
Предлагаем вашему вниманию перевод интереснейшего исследования от компании Crowdstrike. Материал посвящен использованию языка Rust в области Data Science (применительно к malware analysis) и демонстрирует, в чем Rust на таком поле может посоперничать даже с NumPy и SciPy, не говоря уж о чистом Python.

Приятного чтения!
Python один из самых популярных языков программирования для работы с data science, и неслучайно. В индексе пакетов Python (PyPI) найдется огромное множество впечатляющих библиотек для работы с data science, в частности, NumPy, SciPy, Natural Language Toolkit, Pandas и Matplotlib. Благодаря изобилию высококачественных аналитических библиотек в доступе и обширному сообществу разработчиков, Python очевидный выбор для многих исследователей данных.
Многие из этих библиотек реализованы на C и C++ из соображений производительности, но предоставляют интерфейсы внешних функций (FFI) или привязки Python, так, чтобы из функции можно было вызывать из Python. Эти реализации на более низкоуровневых языках призваны смягчить наиболее заметные недостатки Python, связанные, в частности, с длительностью выполнения и потреблением памяти. Если удается ограничить время выполнения и потребление памяти, то сильно упрощается масштабируемость, что критически важно для сокращения расходов. Если мы сможем писать высокопроизводительный код, решающий задачи data science, то интеграция такого кода с Python станет серьезным преимуществом.
При работе на стыке data science и анализа вредоносного ПО требуется не только скоростное выполнение, но и эффективное использование разделяемых ресурсов, опять же, для масштабирования. Проблема масштабирования является одной из ключевых в области больших данных, как, например, эффективная обработка миллионов исполняемых файлов на множестве платформ. Для достижения хорошей производительности на современных процессорах требуется параллелизм, обычно реализуемый при помощи многопоточности; но также необходимо повышать эффективность выполнения кода и расхода памяти. При решении подобных задач бывает сложно сбалансировать ресурсы локальной системы, а правильно реализовать многопоточные системы даже сложнее. Суть C и C++ такова, что потокобезопасность в них не предоставляется. Да, существуют внешние платформо-специфичные библиотеки, но обеспечение потокобезопасности, это, очевидно, долг разработчика.
Парсинг вредоносного ПО это в принципе опасное занятие. Вредоносное ПО часто непредусмотренным образом обращается со структурами данных, касающимися формата файлов, таким образом выводя из строя аналитические утилиты. Относительно распространенная западня, поджидающая нас в Python, связана с отсутствием хорошей типобезопасности. Python, великодушно принимающий значения
None, когда на месте них ожидался
bytearray, может скатиться в полный бедлам, избежать
которого можно, лишь нашпиговав код проверками на
None. Такие допущения, связанные с утиной типизацией
часто приводят к обвалам.Но есть Rust. Язык Rust во многом позиционируется как идеальное решение всех потенциальных проблем, обрисованных выше: время выполнения и потребление памяти сравнимы с C и C++, а также предоставляется обширная типобезопасность. Также в языке Rust предоставляются дополнительные приятности, в частности, серьезные гарантии безопасности памяти и никаких издержек времени исполнения. Поскольку таких издержек нет, упрощается интеграция кода Rust с кодом других языков, в частности, Python. В этой статье мы сделаем небольшую экскурсию по Rust, чтобы понять, достоин ли он связанного с ним хайпа.
Пример приложения для Data Science
Data science очень широкая предметная область со множеством прикладных аспектов, и обсудить их все в одной статье невозможно. Простая задача для data science вычисление информационной энтропии для байтовых последовательностей. Общая формула для расчета энтропии в битах приводится в Википедии:

Чтобы рассчитать энтропию для случайной переменной
X,
мы сначала считаем, сколько раз встречается каждое возможное
байтовое значение  , а потом делим это число на общее количество встречающихся
элементов, чтобы вычислить вероятность встретить конкретное
значение
, а потом делим это число на общее количество встречающихся
элементов, чтобы вычислить вероятность встретить конкретное
значение  , соответственно
, соответственно  . Затем считаем отрицательное значение от взвешенной суммы
вероятностей конкретного значения xi, встречающегося
, а также так называемую собственную информацию
. Затем считаем отрицательное значение от взвешенной суммы
вероятностей конкретного значения xi, встречающегося
, а также так называемую собственную информацию  . Поскольку мы вычисляем энтропию в битах, здесь используется
. Поскольку мы вычисляем энтропию в битах, здесь используется
 (обратите внимание на основание 2 для бит).
(обратите внимание на основание 2 для бит).Давайте испробуем Rust и посмотрим, как он справляется с вычислением энтропии по сравнению с чистым Python, а также с некоторыми популярнейшими библиотеками Python, упомянутыми выше. Это упрощенная оценка потенциальной производительности Rust в области data science; данный эксперимент не является критикой Python или отличных библиотек, имеющихся в нем. В этих примерах мы сгенерируем собственную библиотеку C из кода Rust, который сможем импортировать из Python. Все тесты проводились на Ubuntu 18.04.
Чистый Python
Начнем с простой функции на чистом Python (в
entropy.py) для расчета энтропии
bytearray, воспользуемся при этом только
математическим модулем из стандартной библиотеки. Эта функция не
оптимизирована, возьмем ее в качестве отправной точки для
модификаций и измерения производительности.
import mathdef compute_entropy_pure_python(data): """Compute entropy on bytearray `data`.""" counts = [0] * 256 entropy = 0.0 length = len(data) for byte in data: counts[byte] += 1 for count in counts: if count != 0: probability = float(count) / length entropy -= probability * math.log(probability, 2) return entropy
Python с NumPy и SciPy
Неудивительно, что в SciPy предоставляется функция для расчета энтропии. Но сначала мы воспользуемся функцией
unique() из NumPy для расчета частот байтов.
Сравнивать производительность энтропийной функции SciPy с другими
реализациями немного нечестно, так как в реализации из SciPy есть
дополнительный функционал для расчета относительной энтропии
(расстояния Кульбака-Лейблера). Опять же, мы собираемся провести
(надеюсь, не слишком медленный) тест-драйв, чтобы посмотреть,
какова будет производительность скомпилированных библиотек Rust,
импортированных из Python. Будем придерживаться реализации из
SciPy, включенной в наш скрипт entropy.py.
import numpy as npfrom scipy.stats import entropy as scipy_entropydef compute_entropy_scipy_numpy(data): """Вычисляем энтропию bytearray `data` с SciPy и NumPy.""" counts = np.bincount(bytearray(data), minlength=256) return scipy_entropy(counts, base=2)
Python с Rust
Далее мы несколько подробнее исследуем нашу реализацию на Rust, по сравнению с предыдущими реализациями, ради основательности и закрепления. Начнем с принимаемого по умолчанию библиотечного пакета, сгенерированного при помощи Cargo. В следующих разделах показано, как мы модифицировали пакет Rust.
cargo new --lib rust_entropyCargo.toml
Начинаем с обязательного файла манифеста
Cargo.toml, в
котором определяем пакет Cargo и указываем имя библиотеки,
rust_entropy_lib. Используем общедоступный контейнер
cpython (v0.4.1), доступный на сайте crates.io, в реестре пакетов
Rust Package Registry. В статье мы используем Rust v1.42.0,
новейшую стабильную версию, доступную на момент написания.
[package] name = "rust-entropy"version = "0.1.0"authors = ["Nobody <nobody@nowhere.com>"] edition = "2018"[lib] name = "rust_entropy_lib"crate-type = ["dylib"][dependencies.cpython] version = "0.4.1"features = ["extension-module"]
lib.rs
Реализация библиотеки Rust весьма проста. Как и в случае с нашей реализацией на чистом Python, мы инициализируем массив counts для каждого возможного значения байт и перебираем данные для наполнения counts. Для завершения операции вычисляем и возвращаем отрицательную сумму вероятностей, умноженную на
вероятностей.
use cpython::{py_fn, py_module_initializer, PyResult, Python};/// вычисляем энтропию массива байтfn compute_entropy_pure_rust(data: &[u8]) -> f64 { let mut counts = [0; 256]; let mut entropy = 0_f64; let length = data.len() as f64; // collect byte counts for &byte in data.iter() { counts[usize::from(byte)] += 1; } // вычисление энтропии for &count in counts.iter() { if count != 0 { let probability = f64::from(count) / length; entropy -= probability * probability.log2(); } } entropy}
Все, что нам остается взять из
lib.rs это механизм для
вызова чистой функции Rust из Python. Мы включаем в
lib.rs функцию, приспособленную к работе с CPython
(compute_entropy_cpython()) для вызова нашей чистой
функции Rust (compute_entropy_pure_rust()). Поступая
таким образом, мы только выигрываем, так как будем поддерживать
единственную чистую реализацию Rust, а также предоставим обертку,
удобную для работы с CPython.
/// Функция Rust для работы с CPython fn compute_entropy_cpython(_: Python, data: &[u8]) -> PyResult<f64> { let _gil = Python::acquire_gil(); let entropy = compute_entropy_pure_rust(data); Ok(entropy)}// инициализируем модуль Python и добавляем функцию Rust для работы с CPython py_module_initializer!( librust_entropy_lib, initlibrust_entropy_lib, PyInit_rust_entropy_lib, |py, m | { m.add(py, "__doc__", "Entropy module implemented in Rust")?; m.add( py, "compute_entropy_cpython", py_fn!(py, compute_entropy_cpython(data: &[u8]) ) )?; Ok(()) });
Вызов кода Rust из Python
Наконец, вызываем реализацию Rust из Python (опять же, из
entropy.py). Для этого сначала импортируем нашу
собственную динамическую системную библиотеку, скомпилированную из
Rust. Затем просто вызываем предоставленную библиотечную функцию,
которую ранее указали при инициализации модуля Python с
использованием макроса py_module_initializer! в нашем
коде Rust. На данном этапе у нас всего один модуль Python
(entropy.py), включающий функции для вызова всех
реализаций расчета энтропии.
import rust_entropy_libdef compute_entropy_rust_from_python(data): ""Вычисляем энтропию bytearray `data` при помощи Rust.""" return rust_entropy_lib.compute_entropy_cpython(data)
Мы собираем вышеприведенный библиотечный пакет Rust на Ubuntu 18.04 при помощи Cargo. (Эта ссылка может пригодиться пользователям OS X).
cargo build --release
Закончив со сборкой, мы переименовываем полученную библиотеку и копируем ее в тот каталог, где находятся наши модули Python, так, чтобы ее можно было импортировать из сценариев. Созданная при помощи Cargo библиотека называется
librust_entropy_lib.so, но ее потребуется
переименовать в rust_entropy_lib.so, чтобы успешно
импортировать в рамках этих тестов.Проверка производительности: результаты
Мы измеряли производительность каждой реализации функции при помощи контрольных точек pytest, рассчитав энтропию более чем для 1 миллиона случайно выбранных байт. Все реализации показаны на одних и тех же данных. Эталонные тесты (также включенные в entropy.py) показаны ниже.
# ### КОНТРОЛЬНЕ ТОЧКИ #### генерируем случайные байты для тестирования w/ NumPyNUM = 1000000VAL = np.random.randint(0, 256, size=(NUM, ), dtype=np.uint8)def test_pure_python(benchmark): """тестируем чистый Python.""" benchmark(compute_entropy_pure_python, VAL)def test_python_scipy_numpy(benchmark): """тестируем чистый Python со SciPy.""" benchmark(compute_entropy_scipy_numpy, VAL)def test_rust(benchmark): """тестируем реализацию Rust, вызываемую из Python.""" benchmark(compute_entropy_rust_from_python, VAL)
Наконец, делаем отдельные простые драйверные скрипты для каждого метода, нужного для расчета энтропии. Далее идет репрезентативный драйверный скрипт для тестирования реализации на чистом Python. В файле
testdata.bin 1 000 000 случайных байт,
используемых для тестирования всех методов. Каждый из методов
повторяет вычисления по 100 раз, чтобы упростить захват данных об
использовании памяти.
import entropywith open('testdata.bin', 'rb') as f: DATA = f.read()for _ in range(100): entropy.compute_entropy_pure_python(DATA)
Реализации как для SciPy/NumPy, так и для Rust показали хорошую производительность, легко обставив неоптимизированную реализацию на чистом Python более чем в 100 раз. Версия на Rust показала себя лишь немного лучше, чем версия на SciPy/NumPy, но результаты подтвердили наши ожидания: чистый Python гораздо медленнее скомпилированных языков, а расширения, написанные на Rust, могут весьма успешно конкурировать с аналогами на C (побеждая их даже в таком микротестировании).
Также существуют и другие методы повышения производительности. Мы могли бы использовать модули
ctypes или
cffi. Могли бы добавить подсказки типов и
воспользоваться Cython для генерации библиотеки, которую могли бы
импортировать из Python. При всех этих вариантах требуется
учитывать компромиссы, специфичные для каждого конкретного
решения.
Мы также измерили расход памяти для каждой реализации функции при помощи приложения GNU
time (не путайте со встроенной
командой оболочки time). В частности, мы измерили
максимальный размер резидентной части памяти (resident set
size).Тогда как в реализациях на чистом Python и Rust максимальные размеры этой части весьма схожи, реализация SciPy/NumPy потребляет ощутимо больше памяти по данному контрольному показателю. Предположительно это связано с дополнительными возможностями, загружаемыми в память при импорте. Как бы то ни было, вызов кода Rust из Python, по-видимому, не привносит серьезных накладных расходов памяти.

Итоги
Мы крайне впечатлены производительностью, достигаемой при вызове Rust из Python. В ходе нашей откровенно краткой оценки реализация на Rust смогла потягаться в производительности с базовой реализацией на C из пакетов SciPy и NumPy. Rust, по-видимому, отлично подходит для эффективной крупномасштабной обработки.
Rust показал не только отличное время выполнения; следует отметить, что и накладные расходы памяти в этих тестах также оказались минимальными. Такие характеристики времени выполнения и использования памяти представляются идеальными для целей масштабирования. Производительность реализаций SciPy и NumPy C FFI определенно сопоставима, но с Rust мы получаем дополнительные плюсы, которых не дают нам C и C++. Гарантии по безопасности памяти и потокобезопасности это очень привлекательное преимущество.
Тогда как C обеспечивает сопоставимое с Rust время выполнения, C как таковой не предоставляет потокобезопасности. Существуют внешние библиотеки, обеспечивающие такой функционал для C, но за правильность их использования полностью отвечает разработчик. Rust следит за проблемами потокобезопасности, например, за возникновением гонок, во время компиляции благодаря реализованной в нем модели владения а стандартная библиотека предоставляет комплект механизмов конкурентности, среди которых каналы, блокировки и умные указатели с подсчетом ссылок.
Мы не призываем портировать SciPy или NumPy на Rust, так как эти библиотеки Python уже хорошо оптимизированы и поддерживаются классными сообществами разработчиков. С другой стороны, мы настоятельно рекомендуем портировать с чистого Python на Rust такой код, который не предоставляется в высокопроизводительных библиотеках. В контексте приложений для data science, используемых для анализа безопасности, Rust представляется конкурентоспособной альтернативой для Python, учитывая его скорость и гарантии безопасности.


 Положительная и отрицательная асимметрии
Положительная и отрицательная асимметрии





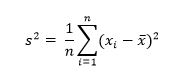



















 посчитать вручную, для определения p-value использовать
регуляризованную гамма-функцию.
посчитать вручную, для определения p-value использовать
регуляризованную гамма-функцию.