнера сервисов, реализуемый объектом, который выбирается или
создается на основе содержимого контекста построения на этапе
создания контейнера сервисов. Ссылка на объект фабрики контейнера
сервисов, которая будет использована, сохраняется во внутреннем
поле построителя (на рис.1 оно обозначено штриховым кругом
справа).
детали реализации: хранение фабрики контейнера сервисов
В объекте построителя, однако, для хранения используется поле
_serviceProviderFactory, имеющее тип адаптера фабрики контейнера
сервисов - внутреннего интерфейса IConfigureContainerAdapter. Этот
интерфейс является необобщенным - по причине того, что класс
HostBuilder, реализующий построитель, также является необобщенным и
не имеет параметра-типа, соответствующего типу
контейнера-построителя - а потому этот тип нельзя использовать в
качестве типа поля этого класса. Методы интерфейса адаптера фабрики
IConfigureContainerAdapter в целом аналогичны методам самой фабрики
IServiceProviderFactory, но с некоторыми различиями. Первое
различие - в том, что метод CreateBuilder имеет дополнительный
параметр - контекст построителя HostBuilderContext: он нужен для
использования фабрики контейнера сервисов, получаемой от делегата,
переданного через вторую форму метода UseServiceProviderFactory.
Второе различие - в том, что методы IConfigureContainerAdapter
вместо недоступного им типа контейнера-построителя используют
универсальный тип Object. Реализуется этот интерфейс, однако,
обобщенным внутренним классом ConfigureContainerAdapter, поэтому
некоторый статический контроль (или вывод) типов все-таки
производится - за счет конструктора этого класса в методе
UseServiceProviderFactory, а потому объект, передаваемый во второй
метод, CreateServiceProvider имеет правильный тип. Но вот
соответствие типа контейнера-построителя, указанного при вызове
метода UseServiceProviderFactory сигнатурам делегатов, помещенных в
очередь конфигурирования контейнера-построителя (см. ниже)
контролируется только динамически при их приведении к нужному для
делегата типу (Из-за чего возможно возникновение исключения).
По умолчанию построитель использует реализацию фабрики
контейнера сервисов на основе класса DefaultServiceProviderFactory.
Этот класс в качестве типа контейнера-построителя использует тип
списка регистраций сервисов IServiceCollection, т.е. реализует
интерфейс IServiceProviderFactory. Некоторые свойства создаваемого
контейнера сервисов можно задать с помощью параметра его
конструктора - и это используется в одном из методов инициализации
построителя веб-приложения (об этом - позже, во второй части).
детали реализации: о параметре конструктора
Конструктор может принимать параметр класса
ServiceProviderOptions - параметры (options) контейнера сервисов.
Этот класс имеет два публичных свойства-флага: ValidateScopes -
проверять, не производится ли разрешение сервиса со временем жизни
ограниченной области (Scoped) из корневого контейнера сервисов
(используемого вне ограниченных областей) и ValidateOnBuild - при
создании контейнера сервисов выполнить проверку, что можно создать
все зарегистрированные в нем сервисы. По умолчанию параметр
конструктора установлен в значение ServiceProviderOptions.Default,
в котором оба эти флага сброшены. Параметр, переданный в
конструктор, сохраняется во внутреннем поле.
Метод CreateBuilder класса DefaultServiceProviderFactory,
реализующего фабрику контейнера сервисов по умолчанию, просто
возвращает переданный в него список регистраций сервисов. Метод
CreateServiceProvider этого класса использует метод расширения
BuildServiceProvider для интерфейса IServiceCollection.
детали реализации: метод CreateServiceProvider
Он возвращает значение, получаемое от BuildServiceProvider,
вызываемого для ссылки на интерфейс IServiceCollection, переданной
в CreateServiceProvider как параметр - "контейнер-построитель". При
вызове в качестве аргумента используется сохраненное значение в
конструкторе значение ServiceProviderOptions - параметры построения
контейнера сервисов.
Этот метод фактически создает контейнер сервисов по умолчанию и
возвращает его интерфейс IServiceProvider. Детали того, как именно
это происходит, находятся вне предмета рассмотрения данной статьи и
потому здесь рассмотрены не будут.
Вернемся к процессу создания контейнера сервисов внутренним
методом CreateServiceProvider построителя, и рассмотрим подробнее
стадии этого процесса. На первой стадии создается объект списка
регистраций сервисов с интерфейсом IServiceCollection - он
записывается в локальную переменную services(на рис.1 она
представлена штриховым прямоугольником). А потом в этот список
добавляются (регистрируются) описатели сервисов, реализующих
базовые сервисы фреймворка.
детали реализации: список регистраций сервисов
Реальный класс объекта, реализующего список регистраций сервисов
- внутренний класс ServiceCollection. Устроен этот класс весьма
прямолинейно: в нем есть внутреннее поле типа List (содержащийся в
нем объект создается в конструкторе пустым), и все методы
интерфейса IServiceCollection напрямую отображаются на
соответствующие методы этого объекта. Базовые сервисы фреймворка -
это следующие сервисы (все они регистрируются как сервисы с
постоянным (Singleton)временем жизни). Во-первых - сервисы,
реализацией которых являются экземпляры объектов, ранее созданных в
процессе работы метода Build: IHostEnvironment и его устаревший
аналог IHostingEnvironment (реализация - экземпляр объекта типа
HostingEnvironment из поля _hostingEnvironment) и
HostBuilderContext (регистрируется в качестве сервиса не интерфейс,
а именно класс) (реализация - объект этого класса из поля
_hostBuilderContext. Во-вторых, сервисы, реализацией являются
классы, реализующие соответствующий интерфейс. Это - сервисы,
которые связаны с запуском, остановом, и отслеживанием этапов
работы приложения (в данной статье они подробно не
рассматриваются): IHostLifetime (реализация - класс
ConsoleLifetime), IHostApplicationLifetime (реализация - класс
ApplicationLifetime) и его устаревший аналог IApplicationLifetime
(последний реализуется с помощью фабрики, получающей реализацию
IHostApplicationLifetime - ссылку на объект класса
ApplicationLifetime - и возвращающий этот результат,
преобразованный к типу IApplicationLifetime) Сервис для интерфейса
IConfiguration регистрируется в виде фабрики - лямбда-функции,
возвращающей конфигурацию приложения - значение поля
_appConfiguration класса построителя (это значение сохраняется в
замыкании этой лямбда-функции). Мотив сделать именно так - вызвать
метод Dispose для конфигурации приложения при уничтожении
контейнера сервисов. Но для этого требуется ещё одно дополнительное
действие - фиктивное получение ссылки на этот сервис (см. спойлер в
конце описания работы внутреннего метода CreateServiceProvider
построителя). Кроме того, методами расширения для интерфейса
IServiceCollection регистрируются группы сервисов, реализующие
компоненты параметров (options) - методом AddOptions, и регистрации
(logging) - методом AddLogging
Кроме этих интерфейсов регистрируется (с постоянным (Singleton)
временем жизни основной интерфейс приложения, построенного на
шаблоне Generic Host - IHost: он реализуется внутренним классом
Internal.Host, его мы затронем немного позднее.
На второй стадии создания контейнера сервисов - стадии
конфигурирования списка регистраций сервисов - к созданному списку
регистраций сервисов IServiceCollection применяются делегаты из
очереди конфигурирования списка регистраций сервисов
_configureServicesActions. На рис.1 она обозначена "корзиной" под
номером 3. Для добавления делегатов в эту очередь служит метод
ConfigureServices. Делегат, добавляемый в эту очередь должен
принимать два параметра: контекст построения HostBuilderContext и
ссылку на конфигурируемый список регистраций сервисов
IServiceCollection.
На третьей стадии создания контейнера сервисов с помощью фабрики
сервисов создается промежуточный объект контейнера-построителя - он
записывается в локальную переменную containerBuilder (на рис.1 она
представлена штриховым прямоугольником).
детали реализации: создание контейнера-построителя
Это делается вызовом метода CreateBuilder адаптера фабрики
контейнера сервисов IConfigureContainerAdapter, ссылка на который
хранится в поле _serviceProviderFactory Ссылка на созданный
контейнер-построитель запоминается в локальной переменной
containerBuilder
При использовании фабрики контейнера сервисов по умолчанию этот
этап является формальным - контейнером-построителем служит все тот
же объект списка регистраций сервисов, что использовался и на
предыдущих стадиях, и доступен он через все тот же интерфейс
IServiceCollection.
На четвертой стадии создания контейнера сервисов - стадии
конфигурирования контейнера-построителя - к контейнеру-построителю
применяются элементы очереди конфигурирования
контейнера-построителя _configureContainerActions. На рис.1 она
обозначена "корзиной" под номером 4. Для добавления элементов в эту
очередь служит метод ConfigureContainer. В рассматриваемом нами
случае "чистой" (без сторонних контейнеров сервисов) ASP.NET Core
этот этап, похоже, не используется. Об этом, например, говорит тот
факт, что в документации даже не отражена возможность использования
Startup-класса на этом этапе конфигурирования, хотя поддержка
метода, производящего такое конфигурирование, в коде реализована
(об этом будет рассказано подробно при рассмотрении реализации
метода расширения UseStartup интерфейса IWebHostBuilder).
Поэтому сведения о реализации этого этапа целиком убраны под
спойлер (и там - детали реализации и лирическое отступление)
ConfigureContainer - это обобщенный метод, имеющий один
параметр-тип, совпадающий с типом контейнера-построителя. И этот
параметр-тип входит в сигнатуру параметров-делегатов, которые в
него передаются: делегаты должны принимать два параметра - контекст
построения типа HostBuilderContext и ссылку на
контейнер-построитель, тип которой - это тип
контейнера-построителя, то есть - значение параметра-типа метода
ConfigureContainer. А так, как значение типа контейнера-построителя
на уровне всего класса построителя на этапе компиляции не известно,
то элементами очереди являются не сами делегаты (потому что их
реальный тип не известен и не может быть использован для
специализации экземпляра класса List<>, используемого в
качестве очереди), а ссылки на необобщенный внутренний интерфейс
IConfigureContainerAdapter, реализуемый внутренним объектом
обобщенного типа ConfigureContainerAdapter, специализированным
типом контейнера-построителя, использованным указанным в сигнатуре
делегата (то есть - типом второго параметра делегата). Этот делегат
передается в качестве параметра в конструктор этого объекта и
запоминается в его внутреннем поле. Метод ConfigureContainer этого
интерфейса по сигнатуре аналогичен инкапсулированному делегату, но
принимает в качестве типа контейнера-построителя универсальный тип
Object. А реализация этого метода в классе
ConfigureContainerAdapter состоит в приведении полученной ссылки на
контейнер-построитель к типу второго параметра запомненного
делегата и вызове этого делегата. Такое решение: палка о двух
концах: с одной стороны, это позволяет довольно просто поместить
все делегаты конфигурирования контейнера-построителя в одну
очередь, но с другой - препятствует статической проверке
соответствия типов параметров делегатов типу
контейнера-построителя. А это несоответствие может привести к
возникновению исключения недопустимого преобразования типов.
Причем, поскольку в реализации метода ConfigureContainer в типе
ConfigureContainerAdapter аргумент ссылки на контейнер-построитель
просто безо всяких проверок приводится к типу, принимаемому
делегатом, то исключение возникнет в месте, не контролируемом
разработчиком, и приводит к прерыванию выполнения метода Build
построителя. Разработчик может бороться с этим, разве что,
используя делегаты с универсальным типом Object в качестве типа
контейнера-построителя и проверяя тип контейнера-построителя внутри
делегата. Но IMHO это - так себе решение.
На следующей, пятой стадии из контейнера-построителя создается
объект контейнера сервисов.
детали реализации: создание контейнера сервисов из
контейнера-построителя
Точнее - корневого контейнера сервисов: попытка получения из
него сервиса со временем жизни ограниченной области (Scoped)
считается ошибкой, потому что полученный сервис реально будет иметь
постоянное время жизни, эквивалентное Singleton - а это, вероятно,
не то, что ожидал разработчик, указывая время жизни ограниченной
области (Scoped). В некоторых режимах - например, в режиме
разработки (окружении Development) - такие действия реально
проверяются и, в случае их обнаружения выбрасывается исключение
InvalidOperationException. За производство такой проверки отвечает
флаг ValidateScopes параметра типа ServiceProviderOptions,
передаваемого при использовании фабрики контейнера сервисов по
умолчанию DefaultServiceProviderFactory, в метод расширения
BuildServiceProvider для интерфейса IServiceCollection, который
производит создание контейнера сервисов. Само создание делается
вызовом метода CreateBuilder адаптера фабрики контейнера сервисов
IConfigureContainerAdapter, ссылка на который хранится в поле
_serviceProviderFactory, а ссылка на созданный
контейнер-построитель запоминается в локальной переменной
containerBuilder
На этом процесс создания контейнера сервисов внутренним методом
CreateServiceProvider построителя заканчивается.
детали реализации: дополнительные действия
Точнее - почти заканчивается: дополнительно производится еще
фиктивный запрос сервиса IConfiguration - чтобы сервис был помечен
как запрошенный, это нужно чтобы реализующий его объект
_appConfiguration был вовремя освобожден (вызовом Dispose())
контейнером сервисов (подробности в этой статье не рассматриваются
- они явно выходят за пределы рассматриваемой темы)
И последнее, что делает метод Build класса построителя
HostBuilder - это получает из контейнера сервисов реализацию
интерфейса IHost (объект класса Internal.Host), которую возвращает
в качестве результата.
Лирическое отступление: О торжестве подхода внедрения зависимостей
На поверхности все выглядит так, что для получения реализации
интерфейса IHost метод Build просто запрашивает его у контейнера
сервисов. А уж контейнер сервисов сам находит нужный класс
Internal.Host, отыскивает его конструктор, который имеет немало
параметров-зависимостей, разрешает внутри себя эти зависимости,
создает экземпляр этого класса, указав все нужные параметры и,
наконец, возвращает ссылку на запрошенный интерфейс, реализованный
этим экземпляром. Это выглядит, вроде бы, как существенное
упрощение, показывающее преимущества внедрения зависимостей. Но это
- только видимость: объекты почти для всех этих
параметров-интерфейсов были созданы в том же самом методе Build,
так что передать их в конструктор класса более традиционным путем
не составило бы никакого труда. Единственный параметр
Internal.Host, который не создается кодом внутри HostBuilder.Build
таким путем - сервис, реализующий параметр (option) для типа
HostOptions: его значение задается одним из методов
конфигурирования, применяемым разработчиком конкретного приложения.
Но фактически единственный параметр, который передается таким
образом - таймаут завершения - мог бы быть куда проще передан
традиционным образом - через параметр типа Timespan. Так что
процесс получения IHost в HostBuilder.Build сам по себе
демонстрирует лишь саму технику использования внедрения
зависимостей, но никак не ее преимущества.
Что происходит потом
Последний этап инициализации приложения, компоненты которого
размещены в полученном размещении IHost - этап, специфичный для
каждого из компонентов. Он происходит в процессе запуска
приложения, который производится методом IHost.StartAsync - прямо
или косвенно, через методы расширения этого интерфейса, которые
внутри себя вызывают StartAsync. Метод StartAsync стандартной
реализации IHost - класса Internal.Host - запускает (уже
асинхронно) каждый из размещенных компонентов приложения методом
IHostedService.StartAsync: все компоненты реализуют интерфейс
IHostedService. С помощью этого метода компоненты выполняют
специфичную для них инициализацию. Об инициализации, выполняемым
компонентом веб-приложения будет подробно рассказано во второй
части статьи. Кроме того, метод StartAsync стандартной реализации
IHost производит еще ряд действий, которые в данной статье не
рассматриваются.
И на этом рассказ об инициализации приложения, построенного по
шаблону Generic Host можно считать законченным - теперь приложение
запущено и выполняется. Не правда ли, все на самом деле очень
просто? Не торопитесь, в продолжении этой статьи последует рассказ
об особенностях инициализации веб-приложения - и ощущение простоты,
если таковое и было, обязательно развеется.
Продолжение: будет скоро опубликовано. Оно уже написано (и даже
выложенно в мой блог, но в не до конца причесанном виде).
















































 Вещи
которые есть в магазине
Вещи
которые есть в магазине

 Зеленым выделена первая опция, красным
вторая. Как видим стоимость в красном круге перевешивает стоимость
в зеленом
Зеленым выделена первая опция, красным
вторая. Как видим стоимость в красном круге перевешивает стоимость
в зеленом



 Батрак предупреждает о том что к гильдии
присоединился игрок
Батрак предупреждает о том что к гильдии
присоединился игрок
 Создание webhook
Создание webhook




 Главная форма ImportExportDataSql
Главная форма ImportExportDataSql
 Сохранить настройку соединения с БД
Сохранить настройку соединения с БД
 Сохранить из БД в БД
Сохранить из БД в БД