
В данной статье я поделюсь опытом, как
недавняя авария в OVH отразилась на нашей инфраструктуре
мониторинга, как мы решали проблему и какие уроки из этого
извлекли.
О мониторинге у нас
Начать стоит с того, как во Фланте вообще устроен мониторинг
клиентских приложений и инфраструктуры в целом. Для этих целей
задействованы три разных вида мониторинга:
1. Blackbox-мониторинг для проверки состояния
сайтов. Цель проста собирать статистику с определенных endpointов и
проверять их состояние по тем условиям, которые требуется
установить. Например, это может быть health page в виде
JSON-страницы, где отражено состояние всех важных элементов
инфраструктуры, или же мониторинг отдельных страниц сайта. У нас
принято считать, что данный вид мониторинга самый критичный, так
как следит за работоспособностью сайта/сервисов клиента для внешних
пользователей.
Вкратце о технической стороне этого мониторинга: он выполняет
запросы разного уровня сложности по HTTP/HTTPS. Есть возможность
определять размер страницы, ее содержимое, работать с JSON (они
обычно используются для построения status page-страниц приложений
клиента). Он географически распределен для повышения
отказоустойчивости и во избежание всевозможных блокировок
(например, от РКН).
Работа данного мониторинга не была затронута аварией благодаря
геораспределенности (к тому же, у него вообще нет инсталляций в
OVH).
2. Мониторинг Kubernetes-инфраструктуры и
приложений клиента, запущенных в ней. С технической точки зрения
этот мониторинг основан на связке Prometheus + Grafana +
Alertmanager, которые устанавливаются локально на кластеры клиента.
Часть данных, собираемых на данных системах мониторинга (например,
метрики, напрямую связанные с Kubernetes и Deckhouse), по умолчанию
отправляется в нашу общую систему, а остальные могут отправляться
опционально (например, для мониторинга приложений и реакции от
наших дежурных инженеров).
3. Мониторинг ресурсов, которые находятся
вне кластеров Kubernetes. Например, это железные
(bare metal) серверы, виртуальные машины и СУБД, запущенные на них.
Данную зону мониторинга мы покрываем с помощью стороннего сервиса
Okmeter
(а с недавних пор уже не очень-то
для нас и стороннего). Именно его работа была фатально
нарушена в момент аварии OVH.
(А о том, как осуществляется дальнейшая обработка
инцидентов, поступающих от всех упомянутых систем, мы рассказывали
в этом докладе.)
Таким образом, все проблемы, описанные ниже, связаны с
недоступностью одной из используемых систем Okmeter. То
есть на некоторое время мы потеряли информацию о некоторой
инфраструктуре (вне Kubernetes-кластеров), сохранив при этом
доступность blackbox-мониторинга (который гарантирует нам, что
главные бизнес-функции работают).
Как мы справлялись с этой аварией? Какие шаги предпринимали во
время инцидента? И какие после?
Первые признаки аварии
Проверка доступности внешних средств мониторинга осуществляется
с применением метода
Dead mans switch (DMS). По своей сути это мониторинг,
который работает наоборот:
-
Создается поддельный алерт OK, означающий, что всё
хорошо, и он постоянно отправляется с локальных мониторингов
(Prometheus, Okmeter и т.п.) в нашу систему
инцидент-менеджмента.
-
Пока с мониторингом действительно всё хорошо, алерт OK
активен, но в системе не показывается.
-
В обратной ситуации, когда возникают проблемы с мониторингом,
алерт OK перестает быть активным, из-за чего автоматически
создаётся алерт ERROR о неработающем мониторинге. И вот
уже на него надо реагировать.
Данная проверка очень эффективна в ситуациях, которая произошла
в роковой день (10 марта): первый алерт о проблеме (ERROR)
мы получили как раз от DMS.
События разворачивались следующим образом:
-
Первое сообщение о проблеме алерт от DMS, полученный
приблизительно в 3:20 ночи по Москве.
-
Связываемся с коллегами из Okmeter и узнаем, что они испытывают
проблемы с ЦОД, в котором расположены. Детальной информации на
данный момент не получаем, из-за чего масштабы аварии нам
неизвестны. Кроме того, дежурный инженер видит, что у нас корректно
работают другие системы мониторинга (blackbox и Kubernetes).
Поэтому принимается решение отложить инцидент до утра.
-
Утром (в 8:14) становится известно, что ЦОД сгорел, а Okmeter не
будет доступен до тех пор, пока не восстановит свою инфраструктуру
в другом ЦОД.
Здесь также стоит остановиться подробнее на том, как была
устроена инфраструктура у Okmeter. Основные её компоненты
находились в дата-центрах OVH:
Так уж получилось, что два формально разных дата-центра
OVH оказались соседними зданиями. И пожар, случившийся в
одном из них, в скором временем затронул и другое здание тоже.
Руководствуясь этой информацией утром 10 марта, мы сделали
вывод, что нужно срочно замещать важные для нас функции Okmeter
хоть какими-то решениями на временной основе.
Первые действия
В компании была собрана специальная команда, основными целями
которой являлись:
-
Определение масштабов аварии;
-
Поэтапное планирование, как устранять последствия инцидента;
-
Дальнейшее внедрение полученных решений.
В неё вошли тимлиды наших DevOps-команд, инженеры нашей
платформенной команды и CTO компании. Позже к ней также добавились
отдельные инженеры, помогавшие со срочной разработкой и
тестированием новых инструментов, заменивших критичные проверки от
Okmeter.
Как уже упоминалось, Okmeter использовался у нас как одно из
средств мониторинга. Какую же роль он занимал в общей системе,
насколько критичен был? Для определения критичности инцидентов мы
опираемся на следующую матрицу:

Матрица
критичности алертов
Эта матрица распространяется на события из всех 3 используемых у
нас систем мониторинга. Каждому инциденту, зафиксированному в любой
из систем, назначается критичность от S1 (полная потеря
работоспособности компонента системы) до S9 (диагностическая
информация). Большая часть алертов с критичностью S1 это
blackbox-мониторинг, который проверяет состояние сайтов клиента.
Однако также к этой категории относится и незначительная часть
алертов, отправляемых со стороны Okmeter (подробнее о них см.
ниже). Другая незначительная часть приходится на S2, а все
остальные имеют более низкую критичность (S3 и т.п.).
Проведя учет количества и видов алертов с S1 и S2 от Okmeter, мы
приняли очевидное решение заняться ими в первую очередь, полностью
компенсировав другим временным решением. А уже после этого можно
было переходить на алерты с меньшей критичностью.
Оповестив всех клиентов, инфраструктуру которых задела авария у
Okmeter, мы приступили к составлению плана восстановления.
Порядок и план восстановления алертов от Okmeter
Первая очередь алертов: S1-S2
Итак, какие именно критичные алерты мы потеряли с недоступностью
Okmeter? Чтобы оперативно собрать эту информацию, каждая команда
инженеров тех, что сопровождают проекты с мониторингом от Okmeter,
подготовила статистику алертов, приходивших с 1 июля 2020 года.
Получился следующий список:
-
Различные алерты для СУБД.
-
Проверка работоспособности СУБД в целом (запущен ли
процесс).
-
Состояние репликации.
-
Состояние запросов к БД (например, сколько запросов находятся в
ожидании).
-
Дисковое потребление на виртуальных машинах.
-
Доступность виртуальных машин в целом.
Вторая очередь алертов: S3 и далее
Ситуация с алертами категории S3 была проще: их меньше, они
менее критичные, да и вообще эта категория оказалась не у всех
команд.
По итогам этого аудита получилась вторая очередь. Она в основном
состояла из проверок доступности менее критичных серверных
приложений, таких как ZooKeeper.
Немного магического Bash
Чтобы реализовать замену проверкам и алертам Okmeter,
требовалось уметь деплоить на все серверы актуальные скрипты
мониторинга, чтобы поддерживать их в актуальном состоянии.
Реализация: с помощью Ansible-плейбуков мы задеплоили все
необходимые скрипты, среди которых был скрипт автообновления.
Последний раз в 10 минут загружал новые версии других скриптов.
Из-за очень сжатых сроков основную часть скриптов мы писали на
Bash.
Общий подход получился следующим:
-
Сделали shell-скрипты, которые запускались на виртуальных
машинах и bare metal-серверах. Помимо своей основной функции
(проверка работоспособности некоторых компонентов) они должны были
доставлять сообщения в наш мониторинг с такими же лейблами и
другими элементами, как и у Okmeter: имя триггера, его severity,
другие лейблы и т.д. Это требовалось для сохранения той логики
работы мониторинга, которая была и до падения. В общем, чтобы
процесс работы дежурных инженеров оставался неизменным и чтобы
работали прежние правила управления инцидентами.
Быстрой реализации этого этапа способствовал тот факт, что у нас
уже были готовые инструменты для работы с API мониторинга
внутренний инструмент под названием flint (flant integration).
-
С помощью Ansible-плейбуков в каждый проект и на каждый сервер,
где это было необходимо, задеплоили новые скрипты мониторинга.
Ansible-плейбуки пришлось писать с нуля, но благодаря нашей
внутренней системе, которая хранит список всех обслуживаемых
хостов, деплоить изменения на серверы оказалось просто.
-
В течение некоторого времени мы дополнительно проверяли, что
алерты корректные, а сами скрипты выполняются правильно.
Результаты
На полную реализацию этого временного решения нам понадобился
один рабочий день для алертов типа S1-S2 и еще один для S3. Все
остальные инциденты (с более низким приоритетом) команды добавляли
в индивидуальном порядке по мере необходимости.
В общей сложности новые скрипты были задеплоены примерно на 3000
хостов.
На каждом этапе решения проблемы мы подробно информировали
клиентов о ходе восстановительных работ:
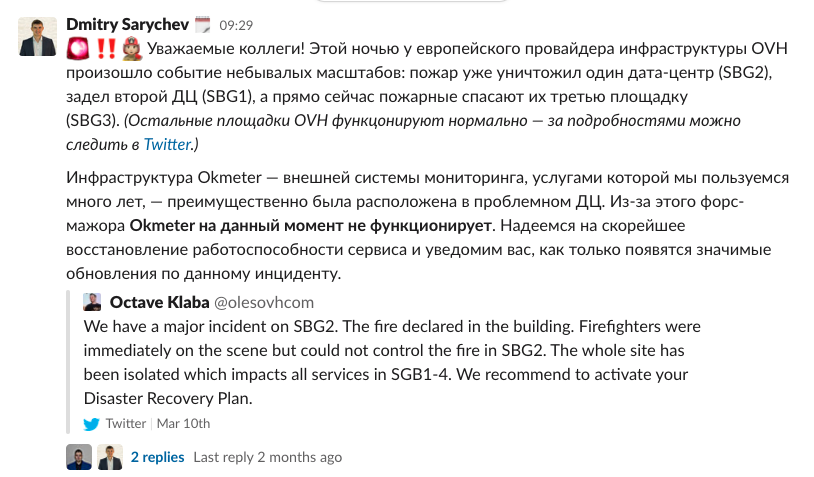
Позже статус по аварии и ликвидации её последствий обновлялся
как в текстовом виде, так и на регулярных еженедельных встречах.
Клиенты отнеслись к происходящему с пониманием и даже
уважением:

В тот момент, когда Okmeter стал доступен и функционировал
полностью корректно, мы отключили свой кастомный мониторинг, после
чего удалили все его следы, оставшиеся на серверах.
Выводы
Для нас данная авария стала показательным случаем и проверкой
основных процессов, которые мы выстраиваем в компании: инцидент
затронул все команды, практически каждого инженера и сотрудника
компании. Основной вывод оказался банален: слаженная командная
работа вместе с четким, структурированным планом действий (DRP)
позволяет решать задачи любой сложности в очень сжатые сроки. И это
по-настоящему ценно в те редкие моменты, когда разваливается
гораздо больше, чем вы могли себе представить
запланировать.
Более практичные выводы таковы:
-
Если сервис требует повышенной отказоустойчивости, всегда важно
разделять инфраструктуру не только на уровне разных ЦОД, но и
географически. Казалось бы, разные ЦОДы у OVH? А в реальной жизни
они горели вместе
-
В процессе подобного инцидента могут возникнуть проблемы и
недопонимания в коммуникациях как между Флантом и Okmeter, так и
между инженерами внутри нашей компании: недостаточное
информирование о масштабах инцидента, медленная реакция и т.п. Хотя
в этот раз нам повезло (их не возникло), мы пересмотрели свой
регламент эскалации и еще немного ужесточили его, чтобы исключить
вероятность появления таких проблем в будущем.
-
Даже столь масштабно погрузившись в спасение ситуации с
технической точки зрения, очень важно не держать клиентов в
информационном вакууме: мы постоянно актуализировали статус
инцидента и анонсировали прогресс по его решению. На это требуются
дополнительные ресурсы и время, но они того стоят.
P.S.
Читайте также в нашем блоге:



