Сегодня в пятничном формате хотел бы рассказать об одном из
своих пет-проектов, чем интересным пришлось заниматься во время
работы над ним и какие вопросы мне так и не удалось решить для его
дальнейшего развития.
И так, у меня было достаточно много пет-проектов разной степени
готовности. Среди них: социальная сеть для писателей, генератор
CSS-спрайтов, Телеграм бот для знакомств по интересам и многое
другое. Сегодня речь пойдёт о моей последней разработке.
Как многие в наши дни, я учу английский. Думаю, так же многие
знают, что эффективным подходом в этом деле является максимальное
погружение в среду. Интерфейс телефона на английском, записи в
блокноте на английском, смотреть кино на английском с английскими
субтитрами. Смотря кино в оригинале, рано или поздно возникает
потребность перевести то или иное слово или фразу, которые мелькают
на экране каждые несколько минут. Без них вообще ничего не
понятно.
Идея проекта
Так у меня и родилась идея видеоплеера с переводимыми
субтитрами. Приложение позволяет переводить слова и целые фразы
прямо во время просмотра кино. С ним отпадает необходимость
переключаться между приложениями или брать в руки смартфон.
Знакомьтесь LinguaPlayer.
Схема работы простая. Пользователь открывает файл с фильмом и
файл субтитров. Смотрит фильм как обычно. Однако теперь в его
распоряжении помимо стандартных горячих клавиш есть клавиши для
перевода каждого слова по отдельности, перевода целых предложений,
перемотки от реплики к реплике. Также присутствует перевод
посредством наведения курсора мыши на слова или выделения нужного
куска текста. Приложение доступно для Windows и MacOS. Все
подробности можно почитать на страничке приложения.
Технологический стек
Плеер реализован на платформе Electron, т. е. по сути это
браузер Chromium внутри которого бежит обычное веб-приложение. На
этой технологии построено большое количество различных приложений
удачных и не очень. Наиболее известные примеры это Visual Studio
Code, Skype, Slack. Electron предоставляет некоторые системные API,
которые недоступны JavaScript, запущенному в обычном браузере. Это
позволяет делать приложения более функциональными и близкими по
возможностям и пользовательскому опыту к нативным. Что касается
всего остального разработчику доступен абсолютно любой стек,
применимый в вебе. Будь то чистый JavaScript, Angular, jQuery, Vue
что угодно.
Для LinguaPlayer я выбрал привычный стек, с которым работаю
каждый день: TypeScript, React, MobX, Webpack. Я планировал сделать
прототип за вечер, так как задача выглядела легко: дал приложению
файл с видео и файл с субтитрами, прикрутил переводчик и готово. С
этой частью проблем не возникло. Однако, как оказалось, встроенный
в браузеры движок отображения субтитров не имеет никаких средств
взаимодействия с текстом реплик. Что я имею в виду. Реплики титров
хоть и появляются поверх видео, но в DOM никаких упоминаний о них
нет. Другими словами, нет возможности распарсить текст, разбить его
по словам и предложениям, повесить обработчики нажатий клавиш или
зарегистрировать события мыши.
Решение интересных задач
Таким образом, мне пришлось решить две задачи. Первая это
парсинг srt-файлов с титрами с последующей синхронизацией реплик с
видеопотоком. Вторая разбивка реплик на токены, чтобы была
возможность взаимодействовать с каждым словом и предложением по
отдельности.
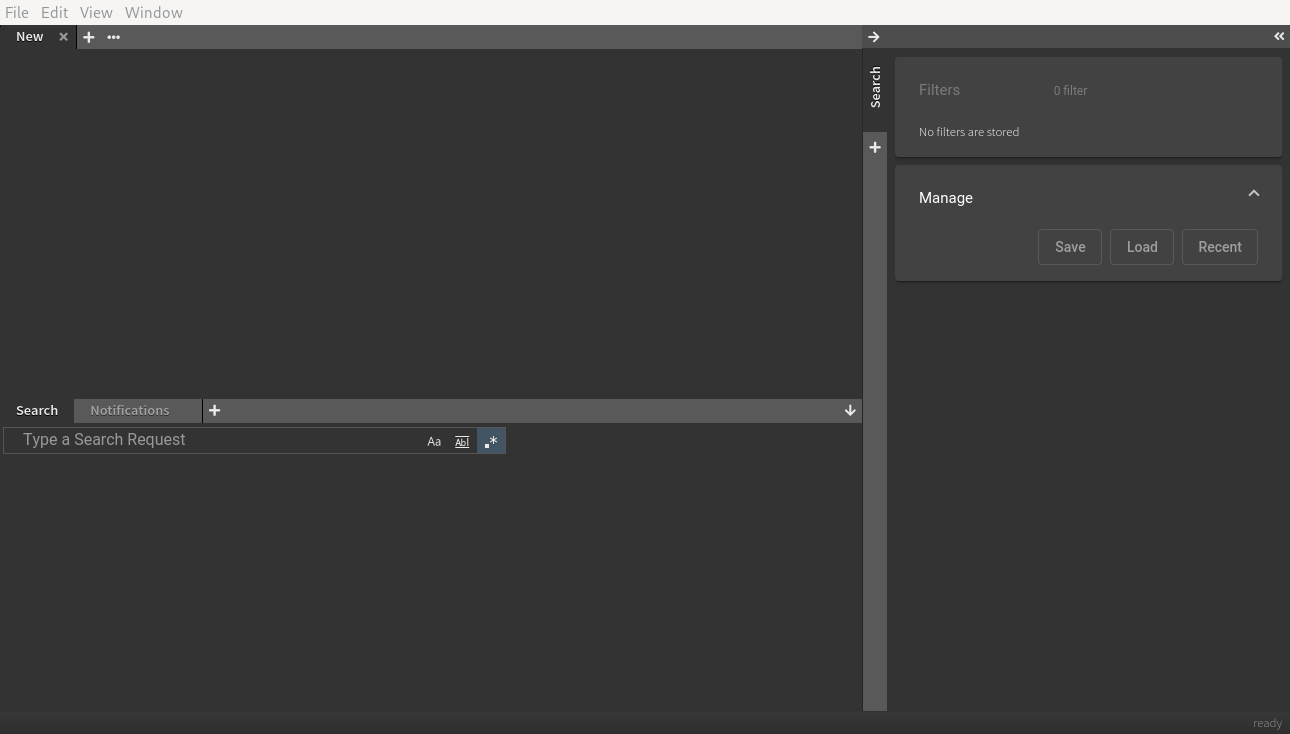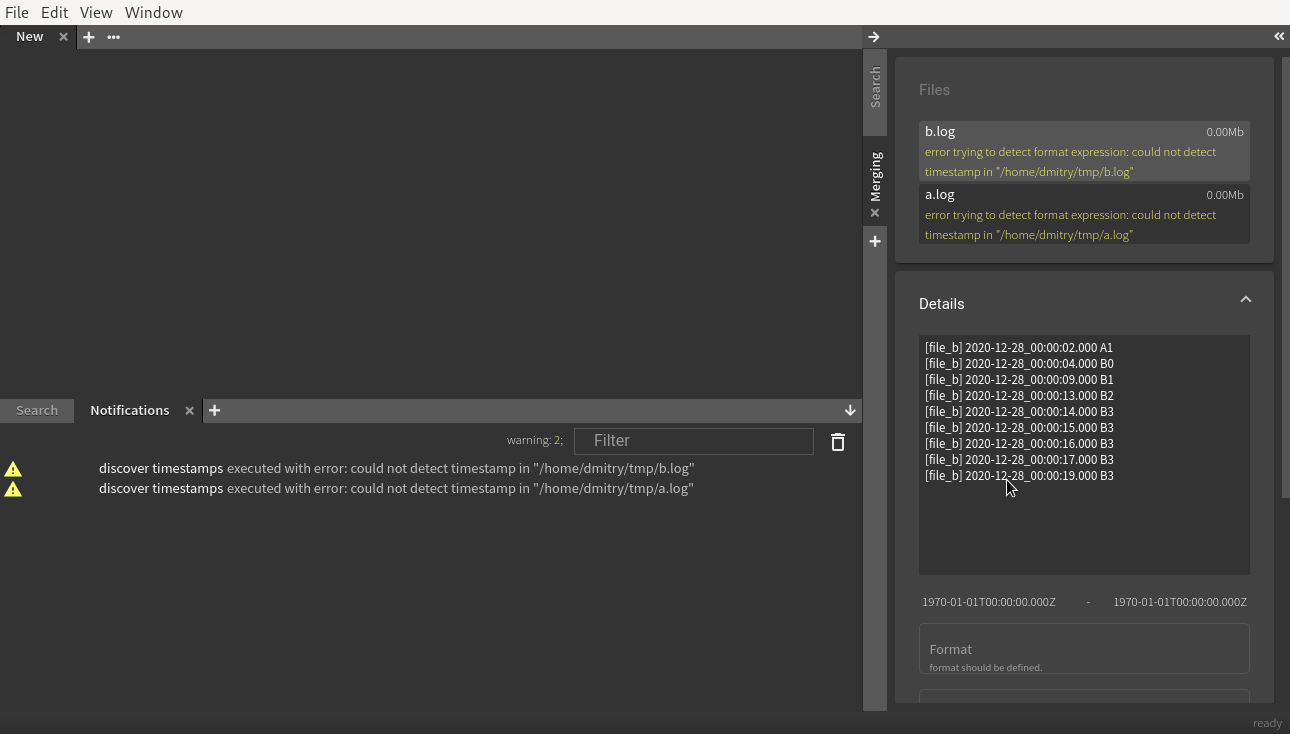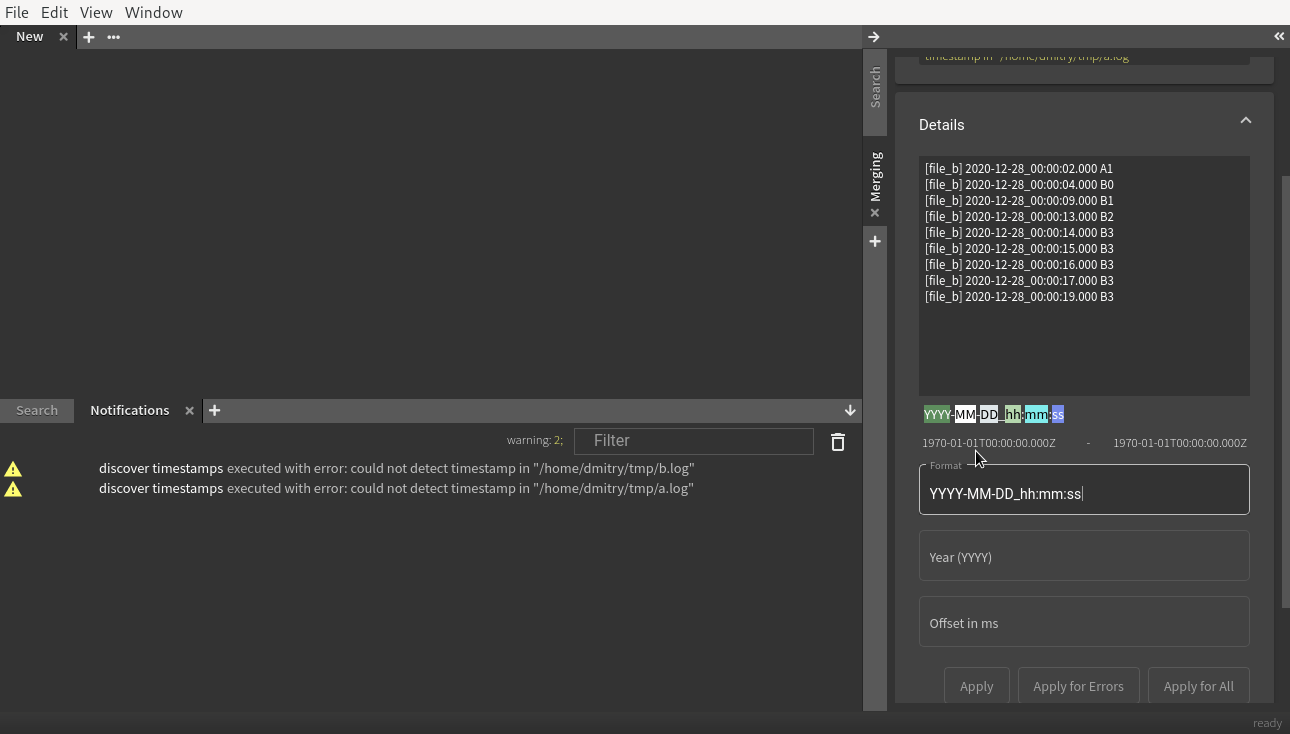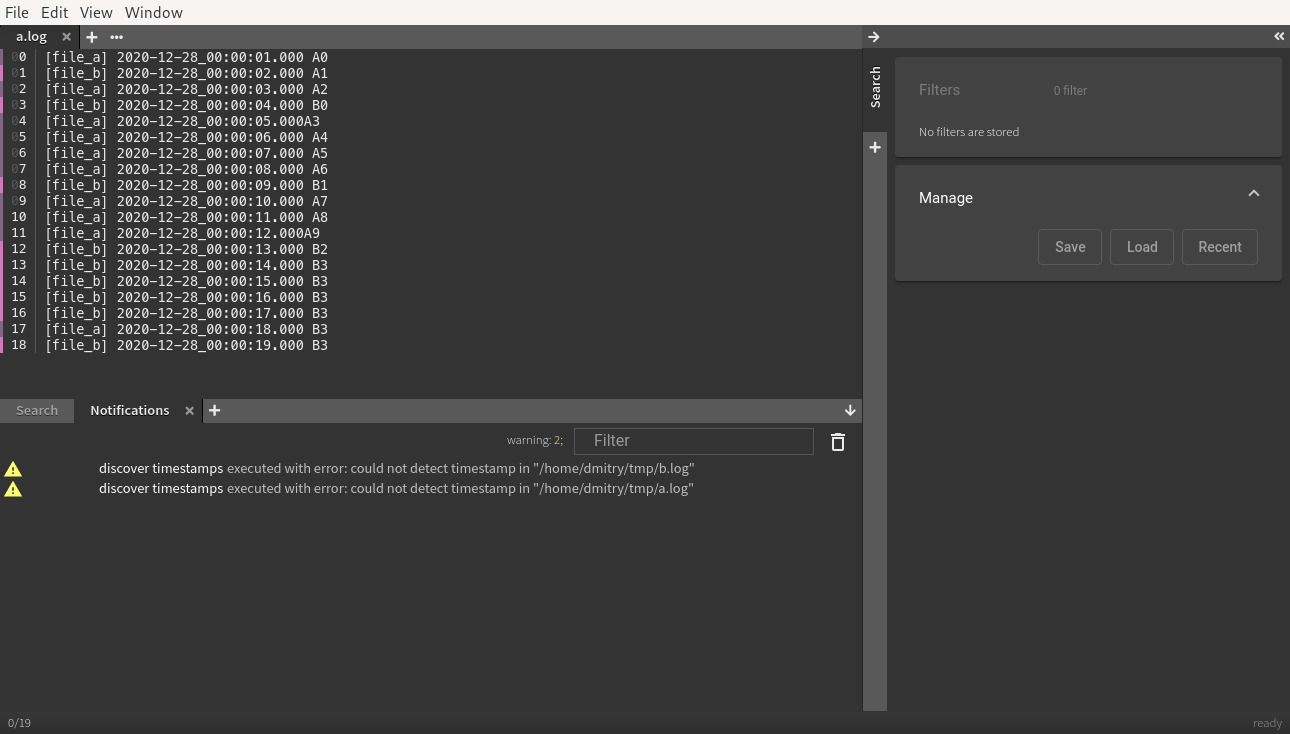
Для парсинга титров я взял библиотекуnode-webvtt. Для синхронизации
титров изначально я написал логику в лоб. Подписавшись на событие
video-элемента timeupdate, я просто ходил
по массиву реплик и сравнивал текущее время видео с временем
реплик. Однако, событие timeupdate срабатывает четыре раза за
секунду, а реплик в среднем фильме несколько тысяч. Всё это дело
жутко тормозило.
Для оптимизации данного процесса я сделал простой hash map. Его
ключом является секунда (целая, без миллисекунд), а значением
массив номеров реплик, которые должны быть показаны в эту секунду.
Выглядело это примерно так:
{// на пятой секунде 2 реплики5: [1, 2]// на седьмой секунде 3 короткие реплики7: [3, 4, 5]}
В каждой секунде может быть от 0 до примерно 4 реплик человек
имеет ограничения и вряд ли сможет прочитать большее количество
текста за секунду. Таки образом, при обновлении времени
воспроизведения, всё что необходимо сделать, это выделить из него
целую часть и обратиться с этим значением к hash map. Если на этой
секунде реплик нет, значит ничего больше не делаем. Если на этой
секунде есть реплики, то итерируемся по вернувшемуся массиву и
ищем, какая именно реплика должна быть показана сейчас. Так как на
секунду может быть до 4 реплик, то цикл завершается быстро.
Возможно, многим будет проще воспринять описанный алгоритм в виде
кода:
// Объект реплики: порядковый номер, время начала отображения (в миллисекундах), время конца отображения, текстclass Cue { public readonly index: number; public readonly startTime: number; public readonly endTime: number; public readonly text: string; constructor(index: number, startTime: number, endTime: number, text: string) { this.index = index; this.startTime = startTime; this.endTime = endTime; this.text = text; }}interface CueIndex { // Ключ индекса это целая секунда (без миллисекунд) и массив порядковых номеров реплик, // которые начинают или заканчиваются в течение этой секунды [key: number]: number[];}class SubtitlesTrack { private readonly cues: Cue[]; private index: CueIndex = {}; constructor(cues: Cue[]) { this.cues = cues; // На входе у нас просто массив реплик, нужно проиндексировать this.indexCues(); } private indexCues() { this.cues.forEach((cue: Cue) => { // Переводим время начала и конца реплики из миллисекунд в секунды и берём только целую часть const startSecond = Math.floor(cue.startTime / 1000); const endSecond = Math.floor(cue.endTime / 1000); // Добавляем реплику (её порядковый номер) в индекс this.addToIndex(startSecond, cue); // Бывает, что реплика началась в одной секунде, и отображается до следующей или даже держится несколько секунд // Такую реплику следуют добавить также в индекс секунды окончания if (endSecond !== startSecond) { this.addToIndex(endSecond, cue); } }); } private addToIndex(secondNumber: number, cue: Cue): void { // Если это первая реплика в данной секунде, инициализируем ключ индекса пустым массивом if (!this.index[secondNumber]) { this.index[secondNumber] = []; } // Затем в массив реплик добавим порядковый номер новой реплики this.index[secondNumber].push(cue.index); } // Метод поиска реплики public findCueForTime(timeInSeconds: number): Cue|null { // Событие плеера timeupdate присылает время сразу в секундах // Поэтому сразу берём целую часть const flooredTime = Math.floor(timeInSeconds); // Выбираем проиндексированные реплики для этой секунды const cues = this.index[flooredTime]; let currentCue = null; // Если на данной секунде есть реплики if (cues) { // Проходимся по каждой for (let index of cues) { const cue = this.cues[index]; // И смотрим, совпадает ли интервал времени начала и конца реплики с текущем временем в плеере if (this.isCueInTime(timeInSeconds, cue)) { // Если да, то устанавливаем значение текущей реплики и останавливаем цикл currentCue = cue; break; } } } // Вернём текущую реплику или null, если для данного времени реплики нет return currentCue; } public isCueInTime(timeInSeconds: number, cue: Cue): boolean { const timeInMilliseconds: number = timeInSeconds * 1000; return timeInMilliseconds >= cue.startTime && timeInMilliseconds <= cue.endTime; }}
Таким образом, вместо того, чтобы 4 раза в секунду обходить
массив из тысяч элементов, необходимо лишь сделать одно обращение
по индексу, и пройтись по массиву длинной от 1 до 4.
Перед тем как выводить получаемые реплики я разбивал их на
предложения и на слова с помощью библиотекиnode-sentence-tokenizer. Всё
это дело я оборачивал в элементы div с классами sentence и word
соответственно, чтобы иметь возможность вешать на них события в
дальнейшем и выполнять перевод. Вот так выглядит код:
import Tokenizer from 'sentence-tokenizer';function formatCue(text: string): string { const brMark: string = '[br]'; const tokenizer = new Tokenizer(); // Заменяем переносы строк на псевдотэг для удобной работы с переносами в дальнейшем text = text .replace(/\r\n/g, ` ${brMark}`) .replace(/\r/g, ` ${brMark}`) .replace(/\n/g, ` ${brMark}`); // Устанавливаем text как сущность для обработки tokenizer.setEntry(text); // Разбиваем текст на предложения const sentenceTokens: string[] = tokenizer.getSentences(); // Проходимся по предложениям const sentencesHtml: string[] = sentenceTokens.map((sentenceToken: string, index: number) => { // Разбиваем предложение по словам const wordTokens: string[] = tokenizer.getTokens(index); // Идём по каждому слову const wordsHtml: string[] = wordTokens.map((wordToken: string) => { let brTag: string = ''; // Если после слова есть псевдотэг переноса, удаляем его и устанавливаем html тэг переноса строки if (wordToken.includes(brMark)) { wordToken = wordToken.replace(brMark, ''); brTag = '<br/>'; } // Оборачиваем слово в span с классом word и добавляем тэг br, если надо return `${brTag}<span class="word">${wordToken}</span>`; }); // Склеиваем слова обратно, в строку, оборачиваем предложение в в span с классом sentence return `<span class="sentence">${wordsHtml.join(' ')}</span>`; }); // Склеиваем предложение обратно в строку const html: string = sentencesHtml.join(' '); return html;}
Далее я прикрутилMicrosoft Translatorдля
осуществления перевода, и плеер для изучения английского был
готов.
Чего не хватает проекту, чтобы развиваться
Конечно, на данный момент плеер даже не является MVP, это скорее
proof of concept. И у меня есть множество идей по развитию данного
проекта. В первую очередь хочется добавить поддержку словарей,
например английского и англо-русского, а также интегрировать Urban
Dictionary для распознавания сленга, а также различных современных
слов и фраз. Во вторую очередь есть мысль реализовать интеграции с
сервисами по изучению иностранных языков, такими какLinguaLeoилиSkyeng. Это позволило бы
добавлять незнакомые слова в персональный словарь на сервисе и
учить их позже. Или же импортировать свой словарь вAnki. Также можно было бы
добавить поддержку изучения других языков.
Но, прежде чем приступить к реализации задуманных функций,
необходимо решить ряд технических и концептуальных проблем. Моя
изначальная идея заключалась в том, чтобы можно было смотреть свои
старые и излюбленные фильмы, пылящиеся на жёстком диске. И здесь
возникает серьёзная техническая проблема, а именно слабая поддержка
кодеков в браузере Chromium. Глядя насписок поддерживаемых форматов,
можно заметить, что по факту в приложении можно проиграть лишь
файлы с видеокодеком H.264 и аудиокодеком FLAC либо MP3. Нужно
очень постараться чтобы найти именно такой файл. Да никто и не
будет заниматься подобным сейчас все избалованы стриминговыми
сервисами. Не говоря уже о вопросах лицензирования, что является
большой, концептуальной проблемой.
Таким образом, главный блокирующий фактор сейчас это контент. Он
должен без проблем играть в приложении, должна быть возможность
легко и быстро его получать, а также, он не должен нарушать
лицензии и авторские права. Как только удастся решить вопрос с
контентом, я с радостью продолжу работу над проектом. А пока, если
кому интересно, можноскачать и
попробоватьконцепт-версию приложения.












 Текущая статистика запусков 2020 года
Текущая статистика запусков 2020 года

 Патчи и логотипы миссии
Патчи и логотипы миссии Легенда к статистике
Легенда к статистике Текущая статистика запусков 2020 года
Текущая статистика запусков 2020 года
 Инфографика текущего запуска
Инфографика текущего запуска
 Эмблемы и нашивки миссии
Эмблемы и нашивки миссии Легенда к статистике
Легенда к статистике
 Разработчица Екатерина демонстрирует
работу функции печати QR-кода на чеке
Разработчица Екатерина демонстрирует
работу функции печати QR-кода на чеке

") Архитектура Кассы Мойсклад (упрощённая)
Архитектура Кассы Мойсклад (упрощённая)