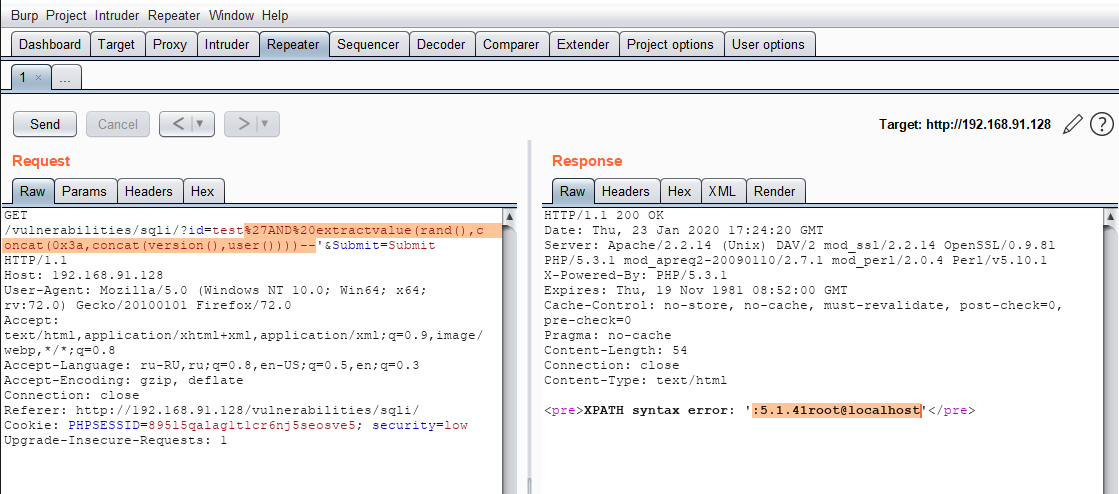
Не секрет, что реализация механизмов безопасности IoT-устройств далека от совершенства. Известные категории уязвимостей умных устройств хорошо описаны в Top IoT Vulnerabilities от 2018 года. Предыдущая версия документа от 2014 года претерпела немало изменений: некоторые пункты исчезли совсем, другие были обновлены, появились и новые.
Чтобы показать актуальность этого списка, мы нашли примеры уязвимых IoT-устройств для каждого типа уязвимостей. Наша цель продемонстрировать риски, с которыми пользователи умных устройств сталкиваются ежедневно.
Уязвимые устройства могут быть совершенно разными от детских игрушек и сигнализаций до автомобилей и холодильников. Некоторые устройства встречаются в нашем списке не один раз. Все это, конечно же, служит показателем низкого уровня безопасности IoT-устройств вообще.

За подробностями следуйте под кат.
I1 Слабые, предсказуемые и жестко закодированные пароли
Использование уязвимых к брутфорсу, публично доступных (например, из инструкции) или неизменяемых паролей, включая бэкдоры в прошивке или клиентский софт, который дает возможность неавторизованного доступа к системе.
| Тип устройства | Название | CWE | Недостаток безопасности |
|---|---|---|---|
 |
Routers Netgear | CWE-601: URL Redirection to Untrusted Site ('Open Redirect') | Кто угодно из сети может воспользоваться путаницей в конфигурации, чтобы получить контроль над устройством, изменять настройки DNS и перенаправлять браузер на зараженные сайты. |
 |
Loxone Smart Home | CWE-261: Weak Encoding for Password | Злоумышленник может получить доступ к паролям пользователей, а следовательно, и к их аккаунтам. |
|
AGFEO smart home ES 5xx/6xx | CWE-261: Weak Encoding for Password | Злоумышленник может получить доступ к паролям пользователей, а следовательно, и к их аккаунтам. |
 |
Industrial wireless access point Moxa AP | CWE-260: Password in Configuration File | Злоумышленник может войти с парой логин-пароль от учетной записи администратора, указанной в инструкции, и получить доступ к управлению всей системой. |
 |
Heatmiser Thermostat | CWE-260: Password in Configuration File | Злоумышленник может войти с парой логин-пароль от учетной записи администратора, указанной в инструкции, и получить доступ к управлению всей системой. |
 |
Digital video recorder Mvpower | CWE-521: Weak Password Requirements | Учетная запись администратора не требует пароль при входе, поэтому доступ к ней может получить кто угодно. |
 |
DBPOWER U818A WIFI quadcopter drone | CWE-276: Incorrect Default Permissions | Злоумышленник может получить доступ к файловой системе, используя возможность анонимного доступа без пароля. |
|
Nuuo NVR (network video recorder) and Netgear | CWE-259: Use of Hard-coded Password | Злоумышленник может получить привилегии администратора, а значит, и полный контроль над системой из-за жестко закодированного пароля. |
 |
Vacuum Cleaner LG | CWE-287: Improper Authentication | Злоумышленник может обойти аутентификацию и получить доступ к видеозаписям с устройства. |
 |
Eminent EM6220 Camera | CWE-312: Cleartext Storage of Sensitive Information | В инструкции указан пароль 123456, который большинство пользователей установят не задумываясь и сделают свое устройство уязвимым. |
 |
LIXIL Satis Toilet | CWE-259: Use of Hard-coded Password | Пароль для подключения устройства по Bluetooth хранится в открытом виде в коде, что дает злоумышленнику возможность управлять работой умного унитаза по собственному желанию и против воли владельца. |
 |
FUEL Drill | CWE-259: Use of Hard-coded Password | Злоумышленник может найти жестко закодированный пароль и получить права администратора и управлять устройством. |
|
Billion Router 7700NR4 | CWE-798: Use of Hard-coded Credentials | Жестко закодированные учетные данные дают злоумышленнику возможность получить полный контроль над устройством. |
 |
Canon Printers | CWE-269: Improper Privilege Management & CWE-295: Improper Certificate Validation | Злоумышленник может получить доступ к незащищенному устройству и обновить прошивку, потому что логин и пароль не требуются для доступа к устройству. |
|
Parrot AR.Drone 2.0 | CWE-285: Improper Authorization | Пустая пара логин-пароль дает возможность злоумышленнику подключиться к дрону и управлять им. |
|
Camera Amazon Ring | CWE-285: Improper Authorization | Злоумышленник может использовать для авторизации учетные данные по умолчанию. |
I2 Небезопасные сетевые подключения
Избыточные или небезопасные подключения (особенно с доступом к Интернету) могут компрометировать конфиденциальность, целостность/аутентичность или доступность информации или предоставить возможность неавторизованного удаленного контроля над устройством.
| Тип устройства | Название | CWE | Недостаток безопасности |
|---|---|---|---|
 |
Smart Massager | CWE-284: Improper Access Control | Злоумышленник может изменить параметры массажера и причинить пользователю боль, вызвать ожог кожи и нанести вред здоровью. |
|
Implantable Cardiac Device | CWE-284: Improper Access Control | Злоумышленник может изменить настройки имплантируемого устройства, что может увеличить расход батареи и/или нанести вред здоровью. |
|
Hikvision Wi-Fi IP Camera | CWE-284: Improper Access Control | Злоумышленник может удаленно управлять камерой и даже отключить ее. |
|
Foscam C1 Indoor HD Cameras | CWE-120: Buffer Copy without Checking Size of Input ('Classic Buffer Overflow') | Удаленное исполнение кода на камерах может привести к утечке чувствительной пользовательской информации. |
 |
Toy Furby | CWE-284: Improper Access Control | Злоумышленник может внести изменения в прошивку и использовать Ферби для слежки за детьми. |
|
Toy My Friend Cayla | CWE-284: Improper Access Control | Злоумышленник может следить за пользователями и собирать информацию о них. |
 |
iSmartAlarm | CWE-20: Improper Input Validation | Злоумышленник может "заморозить" будильник, и он перестанет будить. |
|
iSPY Camera Tank | CWE-284: Improper Access Control | Злоумышленник может залогиниться на устройстве как анонимный пользователь и заполучить контроль над файловой системой устройства. |
 |
DblTek GoIP | CWE-598: Information Exposure Through Query Strings in GET Request | Злоумышленник может отправить команды для изменения конфигурации или выключить устройство. |
|
Nuuo NVR (network video recorder) and Netgear | CWE-259: Use of Hard-coded Password | Злоумышленник может получить привилегии администратора, изменять настройки устройства и даже следить за пользователями. |
|
Sony IPELA Engine IP Cameras | CWE-287: Improper Authentication | Злоумышленник может использовать камеру для отправки фото и видео, добавить камеру в ботнет Mirai или следить за пользователями. |
|
iSmartAlarm | CWE-295: Improper Certificate Validation | Злоумышленник может получить пароль или другие пользовательские данные с помощью поддельного SSL-сертификата. |
|
Routers Dlink 850L | CWE-798: Use of Hard-coded Credentials | Из-за небезопасного сетевого подключения злоумышленник может получить полный контроль над устройством. |
 |
Amazons Ring Video Doorbell | CWE-419: Unprotected Primary Channel | Учетные данные для подключения к устройству передаются по незащищенному каналу связи. |
|
Cacagoo IP camera | CWE-287: Improper Authentication | Злоумышленник может воспользоваться возможностью неавторизованного доступа к устройству, а затем управлять им. |
|
Trifo Ironpie M6 Vacuum cleaner | CWE-284: Improper Access Control | Злоумышленник может удаленно подключиться к устройству и управлять им. |
I3 Небезопасные интерфейсы экосистем
Небезопасные бэкенд API, веб, облачные и мобильные интерфейсы в экосистеме вне устройства, через которые можно скомпрометировать устройство или связанные с ним компоненты. Среди распространенных проблем: отсутствие аутентификации/авторизации, отсутствующее или слабое шифрование, отсутствие фильтрации ввода/вывода.
| Тип устройства | Название | CWE | Недостаток безопасности |
|---|---|---|---|
|
Industrial wireless access point Moxa AP | CWE-79: Improper Neutralization of Input During Web Page Generation ('Cross-site Scripting') | Злоумышленник может получить доступ к сессии, которая никогда не истечет. |
|
AXIS cameras | CWE-20: Improper Input Validation | Злоумышленник может изменить любой файл в системе, получив права администратора. |
|
Belkins smart home products | CWE-79: Improper Neutralization of Input During Web Page Generation ('Cross-site Scripting') & CWE-89: Improper Neutralization of Special Elements used in an SQL Command ('SQL Injection') | Злоумышленник может получить достук к телефону и чувствительной информации. |
|
Routers D-Link DIR-300 | CWE-352: Cross-Site Request Forgery (CSRF) | Злоумышленник может изменить пароль от учетной записи администратора и получить его привилегии. |
|
AVTECH IP Camera, NVR, DVR | CWE-79: Improper Neutralization of Input During Web Page Generation ('Cross-site Scripting') | Злоумышленник может изменять настройки устройства через атаку CSRF (например, пароли пользователей). |
|
AGFEO smart home ES 5xx/6xx | CWE-79: Improper Neutralization of Input During Web Page Generation ('Cross-site Scripting') | Злоумышленник может получить доступ ко всем файлам, хранящимся в системе. Он может изменить конфигурацию устройства и установить нелегитимное обновление. |
|
Loxone Smart Home | CWE-79: Improper Neutralization of Input During Web Page Generation ('Cross-site Scripting') | Все функции устройства могут контролироваться злоумышленником через команды веб-интерфейса. |
 |
Switch TP-Link TL-SG108E | CWE-79: Improper Neutralization of Input During Web Page Generation ('Cross-site Scripting') | Злоумышленник может реализовать XSS-атаку на устройство и "заставить" администратора выполнить Javascript-код в браузере. |
|
Hanbanggaoke IP Camera | CWE-650: Trusting HTTP Permission Methods on the Server Side | Злоумышленник может изменить пароль администратора и получить его привилегии. |
|
iSmartAlarm | CWE-287: Improper Authentication | Злоумышленник может отправлять команды на устройство, включать и выключать его. |
 |
Western Digital My Cloud | CWE-287: Improper Authentication | Злоумышленник может получить полный контроль над устройством. |
 |
In-Flight Entertainment Systems | CWE-287: Improper Authentication | Злоумышленник может контролировать средства информирования пассажиров. Например, может подделать данные о полете (высота, скорость и пр.). |
 |
Smart key KeyWe | CWE-327: Use of a Broken or Risky Cryptographic Algorithm | Злоумышленник может узнать закрытый ключ, чтобы открыть дверь. |
I4 Отсутствие безопасного механизма обновлений
Отсутствие возможности безопасно обновить устройство. Включает в себя отсутствие валидации прошивки, отсутствие безопасной доставки обновлений на устройство (незашифрованная передача), отсутствие механизмов, запрещающих откат к старым версиям прошивки, отсутствие уведомлений об обновлениях, связанных с безопасностью.
| Тип устройства | Название | CWE | Недостаток безопасности |
|---|---|---|---|
|
Devices by GeoVision | CWE-295: Improper Certificate Validation | Злоумышленник может обновить прошивку устройства без авторизации. |
|
Canon Printers | CWE-295: Improper Certificate Validation | Механизм аутентификации отсутствует: кто угодно может получить доступ к устройству и обновить/изменить прошивку. |
|
Smart Nest Thermostat | CWE-940: Improper Verification of Source of a Communication Channel | Прошивка доставляется на устройство по незащищенному протоколу передачи данных, и нет возможности проверить ее легитимность. |
I5 Использование небезопасных или устаревших компонентов
Использование недопустимых или небезопасных программных компонентов и/или библиотек, из-за которых устройство может быть скомпрометировано. Сюда относятся небезопасная кастомизация ОС и использование стороннего софта или железа, полученного через скомпрометированную цепочку поставок.
| Тип устройства | Название | CWE | Недостаток безопасности |
|---|---|---|---|
 |
Amazon Echo | CWE-1233: Improper Hardware Lock Protection for Security Sensitive Control | Злоумышленник при помощи паяльника может изменить конфигурацию колонки, и превратить ее в устройство для прослушки. |
 |
Light bulb | CWE-1233: Improper Hardware Lock Protection for Security Sensitive Controls | Злоумышленник может перепаять элементы лампы. |
I6 Недостаточная защита приватности
Персональные данные пользователей хранятся на устройстве или в экосистеме, которые используются небезопасным или ненадлежащим образом, или без соответствующих на то прав.
| Тип устройства | Название | CWE | Недостаток безопасности |
|---|---|---|---|
 |
Gator 2 smartwatch | CWE-359: Exposure of Private Information ('Privacy Violation') | Злоумышленник может получить доступ к информации о версии прошивки, IMEI, времени, методе определения локации (GPS/Wi-Fi), координатах и уровне заряда батареи. |
|
Routers D-Link DIR-600 and DIR-300 | CWE-200: Information Exposure | Злоумышленник может получить доступ к чувствительной информации об устройстве или сделать его частью ботнета. |
 |
Samsung Smart TV | CWE-200: Information Exposure | Злоумышленник может получить доступ к бинарным файлам или аудиозаписям, хранящимся в системе телевизора. |
|
Home security camera | CWE-359: Exposure of Private Information ('Privacy Violation') | Фотографии пользователя могут быть украдены злоумышленником и опубликованы в сети. |
 |
Smart sex toys We-Vibe | CWE-359: Exposure of Private Information ('Privacy Violation') | Злоумышленник может получить информацию о температуре устройства и интенсивности его вибрации. |
|
iBaby M6 baby monitor | CWE-359: Exposure of Private Information ('Privacy Violation') | Злоумышленник может просмотреть информацию, включая детали видеозаписи. |
I7 Небезопасная передача и хранение данных
Отсутствие шифрования или контроля доступа к чувствительной информации внутри экосистемы при хранении, передаче или обработке.
| Тип устройства | Название | CWE | Недостаток безопасности |
|---|---|---|---|
|
Owlet Wi-Fi baby heart monitor | CWE-201: Information Exposure Through Sent Data | Злоумышленник может следить за детьми и родителями через камеру. |
 |
Samsung fridge | CWE-300: Channel Accessible by Non-Endpoint ('Man-in-the-Middle') | Злоумышленник может заполучить учетные данные от Google-аккаунтов жертв. |
 |
Volkswagen car | CWE CATEGORY: Cryptographic Issues | Злоумышленник может получить удаленный доступ к управлению машиной. |
 |
HS-110 Smart Plug | CWE-201: Information Exposure Through Sent Data | Злоумышленник может контролировать работу вилки, например, выключить подсветку. |
|
Loxone Smart Home | CWE-201: Information Exposure Through Sent Data | Злоумышленник может контролировать каждое устройство, работающее в системе умного дома, и получить права доступа пользователя. |
|
Samsung Smart TV | CWE-200: Information Exposure | Злоумышленник может прослушивать беспроводную сеть и инициировать атаку брутфорсом, чтобы восстановить ключ и дешифровать трафик. |
|
Routers Dlink 850L | CWE-319: Cleartext Transmission of Sensitive Information | Злоумышленник может удаленно контролировать устройство. |
 |
Skaterboards Boosted, Revo, E-Go | CWE-300: Channel Accessible by Non-Endpoint ('Man-in-the-Middle') | Злоумышленник может отправлять различные команды, чтобы управлять скейтом. |
|
LIFX smart LED light bulbs | CWE-327: Use of a Broken or Risky Cryptographic Algorithm | Злоумышленник может перехватывать и дешифровать трафик, включая данные о конфигурации сети. |
|
Stuffed toys | CWE-521: Weak Password Requirements | Аудиозаписи пользователей хранятся так, что доступ к ним может получить злоумышленник. |
|
IoT Smart Deadbolt | CWE-922: Insecure Storage of Sensitive Information | Злоумышленник может получить доступ к чувствительной информации, хранящейся на устройстве. |
|
Router ASUS | CWE-200: Exposure of Sensitive Information to an Unauthorized Actor | Злоумышленник может получить доступ к чувствительной пользовательской информации. |
I8 Отсутствие возможности настройки устройства
Отсутствие поддержки безопасности устройств, выпущенных в производство, включая управление обновлениями, безопасное снятие с эксплуатации, системный мониторинг, средства реагирования.
| Тип устройства | Название | CWE | Недостаток безопасности |
|---|---|---|---|
|
TP-LINK IP Surveillance Camera | CWE-? (не удалось подобрать CWE) | Злоумышленник может беспрепятственно эксплуатировать уязвимость в устройстве, так как оно устарело и не обновляется. |
I9 Небезопасные настройки по умолчанию
Устройства или системы, которые поставляются с небезопасными заводскими настройками или без возможности ограничить изменения конфигурации пользователями, чтобы повысить защищенность системы.
| Тип устройства | Название | CWE | Недостаток безопасности |
|---|---|---|---|
 |
ikettle Smarter Coffee machines | CWE-15: External Control of System or Configuration Setting | Злоумышленник может получить полный контроль над устройством из-за того, что большинство пользователей не настраивают кофемашины под себя, а оставляют их с заводскими небезопасными настройками. |
|
Parrot AR.Drone 2.0 | CWE-284: Improper Access Control | Настройки дрона предполагают возможность неавторизованного подключения к нему и управления им. |
|
HP Fax machine | CWE-276: Incorrect Default Permissions | Злоумышленник может воспользоваться неправильными настройками факса и полным отсутствием механизмов безопасности. |
|
Smart speakers | CWE-1068: Inconsistency Between Implementation and Documented Design | Колонки активируются словами, не указанными в инструкции, и прослушивают происходящие. |
I10 Отсутствие физической защиты
Отсутствие физической защиты позволяет потенциальному злоумышленнику получить доступ к чувствительной информации, которая может быть полезна при удаленной атаке или для получения контроля над устройством.
| Тип устройства | Название | CWE | Недостаток безопасности |
|---|---|---|---|
|
Baby monitors Mi-Cam | CWE-284: Improper Access Control | Злоумышленник может следить за пользователями. |
|
TOTOLINK router | CWE-20: Improper Input Validation | Злоумышленник может внедрить бэкдор. |
|
Router TP-Link | CWE-284: Improper Access Control | Злоумышленник может получить привилегии администратора и сделать устройство частью ботнета через незащищенный UART. |
|
Smart Nest Thermostat | CWE-284: Improper Access Control | Злоумышленник может загрузить процессор через периферийное устройство по USB или UART. |
|
Blink XT2 Sync Module | CWE-1233: Improper Hardware Lock Protection for Security Sensitive Controls | Незащищенный разъем позволяет злоумышленнику подключиться к устройству. |
|
Amazon Echo | CWE-1233: Improper Hardware Lock Protection for Security Sensitive Controls | Злоумышленник при помощи паяльника может изменить конфигурацию колонки, превратив ее в устройство для прослушки. |
К сожалению, этот список можно продолжать бесконечно. На рынке появляется все больше IoT-устройств, а значит у злоумышленников появляются все новые возможности для достижения своих целей. Наша подборка уязвимых IoT-устройств не единственная, и мы предлагаем вам узнать о них больше: Safegadget, Exploitee и Awesome IoT Hacks
Как можно заметить, большинство уязвимостей относятся к одной из десяти категорий списка OWASP, а это значит, что создатели IoT-устройств не учатся на ошибках друг друга. Большинство уязвимостей связаны с безопасностью приложений. Некоторые из упомянутых устройств уже стали частью ботнетов, поскольку меры, принятые вендорами для повышения безопасности, оказались недостаточными.
Национальный институт стандартов и технологий США выпустил Межведомственный отчет о состоянии международной стандартизации кибербезопасности для Интернета вещей (IoT). В этом документе приведены стандарты безопасности программного обеспечения и рекомендации по повышению его защищенности. Кроме того, производителям IoT-устройств рекомендуется использовать программное обеспечение, способное предотвращать, обнаруживать и смягчать вредоносное воздействие на производимые устройства.
Перед покупкой IoT-устройства почитайте как можно больше отзывов, чтобы выбрать наиболее безопасное. И помните: нет здоровых, есть недообследованные. Поэтому другая наша рекомендация по возможности повысить уровень безопасности ваших IoT-устройств самостоятельно, к примеру, установив сложный пароль в настройках. Или обратить внимание на популярный проект OpenWrt, который значительно повысил безопасность IoT-устройств, особенно тех, которые "позабыты" вендорами.
Мы в свою очередь предлагаем услугу исследования безопасности IoT и сетевых устройств. Она может быть востребована как производителями, так и покупателями больших партий таких устройств (например, камер охраны периметра).